 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Loop Neural Activation Control in Vision-Language-Action Models
May 29, 2026Vision-Language-Action (VLA) models can be steered at test time by intervening on semantically meaningful internal directions, but existing methods use a fixed steering coefficient, effectively operating in open loop. This is poorly suited to embodied control, where task state and concept error evolve over time, often causing overcorrection, oscillation, and reduced task success, especially for temporal behaviors such as speed and smoothness. We propose CTRL-STEER, a closed-loop framework that replaces static intervention strength with adaptive, time-varying control signals. The key idea is to decouple representation from regulation: rather than assuming temporal concepts are directly controlled by individual neurons, we steer along motion-aligned residual directions while a feedback controller adjusts intervention magnitude online. We instantiate this framework with both PID and reinforcement learning based controllers. Experiments with a fine-tuned OpenVLA policy on four LIBERO task suites show that CTRL-STEER achieves more stable concept regulation and a better steering-task success trade-off than fixed-coefficient baselines, without modifying or retraining the base model.
Breaking Bad: Interpretability-Based Safety Audits of State-of-the-Art LLMs
Apr 22, 2026Effective safety auditing of large language models (LLMs) demands tools that go beyond black-box probing and systematically uncover vulnerabilities rooted in model internals. We present a comprehensive, interpretability-driven jailbreaking audit of eight SOTA open-source LLMs: Llama-3.1-8B, Llama-3.3-70B-4bt, GPT-oss- 20B, GPT-oss-120B, Qwen3-0.6B, Qwen3-32B, Phi4-3.8B, and Phi4-14B. Leveraging interpretability-based approaches -- Universal Steering (US) and Representation Engineering (RepE) -- we introduce an adaptive two-stage grid search algorithm to identify optimal activation-steering coefficients for unsafe behavioral concepts. Our evaluation, conducted on a curated set of harmful queries and a standardized LLM-based judging protocol, reveals stark contrasts in model robustness. The Llama-3 models are highly vulnerable, with up to 91\% (US) and 83\% (RepE) jailbroken responses on Llama-3.3-70B-4bt, while GPT-oss-120B remains robust to attacks via both interpretability approaches. Qwen and Phi models show mixed results, with the smaller Qwen3-0.6B and Phi4-3.8B mostly exhibiting lower jailbreaking rates, while their larger counterparts are more susceptible. Our results establish interpretability-based steering as a powerful tool for systematic safety audits, but also highlight its dual-use risks and the need for better internal defenses in LLM deployment.
Optimal Abstractions for Verifying Properties of Kolmogorov-Arnold Networks (KANs)
Feb 06, 2026We present a novel approach for verifying properties of Kolmogorov-Arnold Networks (KANs), a class of neural networks characterized by nonlinear, univariate activation functions typically implemented as piecewise polynomial splines or Gaussian processes. Our method creates mathematical ``abstractions'' by replacing each KAN unit with a piecewise affine (PWA) function, providing both local and global error estimates between the original network and its approximation. These abstractions enable property verification by encoding the problem as a Mixed Integer Linear Program (MILP), determining whether outputs satisfy specified properties when inputs belong to a given set. A critical challenge lies in balancing the number of pieces in the PWA approximation: too many pieces add binary variables that make verification computationally intractable, while too few pieces create excessive error margins that yield uninformative bounds. Our key contribution is a systematic framework that exploits KAN structure to find optimal abstractions. By combining dynamic programming at the unit level with a knapsack optimization across the network, we minimize the total number of pieces while guaranteeing specified error bounds. This approach determines the optimal approximation strategy for each unit while maintaining overall accuracy requirements. Empirical evaluation across multiple KAN benchmarks demonstrates that the upfront analysis costs of our method are justified by superior verification results.
Polysemantic Dropout: Conformal OOD Detection for Specialized LLMs
Sep 04, 2025



We propose a novel inference-time out-of-domain (OOD) detection algorithm for specialized large language models (LLMs). Despite achieving state-of-the-art performance on in-domain tasks through fine-tuning, specialized LLMs remain vulnerable to incorrect or unreliable outputs when presented with OOD inputs, posing risks in critical applications. Our method leverages the Inductive Conformal Anomaly Detection (ICAD) framework, using a new non-conformity measure based on the model's dropout tolerance. Motivated by recent findings on polysemanticity and redundancy in LLMs, we hypothesize that in-domain inputs exhibit higher dropout tolerance than OOD inputs. We aggregate dropout tolerance across multiple layers via a valid ensemble approach, improving detection while maintaining theoretical false alarm bounds from ICAD. Experiments with medical-specialized LLMs show that our approach detects OOD inputs better than baseline methods, with AUROC improvements of $2\%$ to $37\%$ when treating OOD datapoints as positives and in-domain test datapoints as negatives.
Scalable Bayesian Low-Rank Adaptation of Large Language Models via Stochastic Variational Subspace Inference
Jun 26, 2025Despite their widespread use, large language models (LLMs) are known to hallucinate incorrect information and be poorly calibrated. This makes the uncertainty quantification of these models of critical importance, especially in high-stakes domains, such as autonomy and healthcare. Prior work has made Bayesian deep learning-based approaches to this problem more tractable by performing inference over the low-rank adaptation (LoRA) parameters of a fine-tuned model. While effective, these approaches struggle to scale to larger LLMs due to requiring further additional parameters compared to LoRA. In this work we present $\textbf{Scala}$ble $\textbf{B}$ayesian $\textbf{L}$ow-Rank Adaptation via Stochastic Variational Subspace Inference (ScalaBL). We perform Bayesian inference in an $r$-dimensional subspace, for LoRA rank $r$. By repurposing the LoRA parameters as projection matrices, we are able to map samples from this subspace into the full weight space of the LLM. This allows us to learn all the parameters of our approach using stochastic variational inference. Despite the low dimensionality of our subspace, we are able to achieve competitive performance with state-of-the-art approaches while only requiring ${\sim}1000$ additional parameters. Furthermore, it allows us to scale up to the largest Bayesian LLM to date, with four times as a many base parameters as prior work.
Calibrating Uncertainty Quantification of Multi-Modal LLMs using Grounding
Apr 30, 2025We introduce a novel approach for calibrating uncertainty quantification (UQ) tailored for multi-modal large language models (LLMs). Existing state-of-the-art UQ methods rely on consistency among multiple responses generated by the LLM on an input query under diverse settings. However, these approaches often report higher confidence in scenarios where the LLM is consistently incorrect. This leads to a poorly calibrated confidence with respect to accuracy. To address this, we leverage cross-modal consistency in addition to self-consistency to improve the calibration of the multi-modal models. Specifically, we ground the textual responses to the visual inputs. The confidence from the grounding model is used to calibrate the overall confidence. Given that using a grounding model adds its own uncertainty in the pipeline, we apply temperature scaling - a widely accepted parametric calibration technique - to calibrate the grounding model's confidence in the accuracy of generated responses. We evaluate the proposed approach across multiple multi-modal tasks, such as medical question answering (Slake) and visual question answering (VQAv2), considering multi-modal models such as LLaVA-Med and LLaVA. The experiments demonstrate that the proposed framework achieves significantly improved calibration on both tasks.
Safety Monitoring for Learning-Enabled Cyber-Physical Systems in Out-of-Distribution Scenarios
Apr 18, 2025The safety of learning-enabled cyber-physical systems is compromised by the well-known vulnerabilities of deep neural networks to out-of-distribution (OOD) inputs. Existing literature has sought to monitor the safety of such systems by detecting OOD data. However, such approaches have limited utility, as the presence of an OOD input does not necessarily imply the violation of a desired safety property. We instead propose to directly monitor safety in a manner that is itself robust to OOD data. To this end, we predict violations of signal temporal logic safety specifications based on predicted future trajectories. Our safety monitor additionally uses a novel combination of adaptive conformal prediction and incremental learning. The former obtains probabilistic prediction guarantees even on OOD data, and the latter prevents overly conservative predictions. We evaluate the efficacy of the proposed approach in two case studies on safety monitoring: 1) predicting collisions of an F1Tenth car with static obstacles, and 2) predicting collisions of a race car with multiple dynamic obstacles. We find that adaptive conformal prediction obtains theoretical guarantees where other uncertainty quantification methods fail to do so. Additionally, combining adaptive conformal prediction and incremental learning for safety monitoring achieves high recall and timeliness while reducing loss in precision. We achieve these results even in OOD settings and outperform alternative methods.
Addressing Uncertainty in LLMs to Enhance Reliability in Generative AI
Nov 04, 2024



In this paper, we present a dynamic semantic clustering approach inspired by the Chinese Restaurant Process, aimed at addressing uncertainty in the inference of Large Language Models (LLMs). We quantify uncertainty of an LLM on a given query by calculating entropy of the generated semantic clusters. Further, we propose leveraging the (negative) likelihood of these clusters as the (non)conformity score within Conformal Prediction framework, allowing the model to predict a set of responses instead of a single output, thereby accounting for uncertainty in its predictions. We demonstrate the effectiveness of our uncertainty quantification (UQ) technique on two well known question answering benchmarks, COQA and TriviaQA, utilizing two LLMs, Llama2 and Mistral. Our approach achieves SOTA performance in UQ, as assessed by metrics such as AUROC, AUARC, and AURAC. The proposed conformal predictor is also shown to produce smaller prediction sets while maintaining the same probabilistic guarantee of including the correct response, in comparison to existing SOTA conformal prediction baseline.
Automating Weak Label Generation for Data Programming with Clinicians in the Loop
Jul 10, 2024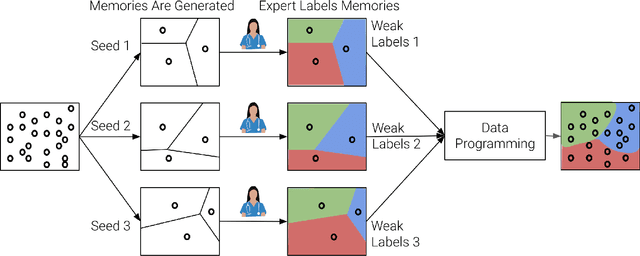
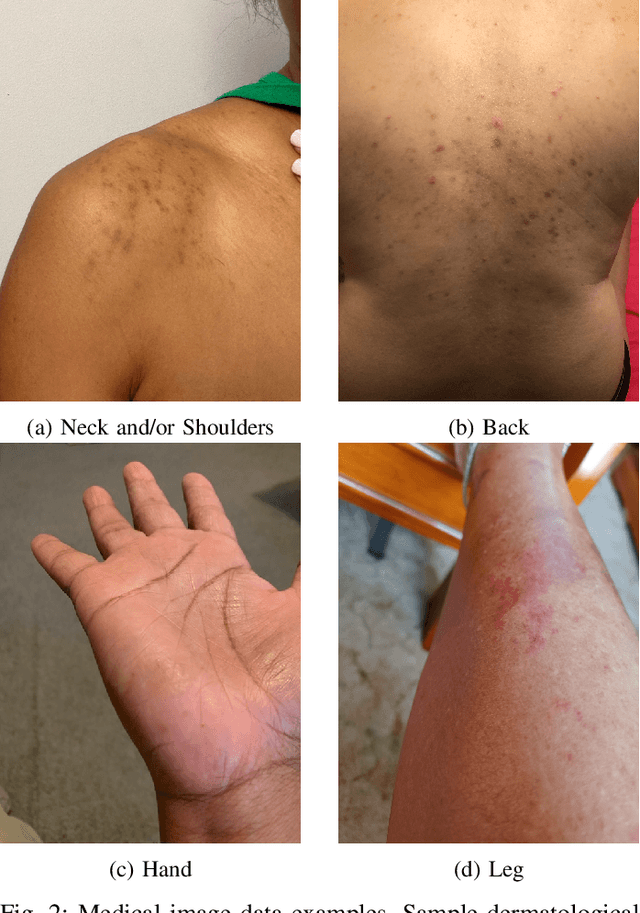
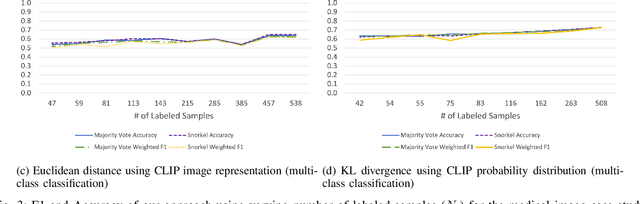
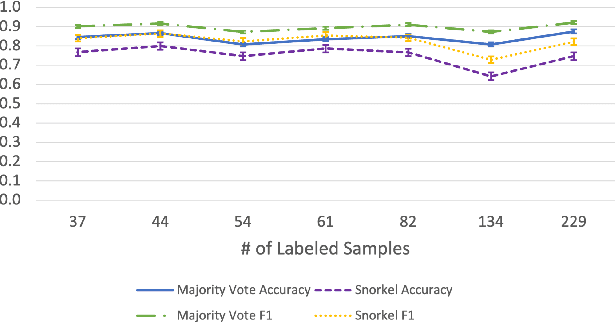
Large Deep Neural Networks (DNNs) are often data hungry and need high-quality labeled data in copious amounts for learning to converge. This is a challenge in the field of medicine since high quality labeled data is often scarce. Data programming has been the ray of hope in this regard, since it allows us to label unlabeled data using multiple weak labeling functions. Such functions are often supplied by a domain expert. Data-programming can combine multiple weak labeling functions and suggest labels better than simple majority voting over the different functions. However, it is not straightforward to express such weak labeling functions, especially in high-dimensional settings such as images and time-series data. What we propose in this paper is a way to bypass this issue, using distance functions. In high-dimensional spaces, it is easier to find meaningful distance metrics which can generalize across different labeling tasks. We propose an algorithm that queries an expert for labels of a few representative samples of the dataset. These samples are carefully chosen by the algorithm to capture the distribution of the dataset. The labels assigned by the expert on the representative subset induce a labeling on the full dataset, thereby generating weak labels to be used in the data programming pipeline. In our medical time series case study, labeling a subset of 50 to 130 out of 3,265 samples showed 17-28% improvement in accuracy and 13-28% improvement in F1 over the baseline using clinician-defined labeling functions. In our medical image case study, labeling a subset of about 50 to 120 images from 6,293 unlabeled medical images using our approach showed significant improvement over the baseline method, Snuba, with an increase of approximately 5-15% in accuracy and 12-19% in F1 score.
Detection of Adversarial Physical Attacks in Time-Series Image Data
Apr 27, 2023



Deep neural networks (DNN) have become a common sensing modality in autonomous systems as they allow for semantically perceiving the ambient environment given input images. Nevertheless, DNN models have proven to be vulnerable to adversarial digital and physical attacks. To mitigate this issue, several detection frameworks have been proposed to detect whether a single input image has been manipulated by adversarial digital noise or not. In our prior work, we proposed a real-time detector, called VisionGuard (VG), for adversarial physical attacks against single input images to DNN models. Building upon that work, we propose VisionGuard* (VG), which couples VG with majority-vote methods, to detect adversarial physical attacks in time-series image data, e.g., videos. This is motivated by autonomous systems applications where images are collected over time using onboard sensors for decision-making purposes. We emphasize that majority-vote mechanisms are quite common in autonomous system applications (among many other applications), as e.g., in autonomous driving stacks for object detection. In this paper, we investigate, both theoretically and experimentally, how this widely used mechanism can be leveraged to enhance the performance of adversarial detectors. We have evaluated VG* on videos of both clean and physically attacked traffic signs generated by a state-of-the-art robust physical attack. We provide extensive comparative experiments against detectors that have been designed originally for out-of-distribution data and digitally attacked images.