 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgei-Code V2: An Autoregressive Generation Framework over Vision, Language, and Speech Data
May 21, 2023



The convergence of text, visual, and audio data is a key step towards human-like artificial intelligence, however the current Vision-Language-Speech landscape is dominated by encoder-only models which lack generative abilities. We propose closing this gap with i-Code V2, the first model capable of generating natural language from any combination of Vision, Language, and Speech data. i-Code V2 is an integrative system that leverages state-of-the-art single-modality encoders, combining their outputs with a new modality-fusing encoder in order to flexibly project combinations of modalities into a shared representational space. Next, language tokens are generated from these representations via an autoregressive decoder. The whole framework is pretrained end-to-end on a large collection of dual- and single-modality datasets using a novel text completion objective that can be generalized across arbitrary combinations of modalities. i-Code V2 matches or outperforms state-of-the-art single- and dual-modality baselines on 7 multimodal tasks, demonstrating the power of generative multimodal pretraining across a diversity of tasks and signals.
Factual Consistency Oriented Speech Recognition
Feb 24, 2023This paper presents a novel optimization framework for automatic speech recognition (ASR) with the aim of reducing hallucinations produced by an ASR model. The proposed framework optimizes the ASR model to maximize an expected factual consistency score between ASR hypotheses and ground-truth transcriptions, where the factual consistency score is computed by a separately trained estimator. Experimental results using the AMI meeting corpus and the VoxPopuli corpus show that the ASR model trained with the proposed framework generates ASR hypotheses that have significantly higher consistency scores with ground-truth transcriptions while maintaining the word error rates close to those of cross entropy-trained ASR models. Furthermore, it is shown that training the ASR models with the proposed framework improves the speech summarization quality as measured by the factual consistency of meeting conversation summaries generated by a large language model.
Simulating realistic speech overlaps improves multi-talker ASR
Nov 17, 2022Multi-talker automatic speech recognition (ASR) has been studied to generate transcriptions of natural conversation including overlapping speech of multiple speakers. Due to the difficulty in acquiring real conversation data with high-quality human transcriptions, a na\"ive simulation of multi-talker speech by randomly mixing multiple utterances was conventionally used for model training. In this work, we propose an improved technique to simulate multi-talker overlapping speech with realistic speech overlaps, where an arbitrary pattern of speech overlaps is represented by a sequence of discrete tokens. With this representation, speech overlapping patterns can be learned from real conversations based on a statistical language model, such as N-gram, which can be then used to generate multi-talker speech for training. In our experiments, multi-talker ASR models trained with the proposed method show consistent improvement on the word error rates across multiple datasets.
Breaking trade-offs in speech separation with sparsely-gated mixture of experts
Nov 11, 2022Several trade-offs need to be balanced when employing monaural speech separation (SS) models in conversational automatic speech recognition (ASR) systems. A larger SS model generally achieves better output quality at an expense of higher computation, meanwhile, a better SS model for overlapping speech often produces distorted output for non-overlapping speech. This paper addresses these trade-offs with a sparsely-gated mixture-of-experts (MoE). The sparsely-gated MoE architecture allows the separation models to be enlarged without compromising the run-time efficiency, which also helps achieve a better separation-distortion trade-off. To further reduce the speech distortion without compromising the SS capability, a multi-gate MoE framework is also explored, where different gates handle non-overlapping and overlapping frames differently. ASR experiments are conducted by using a simulated dataset for measuring both the speech separation accuracy and the speech distortion. Two advanced SS models, Conformer and WavLM-based models, are used as baselines. The sparsely-gated MoE models show a superior SS capability with less speech distortion, meanwhile marginally increasing the run-time computational cost. Experimental results using real conversation recordings are also presented, showing MoE's effectiveness in an end-to-end evaluation setting.
Self-supervised learning with bi-label masked speech prediction for streaming multi-talker speech recognition
Nov 10, 2022



Self-supervised learning (SSL), which utilizes the input data itself for representation learning, has achieved state-of-the-art results for various downstream speech tasks. However, most of the previous studies focused on offline single-talker applications, with limited investigations in multi-talker cases, especially for streaming scenarios. In this paper, we investigate SSL for streaming multi-talker speech recognition, which generates transcriptions of overlapping speakers in a streaming fashion. We first observe that conventional SSL techniques do not work well on this task due to the poor representation of overlapping speech. We then propose a novel SSL training objective, referred to as bi-label masked speech prediction, which explicitly preserves representations of all speakers in overlapping speech. We investigate various aspects of the proposed system including data configuration and quantizer selection. The proposed SSL setup achieves substantially better word error rates on the LibriSpeechMix dataset.
Speech separation with large-scale self-supervised learning
Nov 09, 2022Self-supervised learning (SSL) methods such as WavLM have shown promising speech separation (SS) results in small-scale simulation-based experiments. In this work, we extend the exploration of the SSL-based SS by massively scaling up both the pre-training data (more than 300K hours) and fine-tuning data (10K hours). We also investigate various techniques to efficiently integrate the pre-trained model with the SS network under a limited computation budget, including a low frame rate SSL model training setup and a fine-tuning scheme using only the part of the pre-trained model. Compared with a supervised baseline and the WavLM-based SS model using feature embeddings obtained with the previously released 94K hours trained WavLM, our proposed model obtains 15.9% and 11.2% of relative word error rate (WER) reductions, respectively, for a simulated far-field speech mixture test set. For conversation transcription on real meeting recordings using continuous speech separation, the proposed model achieves 6.8% and 10.6% of relative WER reductions over the purely supervised baseline on AMI and ICSI evaluation sets, respectively, while reducing the computational cost by 38%.
VarArray Meets t-SOT: Advancing the State of the Art of Streaming Distant Conversational Speech Recognition
Sep 12, 2022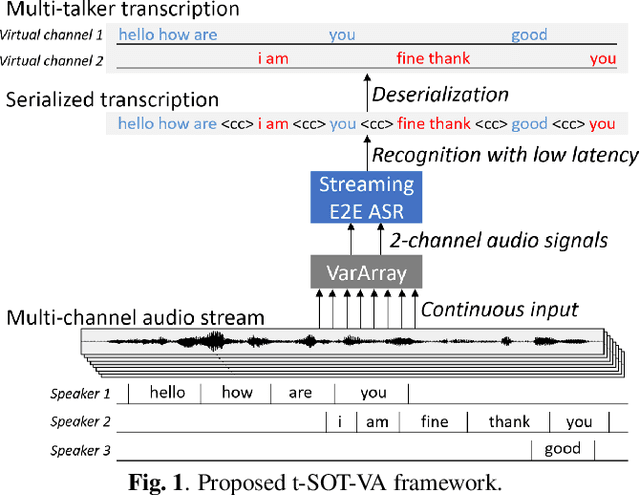
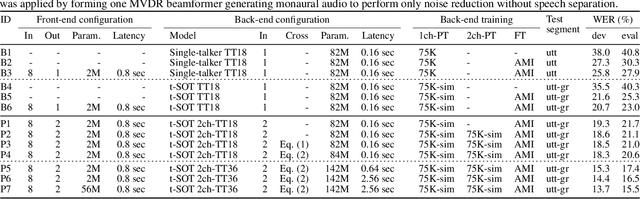
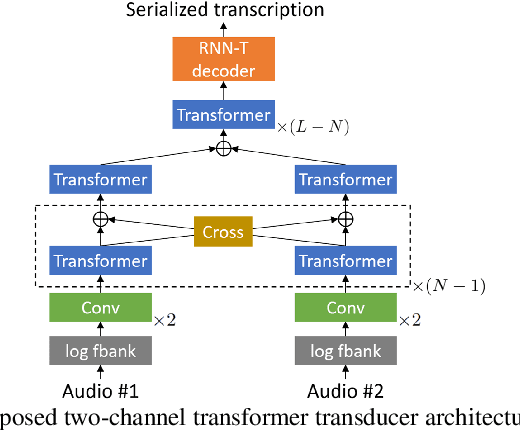

This paper presents a novel streaming automatic speech recognition (ASR) framework for multi-talker overlapping speech captured by a distant microphone array with an arbitrary geometry. Our framework, named t-SOT-VA, capitalizes on independently developed two recent technologies; array-geometry-agnostic continuous speech separation, or VarArray, and streaming multi-talker ASR based on token-level serialized output training (t-SOT). To combine the best of both technologies, we newly design a t-SOT-based ASR model that generates a serialized multi-talker transcription based on two separated speech signals from VarArray. We also propose a pre-training scheme for such an ASR model where we simulate VarArray's output signals based on monaural single-talker ASR training data. Conversation transcription experiments using the AMI meeting corpus show that the system based on the proposed framework significantly outperforms conventional ones. Our system achieves the state-of-the-art word error rates of 13.7% and 15.5% for the AMI development and evaluation sets, respectively, in the multiple-distant-microphone setting while retaining the streaming inference capability.
Target Speaker Voice Activity Detection with Transformers and Its Integration with End-to-End Neural Diarization
Aug 27, 2022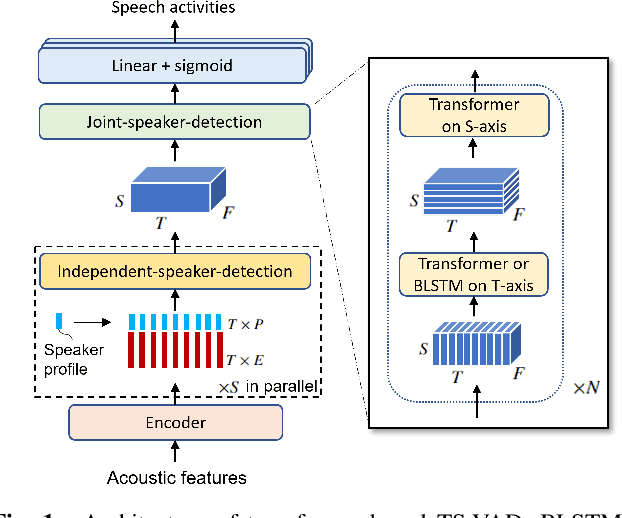
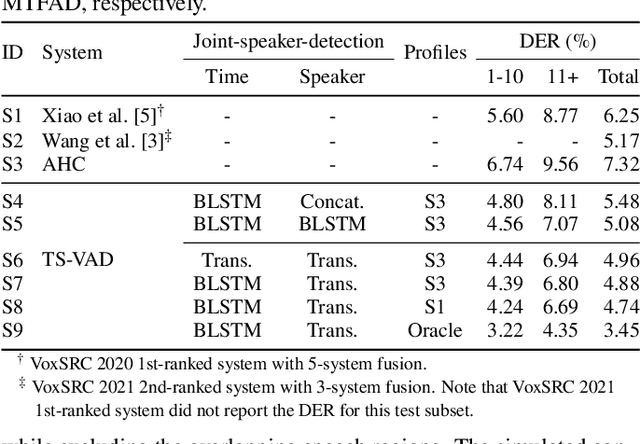
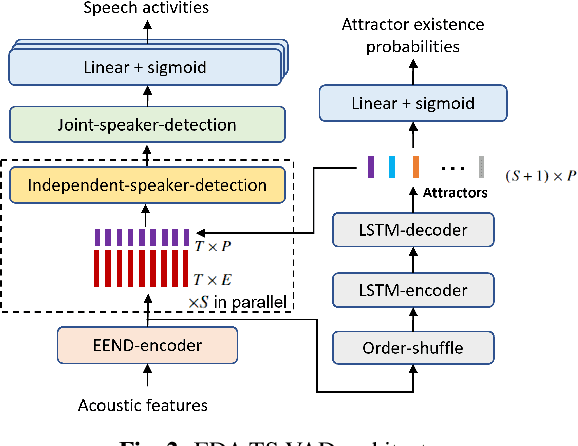
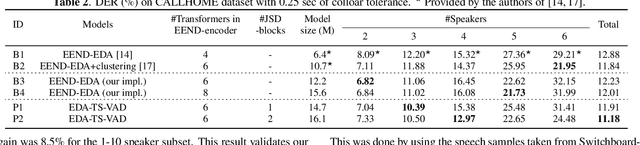
This paper describes a speaker diarization model based on target speaker voice activity detection (TS-VAD) using transformers. To overcome the original TS-VAD model's drawback of being unable to handle an arbitrary number of speakers, we investigate model architectures that use input tensors with variable-length time and speaker dimensions. Transformer layers are applied to the speaker axis to make the model output insensitive to the order of the speaker profiles provided to the TS-VAD model. Time-wise sequential layers are interspersed between these speaker-wise transformer layers to allow the temporal and cross-speaker correlations of the input speech signal to be captured. We also extend a diarization model based on end-to-end neural diarization with encoder-decoder based attractors (EEND-EDA) by replacing its dot-product-based speaker detection layer with the transformer-based TS-VAD. Experimental results on VoxConverse show that using the transformers for the cross-speaker modeling reduces the diarization error rate (DER) of TS-VAD by 10.9%, achieving a new state-of-the-art (SOTA) DER of 4.74%. Also, our extended EEND-EDA reduces DER by 6.9% on the CALLHOME dataset relative to the original EEND-EDA with a similar model size, achieving a new SOTA DER of 11.18% under a widely used training data setting.
i-Code: An Integrative and Composable Multimodal Learning Framework
May 05, 2022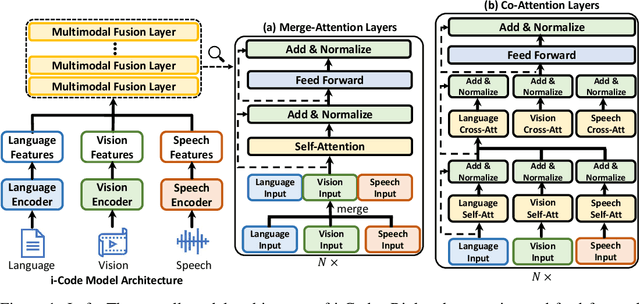
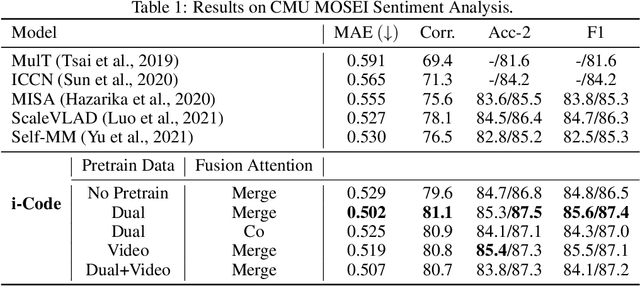
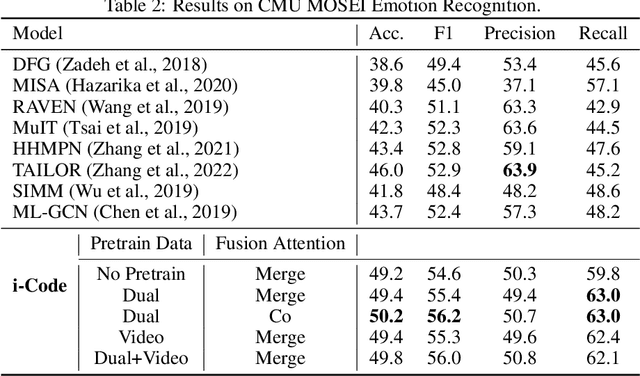

Human intelligence is multimodal; we integrate visual, linguistic, and acoustic signals to maintain a holistic worldview. Most current pretraining methods, however, are limited to one or two modalities. We present i-Code, a self-supervised pretraining framework where users may flexibly combine the modalities of vision, speech, and language into unified and general-purpose vector representations. In this framework, data from each modality are first given to pretrained single-modality encoders. The encoder outputs are then integrated with a multimodal fusion network, which uses novel attention mechanisms and other architectural innovations to effectively combine information from the different modalities. The entire system is pretrained end-to-end with new objectives including masked modality unit modeling and cross-modality contrastive learning. Unlike previous research using only video for pretraining, the i-Code framework can dynamically process single, dual, and triple-modality data during training and inference, flexibly projecting different combinations of modalities into a single representation space. Experimental results demonstrate how i-Code can outperform state-of-the-art techniques on five video understanding tasks and the GLUE NLP benchmark, improving by as much as 11% and demonstrating the power of integrative multimodal pretraining.
Leveraging Real Conversational Data for Multi-Channel Continuous Speech Separation
Apr 07, 2022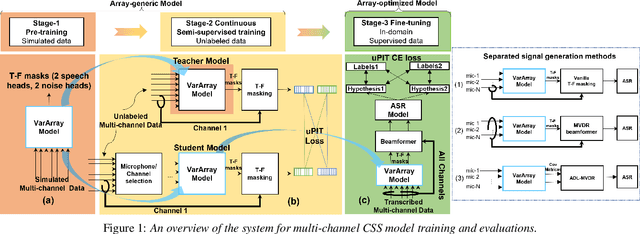
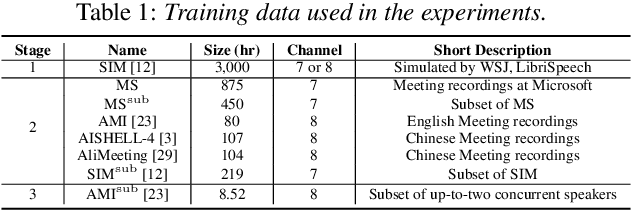
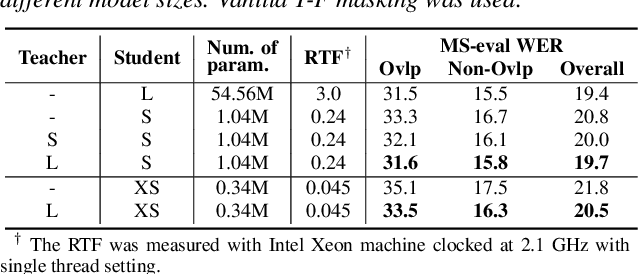

Existing multi-channel continuous speech separation (CSS) models are heavily dependent on supervised data - either simulated data which causes data mismatch between the training and real-data testing, or the real transcribed overlapping data, which is difficult to be acquired, hindering further improvements in the conversational/meeting transcription tasks. In this paper, we propose a three-stage training scheme for the CSS model that can leverage both supervised data and extra large-scale unsupervised real-world conversational data. The scheme consists of two conventional training approaches -- pre-training using simulated data and ASR-loss-based training using transcribed data -- and a novel continuous semi-supervised training between the two, in which the CSS model is further trained by using real data based on the teacher-student learning framework. We apply this scheme to an array-geometry-agnostic CSS model, which can use the multi-channel data collected from any microphone array. Large-scale meeting transcription experiments are carried out on both Microsoft internal meeting data and the AMI meeting corpus. The steady improvement by each training stage has been observed, showing the effect of the proposed method that enables leveraging real conversational data for CSS model training.