 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic R-CNN: Towards High Quality Object Detection via Dynamic Training
Apr 13, 2020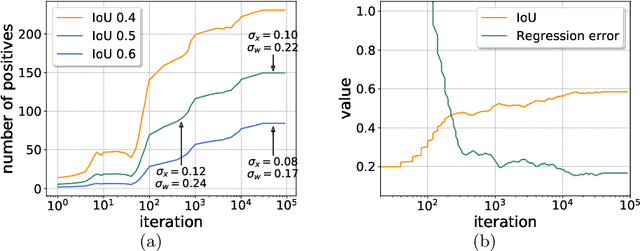
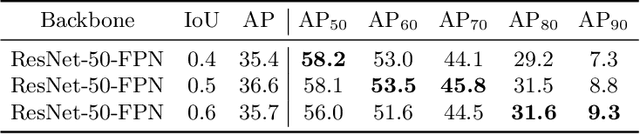
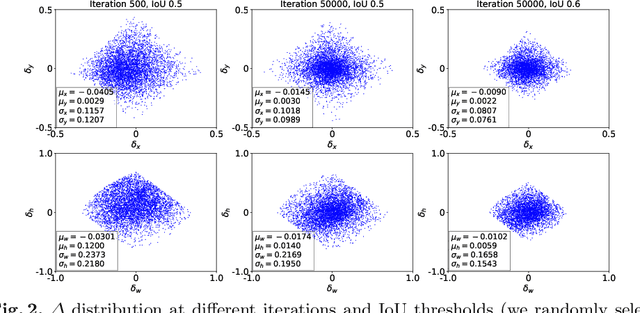
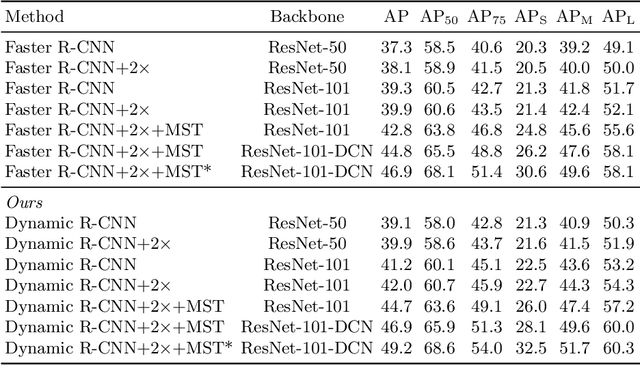
Although two-stage object detectors have continuously advanced the state-of-the-art performance in recent years, the training process itself is far from crystal. In this work, we first point out the inconsistency problem between the fixed network settings and the dynamic training procedure, which greatly affects the performance. For example, the fixed label assignment strategy and regression loss function cannot fit the distribution change of proposals and thus are harmful to training high quality detectors. Consequently, we propose Dynamic R-CNN to adjust the label assignment criteria (IoU threshold) and the shape of regression loss function (parameters of SmoothL1 Loss) automatically based on the statistics of proposals during training. This dynamic design makes better use of the training samples and pushes the detector to fit more high quality samples. Specifically, our method improves upon ResNet-50-FPN baseline with 1.9% AP and 5.5% AP$_{90}$ on the MS COCO dataset with no extra overhead. Codes and models are available at https://github.com/hkzhang95/DynamicRCNN.
DMLO: Deep Matching LiDAR Odometry
Apr 09, 2020
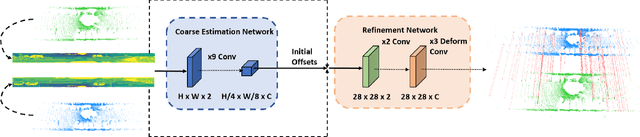
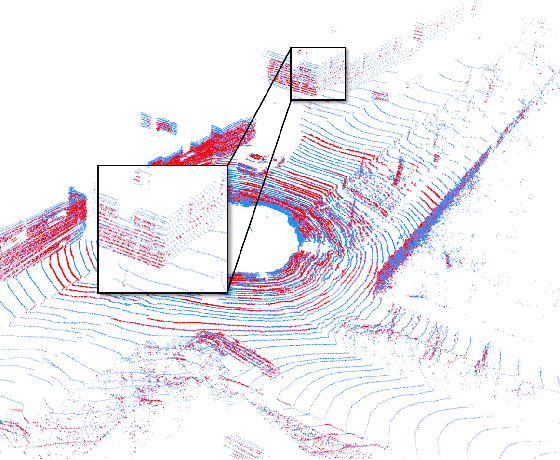

LiDAR odometry is a fundamental task for various areas such as robotics, autonomous driving. This problem is difficult since it requires the systems to be highly robust running in noisy real-world data. Existing methods are mostly local iterative methods. Feature-based global registration methods are not preferred since extracting accurate matching pairs in the nonuniform and sparse LiDAR data remains challenging. In this paper, we present Deep Matching LiDAR Odometry (DMLO), a novel learning-based framework which makes the feature matching method applicable to LiDAR odometry task. Unlike many recent learning-based methods, DMLO explicitly enforces geometry constraints in the framework. Specifically, DMLO decomposes the 6-DoF pose estimation into two parts, a learning-based matching network which provides accurate correspondences between two scans and rigid transformation estimation with a close-formed solution by Singular Value Decomposition (SVD). Comprehensive experimental results on real-world datasets KITTI and Argoverse demonstrate that our DMLO dramatically outperforms existing learning-based methods and comparable with the state-of-the-art geometry based approaches.
Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video
Oct 03, 2019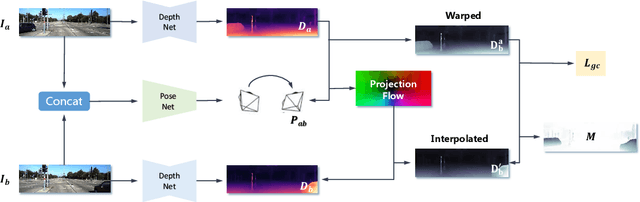



Recent work has shown that CNN-based depth and ego-motion estimators can be learned using unlabelled monocular videos. However, the performance is limited by unidentified moving objects that violate the underlying static scene assumption in geometric image reconstruction. More significantly, due to lack of proper constraints, networks output scale-inconsistent results over different samples, i.e., the ego-motion network cannot provide full camera trajectories over a long video sequence because of the per-frame scale ambiguity. This paper tackles these challenges by proposing a geometry consistency loss for scale-consistent predictions and an induced self-discovered mask for handling moving objects and occlusions. Since we do not leverage multi-task learning like recent works, our framework is much simpler and more efficient. Comprehensive evaluation results demonstrate that our depth estimator achieves the state-of-the-art performance on the KITTI dataset. Moreover, we show that our ego-motion network is able to predict a globally scale-consistent camera trajectory for long video sequences, and the resulting visual odometry accuracy is competitive with the recent model that is trained using stereo videos. To the best of our knowledge, this is the first work to show that deep networks trained using unlabelled monocular videos can predict globally scale-consistent camera trajectories over a long video sequence.
Cross View Fusion for 3D Human Pose Estimation
Sep 03, 2019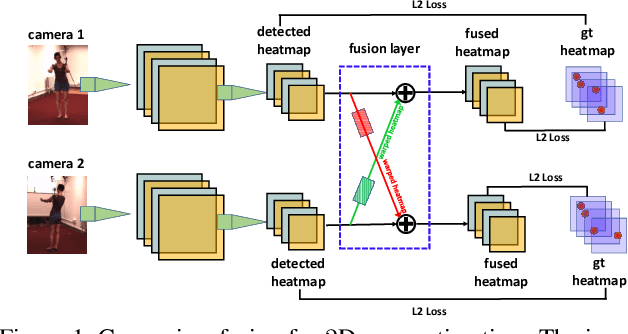
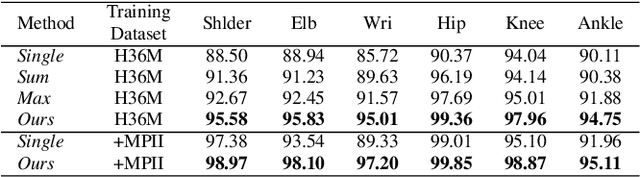
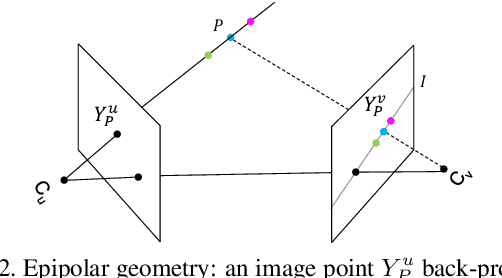
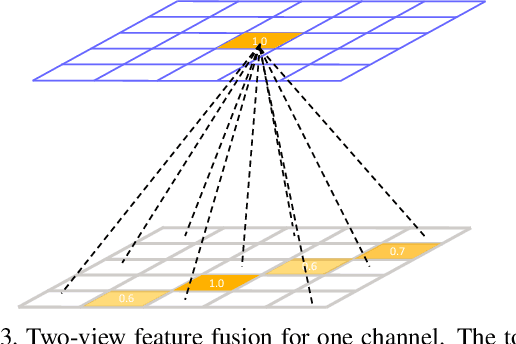
We present an approach to recover absolute 3D human poses from multi-view images by incorporating multi-view geometric priors in our model. It consists of two separate steps: (1) estimating the 2D poses in multi-view images and (2) recovering the 3D poses from the multi-view 2D poses. First, we introduce a cross-view fusion scheme into CNN to jointly estimate 2D poses for multiple views. Consequently, the 2D pose estimation for each view already benefits from other views. Second, we present a recursive Pictorial Structure Model to recover the 3D pose from the multi-view 2D poses. It gradually improves the accuracy of 3D pose with affordable computational cost. We test our method on two public datasets H36M and Total Capture. The Mean Per Joint Position Errors on the two datasets are 26mm and 29mm, which outperforms the state-of-the-arts remarkably (26mm vs 52mm, 29mm vs 35mm). Our code is released at \url{https://github.com/microsoft/multiview-human-pose-estimation-pytorch}.
Sequence Level Semantics Aggregation for Video Object Detection
Aug 20, 2019
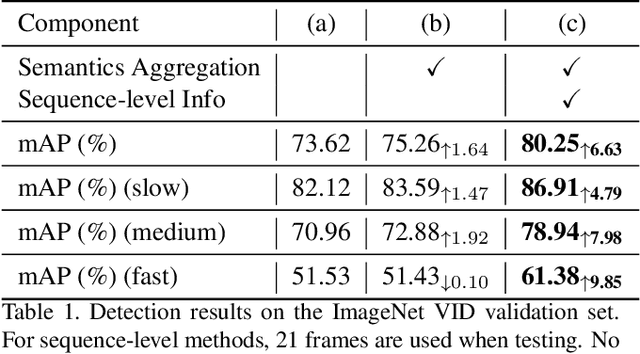
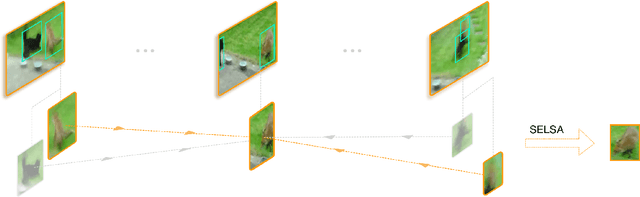

Video objection detection (VID) has been a rising research direction in recent years. A central issue of VID is the appearance degradation of video frames caused by fast motion. This problem is essentially ill-posed for a single frame. Therefore, aggregating features from other frames becomes a natural choice. Existing methods rely heavily on optical flow or recurrent neural networks for feature aggregation. However, these methods emphasize more on the temporally nearby frames. In this work, we argue that aggregating features in the full-sequence level will lead to more discriminative and robust features for video object detection. To achieve this goal, we devise a novel Sequence Level Semantics Aggregation (SELSA) module. We further demonstrate the close relationship between the proposed method and the classic spectral clustering method, providing a novel view for understanding the VID problem. We test the proposed method on the ImageNet VID and the EPIC KITCHENS dataset and achieve new state-of-the-art results. Our method does not need complicated postprocessing methods such as Seq-NMS or Tubelet rescoring, which keeps the pipeline simple and clean.
Revisiting Feature Alignment for One-stage Object Detection
Aug 05, 2019
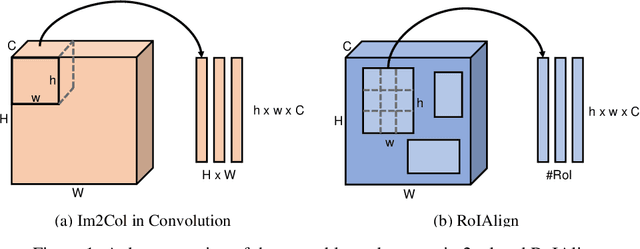
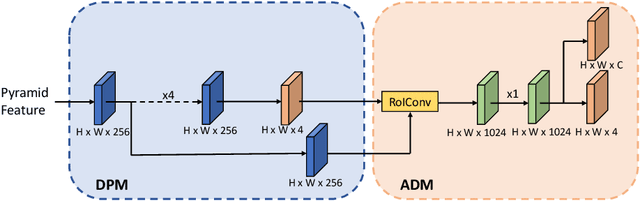

Recently, one-stage object detectors gain much attention due to their simplicity in practice. Its fully convolutional nature greatly reduces the difficulty of training and deployment compared with two-stage detectors which require NMS and sorting for the proposal stage. However, a fundamental issue lies in all one-stage detectors is the misalignment between anchor boxes and convolutional features, which significantly hinders the performance of one-stage detectors. In this work, we first reveal the deep connection between the widely used im2col operator and the RoIAlign operator. Guided by this illuminating observation, we propose a RoIConv operator which aligns the features and its corresponding anchors in one-stage detection in a principled way. We then design a fully convolutional AlignDet architecture which combines the flexibility of learned anchors and the preciseness of aligned features. Specifically, our AlignDet achieves a state-of-the-art mAP of 44.1 on the COCO test-dev with ResNeXt-101 backbone.
SimpleDet: A Simple and Versatile Distributed Framework for Object Detection and Instance Recognition
Mar 14, 2019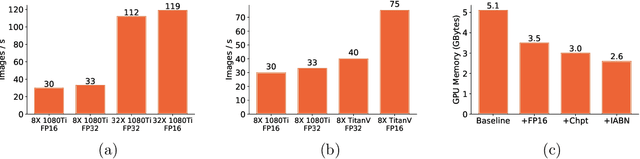

Object detection and instance recognition play a central role in many AI applications like autonomous driving, video surveillance and medical image analysis. However, training object detection models on large scale datasets remains computationally expensive and time consuming. This paper presents an efficient and open source object detection framework called SimpleDet which enables the training of state-of-the-art detection models on consumer grade hardware at large scale. SimpleDet supports up-to-date detection models with best practice. SimpleDet also supports distributed training with near linear scaling out of box. Codes, examples and documents of SimpleDet can be found at https://github.com/tusimple/simpledet .
Scale-Aware Trident Networks for Object Detection
Jan 07, 2019
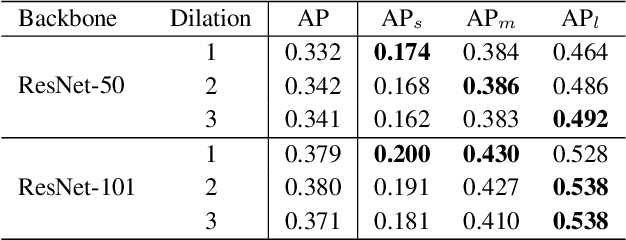
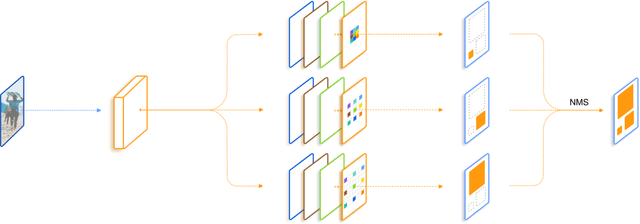
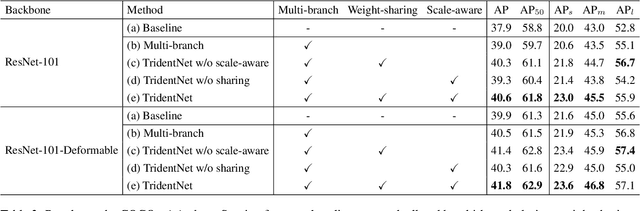
Scale variation is one of the key challenges in object detection. In this work, we first present a controlled experiment to investigate the effect of receptive fields on the detection of different scale objects. Based on the findings from the exploration experiments, we propose a novel Trident Network (TridentNet) aiming to generate scale-specific feature maps with a uniform representational power. We construct a parallel multi-branch architecture in which each branch shares the same transformation parameters but with different receptive fields. Then, we propose a scale-aware training scheme to specialize each branch by sampling object instances of proper scales for training. As a bonus, a fast approximation version of TridentNet could achieve significant improvements without any additional parameters and computational cost. On the COCO dataset, our TridentNet with ResNet-101 backbone achieves state-of-the-art single-model results by obtaining an mAP of 48.4. Code will be made publicly available.
Spectral Feature Transformation for Person Re-identification
Nov 28, 2018

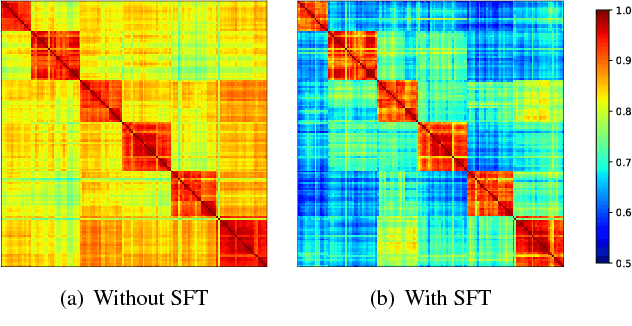
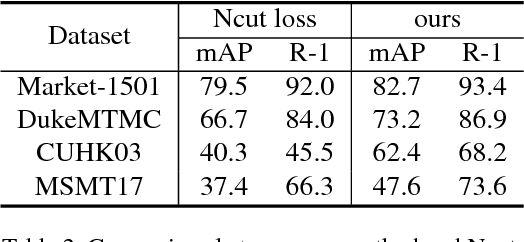
With the surge of deep learning techniques, the field of person re-identification has witnessed rapid progress in recent years. Deep learning based methods focus on learning a feature space where samples are clustered compactly according to their corresponding identities. Most existing methods rely on powerful CNNs to transform the samples individually. In contrast, we propose to consider the sample relations in the transformation. To achieve this goal, we incorporate spectral clustering technique into CNN. We derive a novel module named Spectral Feature Transformation and seamlessly integrate it into existing CNN pipeline with negligible cost,which makes our method enjoy the best of two worlds. Empirical studies show that the proposed approach outperforms previous state-of-the-art methods on four public benchmarks by a considerable margin without bells and whistles.
You Only Search Once: Single Shot Neural Architecture Search via Direct Sparse Optimization
Nov 05, 2018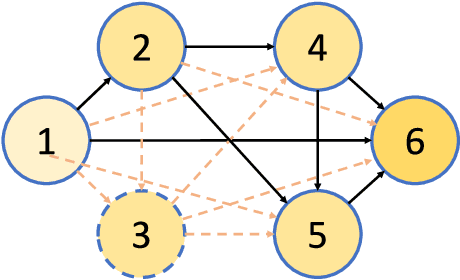
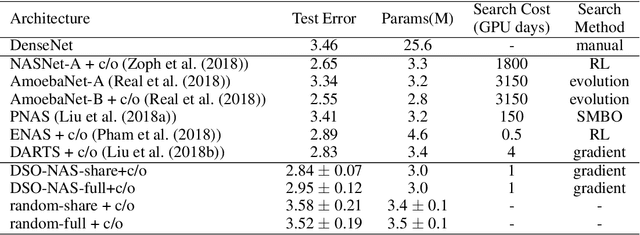
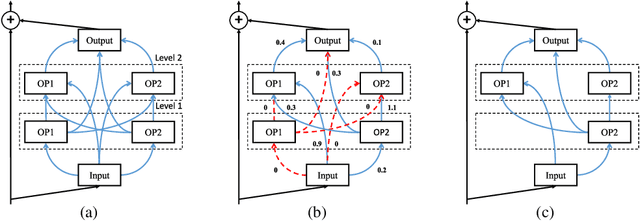
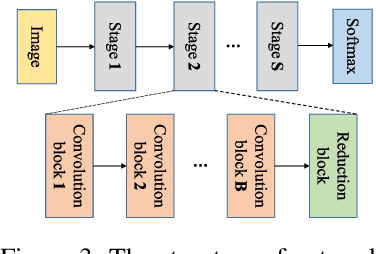
Recently Neural Architecture Search (NAS) has aroused great interest in both academia and industry, however it remains challenging because of its huge and non-continuous search space. Instead of applying evolutionary algorithm or reinforcement learning as previous works, this paper proposes a Direct Sparse Optimization NAS (DSO-NAS) method. In DSO-NAS, we provide a novel model pruning view to NAS problem. In specific, we start from a completely connected block, and then introduce scaling factors to scale the information flow between operations. Next, we impose sparse regularizations to prune useless connections in the architecture. Lastly, we derive an efficient and theoretically sound optimization method to solve it. Our method enjoys both advantages of differentiability and efficiency, therefore can be directly applied to large datasets like ImageNet. Particularly, On CIFAR-10 dataset, DSO-NAS achieves an average test error 2.84\%, while on the ImageNet dataset DSO-NAS achieves 25.4\% test error under 600M FLOPs with 8 GPUs in 18 hours.