 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPD+: Rethinking the Advantage Design for On-Policy Distillation
May 31, 2026On-policy distillation (OPD) is a widely used technique to transfer capabilities from capable teacher language models to the base student models, and can be formulated in a reinforcement learning style objective using student generated rollouts. Yet, despite the divergence reward being dependent on student model likelihood, existing works usually adopt a stop gradient design primarily for stability, which makes the resulting advantage estimation questionable. In this work, we provide a generic optimization framework based on f-divergence between the student and teacher, and mathematically revisit whether such design space is valid. We prove that general stop-gradient operation would lead to biased estimates of the reward objective and corresponding gradient for general divergence functions. We propose OPD+, the corrected version of OPD that demonstrates improved performance over the baseline KL approach and also supports the choice of various f-divergence. We validate our findings on mathematical reasoning and tool-use benchmarks.
Tweedie's Formulae and Diffusion Generative Models Beyond Gaussian
May 19, 2026Diffusion models have achieved remarkable success in generating samples from unknown data distributions. Most popular stochastic differential equation-based diffusion models perturb the target distribution by adding Gaussian noise, transforming it into a simple prior, and then use denoising score matching, a consequence of Tweedie's formula, to learn the score function and generate clean samples from noise. However, non-Gaussian diffusion models with state-dependent diffusion coefficient have been largely underexplored, as have the corresponding Tweedie's formulae. In this work, we extend Tweedie's formula to important non-Gaussian processes, including geometric Brownian motion (GBM), squared Bessel (BESQ) processes, and Cox-Ingersoll-Ross (CIR) processes, thereby yielding the corresponding denoising score-matching objectives. We then apply the derived formulae to image and financial time series generation using GBM- and CIR-based diffusion models, and to empirical Bayes estimation under the BESQ setting. The reported experimental results demonstrate the potential of non-Gaussian models.
Sample Complexity of Transfer Learning: An Optimal Transport Approach
May 19, 2026Transfer learning is an essential technique for many machine learning/AI models of complex structures such as large language models and generative AI. The essence of transfer learning is to leverage knowledge from resolved source tasks for a new target task, especially when the sample size $m$ of the training data for the latter is low. In this work, we rigorously analyze the potential benefit of transfer learning in terms of sample efficiency. Specifically, taking an optimal transport viewpoint of transfer learning, we find that when the data dimension $d$ is higher than $3$, the sample complexity for transfer learning is $O(m^{-(α+1)/d})$, with $α$ indicating the smoothness of the data distribution, as opposed to the $O(m^{-p/d})$ sample complexity for direct learning with $p$ indicating the smoothness of the optimal target model. Our finding theoretically supports a better sample efficiency for transfer learning, when the target task is optimizing over a family of not-so-smooth models (i.e., highly complex networks with the possible use of non-smooth activation functions). Using image classification as an example, we numerically demonstrate the sample efficiency for transfer learning, that is, in the data hungry regime, the model performance can be significantly improved by transfer learning.
Improved techniques for fine-tuning flow models via adjoint matching: a deterministic control pipeline
May 07, 2026We propose a deterministic adjoint matching framework that formulates human preference alignment for flow-based generative models as an optimal control problem over velocity fields. One can directly regress the control toward a value-gradient-induced target under the current policy, leading to a simple and stable training objective. Building on this perspective, we introduce a truncated adjoint scheme that focuses computation on the terminal portion of the trajectory, where reward-relevant signals concentrate, which yields substantial computational savings while preserving alignment quality. We further generalize the framework beyond standard KL-based regularization, allowing more flexible trade-offs between alignment strength and distributional preservation. Experiments on SiT-XL/2 and FLUX.2-Klein-4B demonstrate consistent gains across multiple alignment metrics, along with substantially improved diversity and mode preservation.
Conditional Diffusion Guidance under Hard Constraint: A Stochastic Analysis Approach
Feb 05, 2026We study conditional generation in diffusion models under hard constraints, where generated samples must satisfy prescribed events with probability one. Such constraints arise naturally in safety-critical applications and in rare-event simulation, where soft or reward-based guidance methods offer no guarantee of constraint satisfaction. Building on a probabilistic interpretation of diffusion models, we develop a principled conditional diffusion guidance framework based on Doob's h-transform, martingale representation and quadratic variation process. Specifically, the resulting guided dynamics augment a pretrained diffusion with an explicit drift correction involving the logarithmic gradient of a conditioning function, without modifying the pretrained score network. Leveraging martingale and quadratic-variation identities, we propose two novel off-policy learning algorithms based on a martingale loss and a martingale-covariation loss to estimate h and its gradient using only trajectories from the pretrained model. We provide non-asymptotic guarantees for the resulting conditional sampler in both total variation and Wasserstein distances, explicitly characterizing the impact of score approximation and guidance estimation errors. Numerical experiments demonstrate the effectiveness of the proposed methods in enforcing hard constraints and generating rare-event samples.
ART for Diffusion Sampling: A Reinforcement Learning Approach to Timestep Schedule
Jan 26, 2026We consider time discretization for score-based diffusion models to generate samples from a learned reverse-time dynamic on a finite grid. Uniform and hand-crafted grids can be suboptimal given a budget on the number of time steps. We introduce Adaptive Reparameterized Time (ART) that controls the clock speed of a reparameterized time variable, leading to a time change and uneven timesteps along the sampling trajectory while preserving the terminal time. The objective is to minimize the aggregate error arising from the discretized Euler scheme. We derive a randomized control companion, ART-RL, and formulate time change as a continuous-time reinforcement learning (RL) problem with Gaussian policies. We then prove that solving ART-RL recovers the optimal ART schedule, which in turn enables practical actor--critic updates to learn the latter in a data-driven way. Empirically, based on the official EDM pipeline, ART-RL improves Fréchet Inception Distance on CIFAR-10 over a wide range of budgets and transfers to AFHQv2, FFHQ, and ImageNet without the need of retraining.
DiFFPO: Training Diffusion LLMs to Reason Fast and Furious via Reinforcement Learning
Oct 02, 2025



We propose DiFFPO, Diffusion Fast and Furious Policy Optimization, a unified framework for training masked diffusion large language models (dLLMs) to reason not only better (furious), but also faster via reinforcement learning (RL). We first unify the existing baseline approach such as d1 by proposing to train surrogate policies via off-policy RL, whose likelihood is much more tractable as an approximation to the true dLLM policy. This naturally motivates a more accurate and informative two-stage likelihood approximation combined with importance sampling correction, which leads to generalized RL algorithms with better sample efficiency and superior task performance. Second, we propose a new direction of joint training efficient samplers/controllers of dLLMs policy. Via RL, we incentivize dLLMs' natural multi-token prediction capabilities by letting the model learn to adaptively allocate an inference threshold for each prompt. By jointly training the sampler, we yield better accuracies with lower number of function evaluations (NFEs) compared to training the model only, obtaining the best performance in improving the Pareto frontier of the inference-time compute of dLLMs. We showcase the effectiveness of our pipeline by training open source large diffusion language models over benchmark math and planning tasks.
Diffusion Generative Models Meet Compressed Sensing, with Applications to Image Data and Financial Time Series
Sep 04, 2025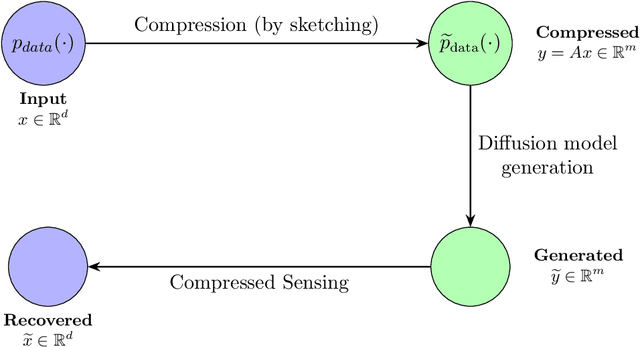



This paper develops dimension reduction techniques for accelerating diffusion model inference in the context of synthetic data generation. The idea is to integrate compressed sensing into diffusion models: (i) compress the data into a latent space, (ii) train a diffusion model in the latent space, and (iii) apply a compressed sensing algorithm to the samples generated in the latent space, facilitating the efficiency of both model training and inference. Under suitable sparsity assumptions on data, the proposed algorithm is proved to enjoy faster convergence by combining diffusion model inference with sparse recovery. As a byproduct, we obtain an optimal value for the latent space dimension. We also conduct numerical experiments on a range of datasets, including image data (handwritten digits, medical images, and climate data) and financial time series for stress testing.
Fine-Tuning Diffusion Generative Models via Rich Preference Optimization
Mar 13, 2025



We introduce Rich Preference Optimization (RPO), a novel pipeline that leverages rich feedback signals to improve the curation of preference pairs for fine-tuning text-to-image diffusion models. Traditional methods, like Diffusion-DPO, often rely solely on reward model labeling, which can be opaque, offer limited insights into the rationale behind preferences, and are prone to issues such as reward hacking or overfitting. In contrast, our approach begins with generating detailed critiques of synthesized images to extract reliable and actionable image editing instructions. By implementing these instructions, we create refined images, resulting in synthetic, informative preference pairs that serve as enhanced tuning datasets. We demonstrate the effectiveness of our pipeline and the resulting datasets in fine-tuning state-of-the-art diffusion models.
Score as Action: Fine-Tuning Diffusion Generative Models by Continuous-time Reinforcement Learning
Feb 03, 2025



Reinforcement learning from human feedback (RLHF), which aligns a diffusion model with input prompt, has become a crucial step in building reliable generative AI models. Most works in this area use a discrete-time formulation, which is prone to induced errors, and often not applicable to models with higher-order/black-box solvers. The objective of this study is to develop a disciplined approach to fine-tune diffusion models using continuous-time RL, formulated as a stochastic control problem with a reward function that aligns the end result (terminal state) with input prompt. The key idea is to treat score matching as controls or actions, and thereby making connections to policy optimization and regularization in continuous-time RL. To carry out this idea, we lay out a new policy optimization framework for continuous-time RL, and illustrate its potential in enhancing the value networks design space via leveraging the structural property of diffusion models. We validate the advantages of our method by experiments in downstream tasks of fine-tuning large-scale Text2Image models of Stable Diffusion v1.5.