 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMM-Refine: A Recipe for Improving Faithfulness in Generation with Multi-Agent Collaboration
Mar 19, 2025



Multi-agent collaboration among models has shown promise in reasoning tasks but is underexplored in long-form generation tasks like summarization and question-answering. We extend multi-agent multi-model reasoning to generation, specifically to improving faithfulness through refinement, i.e., revising model-generated outputs to remove factual inconsistencies. We investigate how iterative collaboration among multiple instances and types of large language models (LLMs) enhances subtasks in the refinement process, such as error detection, critiquing unfaithful sentences, and making corrections based on critiques. We design intrinsic evaluations for each subtask, with our findings indicating that both multi-agent (multiple instances) and multi-model (diverse LLM types) approaches benefit error detection and critiquing. Additionally, reframing critiquing and refinement as reranking rather than generation tasks improves multi-agent performance. We consolidate these insights into a final "recipe" called Multi-Agent Multi-Model Refinement (MAMM-Refine), where multi-agent and multi-model collaboration significantly boosts performance on three summarization datasets as well as on long-form question answering, demonstrating the effectiveness and generalizability of our recipe.
Symbolic Mixture-of-Experts: Adaptive Skill-based Routing for Heterogeneous Reasoning
Mar 07, 2025



Combining existing pre-trained expert LLMs is a promising avenue for scalably tackling large-scale and diverse tasks. However, selecting experts at the task level is often too coarse-grained, as heterogeneous tasks may require different expertise for each instance. To enable adaptive instance-level mixing of pre-trained LLM experts, we propose Symbolic-MoE, a symbolic, text-based, and gradient-free Mixture-of-Experts framework. Symbolic-MoE takes a fine-grained approach to selection by emphasizing skills, e.g., algebra in math or molecular biology in biomedical reasoning. We propose a skill-based recruiting strategy that dynamically selects the most relevant set of expert LLMs for diverse reasoning tasks based on their strengths. Each selected expert then generates its own reasoning, resulting in k outputs from k experts, which are then synthesized into a final high-quality response by an aggregator chosen based on its ability to integrate diverse reasoning outputs. We show that Symbolic-MoE's instance-level expert selection improves performance by a large margin but -- when implemented naively -- can introduce a high computational overhead due to the need for constant model loading and offloading. To address this, we implement a batch inference strategy that groups instances based on their assigned experts, loading each model only once. This allows us to integrate 16 expert models on 1 GPU with a time cost comparable to or better than prior multi-agent baselines using 4 GPUs. Through extensive evaluations on diverse benchmarks (MMLU-Pro, GPQA, AIME, and MedMCQA), we demonstrate that Symbolic-MoE outperforms strong LLMs like GPT4o-mini, as well as multi-agent approaches, with an absolute average improvement of 8.15% over the best multi-agent baseline. Moreover, Symbolic-MoE removes the need for expensive multi-round discussions, outperforming discussion baselines with less computation.
RSQ: Learning from Important Tokens Leads to Better Quantized LLMs
Mar 03, 2025Layer-wise quantization is a key technique for efficiently compressing large models without expensive retraining. Previous methods typically quantize the weights of each layer by "uniformly" optimizing the layer reconstruction loss across all output tokens. However, in this paper, we demonstrate that better-quantized models can be obtained by prioritizing learning from important tokens (e.g. which have large attention scores). Building on this finding, we propose RSQ (Rotate, Scale, then Quantize), which (1) applies rotations (orthogonal transformation) to the model to mitigate outliers (those with exceptionally large magnitude), (2) scales the token feature based on its importance, and (3) quantizes the model using the GPTQ framework with the second-order statistics computed by scaled tokens. To compute token importance, we explore both heuristic and dynamic strategies. Based on a thorough analysis of all approaches, we adopt attention concentration, which uses attention scores of each token as its importance, as the best approach. We demonstrate that RSQ consistently outperforms baseline methods across multiple downstream tasks and three model families: LLaMA3, Mistral, and Qwen2.5. Additionally, models quantized with RSQ achieve superior performance on long-context tasks, further highlighting its effectiveness. Lastly, RSQ demonstrates generalizability across various setups, including different model sizes, calibration datasets, bit precisions, and quantization methods.
MutaGReP: Execution-Free Repository-Grounded Plan Search for Code-Use
Feb 21, 2025



When a human requests an LLM to complete a coding task using functionality from a large code repository, how do we provide context from the repo to the LLM? One approach is to add the entire repo to the LLM's context window. However, most tasks involve only fraction of symbols from a repo, longer contexts are detrimental to the LLM's reasoning abilities, and context windows are not unlimited. Alternatively, we could emulate the human ability to navigate a large repo, pick out the right functionality, and form a plan to solve the task. We propose MutaGReP (Mutation-guided Grounded Repository Plan Search), an approach to search for plans that decompose a user request into natural language steps grounded in the codebase. MutaGReP performs neural tree search in plan space, exploring by mutating plans and using a symbol retriever for grounding. On the challenging LongCodeArena benchmark, our plans use less than 5% of the 128K context window for GPT-4o but rival the coding performance of GPT-4o with a context window filled with the repo. Plans produced by MutaGReP allow Qwen 2.5 Coder 32B and 72B to match the performance of GPT-4o with full repo context and enable progress on the hardest LongCodeArena tasks. Project page: zaidkhan.me/MutaGReP
UPCORE: Utility-Preserving Coreset Selection for Balanced Unlearning
Feb 20, 2025



User specifications or legal frameworks often require information to be removed from pretrained models, including large language models (LLMs). This requires deleting or "forgetting" a set of data points from an already-trained model, which typically degrades its performance on other data points. Thus, a balance must be struck between removing information and keeping the model's other abilities intact, with a failure to balance this trade-off leading to poor deletion or an unusable model. To this end, we propose UPCORE (Utility-Preserving Coreset Selection), a method-agnostic data selection framework for mitigating collateral damage during unlearning. Finding that the model damage is correlated with the variance of the model's representations on the forget set, we selectively prune the forget set to remove outliers, thereby minimizing model degradation after unlearning. We evaluate UPCORE across three standard unlearning methods consistently achieving a superior balance between the competing objectives of deletion efficacy and model preservation. To better evaluate this trade-off, we introduce a new metric, measuring the area-under-the-curve (AUC) across standard metrics. We find that UPCORE improves both standard metrics and AUC, benefitting from positive transfer between the coreset and pruned points while reducing negative transfer from the forget set to points outside of it.
Multi-Attribute Steering of Language Models via Targeted Intervention
Feb 18, 2025Inference-time intervention (ITI) has emerged as a promising method for steering large language model (LLM) behavior in a particular direction (e.g., improving helpfulness) by intervening on token representations without costly updates to the LLM's parameters. However, existing ITI approaches fail to scale to multi-attribute settings with conflicts, such as enhancing helpfulness while also reducing toxicity. To address this, we introduce Multi-Attribute Targeted Steering (MAT-Steer), a novel steering framework designed for selective token-level intervention across multiple attributes. MAT-Steer learns steering vectors using an alignment objective that shifts the model's internal representations of undesirable outputs closer to those of desirable ones while enforcing sparsity and orthogonality among vectors for different attributes, thereby reducing inter-attribute conflicts. We evaluate MAT-Steer in two distinct settings: (i) on question answering (QA) tasks where we balance attributes like truthfulness, bias, and toxicity; (ii) on generative tasks where we simultaneously improve attributes like helpfulness, correctness, and coherence. MAT-Steer outperforms existing ITI and parameter-efficient finetuning approaches across both task types (e.g., 3% average accuracy gain across QA tasks and 55.82% win rate against the best ITI baseline).
Learning to Generate Unit Tests for Automated Debugging
Feb 03, 2025



Unit tests (UTs) play an instrumental role in assessing code correctness as well as providing feedback to a large language model (LLM) as it iteratively debugs faulty code, motivating automated test generation. However, we uncover a trade-off between generating unit test inputs that reveal errors when given a faulty code and correctly predicting the unit test output without access to the gold solution. To address this trade-off, we propose UTGen, which teaches LLMs to generate unit test inputs that reveal errors along with their correct expected outputs based on task descriptions and candidate code. We integrate UTGen into UTDebug, a robust debugging pipeline that uses generated tests to help LLMs debug effectively. Since model-generated tests can provide noisy signals (e.g., from incorrectly predicted outputs), UTDebug (i) scales UTGen via test-time compute to improve UT output prediction, and (ii) validates and back-tracks edits based on multiple generated UTs to avoid overfitting. We show that UTGen outperforms UT generation baselines by 7.59% based on a metric measuring the presence of both error-revealing UT inputs and correct UT outputs. When used with UTDebug, we find that feedback from UTGen's unit tests improves pass@1 accuracy of Qwen-2.5 7B on HumanEvalFix and our own harder debugging split of MBPP+ by over 3% and 12.35% (respectively) over other LLM-based UT generation baselines.
TimeRefine: Temporal Grounding with Time Refining Video LLM
Dec 12, 2024



Video temporal grounding aims to localize relevant temporal boundaries in a video given a textual prompt. Recent work has focused on enabling Video LLMs to perform video temporal grounding via next-token prediction of temporal timestamps. However, accurately localizing timestamps in videos remains challenging for Video LLMs when relying solely on temporal token prediction. Our proposed TimeRefine addresses this challenge in two ways. First, instead of directly predicting the start and end timestamps, we reformulate the temporal grounding task as a temporal refining task: the model first makes rough predictions and then refines them by predicting offsets to the target segment. This refining process is repeated multiple times, through which the model progressively self-improves its temporal localization accuracy. Second, to enhance the model's temporal perception capabilities, we incorporate an auxiliary prediction head that penalizes the model more if a predicted segment deviates further from the ground truth, thus encouraging the model to make closer and more accurate predictions. Our plug-and-play method can be integrated into most LLM-based temporal grounding approaches. The experimental results demonstrate that TimeRefine achieves 3.6% and 5.0% mIoU improvements on the ActivityNet and Charades-STA datasets, respectively. Code and pretrained models will be released.
Bootstrapping Language-Guided Navigation Learning with Self-Refining Data Flywheel
Dec 11, 2024
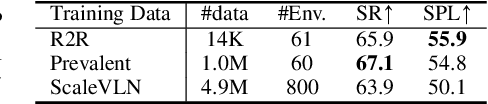

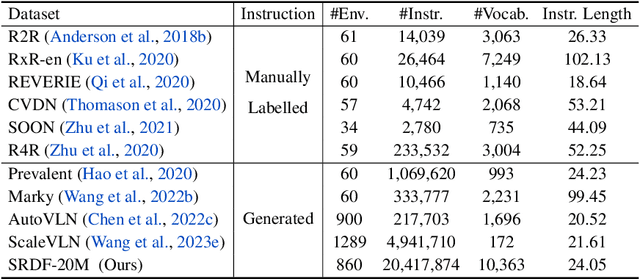
Creating high-quality data for training robust language-instructed agents is a long-lasting challenge in embodied AI. In this paper, we introduce a Self-Refining Data Flywheel (SRDF) that generates high-quality and large-scale navigational instruction-trajectory pairs by iteratively refining the data pool through the collaboration between two models, the instruction generator and the navigator, without any human-in-the-loop annotation. Specifically, SRDF starts with using a base generator to create an initial data pool for training a base navigator, followed by applying the trained navigator to filter the data pool. This leads to higher-fidelity data to train a better generator, which can, in turn, produce higher-quality data for training the next-round navigator. Such a flywheel establishes a data self-refining process, yielding a continuously improved and highly effective dataset for large-scale language-guided navigation learning. Our experiments demonstrate that after several flywheel rounds, the navigator elevates the performance boundary from 70% to 78% SPL on the classic R2R test set, surpassing human performance (76%) for the first time. Meanwhile, this process results in a superior generator, evidenced by a SPICE increase from 23.5 to 26.2, better than all previous VLN instruction generation methods. Finally, we demonstrate the scalability of our method through increasing environment and instruction diversity, and the generalization ability of our pre-trained navigator across various downstream navigation tasks, surpassing state-of-the-art methods by a large margin in all cases.
QAPyramid: Fine-grained Evaluation of Content Selection for Text Summarization
Dec 10, 2024



How to properly conduct human evaluations for text summarization is a longstanding challenge. The Pyramid human evaluation protocol, which assesses content selection by breaking the reference summary into sub-units and verifying their presence in the system summary, has been widely adopted. However, it suffers from a lack of systematicity in the definition and granularity of the sub-units. We address these problems by proposing QAPyramid, which decomposes each reference summary into finer-grained question-answer (QA) pairs according to the QA-SRL framework. We collect QA-SRL annotations for reference summaries from CNN/DM and evaluate 10 summarization systems, resulting in 8.9K QA-level annotations. We show that, compared to Pyramid, QAPyramid provides more systematic and fine-grained content selection evaluation while maintaining high inter-annotator agreement without needing expert annotations. Furthermore, we propose metrics that automate the evaluation pipeline and achieve higher correlations with QAPyramid than other widely adopted metrics, allowing future work to accurately and efficiently benchmark summarization systems.