 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiFFPO: Training Diffusion LLMs to Reason Fast and Furious via Reinforcement Learning
Oct 02, 2025



We propose DiFFPO, Diffusion Fast and Furious Policy Optimization, a unified framework for training masked diffusion large language models (dLLMs) to reason not only better (furious), but also faster via reinforcement learning (RL). We first unify the existing baseline approach such as d1 by proposing to train surrogate policies via off-policy RL, whose likelihood is much more tractable as an approximation to the true dLLM policy. This naturally motivates a more accurate and informative two-stage likelihood approximation combined with importance sampling correction, which leads to generalized RL algorithms with better sample efficiency and superior task performance. Second, we propose a new direction of joint training efficient samplers/controllers of dLLMs policy. Via RL, we incentivize dLLMs' natural multi-token prediction capabilities by letting the model learn to adaptively allocate an inference threshold for each prompt. By jointly training the sampler, we yield better accuracies with lower number of function evaluations (NFEs) compared to training the model only, obtaining the best performance in improving the Pareto frontier of the inference-time compute of dLLMs. We showcase the effectiveness of our pipeline by training open source large diffusion language models over benchmark math and planning tasks.
Entropy After $\langle \texttt{/Think} \rangle$ for reasoning model early exiting
Sep 30, 2025



Large reasoning models show improved performance with longer chains of thought. However, recent work has highlighted (qualitatively) their tendency to overthink, continuing to revise answers even after reaching the correct solution. We quantitatively confirm this inefficiency by tracking Pass@1 for answers averaged over a large number of rollouts and find that the model often begins to always produce the correct answer early in the reasoning, making extra reasoning a waste of tokens. To detect and prevent overthinking, we propose a simple and inexpensive novel signal -- Entropy After </Think> (EAT) -- for monitoring and deciding whether to exit reasoning early. By appending a stop thinking token (</think>) and monitoring the entropy of the following token as the model reasons, we obtain a trajectory that decreases and stabilizes when Pass@1 plateaus; thresholding its variance under an exponential moving average yields a practical stopping rule. Importantly, our approach enables adaptively allocating compute based on the EAT trajectory, allowing us to spend compute in a more efficient way compared with fixing the token budget for all questions. Empirically, on MATH500 and AIME2025, EAT reduces token usage by 13 - 21% without harming accuracy, and it remains effective in black box settings where logits from the reasoning model are not accessible, and EAT is computed with proxy models.
Value-Guided Search for Efficient Chain-of-Thought Reasoning
May 23, 2025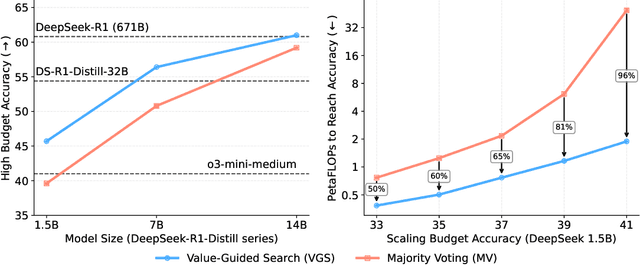
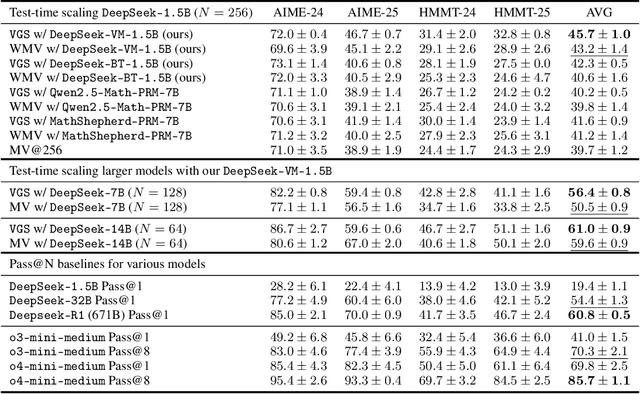
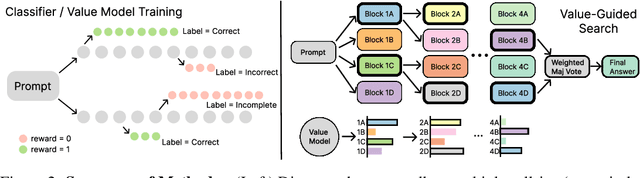
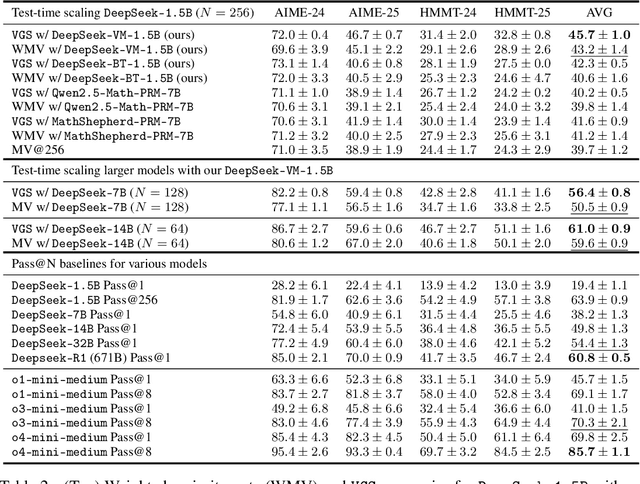
In this paper, we propose a simple and efficient method for value model training on long-context reasoning traces. Compared to existing process reward models (PRMs), our method does not require a fine-grained notion of "step," which is difficult to define for long-context reasoning models. By collecting a dataset of 2.5 million reasoning traces, we train a 1.5B token-level value model and apply it to DeepSeek models for improved performance with test-time compute scaling. We find that block-wise value-guided search (VGS) with a final weighted majority vote achieves better test-time scaling than standard methods such as majority voting or best-of-n. With an inference budget of 64 generations, VGS with DeepSeek-R1-Distill-1.5B achieves an average accuracy of 45.7% across four competition math benchmarks (AIME 2024 & 2025, HMMT Feb 2024 & 2025), reaching parity with o3-mini-medium. Moreover, VGS significantly reduces the inference FLOPs required to achieve the same performance of majority voting. Our dataset, model and codebase are open-sourced.
Efficient Adaptive Experimentation with Non-Compliance
May 23, 2025We study the problem of estimating the average treatment effect (ATE) in adaptive experiments where treatment can only be encouraged--rather than directly assigned--via a binary instrumental variable. Building on semiparametric efficiency theory, we derive the efficiency bound for ATE estimation under arbitrary, history-dependent instrument-assignment policies, and show it is minimized by a variance-aware allocation rule that balances outcome noise and compliance variability. Leveraging this insight, we introduce AMRIV--an \textbf{A}daptive, \textbf{M}ultiply-\textbf{R}obust estimator for \textbf{I}nstrumental-\textbf{V}ariable settings with variance-optimal assignment. AMRIV pairs (i) an online policy that adaptively approximates the optimal allocation with (ii) a sequential, influence-function-based estimator that attains the semiparametric efficiency bound while retaining multiply-robust consistency. We establish asymptotic normality, explicit convergence rates, and anytime-valid asymptotic confidence sequences that enable sequential inference. Finally, we demonstrate the practical effectiveness of our approach through empirical studies, showing that adaptive instrument assignment, when combined with the AMRIV estimator, yields improved efficiency and robustness compared to existing baselines.
Nonparametric Instrumental Variable Inference with Many Weak Instruments
May 12, 2025We study inference on linear functionals in the nonparametric instrumental variable (NPIV) problem with a discretely-valued instrument under a many-weak-instruments asymptotic regime, where the number of instrument values grows with the sample size. A key motivating example is estimating long-term causal effects in a new experiment with only short-term outcomes, using past experiments to instrument for the effect of short- on long-term outcomes. Here, the assignment to a past experiment serves as the instrument: we have many past experiments but only a limited number of units in each. Since the structural function is nonparametric but constrained by only finitely many moment restrictions, point identification typically fails. To address this, we consider linear functionals of the minimum-norm solution to the moment restrictions, which is always well-defined. As the number of instrument levels grows, these functionals define an approximating sequence to a target functional, replacing point identification with a weaker asymptotic notion suited to discrete instruments. Extending the Jackknife Instrumental Variable Estimator (JIVE) beyond the classical parametric setting, we propose npJIVE, a nonparametric estimator for solutions to linear inverse problems with many weak instruments. We construct automatic debiased machine learning estimators for linear functionals of both the structural function and its minimum-norm projection, and establish their efficiency in the many-weak-instruments regime.
From Reviews to Dialogues: Active Synthesis for Zero-Shot LLM-based Conversational Recommender System
Apr 21, 2025



Conversational recommender systems (CRS) typically require extensive domain-specific conversational datasets, yet high costs, privacy concerns, and data-collection challenges severely limit their availability. Although Large Language Models (LLMs) demonstrate strong zero-shot recommendation capabilities, practical applications often favor smaller, internally managed recommender models due to scalability, interpretability, and data privacy constraints, especially in sensitive or rapidly evolving domains. However, training these smaller models effectively still demands substantial domain-specific conversational data, which remains challenging to obtain. To address these limitations, we propose an active data augmentation framework that synthesizes conversational training data by leveraging black-box LLMs guided by active learning techniques. Specifically, our method utilizes publicly available non-conversational domain data, including item metadata, user reviews, and collaborative signals, as seed inputs. By employing active learning strategies to select the most informative seed samples, our approach efficiently guides LLMs to generate synthetic, semantically coherent conversational interactions tailored explicitly to the target domain. Extensive experiments validate that conversational data generated by our proposed framework significantly improves the performance of LLM-based CRS models, effectively addressing the challenges of building CRS in no- or low-resource scenarios.
SNPL: Simultaneous Policy Learning and Evaluation for Safe Multi-Objective Policy Improvement
Mar 17, 2025To design effective digital interventions, experimenters face the challenge of learning decision policies that balance multiple objectives using offline data. Often, they aim to develop policies that maximize goal outcomes, while ensuring there are no undesirable changes in guardrail outcomes. To provide credible recommendations, experimenters must not only identify policies that satisfy the desired changes in goal and guardrail outcomes, but also offer probabilistic guarantees about the changes these policies induce. In practice, however, policy classes are often large, and digital experiments tend to produce datasets with small effect sizes relative to noise. In this setting, standard approaches such as data splitting or multiple testing often result in unstable policy selection and/or insufficient statistical power. In this paper, we provide safe noisy policy learning (SNPL), a novel approach that leverages the concept of algorithmic stability to address these challenges. Our method enables policy learning while simultaneously providing high-confidence guarantees using the entire dataset, avoiding the need for data-splitting. We present finite-sample and asymptotic versions of our algorithm that ensure the recommended policy satisfies high-probability guarantees for avoiding guardrail regressions and/or achieving goal outcome improvements. We test both variants of our approach approach empirically on a real-world application of personalizing SMS delivery. Our results on real-world data suggest that our approach offers dramatic improvements in settings with large policy classes and low signal-to-noise across both finite-sample and asymptotic safety guarantees, offering up to 300\% improvements in detection rates and 150\% improvements in policy gains at significantly smaller sample sizes.
$Q\sharp$: Provably Optimal Distributional RL for LLM Post-Training
Feb 27, 2025



Reinforcement learning (RL) post-training is crucial for LLM alignment and reasoning, but existing policy-based methods, such as PPO and DPO, can fall short of fixing shortcuts inherited from pre-training. In this work, we introduce $Q\sharp$, a value-based algorithm for KL-regularized RL that guides the reference policy using the optimal regularized $Q$ function. We propose to learn the optimal $Q$ function using distributional RL on an aggregated online dataset. Unlike prior value-based baselines that guide the model using unregularized $Q$-values, our method is theoretically principled and provably learns the optimal policy for the KL-regularized RL problem. Empirically, $Q\sharp$ outperforms prior baselines in math reasoning benchmarks while maintaining a smaller KL divergence to the reference policy. Theoretically, we establish a reduction from KL-regularized RL to no-regret online learning, providing the first bounds for deterministic MDPs under only realizability. Thanks to distributional RL, our bounds are also variance-dependent and converge faster when the reference policy has small variance. In sum, our results highlight $Q\sharp$ as an effective approach for post-training LLMs, offering both improved performance and theoretical guarantees. The code can be found at https://github.com/jinpz/q_sharp.
Collaborative Retrieval for Large Language Model-based Conversational Recommender Systems
Feb 19, 2025



Conversational recommender systems (CRS) aim to provide personalized recommendations via interactive dialogues with users. While large language models (LLMs) enhance CRS with their superior understanding of context-aware user preferences, they typically struggle to leverage behavioral data, which have proven to be important for classical collaborative filtering (CF)-based approaches. For this reason, we propose CRAG, Collaborative Retrieval Augmented Generation for LLM-based CRS. To the best of our knowledge, CRAG is the first approach that combines state-of-the-art LLMs with CF for conversational recommendations. Our experiments on two publicly available movie conversational recommendation datasets, i.e., a refined Reddit dataset (which we name Reddit-v2) as well as the Redial dataset, demonstrate the superior item coverage and recommendation performance of CRAG, compared to several CRS baselines. Moreover, we observe that the improvements are mainly due to better recommendation accuracy on recently released movies. The code and data are available at https://github.com/yaochenzhu/CRAG.
GST-UNet: Spatiotemporal Causal Inference with Time-Varying Confounders
Feb 07, 2025Estimating causal effects from spatiotemporal data is a key challenge in fields such as public health, social policy, and environmental science, where controlled experiments are often infeasible. However, existing causal inference methods relying on observational data face significant limitations: they depend on strong structural assumptions to address spatiotemporal challenges $\unicode{x2013}$ such as interference, spatial confounding, and temporal carryover effects $\unicode{x2013}$ or fail to account for $\textit{time-varying confounders}$. These confounders, influenced by past treatments and outcomes, can themselves shape future treatments and outcomes, creating feedback loops that complicate traditional adjustment strategies. To address these challenges, we introduce the $\textbf{GST-UNet}$ ($\textbf{G}$-computation $\textbf{S}$patio-$\textbf{T}$emporal $\textbf{UNet}$), a novel end-to-end neural network framework designed to estimate treatment effects in complex spatial and temporal settings. The GST-UNet leverages regression-based iterative G-computation to explicitly adjust for time-varying confounders, providing valid estimates of potential outcomes and treatment effects. To the best of our knowledge, the GST-UNet is the first neural model to account for complex, non-linear dynamics and time-varying confounders in spatiotemporal interventions. We demonstrate the effectiveness of the GST-UNet through extensive simulation studies and showcase its practical utility with a real-world analysis of the impact of wildfire smoke on respiratory hospitalizations during the 2018 California Camp Fire. Our results highlight the potential of GST-UNet to advance spatiotemporal causal inference across a wide range of policy-driven and scientific applications.