 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Neural Networks for Frame-based and Event-based Single Object Localization
Jun 13, 2022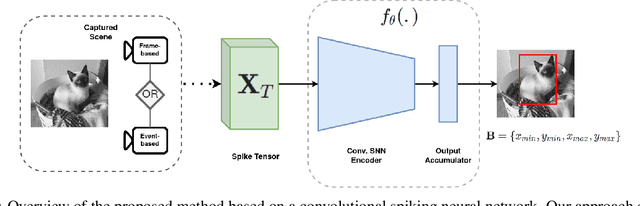

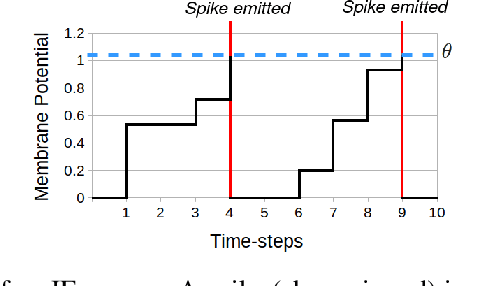

Spiking neural networks have shown much promise as an energy-efficient alternative to artificial neural networks. However, understanding the impacts of sensor noises and input encodings on the network activity and performance remains difficult with common neuromorphic vision baselines like classification. Therefore, we propose a spiking neural network approach for single object localization trained using surrogate gradient descent, for frame- and event-based sensors. We compare our method with similar artificial neural networks and show that our model has competitive/better performance in accuracy, robustness against various corruptions, and has lower energy consumption. Moreover, we study the impact of neural coding schemes for static images in accuracy, robustness, and energy efficiency. Our observations differ importantly from previous studies on bio-plausible learning rules, which helps in the design of surrogate gradient trained architectures, and offers insight to design priorities in future neuromorphic technologies in terms of noise characteristics and data encoding methods.
CrossFormer: Cross Spatio-Temporal Transformer for 3D Human Pose Estimation
Mar 24, 2022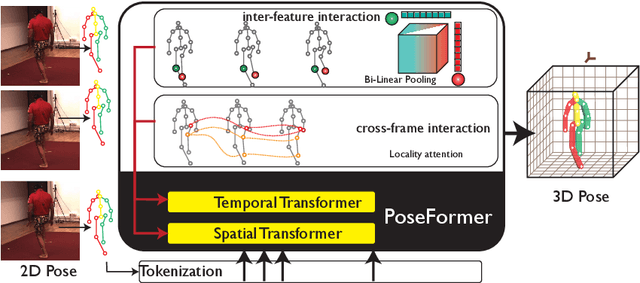
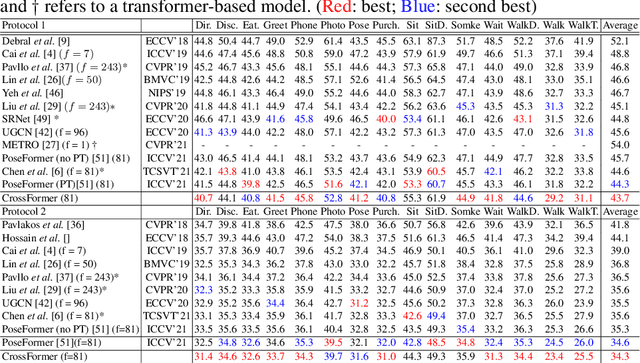
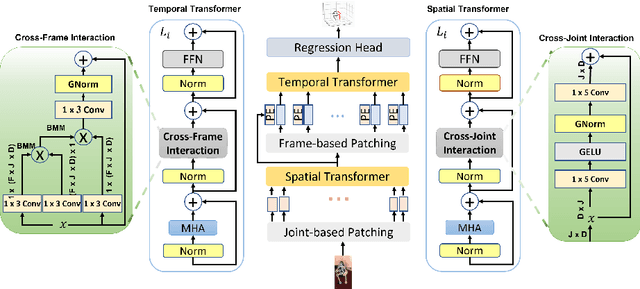
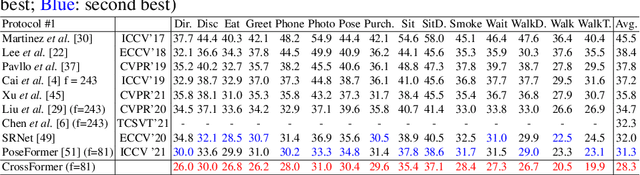
3D human pose estimation can be handled by encoding the geometric dependencies between the body parts and enforcing the kinematic constraints. Recently, Transformer has been adopted to encode the long-range dependencies between the joints in the spatial and temporal domains. While they had shown excellence in long-range dependencies, studies have noted the need for improving the locality of vision Transformers. In this direction, we propose a novel pose estimation Transformer featuring rich representations of body joints critical for capturing subtle changes across frames (i.e., inter-feature representation). Specifically, through two novel interaction modules; Cross-Joint Interaction and Cross-Frame Interaction, the model explicitly encodes the local and global dependencies between the body joints. The proposed architecture achieved state-of-the-art performance on two popular 3D human pose estimation datasets, Human3.6 and MPI-INF-3DHP. In particular, our proposed CrossFormer method boosts performance by 0.9% and 0.3%, compared to the closest counterpart, PoseFormer, using the detected 2D poses and ground-truth settings respectively.
Multi-class Token Transformer for Weakly Supervised Semantic Segmentation
Mar 06, 2022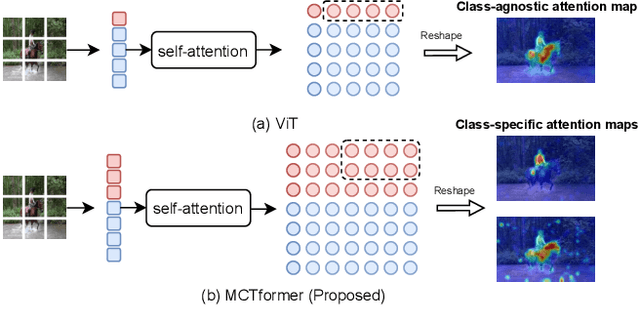
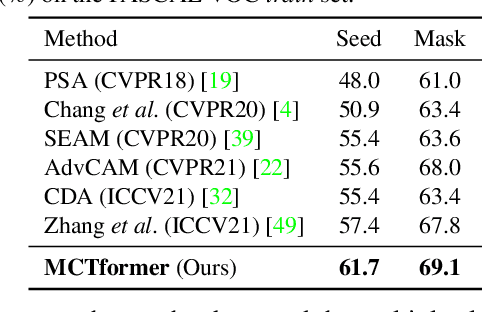
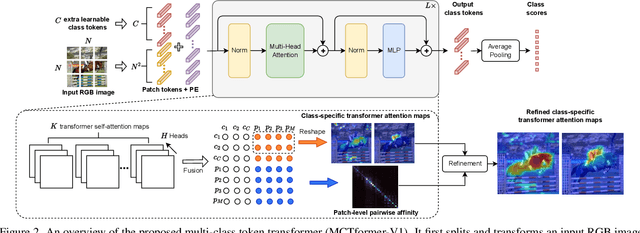
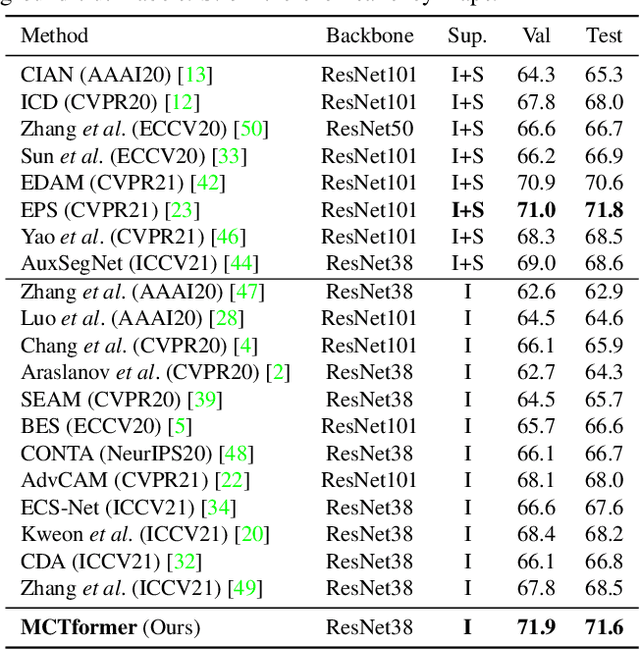
This paper proposes a new transformer-based framework to learn class-specific object localization maps as pseudo labels for weakly supervised semantic segmentation (WSSS). Inspired by the fact that the attended regions of the one-class token in the standard vision transformer can be leveraged to form a class-agnostic localization map, we investigate if the transformer model can also effectively capture class-specific attention for more discriminative object localization by learning multiple class tokens within the transformer. To this end, we propose a Multi-class Token Transformer, termed as MCTformer, which uses multiple class tokens to learn interactions between the class tokens and the patch tokens. The proposed MCTformer can successfully produce class-discriminative object localization maps from class-to-patch attentions corresponding to different class tokens. We also propose to use a patch-level pairwise affinity, which is extracted from the patch-to-patch transformer attention, to further refine the localization maps. Moreover, the proposed framework is shown to fully complement the Class Activation Mapping (CAM) method, leading to remarkably superior WSSS results on the PASCAL VOC and MS COCO datasets. These results underline the importance of the class token for WSSS.
Unsupervised Learning on 3D Point Clouds by Clustering and Contrasting
Feb 14, 2022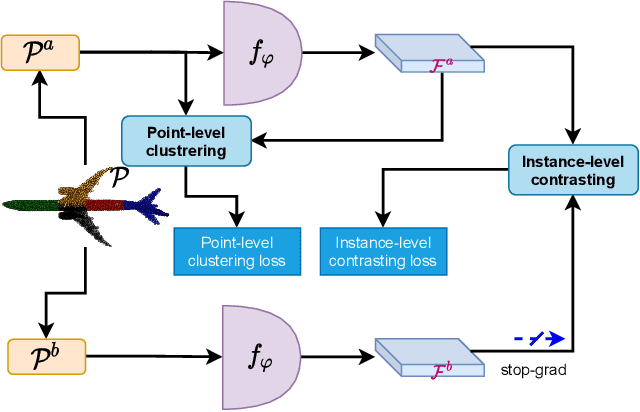
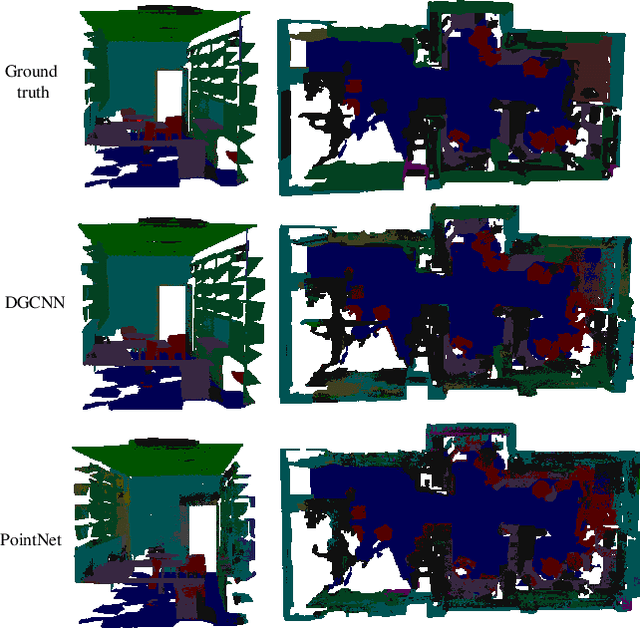
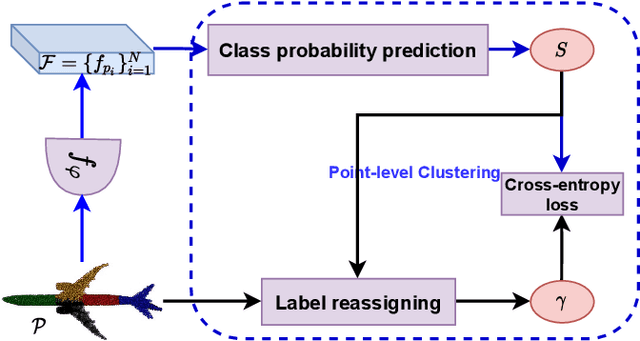
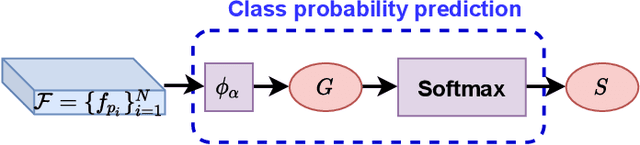
Learning from unlabeled or partially labeled data to alleviate human labeling remains a challenging research topic in 3D modeling. Along this line, unsupervised representation learning is a promising direction to auto-extract features without human intervention. This paper proposes a general unsupervised approach, named \textbf{ConClu}, to perform the learning of point-wise and global features by jointly leveraging point-level clustering and instance-level contrasting. Specifically, for one thing, we design an Expectation-Maximization (EM) like soft clustering algorithm that provides local supervision to extract discriminating local features based on optimal transport. We show that this criterion extends standard cross-entropy minimization to an optimal transport problem, which we solve efficiently using a fast variant of the Sinkhorn-Knopp algorithm. For another, we provide an instance-level contrasting method to learn the global geometry, which is formulated by maximizing the similarity between two augmentations of one point cloud. Experimental evaluations on downstream applications such as 3D object classification and semantic segmentation demonstrate the effectiveness of our framework and show that it can outperform state-of-the-art techniques.
Performance of multilabel machine learning models and risk stratification schemas for predicting stroke and bleeding risk in patients with non-valvular atrial fibrillation
Feb 02, 2022
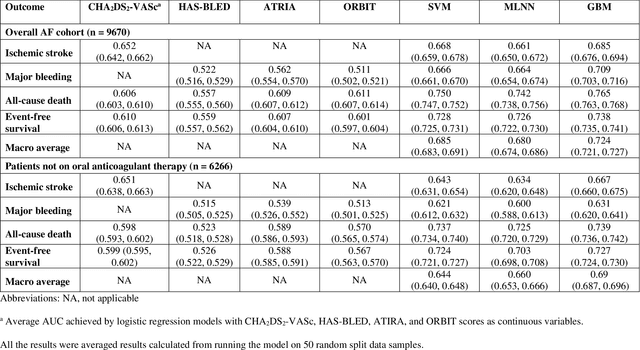
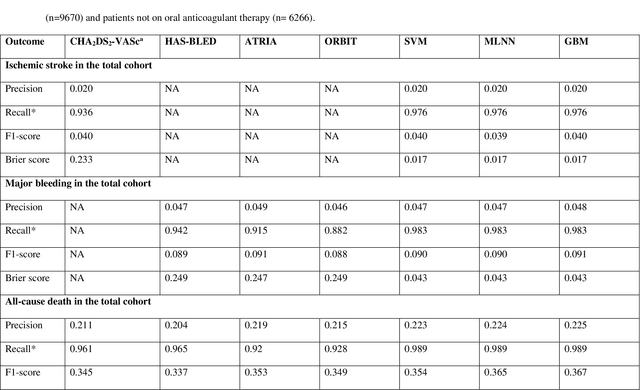
Appropriate antithrombotic therapy for patients with atrial fibrillation (AF) requires assessment of ischemic stroke and bleeding risks. However, risk stratification schemas such as CHA2DS2-VASc and HAS-BLED have modest predictive capacity for patients with AF. Machine learning (ML) techniques may improve predictive performance and support decision-making for appropriate antithrombotic therapy. We compared the performance of multilabel ML models with the currently used risk scores for predicting outcomes in AF patients. Materials and Methods This was a retrospective cohort study of 9670 patients, mean age 76.9 years, 46% women, who were hospitalized with non-valvular AF, and had 1-year follow-up. The primary outcome was ischemic stroke and major bleeding admission. The secondary outcomes were all-cause death and event-free survival. The discriminant power of ML models was compared with clinical risk scores by the area under the curve (AUC). Risk stratification was assessed using the net reclassification index. Results Multilabel gradient boosting machine provided the best discriminant power for stroke, major bleeding, and death (AUC = 0.685, 0.709, and 0.765 respectively) compared to other ML models. It provided modest performance improvement for stroke compared to CHA2DS2-VASc (AUC = 0.652), but significantly improved major bleeding prediction compared to HAS-BLED (AUC = 0.522). It also had a much greater discriminant power for death compared with CHA2DS2-VASc (AUC = 0.606). Also, models identified additional risk features (such as hemoglobin level, renal function, etc.) for each outcome. Conclusions Multilabel ML models can outperform clinical risk stratification scores for predicting the risk of major bleeding and death in non-valvular AF patients.
A Novel Incremental Learning Driven Instance Segmentation Framework to Recognize Highly Cluttered Instances of the Contraband Items
Jan 10, 2022
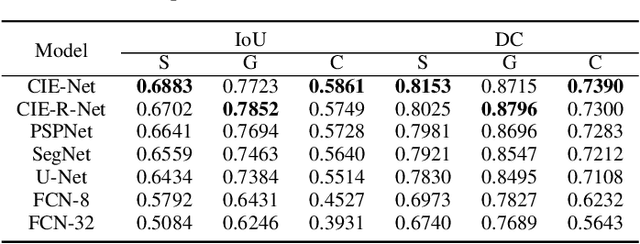
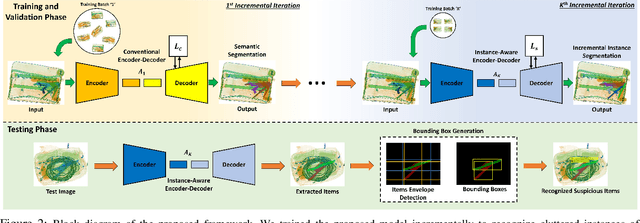
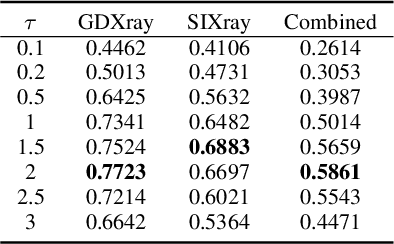
Screening cluttered and occluded contraband items from baggage X-ray scans is a cumbersome task even for the expert security staff. This paper presents a novel strategy that extends a conventional encoder-decoder architecture to perform instance-aware segmentation and extract merged instances of contraband items without using any additional sub-network or an object detector. The encoder-decoder network first performs conventional semantic segmentation and retrieves cluttered baggage items. The model then incrementally evolves during training to recognize individual instances using significantly reduced training batches. To avoid catastrophic forgetting, a novel objective function minimizes the network loss in each iteration by retaining the previously acquired knowledge while learning new class representations and resolving their complex structural inter-dependencies through Bayesian inference. A thorough evaluation of our framework on two publicly available X-ray datasets shows that it outperforms state-of-the-art methods, especially within the challenging cluttered scenarios, while achieving an optimal trade-off between detection accuracy and efficiency.
* IEEE Transactions on Systems, Man, and Cybernetics: Systems, Source code is available at https://github.com/taimurhassan/inc-inst-seg
Spatio-Temporal Graph Representation Learning for Fraudster Group Detection
Jan 07, 2022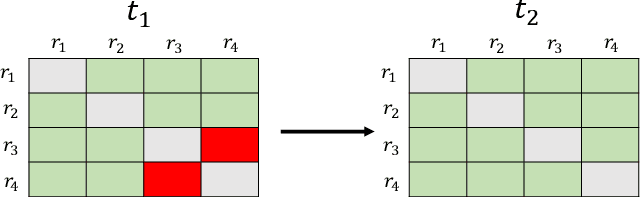
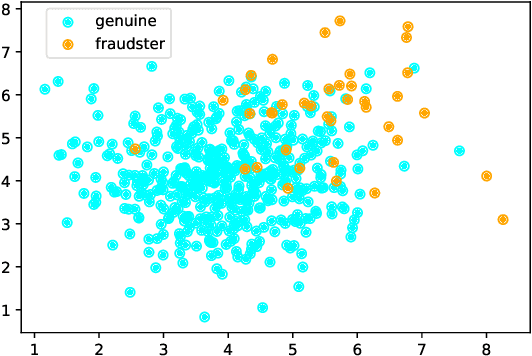
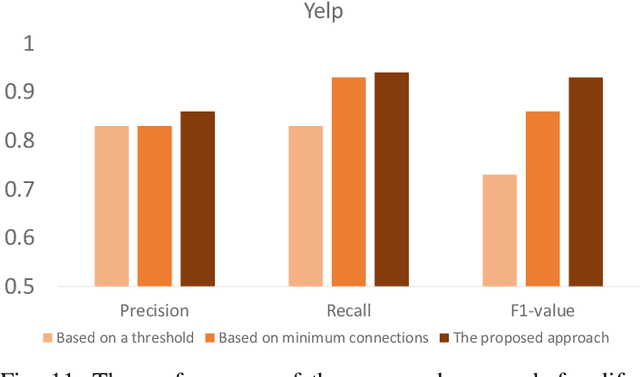
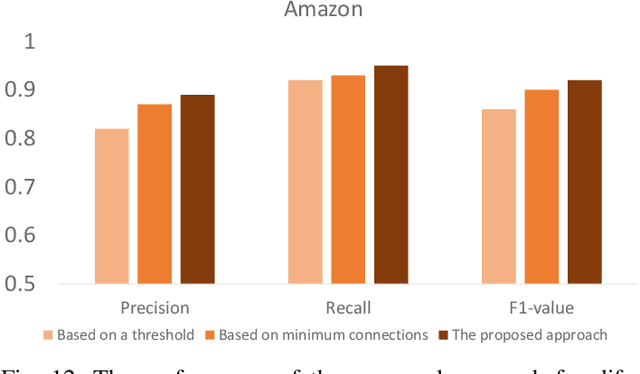
Motivated by potential financial gain, companies may hire fraudster groups to write fake reviews to either demote competitors or promote their own businesses. Such groups are considerably more successful in misleading customers, as people are more likely to be influenced by the opinion of a large group. To detect such groups, a common model is to represent fraudster groups' static networks, consequently overlooking the longitudinal behavior of a reviewer thus the dynamics of co-review relations among reviewers in a group. Hence, these approaches are incapable of excluding outlier reviewers, which are fraudsters intentionally camouflaging themselves in a group and genuine reviewers happen to co-review in fraudster groups. To address this issue, in this work, we propose to first capitalize on the effectiveness of the HIN-RNN in both reviewers' representation learning while capturing the collaboration between reviewers, we first utilize the HIN-RNN to model the co-review relations of reviewers in a group in a fixed time window of 28 days. We refer to this as spatial relation learning representation to signify the generalisability of this work to other networked scenarios. Then we use an RNN on the spatial relations to predict the spatio-temporal relations of reviewers in the group. In the third step, a Graph Convolution Network (GCN) refines the reviewers' vector representations using these predicted relations. These refined representations are then used to remove outlier reviewers. The average of the remaining reviewers' representation is then fed to a simple fully connected layer to predict if the group is a fraudster group or not. Exhaustive experiments of the proposed approach showed a 5% (4%), 12% (5%), 12% (5%) improvement over three of the most recent approaches on precision, recall, and F1-value over the Yelp (Amazon) dataset, respectively.
Scene Graph Generation: A Comprehensive Survey
Jan 03, 2022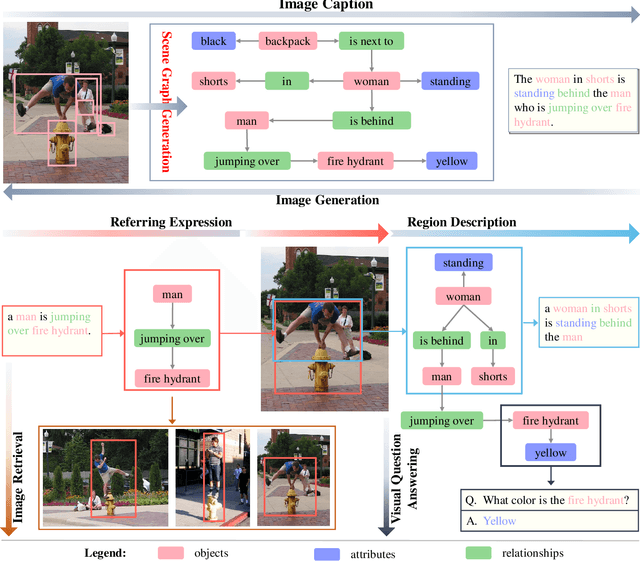
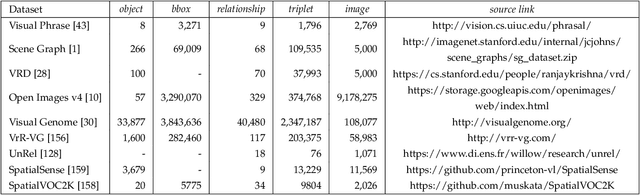
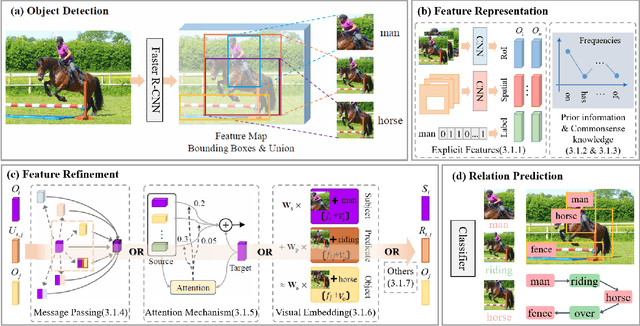
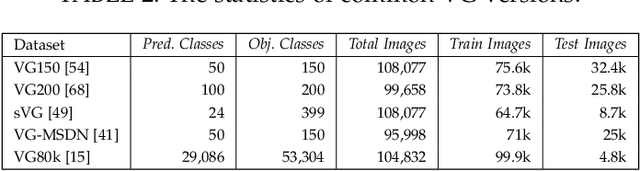
Deep learning techniques have led to remarkable breakthroughs in the field of generic object detection and have spawned a lot of scene-understanding tasks in recent years. Scene graph has been the focus of research because of its powerful semantic representation and applications to scene understanding. Scene Graph Generation (SGG) refers to the task of automatically mapping an image into a semantic structural scene graph, which requires the correct labeling of detected objects and their relationships. Although this is a challenging task, the community has proposed a lot of SGG approaches and achieved good results. In this paper, we provide a comprehensive survey of recent achievements in this field brought about by deep learning techniques. We review 138 representative works that cover different input modalities, and systematically summarize existing methods of image-based SGG from the perspective of feature extraction and fusion. We attempt to connect and systematize the existing visual relationship detection methods, to summarize, and interpret the mechanisms and the strategies of SGG in a comprehensive way. Finally, we finish this survey with deep discussions about current existing problems and future research directions. This survey will help readers to develop a better understanding of the current research status and ideas.
COTReg:Coupled Optimal Transport based Point Cloud Registration
Dec 29, 2021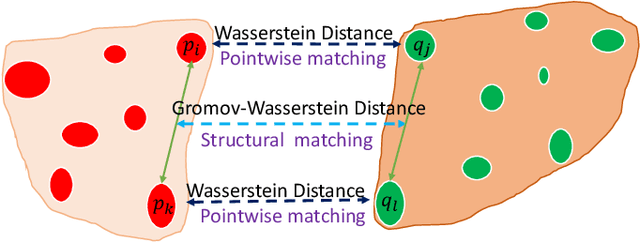

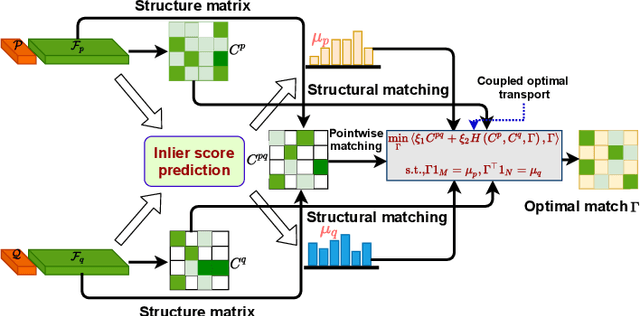
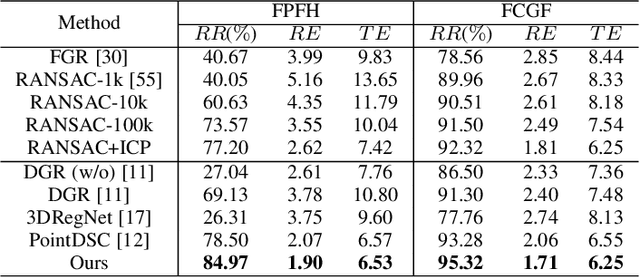
Generating a set of high-quality correspondences or matches is one of the most critical steps in point cloud registration. This paper proposes a learning framework COTReg by jointly considering the pointwise and structural matchings to predict correspondences of 3D point cloud registration. Specifically, we transform the two matchings into a Wasserstein distance-based and a Gromov-Wasserstein distance-based optimizations, respectively. Thus the task of establishing the correspondences can be naturally reshaped to a coupled optimal transport problem. Furthermore, we design a network to predict the confidence score of being an inlier for each point of the point clouds, which provides the overlap region information to generate correspondences. Our correspondence prediction pipeline can be easily integrated into either learning-based features like FCGF or traditional descriptors like FPFH. We conducted comprehensive experiments on 3DMatch, KITTI, 3DCSR, and ModelNet40 benchmarks, showing the state-of-art performance of the proposed method.
Explainable Artificial Intelligence for Pharmacovigilance: What Features Are Important When Predicting Adverse Outcomes?
Dec 25, 2021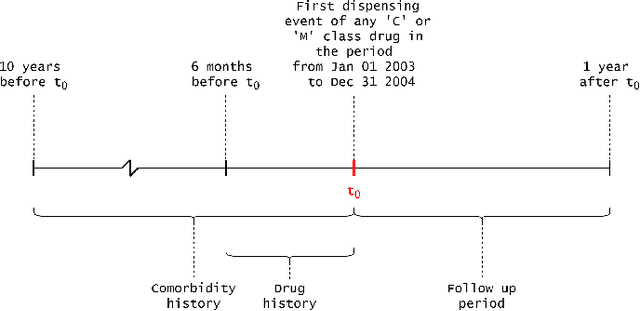

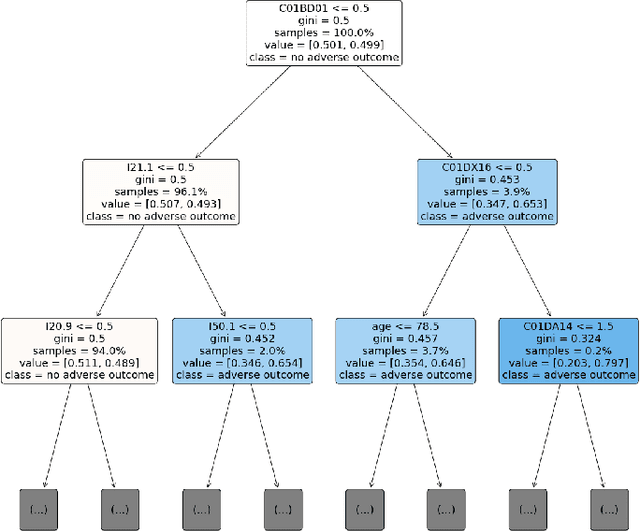
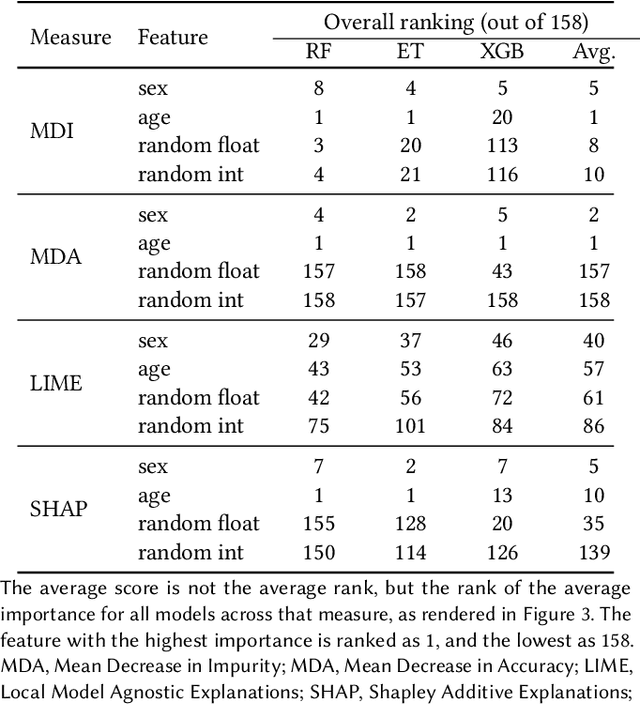
Explainable Artificial Intelligence (XAI) has been identified as a viable method for determining the importance of features when making predictions using Machine Learning (ML) models. In this study, we created models that take an individual's health information (e.g. their drug history and comorbidities) as inputs, and predict the probability that the individual will have an Acute Coronary Syndrome (ACS) adverse outcome. Using XAI, we quantified the contribution that specific drugs had on these ACS predictions, thus creating an XAI-based technique for pharmacovigilance monitoring, using ACS as an example of the adverse outcome to detect. Individuals aged over 65 who were supplied Musculo-skeletal system (anatomical therapeutic chemical (ATC) class M) or Cardiovascular system (ATC class C) drugs between 1993 and 2009 were identified, and their drug histories, comorbidities, and other key features were extracted from linked Western Australian datasets. Multiple ML models were trained to predict if these individuals would have an ACS related adverse outcome (i.e., death or hospitalisation with a discharge diagnosis of ACS), and a variety of ML and XAI techniques were used to calculate which features -- specifically which drugs -- led to these predictions. The drug dispensing features for rofecoxib and celecoxib were found to have a greater than zero contribution to ACS related adverse outcome predictions (on average), and it was found that ACS related adverse outcomes can be predicted with 72% accuracy. Furthermore, the XAI libraries LIME and SHAP were found to successfully identify both important and unimportant features, with SHAP slightly outperforming LIME. ML models trained on linked administrative health datasets in tandem with XAI algorithms can successfully quantify feature importance, and with further development, could potentially be used as pharmacovigilance monitoring techniques.