 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntriguing Properties of Vision Transformers
Jun 08, 2021



Vision transformers (ViT) have demonstrated impressive performance across various machine vision problems. These models are based on multi-head self-attention mechanisms that can flexibly attend to a sequence of image patches to encode contextual cues. An important question is how such flexibility in attending image-wide context conditioned on a given patch can facilitate handling nuisances in natural images e.g., severe occlusions, domain shifts, spatial permutations, adversarial and natural perturbations. We systematically study this question via an extensive set of experiments encompassing three ViT families and comparisons with a high-performing convolutional neural network (CNN). We show and analyze the following intriguing properties of ViT: (a) Transformers are highly robust to severe occlusions, perturbations and domain shifts, e.g., retain as high as 60% top-1 accuracy on ImageNet even after randomly occluding 80% of the image content. (b) The robust performance to occlusions is not due to a bias towards local textures, and ViTs are significantly less biased towards textures compared to CNNs. When properly trained to encode shape-based features, ViTs demonstrate shape recognition capability comparable to that of human visual system, previously unmatched in the literature. (c) Using ViTs to encode shape representation leads to an interesting consequence of accurate semantic segmentation without pixel-level supervision. (d) Off-the-shelf features from a single ViT model can be combined to create a feature ensemble, leading to high accuracy rates across a range of classification datasets in both traditional and few-shot learning paradigms. We show effective features of ViTs are due to flexible and dynamic receptive fields possible via the self-attention mechanism.
On Generating Transferable Targeted Perturbations
Mar 26, 2021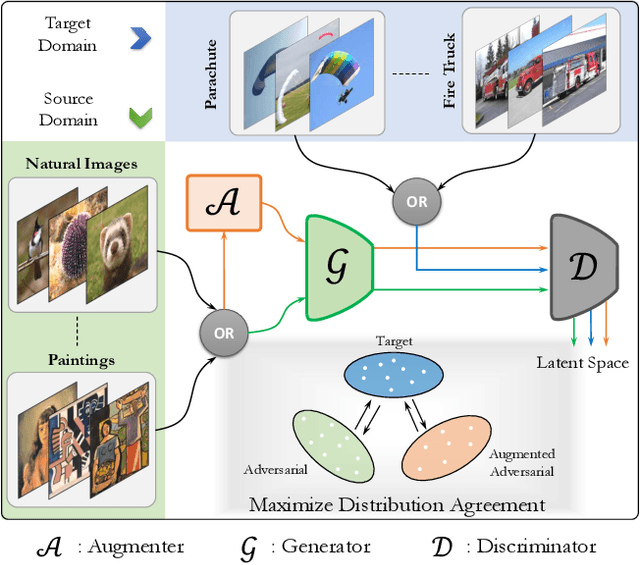
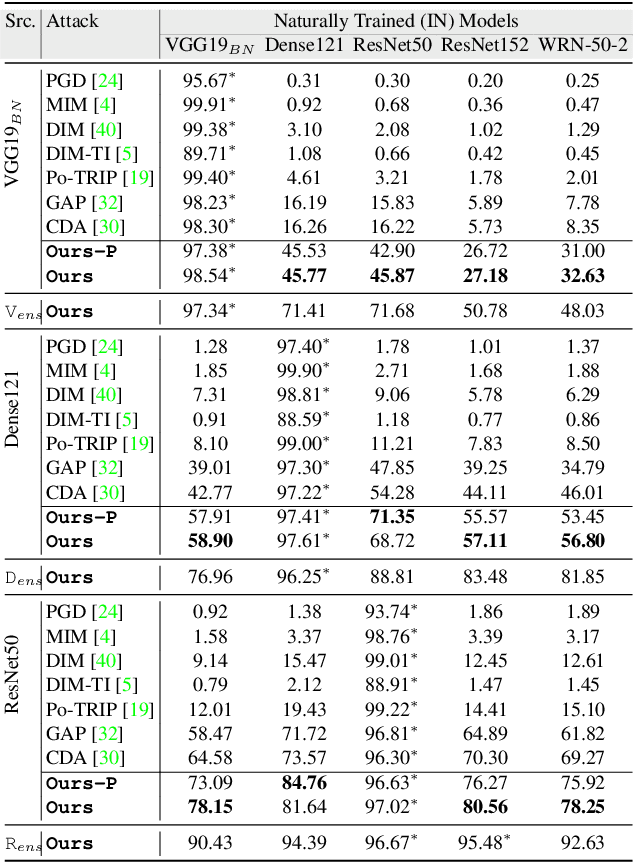

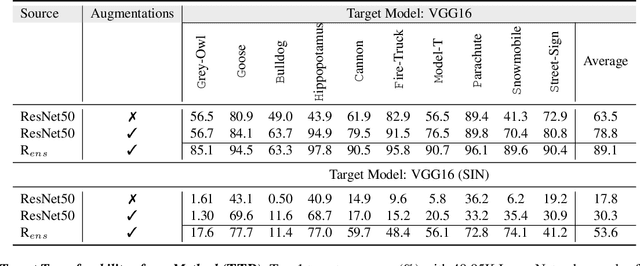
While the untargeted black-box transferability of adversarial perturbations has been extensively studied before, changing an unseen model's decisions to a specific `targeted' class remains a challenging feat. In this paper, we propose a new generative approach for highly transferable targeted perturbations (\ours). We note that the existing methods are less suitable for this task due to their reliance on class-boundary information that changes from one model to another, thus reducing transferability. In contrast, our approach matches the perturbed image `distribution' with that of the target class, leading to high targeted transferability rates. To this end, we propose a new objective function that not only aligns the global distributions of source and target images, but also matches the local neighbourhood structure between the two domains. Based on the proposed objective, we train a generator function that can adaptively synthesize perturbations specific to a given input. Our generative approach is independent of the source or target domain labels, while consistently performs well against state-of-the-art methods on a wide range of attack settings. As an example, we achieve $32.63\%$ target transferability from (an adversarially weak) VGG19$_{BN}$ to (a strong) WideResNet on ImageNet val. set, which is 4$\times$ higher than the previous best generative attack and 16$\times$ better than instance-specific iterative attack. Code is available at: {\small\url{https://github.com/Muzammal-Naseer/TTP}}.
Orthogonal Projection Loss
Mar 25, 2021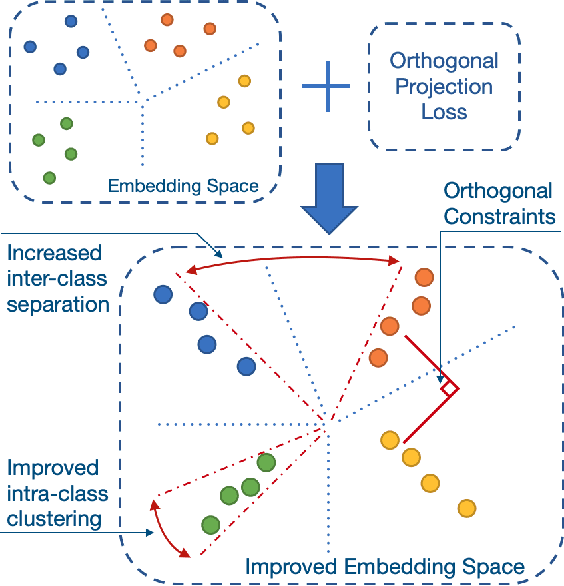
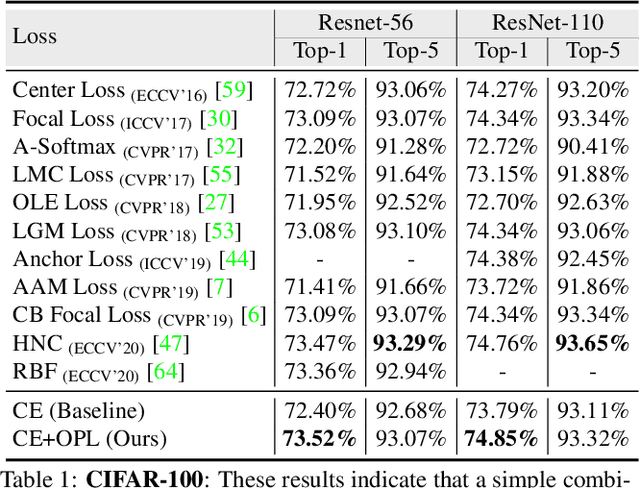
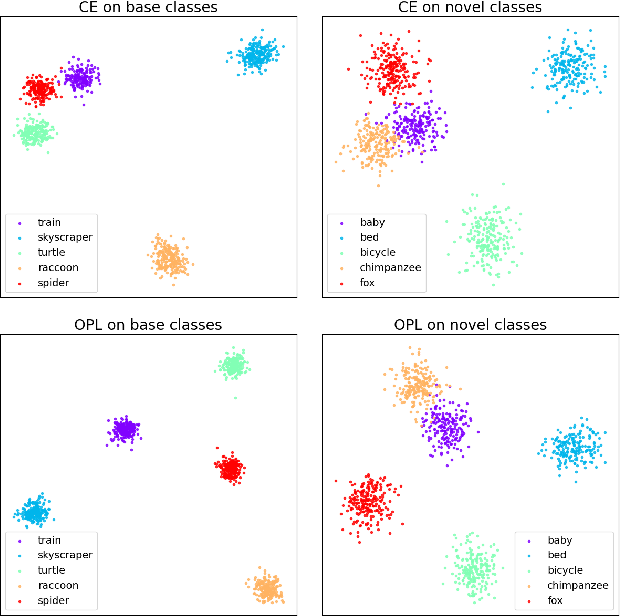
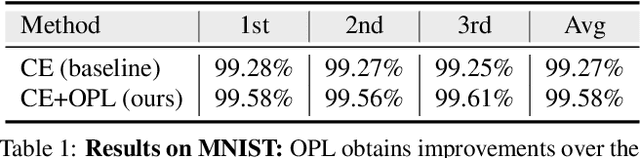
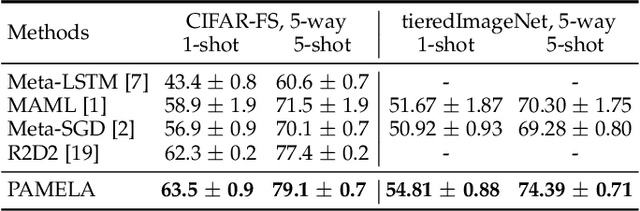
Deep neural networks have achieved remarkable performance on a range of classification tasks, with softmax cross-entropy (CE) loss emerging as the de-facto objective function. The CE loss encourages features of a class to have a higher projection score on the true class-vector compared to the negative classes. However, this is a relative constraint and does not explicitly force different class features to be well-separated. Motivated by the observation that ground-truth class representations in CE loss are orthogonal (one-hot encoded vectors), we develop a novel loss function termed `Orthogonal Projection Loss' (OPL) which imposes orthogonality in the feature space. OPL augments the properties of CE loss and directly enforces inter-class separation alongside intra-class clustering in the feature space through orthogonality constraints on the mini-batch level. As compared to other alternatives of CE, OPL offers unique advantages e.g., no additional learnable parameters, does not require careful negative mining and is not sensitive to the batch size. Given the plug-and-play nature of OPL, we evaluate it on a diverse range of tasks including image recognition (CIFAR-100), large-scale classification (ImageNet), domain generalization (PACS) and few-shot learning (miniImageNet, CIFAR-FS, tiered-ImageNet and Meta-dataset) and demonstrate its effectiveness across the board. Furthermore, OPL offers better robustness against practical nuisances such as adversarial attacks and label noise. Code is available at: https://github.com/kahnchana/opl.
Multi-Stage Progressive Image Restoration
Feb 04, 2021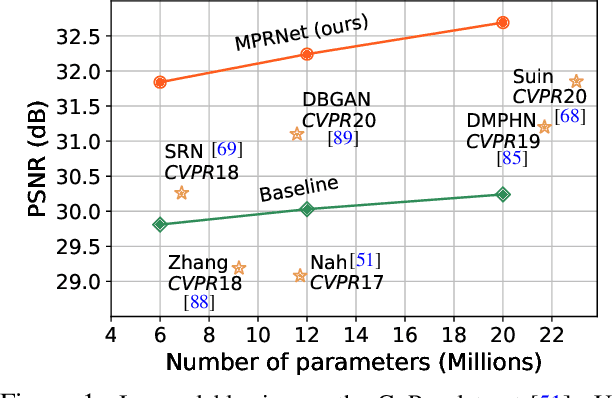

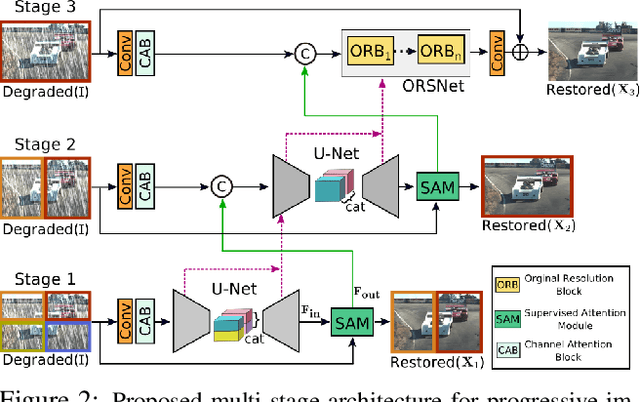
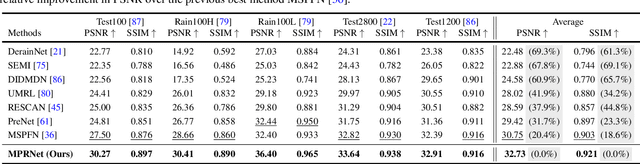
Image restoration tasks demand a complex balance between spatial details and high-level contextualized information while recovering images. In this paper, we propose a novel synergistic design that can optimally balance these competing goals. Our main proposal is a multi-stage architecture, that progressively learns restoration functions for the degraded inputs, thereby breaking down the overall recovery process into more manageable steps. Specifically, our model first learns the contextualized features using encoder-decoder architectures and later combines them with a high-resolution branch that retains local information. At each stage, we introduce a novel per-pixel adaptive design that leverages in-situ supervised attention to reweight the local features. A key ingredient in such a multi-stage architecture is the information exchange between different stages. To this end, we propose a two-faceted approach where the information is not only exchanged sequentially from early to late stages, but lateral connections between feature processing blocks also exist to avoid any loss of information. The resulting tightly interlinked multi-stage architecture, named as MPRNet, delivers strong performance gains on ten datasets across a range of tasks including image deraining, deblurring, and denoising. For example, on the Rain100L, GoPro and DND datasets, we obtain PSNR gains of 4 dB, 0.81 dB and 0.21 dB, respectively, compared to the state-of-the-art. The source code and pre-trained models are available at https://github.com/swz30/MPRNet.
Transformers in Vision: A Survey
Jan 04, 2021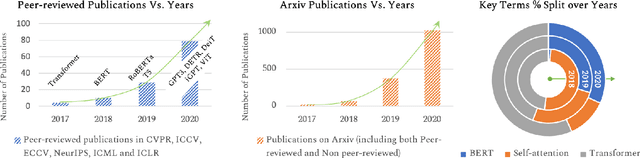
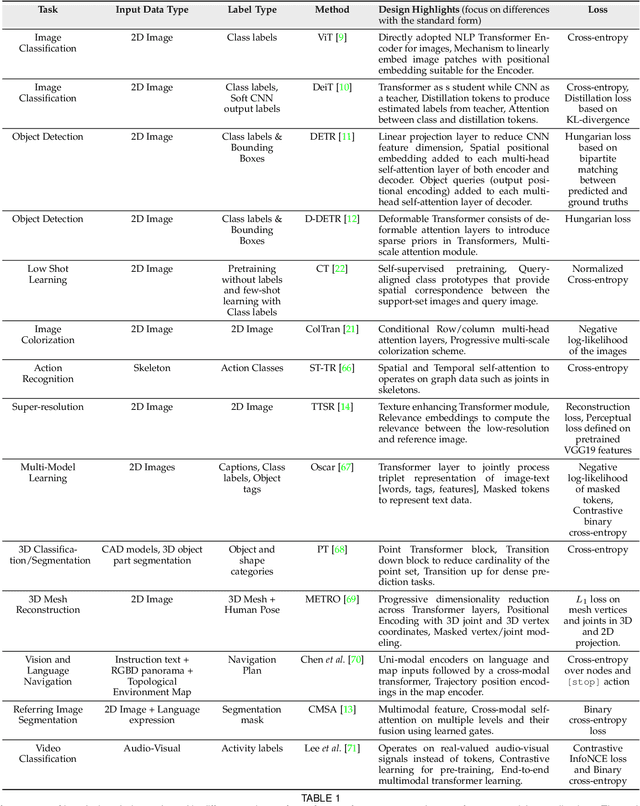
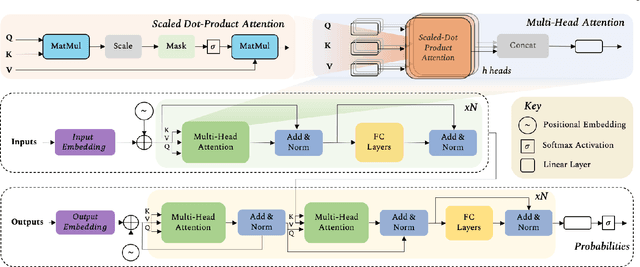
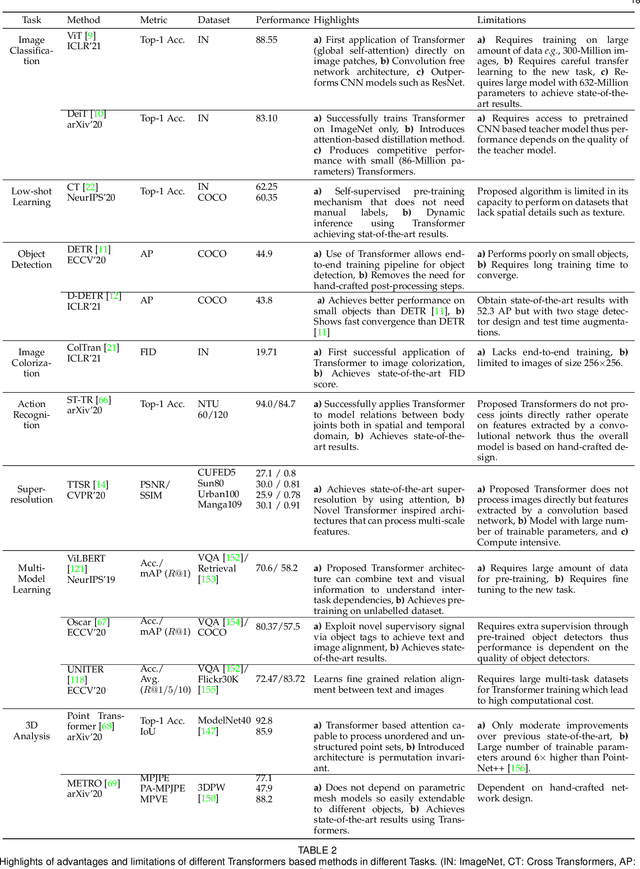
Astounding results from transformer models on natural language tasks have intrigued the vision community to study their application to computer vision problems. This has led to exciting progress on a number of tasks while requiring minimal inductive biases in the model design. This survey aims to provide a comprehensive overview of the transformer models in the computer vision discipline and assumes little to no prior background in the field. We start with an introduction to fundamental concepts behind the success of transformer models i.e., self-supervision and self-attention. Transformer architectures leverage self-attention mechanisms to encode long-range dependencies in the input domain which makes them highly expressive. Since they assume minimal prior knowledge about the structure of the problem, self-supervision using pretext tasks is applied to pre-train transformer models on large-scale (unlabelled) datasets. The learned representations are then fine-tuned on the downstream tasks, typically leading to excellent performance due to the generalization and expressivity of encoded features. We cover extensive applications of transformers in vision including popular recognition tasks (e.g., image classification, object detection, action recognition, and segmentation), generative modeling, multi-modal tasks (e.g., visual-question answering and visual reasoning), video processing (e.g., activity recognition, video forecasting), low-level vision (e.g., image super-resolution and colorization) and 3D analysis (e.g., point cloud classification and segmentation). We compare the respective advantages and limitations of popular techniques both in terms of architectural design and their experimental value. Finally, we provide an analysis on open research directions and possible future works.
Low Light Image Enhancement via Global and Local Context Modeling
Jan 04, 2021
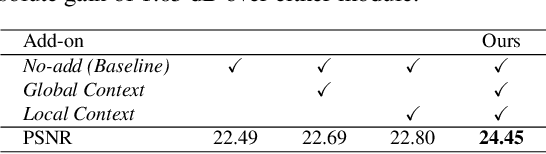
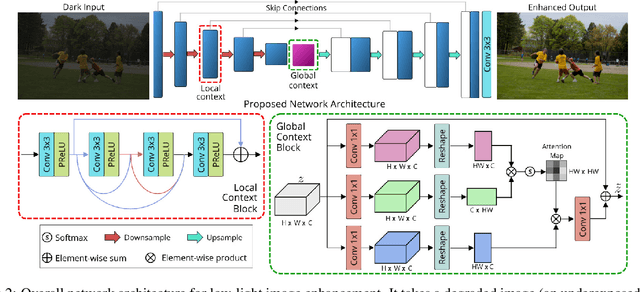

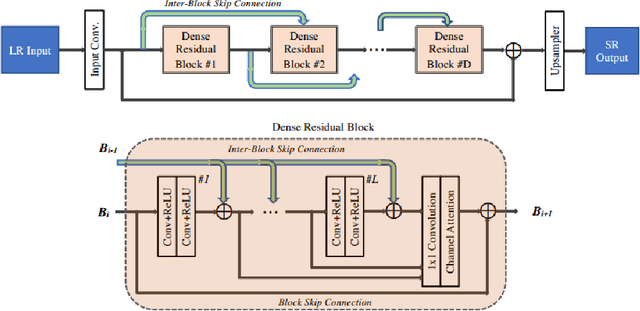
Images captured under low-light conditions manifest poor visibility, lack contrast and color vividness. Compared to conventional approaches, deep convolutional neural networks (CNNs) perform well in enhancing images. However, being solely reliant on confined fixed primitives to model dependencies, existing data-driven deep models do not exploit the contexts at various spatial scales to address low-light image enhancement. These contexts can be crucial towards inferring several image enhancement tasks, e.g., local and global contrast, brightness and color corrections; which requires cues from both local and global spatial extent. To this end, we introduce a context-aware deep network for low-light image enhancement. First, it features a global context module that models spatial correlations to find complementary cues over full spatial domain. Second, it introduces a dense residual block that captures local context with a relatively large receptive field. We evaluate the proposed approach using three challenging datasets: MIT-Adobe FiveK, LoL, and SID. On all these datasets, our method performs favorably against the state-of-the-arts in terms of standard image fidelity metrics. In particular, compared to the best performing method on the MIT-Adobe FiveK dataset, our algorithm improves PSNR from 23.04 dB to 24.45 dB.
D2-Net: Weakly-Supervised Action Localization via Discriminative Embeddings and Denoised Activations
Dec 11, 2020
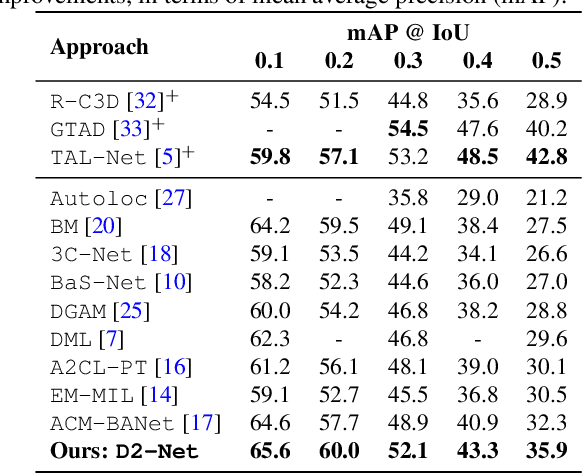
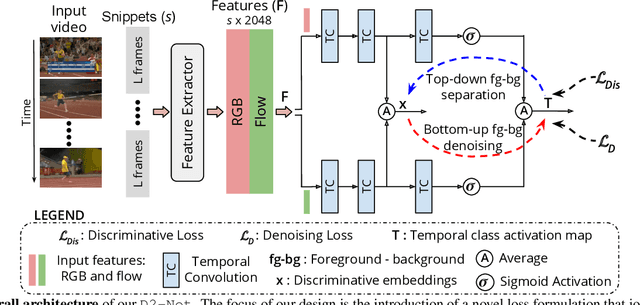
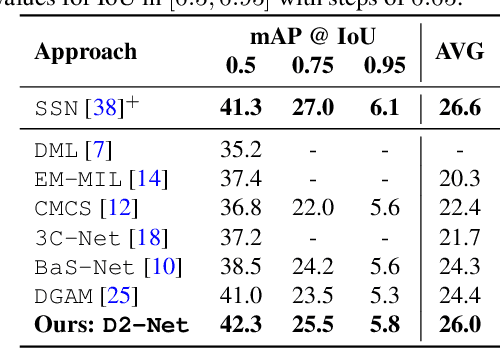
This work proposes a weakly-supervised temporal action localization framework, called D2-Net, which strives to temporally localize actions using video-level supervision. Our main contribution is the introduction of a novel loss formulation, which jointly enhances the discriminability of latent embeddings and robustness of the output temporal class activations with respect to foreground-background noise caused by weak supervision. The proposed formulation comprises a discriminative and a denoising loss term for enhancing temporal action localization. The discriminative term incorporates a classification loss and utilizes a top-down attention mechanism to enhance the separability of latent foreground-background embeddings. The denoising loss term explicitly addresses the foreground-background noise in class activations by simultaneously maximizing intra-video and inter-video mutual information using a bottom-up attention mechanism. As a result, activations in the foreground regions are emphasized whereas those in the background regions are suppressed, thereby leading to more robust predictions. Comprehensive experiments are performed on two benchmarks: THUMOS14 and ActivityNet1.2. Our D2-Net performs favorably in comparison to the existing methods on both datasets, achieving gains as high as 3.6% in terms of mean average precision on THUMOS14.
Synthesizing the Unseen for Zero-shot Object Detection
Oct 19, 2020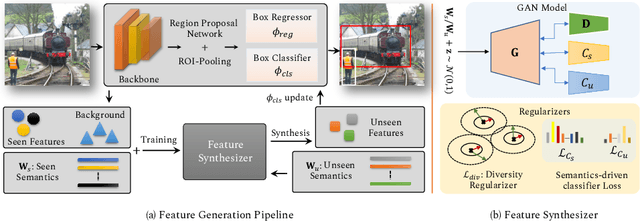
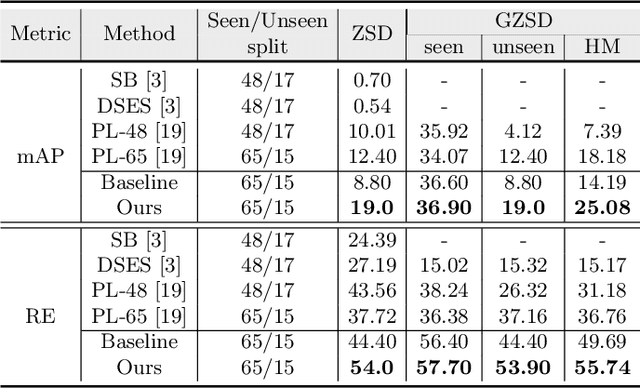
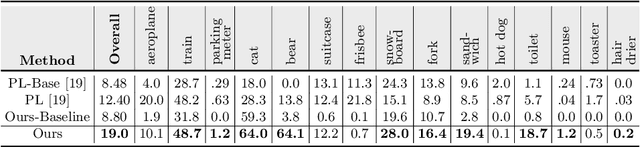
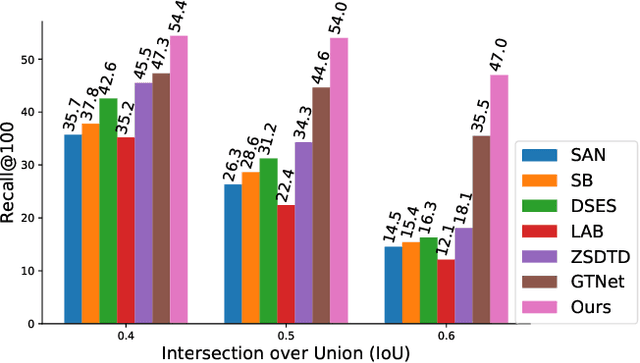
The existing zero-shot detection approaches project visual features to the semantic domain for seen objects, hoping to map unseen objects to their corresponding semantics during inference. However, since the unseen objects are never visualized during training, the detection model is skewed towards seen content, thereby labeling unseen as background or a seen class. In this work, we propose to synthesize visual features for unseen classes, so that the model learns both seen and unseen objects in the visual domain. Consequently, the major challenge becomes, how to accurately synthesize unseen objects merely using their class semantics? Towards this ambitious goal, we propose a novel generative model that uses class-semantics to not only generate the features but also to discriminatively separate them. Further, using a unified model, we ensure the synthesized features have high diversity that represents the intra-class differences and variable localization precision in the detected bounding boxes. We test our approach on three object detection benchmarks, PASCAL VOC, MSCOCO, and ILSVRC detection, under both conventional and generalized settings, showing impressive gains over the state-of-the-art methods. Our codes are available at https://github.com/nasir6/zero_shot_detection.
Meta-learning the Learning Trends Shared Across Tasks
Oct 19, 2020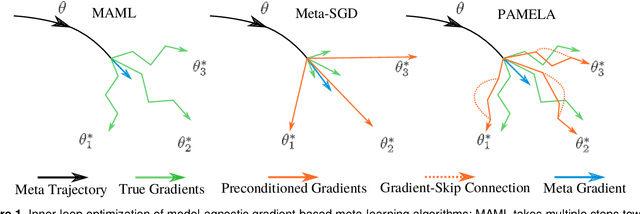

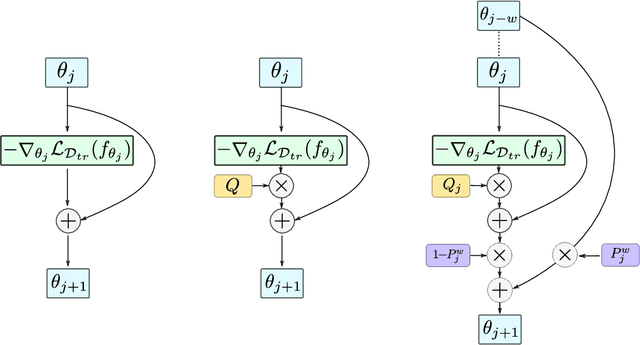
Meta-learning stands for 'learning to learn' such that generalization to new tasks is achieved. Among these methods, Gradient-based meta-learning algorithms are a specific sub-class that excel at quick adaptation to new tasks with limited data. This demonstrates their ability to acquire transferable knowledge, a capability that is central to human learning. However, the existing meta-learning approaches only depend on the current task information during the adaptation, and do not share the meta-knowledge of how a similar task has been adapted before. To address this gap, we propose a 'Path-aware' model-agnostic meta-learning approach. Specifically, our approach not only learns a good initialization for adaptation, it also learns an optimal way to adapt these parameters to a set of task-specific parameters, with learnable update directions, learning rates and, most importantly, the way updates evolve over different time-steps. Compared to the existing meta-learning methods, our approach offers: (a) The ability to learn gradient-preconditioning at different time-steps of the inner-loop, thereby modeling the dynamic learning behavior shared across tasks, and (b) The capability of aggregating the learning context through the provision of direct gradient-skip connections from the old time-steps, thus avoiding overfitting and improving generalization. In essence, our approach not only learns a transferable initialization, but also models the optimal update directions, learning rates, and task-specific learning trends. Specifically, in terms of learning trends, our approach determines the way update directions shape up as the task-specific learning progresses and how the previous update history helps in the current update. Our approach is simple to implement and demonstrates faster convergence. We report significant performance improvements on a number of FSL datasets.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020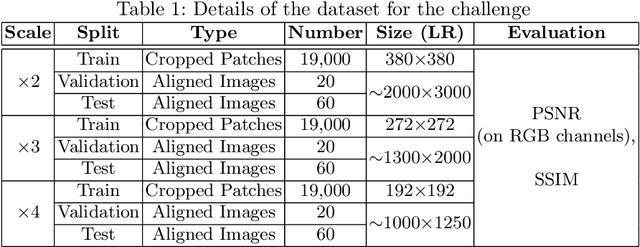
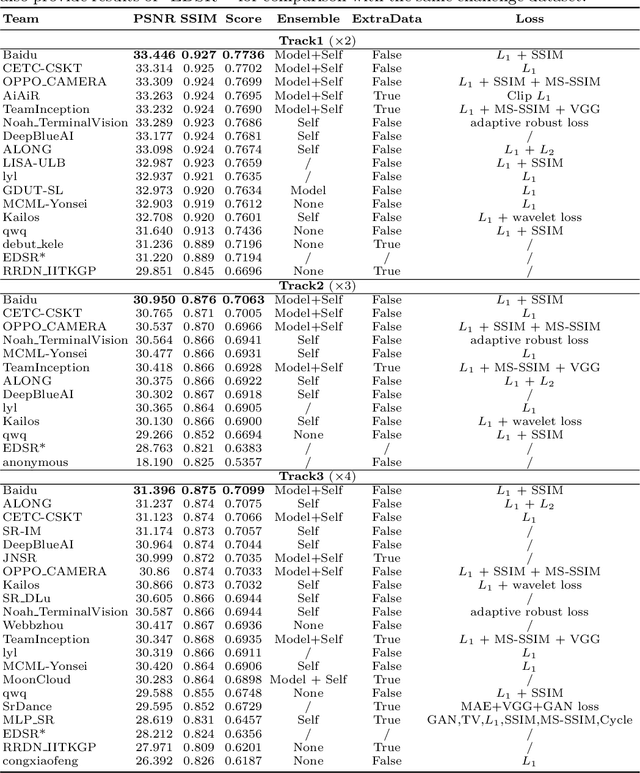
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.