 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUA: Mobile Ultra-detailed Animatable Avatars
Apr 20, 2026Building photorealistic, animatable full-body digital humans remains a longstanding challenge in computer graphics and vision. Recent advances in animatable avatar modeling have largely progressed along two directions: improving the fidelity of dynamic geometry and appearance, or reducing computational complexity to enable deployment on resource-constrained platforms, e.g., VR headsets. However, existing approaches fail to achieve both goals simultaneously: Ultra-high-fidelity avatars typically require substantial computation on server-class GPUs, whereas lightweight avatars often suffer from limited surface dynamics, reduced appearance details, and noticeable artifacts. To bridge this gap, we propose a novel animatable avatar representation, termed Wavelet-guided Multi-level Spatial Factorized Blendshapes, and a corresponding distillation pipeline that transfers motion-aware clothing dynamics and fine-grained appearance details from a pre-trained ultra-high-quality avatar model into a compact, efficient representation. By coupling multi-level wavelet spectral decomposition with low-rank structural factorization in texture space, our method achieves up to 2000X lower computational cost and a 10X smaller model size than the original high-quality teacher avatar model, while preserving visually plausible dynamics and appearance details closely resemble those of the teacher model. Extensive comparisons with state-of-the-art methods show that our approach significantly outperforms existing avatar approaches designed for mobile settings and achieves comparable or superior rendering quality to most approaches that can only run on servers. Importantly, our representation substantially improves the practicality of high-fidelity avatars for immersive applications, achieving over 180 FPS on a desktop PC and real-time native on-device performance at 24 FPS on a standalone Meta Quest 3.
Hyper Diffusion Avatars: Dynamic Human Avatar Generation using Network Weight Space Diffusion
Sep 04, 2025Creating human avatars is a highly desirable yet challenging task. Recent advancements in radiance field rendering have achieved unprecedented photorealism and real-time performance for personalized dynamic human avatars. However, these approaches are typically limited to person-specific rendering models trained on multi-view video data for a single individual, limiting their ability to generalize across different identities. On the other hand, generative approaches leveraging prior knowledge from pre-trained 2D diffusion models can produce cartoonish, static human avatars, which are animated through simple skeleton-based articulation. Therefore, the avatars generated by these methods suffer from lower rendering quality compared to person-specific rendering methods and fail to capture pose-dependent deformations such as cloth wrinkles. In this paper, we propose a novel approach that unites the strengths of person-specific rendering and diffusion-based generative modeling to enable dynamic human avatar generation with both high photorealism and realistic pose-dependent deformations. Our method follows a two-stage pipeline: first, we optimize a set of person-specific UNets, with each network representing a dynamic human avatar that captures intricate pose-dependent deformations. In the second stage, we train a hyper diffusion model over the optimized network weights. During inference, our method generates network weights for real-time, controllable rendering of dynamic human avatars. Using a large-scale, cross-identity, multi-view video dataset, we demonstrate that our approach outperforms state-of-the-art human avatar generation methods.
EVA: Expressive Virtual Avatars from Multi-view Videos
May 21, 2025

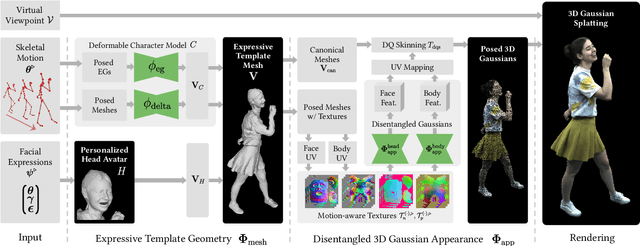

With recent advancements in neural rendering and motion capture algorithms, remarkable progress has been made in photorealistic human avatar modeling, unlocking immense potential for applications in virtual reality, augmented reality, remote communication, and industries such as gaming, film, and medicine. However, existing methods fail to provide complete, faithful, and expressive control over human avatars due to their entangled representation of facial expressions and body movements. In this work, we introduce Expressive Virtual Avatars (EVA), an actor-specific, fully controllable, and expressive human avatar framework that achieves high-fidelity, lifelike renderings in real time while enabling independent control of facial expressions, body movements, and hand gestures. Specifically, our approach designs the human avatar as a two-layer model: an expressive template geometry layer and a 3D Gaussian appearance layer. First, we present an expressive template tracking algorithm that leverages coarse-to-fine optimization to accurately recover body motions, facial expressions, and non-rigid deformation parameters from multi-view videos. Next, we propose a novel decoupled 3D Gaussian appearance model designed to effectively disentangle body and facial appearance. Unlike unified Gaussian estimation approaches, our method employs two specialized and independent modules to model the body and face separately. Experimental results demonstrate that EVA surpasses state-of-the-art methods in terms of rendering quality and expressiveness, validating its effectiveness in creating full-body avatars. This work represents a significant advancement towards fully drivable digital human models, enabling the creation of lifelike digital avatars that faithfully replicate human geometry and appearance.
Real-time Free-view Human Rendering from Sparse-view RGB Videos using Double Unprojected Textures
Dec 17, 2024



Real-time free-view human rendering from sparse-view RGB inputs is a challenging task due to the sensor scarcity and the tight time budget. To ensure efficiency, recent methods leverage 2D CNNs operating in texture space to learn rendering primitives. However, they either jointly learn geometry and appearance, or completely ignore sparse image information for geometry estimation, significantly harming visual quality and robustness to unseen body poses. To address these issues, we present Double Unprojected Textures, which at the core disentangles coarse geometric deformation estimation from appearance synthesis, enabling robust and photorealistic 4K rendering in real-time. Specifically, we first introduce a novel image-conditioned template deformation network, which estimates the coarse deformation of the human template from a first unprojected texture. This updated geometry is then used to apply a second and more accurate texture unprojection. The resulting texture map has fewer artifacts and better alignment with input views, which benefits our learning of finer-level geometry and appearance represented by Gaussian splats. We validate the effectiveness and efficiency of the proposed method in quantitative and qualitative experiments, which significantly surpasses other state-of-the-art methods.
MetaCap: Meta-learning Priors from Multi-View Imagery for Sparse-view Human Performance Capture and Rendering
Mar 27, 2024



Faithful human performance capture and free-view rendering from sparse RGB observations is a long-standing problem in Vision and Graphics. The main challenges are the lack of observations and the inherent ambiguities of the setting, e.g. occlusions and depth ambiguity. As a result, radiance fields, which have shown great promise in capturing high-frequency appearance and geometry details in dense setups, perform poorly when na\"ively supervising them on sparse camera views, as the field simply overfits to the sparse-view inputs. To address this, we propose MetaCap, a method for efficient and high-quality geometry recovery and novel view synthesis given very sparse or even a single view of the human. Our key idea is to meta-learn the radiance field weights solely from potentially sparse multi-view videos, which can serve as a prior when fine-tuning them on sparse imagery depicting the human. This prior provides a good network weight initialization, thereby effectively addressing ambiguities in sparse-view capture. Due to the articulated structure of the human body and motion-induced surface deformations, learning such a prior is non-trivial. Therefore, we propose to meta-learn the field weights in a pose-canonicalized space, which reduces the spatial feature range and makes feature learning more effective. Consequently, one can fine-tune our field parameters to quickly generalize to unseen poses, novel illumination conditions as well as novel and sparse (even monocular) camera views. For evaluating our method under different scenarios, we collect a new dataset, WildDynaCap, which contains subjects captured in, both, a dense camera dome and in-the-wild sparse camera rigs, and demonstrate superior results compared to recent state-of-the-art methods on both public and WildDynaCap dataset.
Holoported Characters: Real-time Free-viewpoint Rendering of Humans from Sparse RGB Cameras
Dec 12, 2023



We present the first approach to render highly realistic free-viewpoint videos of a human actor in general apparel, from sparse multi-view recording to display, in real-time at an unprecedented 4K resolution. At inference, our method only requires four camera views of the moving actor and the respective 3D skeletal pose. It handles actors in wide clothing, and reproduces even fine-scale dynamic detail, e.g. clothing wrinkles, face expressions, and hand gestures. At training time, our learning-based approach expects dense multi-view video and a rigged static surface scan of the actor. Our method comprises three main stages. Stage 1 is a skeleton-driven neural approach for high-quality capture of the detailed dynamic mesh geometry. Stage 2 is a novel solution to create a view-dependent texture using four test-time camera views as input. Finally, stage 3 comprises a new image-based refinement network rendering the final 4K image given the output from the previous stages. Our approach establishes a new benchmark for real-time rendering resolution and quality using sparse input camera views, unlocking possibilities for immersive telepresence.
NeuralHOFusion: Neural Volumetric Rendering under Human-object Interactions
Mar 28, 2022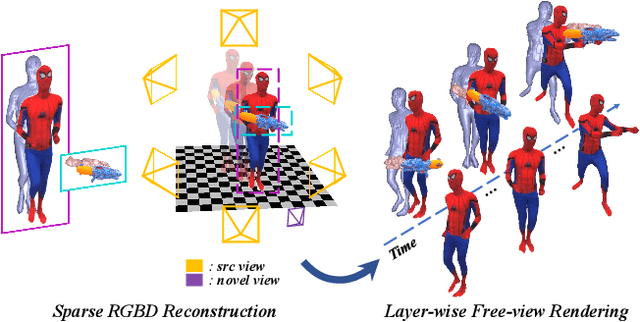
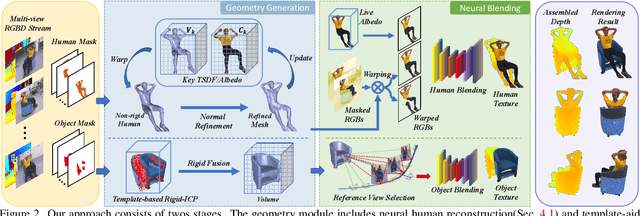
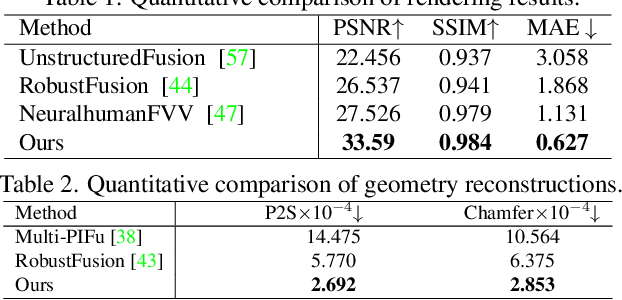
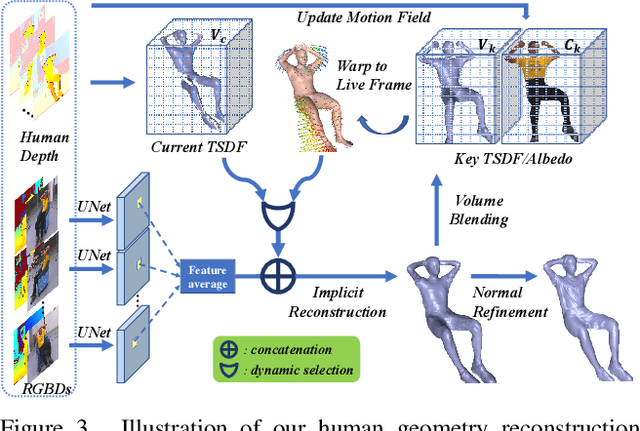
4D modeling of human-object interactions is critical for numerous applications. However, efficient volumetric capture and rendering of complex interaction scenarios, especially from sparse inputs, remain challenging. In this paper, we propose NeuralHOFusion, a neural approach for volumetric human-object capture and rendering using sparse consumer RGBD sensors. It marries traditional non-rigid fusion with recent neural implicit modeling and blending advances, where the captured humans and objects are layerwise disentangled. For geometry modeling, we propose a neural implicit inference scheme with non-rigid key-volume fusion, as well as a template-aid robust object tracking pipeline. Our scheme enables detailed and complete geometry generation under complex interactions and occlusions. Moreover, we introduce a layer-wise human-object texture rendering scheme, which combines volumetric and image-based rendering in both spatial and temporal domains to obtain photo-realistic results. Extensive experiments demonstrate the effectiveness and efficiency of our approach in synthesizing photo-realistic free-view results under complex human-object interactions.
Neural Free-Viewpoint Performance Rendering under Complex Human-object Interactions
Aug 03, 2021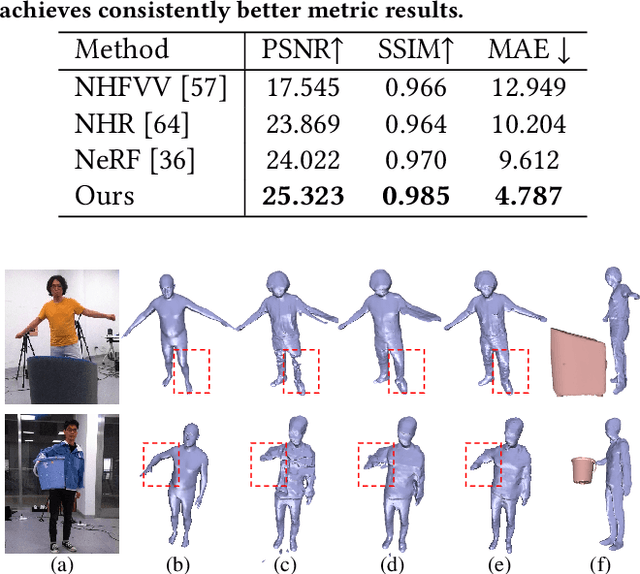
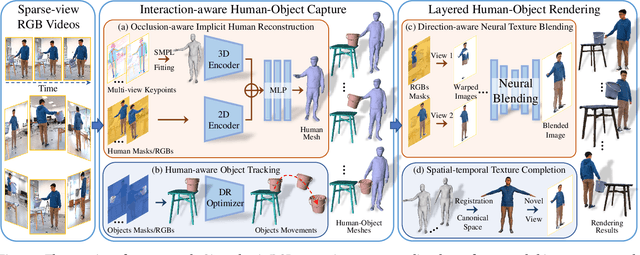
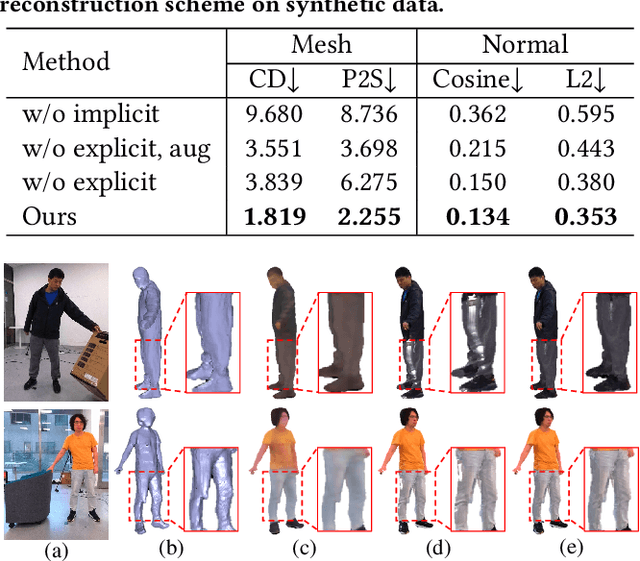

4D reconstruction of human-object interaction is critical for immersive VR/AR experience and human activity understanding. Recent advances still fail to recover fine geometry and texture results from sparse RGB inputs, especially under challenging human-object interactions scenarios. In this paper, we propose a neural human performance capture and rendering system to generate both high-quality geometry and photo-realistic texture of both human and objects under challenging interaction scenarios in arbitrary novel views, from only sparse RGB streams. To deal with complex occlusions raised by human-object interactions, we adopt a layer-wise scene decoupling strategy and perform volumetric reconstruction and neural rendering of the human and object. Specifically, for geometry reconstruction, we propose an interaction-aware human-object capture scheme that jointly considers the human reconstruction and object reconstruction with their correlations. Occlusion-aware human reconstruction and robust human-aware object tracking are proposed for consistent 4D human-object dynamic reconstruction. For neural texture rendering, we propose a layer-wise human-object rendering scheme, which combines direction-aware neural blending weight learning and spatial-temporal texture completion to provide high-resolution and photo-realistic texture results in the occluded scenarios. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality geometry and texture reconstruction in free viewpoints for challenging human-object interactions.