 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Transfer from Inverse Reinforcement Learning: A Coupled Minimax Approach
May 27, 2026We study the transfer of rewards learned using inverse reinforcement learning from expert demonstrations in one environment to reinforcement learning in a new, different environment. This arises naturally when demonstrations are collected in a controlled environment. We formulate the problem as a joint system of Bellman equations across the source and target environments and develop minimax estimators for the target soft-$q$-function. Whereas a sequential solution approach first estimates the source reward and then plugs it into the target control problem, a coupled approach solves the source and target system of equations jointly. We show that, in contrast to the sequential approach, the coupled approach removes the first-order influence of source Bellman residual error. We characterize the local behavior of each approach, develop finite-sample soft-$q$-function error bounds, and prove regret guarantees for the resulting soft-control policy. An empirical investigation using a sepsis simulator validates the theoretical comparison.
Semiparametric Efficient Bilevel Gradient Estimation
May 20, 2026Functional bilevel methods estimate a lower-level function and plug it into a hypergradient, but this plug-in gradient can retain first-order bias when the lower-level problem is learned nonparametrically. To remove this bias, we develop a semiparametric debiasing theory for population bilevel gradients based on the efficient influence function. This perspective leads to a cross-fitted orthogonal hypergradient estimator for which we establish asymptotic normality together with uniform control over the outer parameter. Under quadratic losses, the estimator reduces to a simple doubly robust score based on conditional mean nuisances. On synthetic bilevel benchmarks with known ground truth, the method tracks the oracle efficient-gradient benchmark and improves over plug-in functional hypergradients and regularized kernel bilevel baselines.
Instrumental Variable Analysis Without Structural Equations
Apr 27, 2026We consider debiased inference on least-squares solutions to inverse problems as a way to avoid having to assume exact solutions exist. Such assumptions are substantive and not innocuous and their failure may well imperil inference when we impose them on the statistical model. Our approach instead allows us to conduct inference on a quantity that is defined regardless of solutions existing and coincides with the usual estimands when they do. For the case of instrumental variables, this means we can motivate the analysis with structural models but these do not need to hold exactly for the inferential procedure to remain valid.
Efficient Inference after Directionally Stable Adaptive Experiments
Feb 25, 2026We study inference on scalar-valued pathwise differentiable targets after adaptive data collection, such as a bandit algorithm. We introduce a novel target-specific condition, directional stability, which is strictly weaker than previously imposed target-agnostic stability conditions. Under directional stability, we show that estimators that would have been efficient under i.i.d. data remain asymptotically normal and semiparametrically efficient when computed from adaptively collected trajectories. The canonical gradient has a martingale form, and directional stability guarantees stabilization of its predictable quadratic variation, enabling high-dimensional asymptotic normality. We characterize efficiency using a convolution theorem for the adaptive-data setting, and give a condition under which the one-step estimator attains the efficiency bound. We verify directional stability for LinUCB, yielding the first semiparametric efficiency guarantee for a regular scalar target under LinUCB sampling.
The Value of Personalized Recommendations: Evidence from Netflix
Nov 11, 2025Personalized recommendation systems shape much of user choice online, yet their targeted nature makes separating out the value of recommendation and the underlying goods challenging. We build a discrete choice model that embeds recommendation-induced utility, low-rank heterogeneity, and flexible state dependence and apply the model to viewership data at Netflix. We exploit idiosyncratic variation introduced by the recommendation algorithm to identify and separately value these components as well as to recover model-free diversion ratios that we can use to validate our structural model. We use the model to evaluate counterfactuals that quantify the incremental engagement generated by personalized recommendations. First, we show that replacing the current recommender system with a matrix factorization or popularity-based algorithm would lead to 4% and 12% reduction in engagement, respectively, and decreased consumption diversity. Second, most of the consumption increase from recommendations comes from effective targeting, not mechanical exposure, with the largest gains for mid-popularity goods (as opposed to broadly appealing or very niche goods).
Nonparametric Instrumental Variable Inference with Many Weak Instruments
May 12, 2025We study inference on linear functionals in the nonparametric instrumental variable (NPIV) problem with a discretely-valued instrument under a many-weak-instruments asymptotic regime, where the number of instrument values grows with the sample size. A key motivating example is estimating long-term causal effects in a new experiment with only short-term outcomes, using past experiments to instrument for the effect of short- on long-term outcomes. Here, the assignment to a past experiment serves as the instrument: we have many past experiments but only a limited number of units in each. Since the structural function is nonparametric but constrained by only finitely many moment restrictions, point identification typically fails. To address this, we consider linear functionals of the minimum-norm solution to the moment restrictions, which is always well-defined. As the number of instrument levels grows, these functionals define an approximating sequence to a target functional, replacing point identification with a weaker asymptotic notion suited to discrete instruments. Extending the Jackknife Instrumental Variable Estimator (JIVE) beyond the classical parametric setting, we propose npJIVE, a nonparametric estimator for solutions to linear inverse problems with many weak instruments. We construct automatic debiased machine learning estimators for linear functionals of both the structural function and its minimum-norm projection, and establish their efficiency in the many-weak-instruments regime.
Automatic Double Reinforcement Learning in Semiparametric Markov Decision Processes with Applications to Long-Term Causal Inference
Jan 12, 2025


Double reinforcement learning (DRL) enables statistically efficient inference on the value of a policy in a nonparametric Markov Decision Process (MDP) given trajectories generated by another policy. However, this approach necessarily requires stringent overlap between the state distributions, which is often violated in practice. To relax this requirement and extend DRL, we study efficient inference on linear functionals of the $Q$-function (of which policy value is a special case) in infinite-horizon, time-invariant MDPs under semiparametric restrictions on the $Q$-function. These restrictions can reduce the overlap requirement and lower the efficiency bound, yielding more precise estimates. As an important example, we study the evaluation of long-term value under domain adaptation, given a few short trajectories from the new domain and restrictions on the difference between the domains. This can be used for long-term causal inference. Our method combines flexible estimates of the $Q$-function and the Riesz representer of the functional of interest (e.g., the stationary state density ratio for policy value) and is automatic in that we do not need to know the form of the latter - only the functional we care about. To address potential model misspecification bias, we extend the adaptive debiased machine learning (ADML) framework of \citet{van2023adaptive} to construct nonparametrically valid and superefficient estimators that adapt to the functional form of the $Q$-function. As a special case, we propose a novel adaptive debiased plug-in estimator that uses isotonic-calibrated fitted $Q$-iteration - a new calibration algorithm for MDPs - to circumvent the computational challenges of estimating debiasing nuisances from min-max objectives.
Demistifying Inference after Adaptive Experiments
May 02, 2024Adaptive experiments such as multi-arm bandits adapt the treatment-allocation policy and/or the decision to stop the experiment to the data observed so far. This has the potential to improve outcomes for study participants within the experiment, to improve the chance of identifying best treatments after the experiment, and to avoid wasting data. Seen as an experiment (rather than just a continually optimizing system) it is still desirable to draw statistical inferences with frequentist guarantees. The concentration inequalities and union bounds that generally underlie adaptive experimentation algorithms can yield overly conservative inferences, but at the same time the asymptotic normality we would usually appeal to in non-adaptive settings can be imperiled by adaptivity. In this article we aim to explain why, how, and when adaptivity is in fact an issue for inference and, when it is, understand the various ways to fix it: reweighting to stabilize variances and recover asymptotic normality, always-valid inference based on joint normality of an asymptotic limiting sequence, and characterizing and inverting the non-normal distributions induced by adaptivity.
Risk Minimization from Adaptively Collected Data: Guarantees for Supervised and Policy Learning
Jun 03, 2021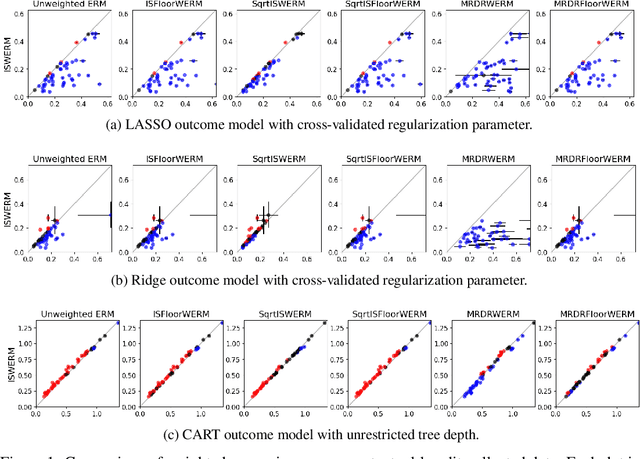

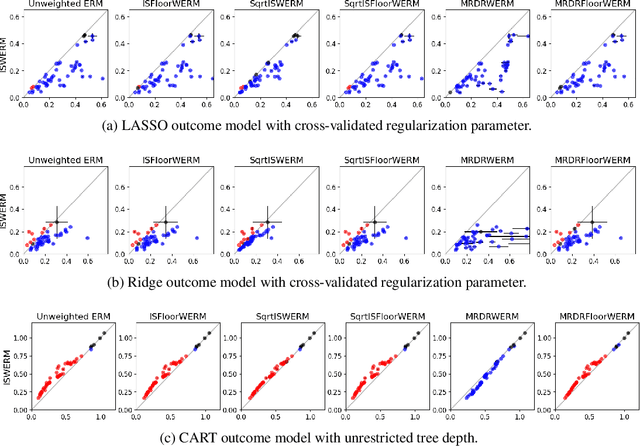
Empirical risk minimization (ERM) is the workhorse of machine learning, whether for classification and regression or for off-policy policy learning, but its model-agnostic guarantees can fail when we use adaptively collected data, such as the result of running a contextual bandit algorithm. We study a generic importance sampling weighted ERM algorithm for using adaptively collected data to minimize the average of a loss function over a hypothesis class and provide first-of-their-kind generalization guarantees and fast convergence rates. Our results are based on a new maximal inequality that carefully leverages the importance sampling structure to obtain rates with the right dependence on the exploration rate in the data. For regression, we provide fast rates that leverage the strong convexity of squared-error loss. For policy learning, we provide rate-optimal regret guarantees that close an open gap in the existing literature whenever exploration decays to zero, as is the case for bandit-collected data. An empirical investigation validates our theory.
Post-Contextual-Bandit Inference
Jun 01, 2021
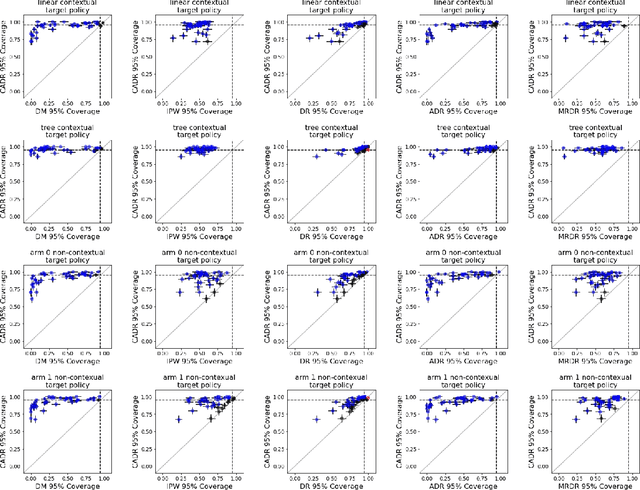
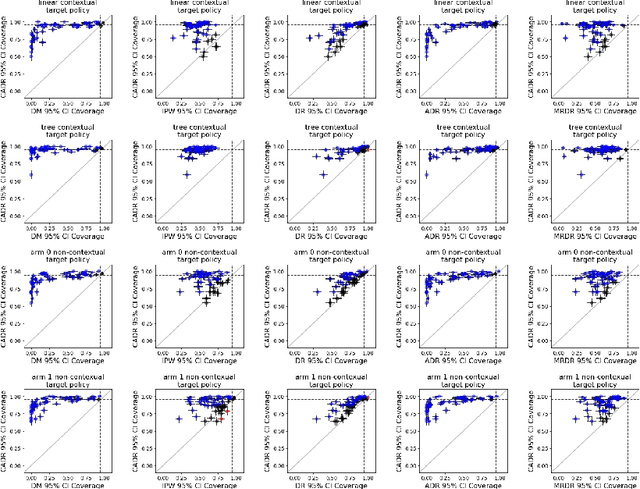
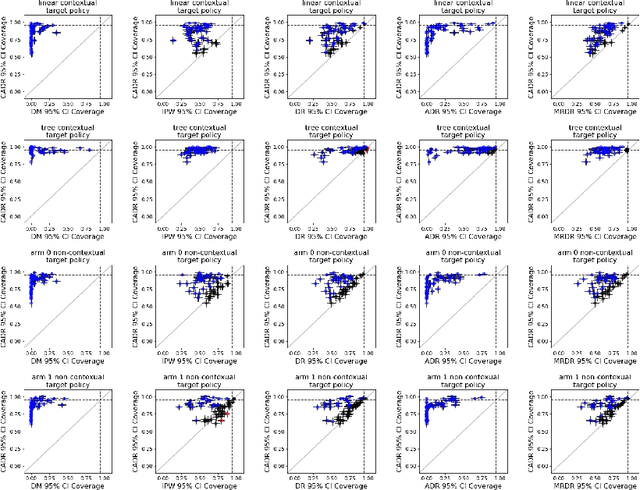
Contextual bandit algorithms are increasingly replacing non-adaptive A/B tests in e-commerce, healthcare, and policymaking because they can both improve outcomes for study participants and increase the chance of identifying good or even best policies. To support credible inference on novel interventions at the end of the study, nonetheless, we still want to construct valid confidence intervals on average treatment effects, subgroup effects, or value of new policies. The adaptive nature of the data collected by contextual bandit algorithms, however, makes this difficult: standard estimators are no longer asymptotically normally distributed and classic confidence intervals fail to provide correct coverage. While this has been addressed in non-contextual settings by using stabilized estimators, the contextual setting poses unique challenges that we tackle for the first time in this paper. We propose the Contextual Adaptive Doubly Robust (CADR) estimator, the first estimator for policy value that is asymptotically normal under contextual adaptive data collection. The main technical challenge in constructing CADR is designing adaptive and consistent conditional standard deviation estimators for stabilization. Extensive numerical experiments using 57 OpenML datasets demonstrate that confidence intervals based on CADR uniquely provide correct coverage.