 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRef-DVGO: Reflection-Aware Direct Voxel Grid Optimization for an Improved Quality-Efficiency Trade-Off in Reflective Scene Reconstruction
Aug 21, 2023



Neural Radiance Fields (NeRFs) have revolutionized the field of novel view synthesis, demonstrating remarkable performance. However, the modeling and rendering of reflective objects remain challenging problems. Recent methods have shown significant improvements over the baselines in handling reflective scenes, albeit at the expense of efficiency. In this work, we aim to strike a balance between efficiency and quality. To this end, we investigate an implicit-explicit approach based on conventional volume rendering to enhance the reconstruction quality and accelerate the training and rendering processes. We adopt an efficient density-based grid representation and reparameterize the reflected radiance in our pipeline. Our proposed reflection-aware approach achieves a competitive quality efficiency trade-off compared to competing methods. Based on our experimental results, we propose and discuss hypotheses regarding the factors influencing the results of density-based methods for reconstructing reflective objects. The source code is available at https://github.com/gkouros/ref-dvgo.
Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos
Apr 10, 2023The success of the Neural Radiance Fields (NeRFs) for modeling and free-view rendering static objects has inspired numerous attempts on dynamic scenes. Current techniques that utilize neural rendering for facilitating free-view videos (FVVs) are restricted to either offline rendering or are capable of processing only brief sequences with minimal motion. In this paper, we present a novel technique, Residual Radiance Field or ReRF, as a highly compact neural representation to achieve real-time FVV rendering on long-duration dynamic scenes. ReRF explicitly models the residual information between adjacent timestamps in the spatial-temporal feature space, with a global coordinate-based tiny MLP as the feature decoder. Specifically, ReRF employs a compact motion grid along with a residual feature grid to exploit inter-frame feature similarities. We show such a strategy can handle large motions without sacrificing quality. We further present a sequential training scheme to maintain the smoothness and the sparsity of the motion/residual grids. Based on ReRF, we design a special FVV codec that achieves three orders of magnitudes compression rate and provides a companion ReRF player to support online streaming of long-duration FVVs of dynamic scenes. Extensive experiments demonstrate the effectiveness of ReRF for compactly representing dynamic radiance fields, enabling an unprecedented free-viewpoint viewing experience in speed and quality.
Human Performance Modeling and Rendering via Neural Animated Mesh
Sep 18, 2022

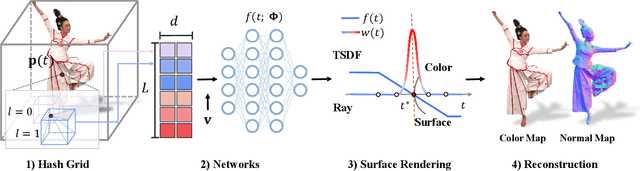
We have recently seen tremendous progress in the neural advances for photo-real human modeling and rendering. However, it's still challenging to integrate them into an existing mesh-based pipeline for downstream applications. In this paper, we present a comprehensive neural approach for high-quality reconstruction, compression, and rendering of human performances from dense multi-view videos. Our core intuition is to bridge the traditional animated mesh workflow with a new class of highly efficient neural techniques. We first introduce a neural surface reconstructor for high-quality surface generation in minutes. It marries the implicit volumetric rendering of the truncated signed distance field (TSDF) with multi-resolution hash encoding. We further propose a hybrid neural tracker to generate animated meshes, which combines explicit non-rigid tracking with implicit dynamic deformation in a self-supervised framework. The former provides the coarse warping back into the canonical space, while the latter implicit one further predicts the displacements using the 4D hash encoding as in our reconstructor. Then, we discuss the rendering schemes using the obtained animated meshes, ranging from dynamic texturing to lumigraph rendering under various bandwidth settings. To strike an intricate balance between quality and bandwidth, we propose a hierarchical solution by first rendering 6 virtual views covering the performer and then conducting occlusion-aware neural texture blending. We demonstrate the efficacy of our approach in a variety of mesh-based applications and photo-realistic free-view experiences on various platforms, i.e., inserting virtual human performances into real environments through mobile AR or immersively watching talent shows with VR headsets.
NeuralHOFusion: Neural Volumetric Rendering under Human-object Interactions
Mar 28, 2022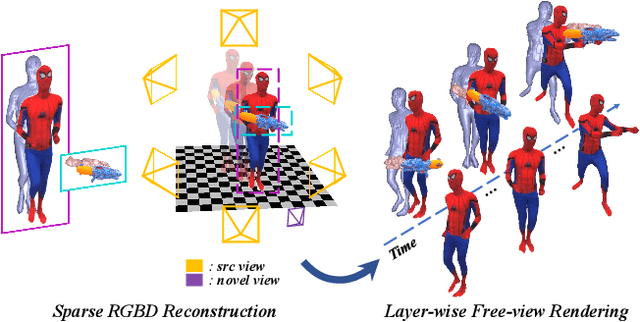
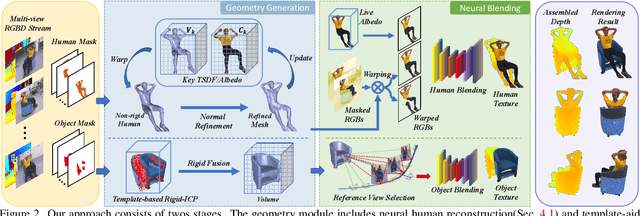
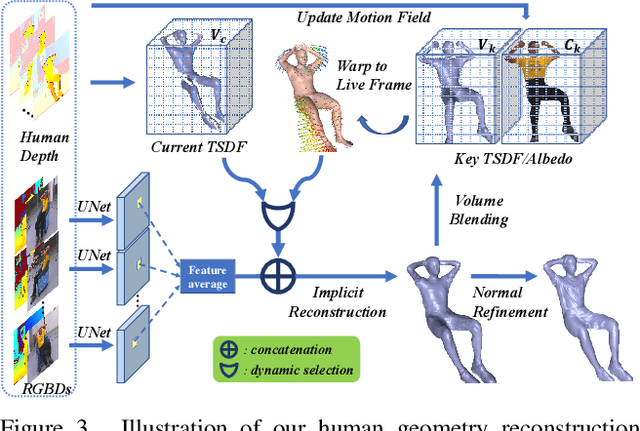
4D modeling of human-object interactions is critical for numerous applications. However, efficient volumetric capture and rendering of complex interaction scenarios, especially from sparse inputs, remain challenging. In this paper, we propose NeuralHOFusion, a neural approach for volumetric human-object capture and rendering using sparse consumer RGBD sensors. It marries traditional non-rigid fusion with recent neural implicit modeling and blending advances, where the captured humans and objects are layerwise disentangled. For geometry modeling, we propose a neural implicit inference scheme with non-rigid key-volume fusion, as well as a template-aid robust object tracking pipeline. Our scheme enables detailed and complete geometry generation under complex interactions and occlusions. Moreover, we introduce a layer-wise human-object texture rendering scheme, which combines volumetric and image-based rendering in both spatial and temporal domains to obtain photo-realistic results. Extensive experiments demonstrate the effectiveness and efficiency of our approach in synthesizing photo-realistic free-view results under complex human-object interactions.
Find a Way Forward: a Language-Guided Semantic Map Navigator
Mar 07, 2022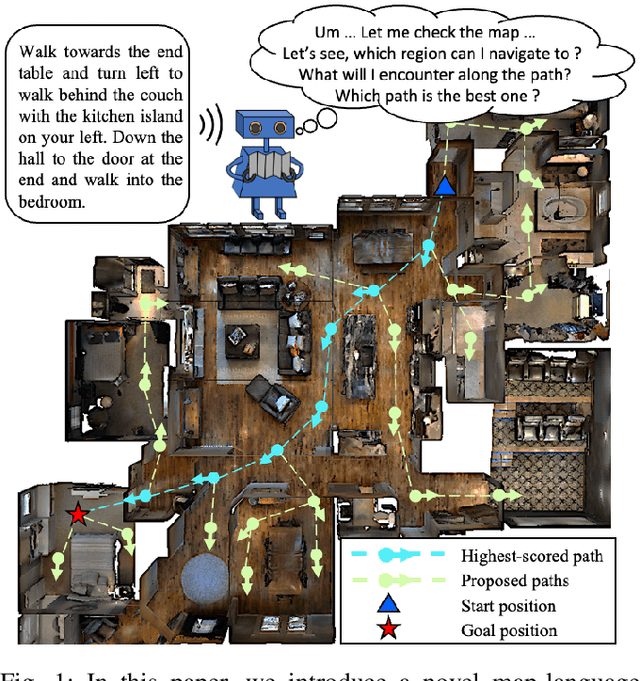
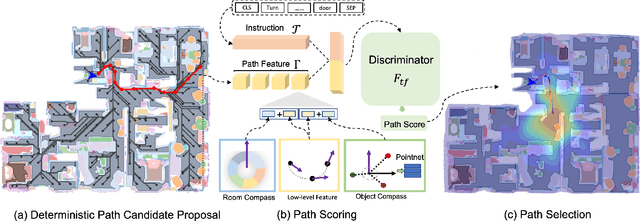
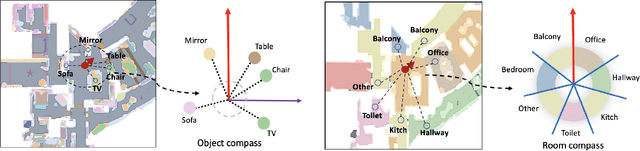
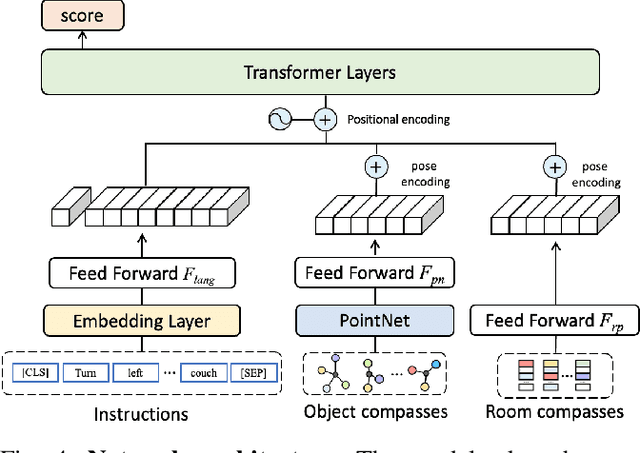
This paper attacks the problem of language-guided navigation in a new perspective by using novel semantic navigation maps, which enables robots to carry out natural language instructions and move to a target position based on the map observations. We break down this problem into parts and introduce three different modules to solve the corresponding subproblems. Our approach leverages map information to provide Deterministic Path Candidate Proposals to reduce the solution space. Different from traditional methods that predict robots' movements toward the target step-by-step, we design an attention-based Language Driven Discriminator to evaluate path candidates and determine the best path as the final result. To represent the map observations along a path for a better modality alignment, a novel Path Feature Encoding scheme tailored for semantic navigation maps is proposed. Unlike traditional methods that tend to produce cumulative errors or be stuck in local decisions, our method which plans paths based on global information can greatly alleviate these problems. The proposed approach has noticeable performance gains, especially in long-distance navigation cases. Also, its training efficiency is significantly higher than of other methods.
Fourier PlenOctrees for Dynamic Radiance Field Rendering in Real-time
Feb 22, 2022
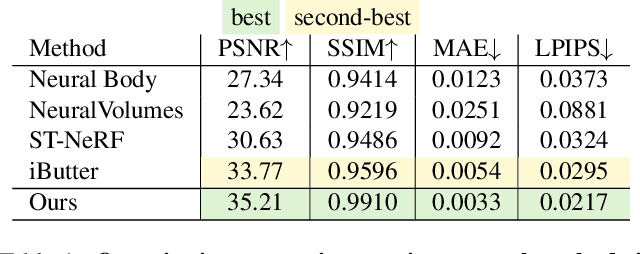
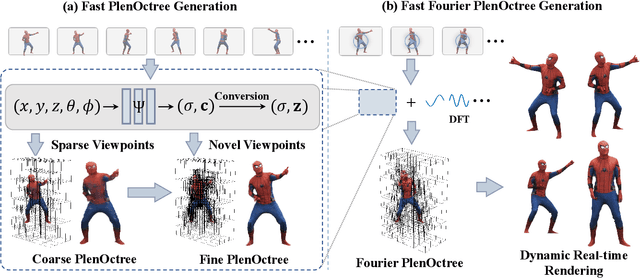

Implicit neural representations such as Neural Radiance Field (NeRF) have focused mainly on modeling static objects captured under multi-view settings where real-time rendering can be achieved with smart data structures, e.g., PlenOctree. In this paper, we present a novel Fourier PlenOctree (FPO) technique to tackle efficient neural modeling and real-time rendering of dynamic scenes captured under the free-view video (FVV) setting. The key idea in our FPO is a novel combination of generalized NeRF, PlenOctree representation, volumetric fusion and Fourier transform. To accelerate FPO construction, we present a novel coarse-to-fine fusion scheme that leverages the generalizable NeRF technique to generate the tree via spatial blending. To tackle dynamic scenes, we tailor the implicit network to model the Fourier coefficients of timevarying density and color attributes. Finally, we construct the FPO and train the Fourier coefficients directly on the leaves of a union PlenOctree structure of the dynamic sequence. We show that the resulting FPO enables compact memory overload to handle dynamic objects and supports efficient fine-tuning. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF and achieves over an order of magnitude acceleration over SOTA while preserving high visual quality for the free-viewpoint rendering of unseen dynamic scenes.
iButter: Neural Interactive Bullet Time Generator for Human Free-viewpoint Rendering
Aug 12, 2021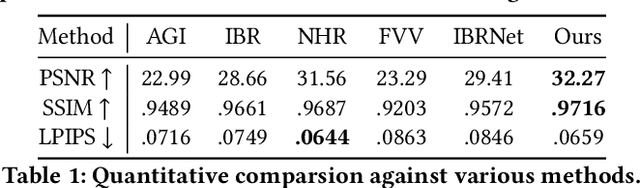
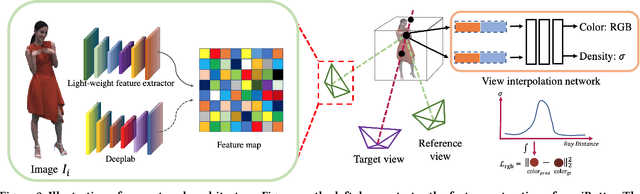
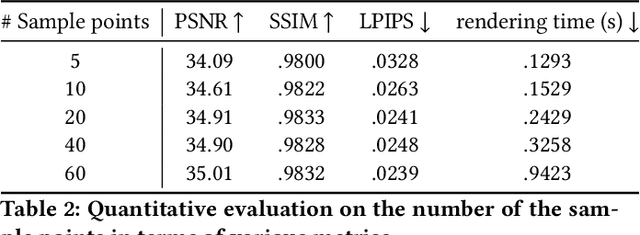
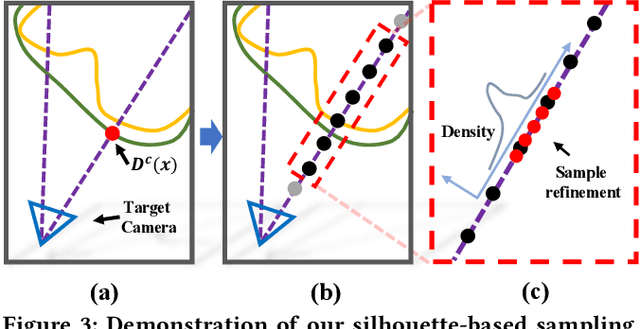
Generating ``bullet-time'' effects of human free-viewpoint videos is critical for immersive visual effects and VR/AR experience. Recent neural advances still lack the controllable and interactive bullet-time design ability for human free-viewpoint rendering, especially under the real-time, dynamic and general setting for our trajectory-aware task. To fill this gap, in this paper we propose a neural interactive bullet-time generator (iButter) for photo-realistic human free-viewpoint rendering from dense RGB streams, which enables flexible and interactive design for human bullet-time visual effects. Our iButter approach consists of a real-time preview and design stage as well as a trajectory-aware refinement stage. During preview, we propose an interactive bullet-time design approach by extending the NeRF rendering to a real-time and dynamic setting and getting rid of the tedious per-scene training. To this end, our bullet-time design stage utilizes a hybrid training set, light-weight network design and an efficient silhouette-based sampling strategy. During refinement, we introduce an efficient trajectory-aware scheme within 20 minutes, which jointly encodes the spatial, temporal consistency and semantic cues along the designed trajectory, achieving photo-realistic bullet-time viewing experience of human activities. Extensive experiments demonstrate the effectiveness of our approach for convenient interactive bullet-time design and photo-realistic human free-viewpoint video generation.
Relightable Neural Video Portrait
Jul 30, 2021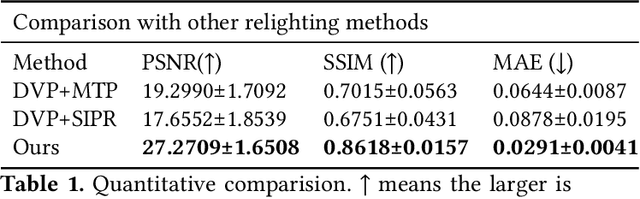
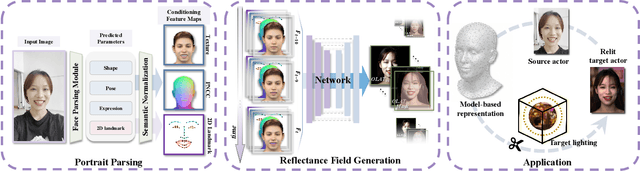

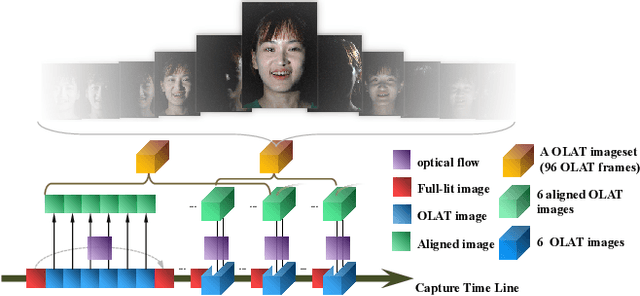
Photo-realistic facial video portrait reenactment benefits virtual production and numerous VR/AR experiences. The task remains challenging as the portrait should maintain high realism and consistency with the target environment. In this paper, we present a relightable neural video portrait, a simultaneous relighting and reenactment scheme that transfers the head pose and facial expressions from a source actor to a portrait video of a target actor with arbitrary new backgrounds and lighting conditions. Our approach combines 4D reflectance field learning, model-based facial performance capture and target-aware neural rendering. Specifically, we adopt a rendering-to-video translation network to first synthesize high-quality OLAT imagesets and alpha mattes from hybrid facial performance capture results. We then design a semantic-aware facial normalization scheme to enable reliable explicit control as well as a multi-frame multi-task learning strategy to encode content, segmentation and temporal information simultaneously for high-quality reflectance field inference. After training, our approach further enables photo-realistic and controllable video portrait editing of the target performer. Reliable face poses and expression editing is obtained by applying the same hybrid facial capture and normalization scheme to the source video input, while our explicit alpha and OLAT output enable high-quality relit and background editing. With the ability to achieve simultaneous relighting and reenactment, we are able to improve the realism in a variety of virtual production and video rewrite applications.
Few-shot Neural Human Performance Rendering from Sparse RGBD Videos
Jul 14, 2021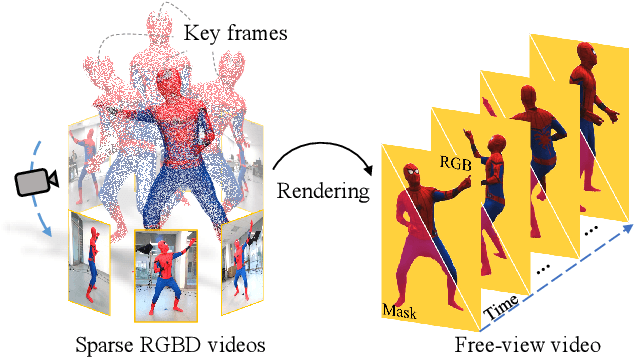
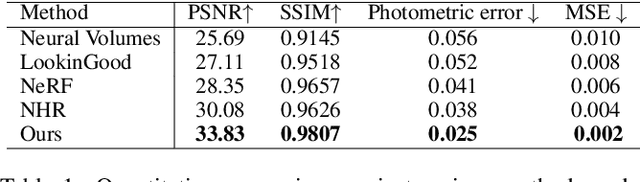
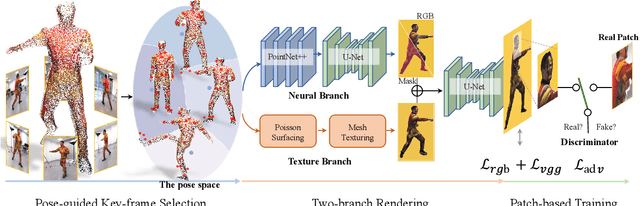
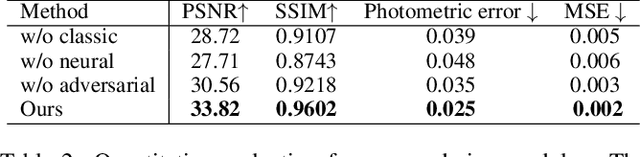
Recent neural rendering approaches for human activities achieve remarkable view synthesis results, but still rely on dense input views or dense training with all the capture frames, leading to deployment difficulty and inefficient training overload. However, existing advances will be ill-posed if the input is both spatially and temporally sparse. To fill this gap, in this paper we propose a few-shot neural human rendering approach (FNHR) from only sparse RGBD inputs, which exploits the temporal and spatial redundancy to generate photo-realistic free-view output of human activities. Our FNHR is trained only on the key-frames which expand the motion manifold in the input sequences. We introduce a two-branch neural blending to combine the neural point render and classical graphics texturing pipeline, which integrates reliable observations over sparse key-frames. Furthermore, we adopt a patch-based adversarial training process to make use of the local redundancy and avoids over-fitting to the key-frames, which generates fine-detailed rendering results. Extensive experiments demonstrate the effectiveness of our approach to generate high-quality free view-point results for challenging human performances under the sparse setting.
PIANO: A Parametric Hand Bone Model from Magnetic Resonance Imaging
Jun 21, 2021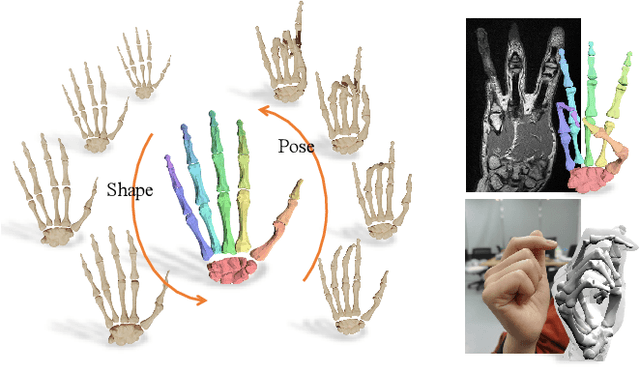
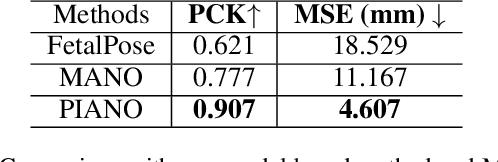

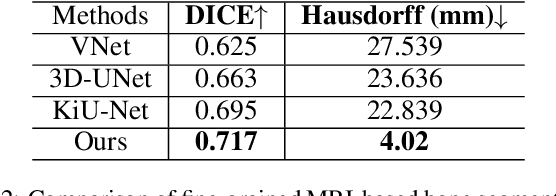
Hand modeling is critical for immersive VR/AR, action understanding, or human healthcare. Existing parametric models account only for hand shape, pose, or texture, without modeling the anatomical attributes like bone, which is essential for realistic hand biomechanics analysis. In this paper, we present PIANO, the first parametric bone model of human hands from MRI data. Our PIANO model is biologically correct, simple to animate, and differentiable, achieving more anatomically precise modeling of the inner hand kinematic structure in a data-driven manner than the traditional hand models based on the outer surface only. Furthermore, our PIANO model can be applied in neural network layers to enable training with a fine-grained semantic loss, which opens up the new task of data-driven fine-grained hand bone anatomic and semantic understanding from MRI or even RGB images. We make our model publicly available.