 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Adaptive Normalization for Single Domain Generalization
Jun 01, 2021
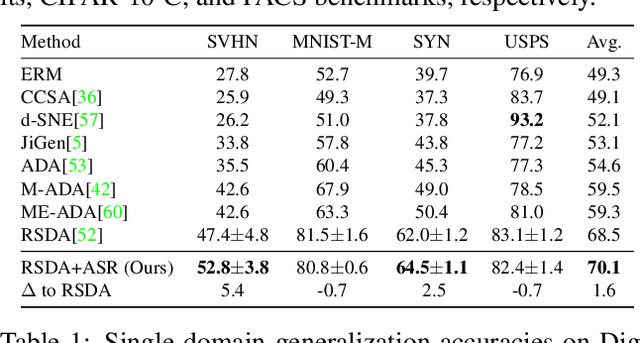
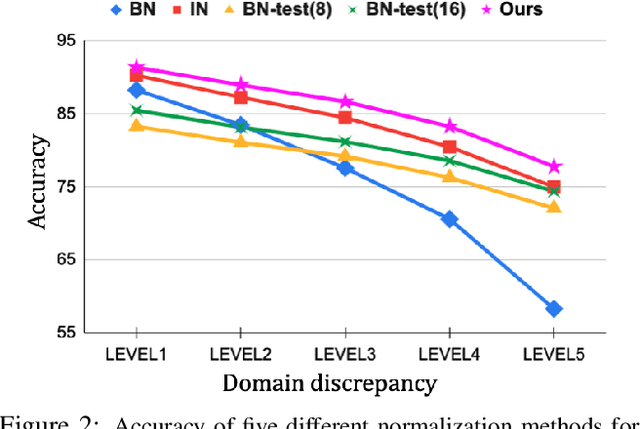
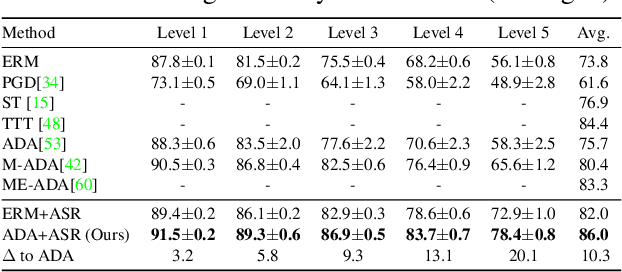
Single domain generalization aims to learn a model that performs well on many unseen domains with only one domain data for training. Existing works focus on studying the adversarial domain augmentation (ADA) to improve the model's generalization capability. The impact on domain generalization of the statistics of normalization layers is still underinvestigated. In this paper, we propose a generic normalization approach, adaptive standardization and rescaling normalization (ASR-Norm), to complement the missing part in previous works. ASR-Norm learns both the standardization and rescaling statistics via neural networks. This new form of normalization can be viewed as a generic form of the traditional normalizations. When trained with ADA, the statistics in ASR-Norm are learned to be adaptive to the data coming from different domains, and hence improves the model generalization performance across domains, especially on the target domain with large discrepancy from the source domain. The experimental results show that ASR-Norm can bring consistent improvement to the state-of-the-art ADA approaches by 1.6%, 2.7%, and 6.3% averagely on the Digits, CIFAR-10-C, and PACS benchmarks, respectively. As a generic tool, the improvement introduced by ASR-Norm is agnostic to the choice of ADA methods.
ARMS: Antithetic-REINFORCE-Multi-Sample Gradient for Binary Variables
May 28, 2021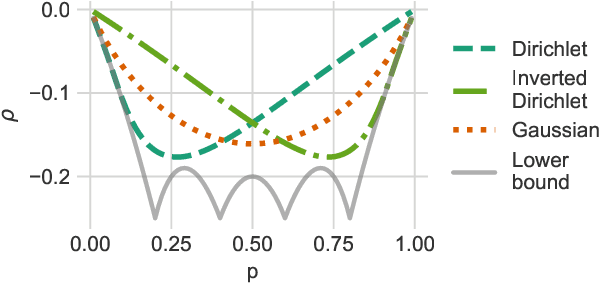
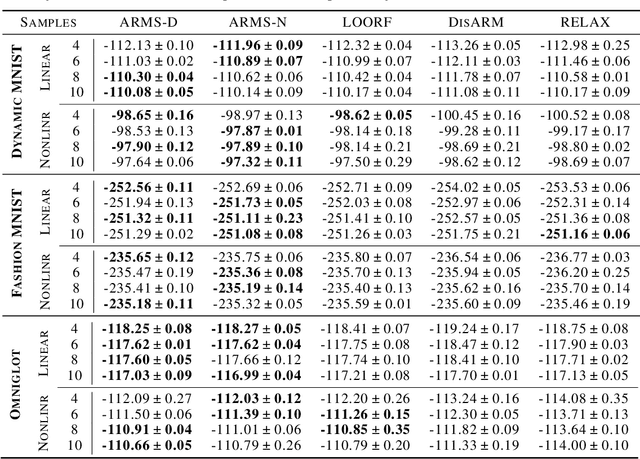
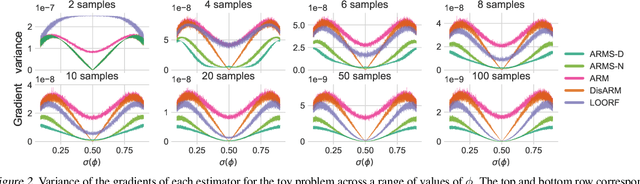
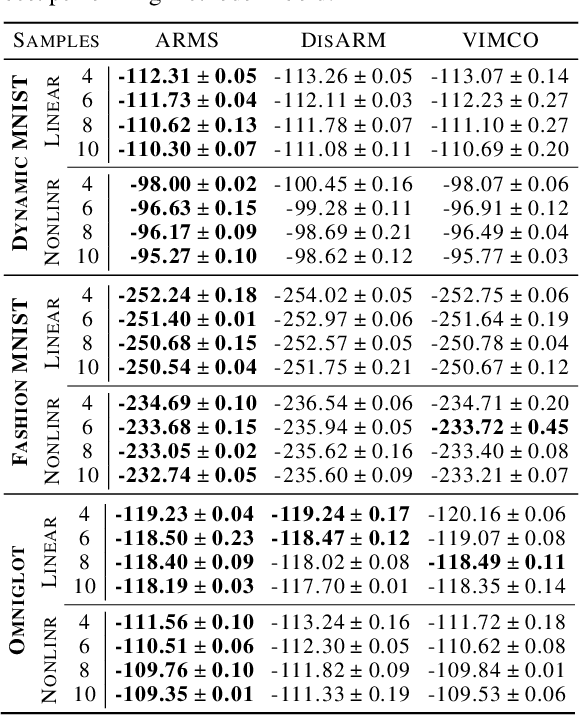
Estimating the gradients for binary variables is a task that arises frequently in various domains, such as training discrete latent variable models. What has been commonly used is a REINFORCE based Monte Carlo estimation method that uses either independent samples or pairs of negatively correlated samples. To better utilize more than two samples, we propose ARMS, an Antithetic REINFORCE-based Multi-Sample gradient estimator. ARMS uses a copula to generate any number of mutually antithetic samples. It is unbiased, has low variance, and generalizes both DisARM, which we show to be ARMS with two samples, and the leave-one-out REINFORCE (LOORF) estimator, which is ARMS with uncorrelated samples. We evaluate ARMS on several datasets for training generative models, and our experimental results show that it outperforms competing methods. We also develop a version of ARMS for optimizing the multi-sample variational bound, and show that it outperforms both VIMCO and DisARM. The code is publicly available.
Matching Visual Features to Hierarchical Semantic Topics for Image Paragraph Captioning
May 10, 2021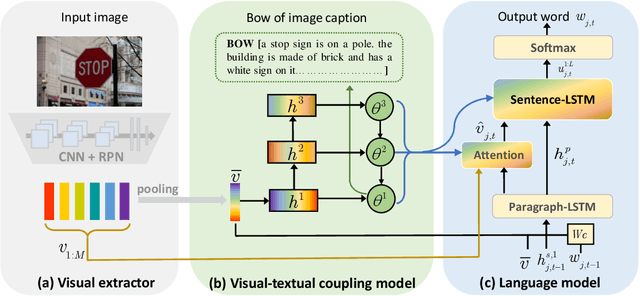
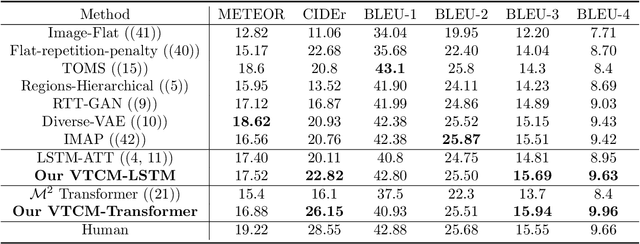
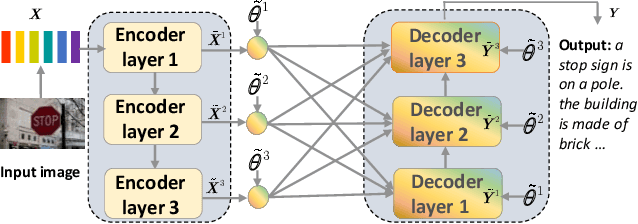
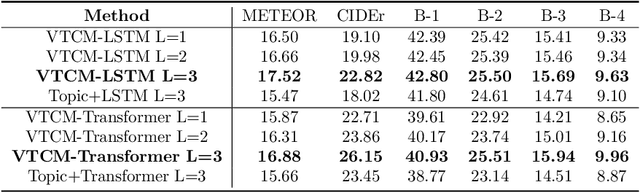
Observing a set of images and their corresponding paragraph-captions, a challenging task is to learn how to produce a semantically coherent paragraph to describe the visual content of an image. Inspired by recent successes in integrating semantic topics into this task, this paper develops a plug-and-play hierarchical-topic-guided image paragraph generation framework, which couples a visual extractor with a deep topic model to guide the learning of a language model. To capture the correlations between the image and text at multiple levels of abstraction and learn the semantic topics from images, we design a variational inference network to build the mapping from image features to textual captions. To guide the paragraph generation, the learned hierarchical topics and visual features are integrated into the language model, including Long Short-Term Memory (LSTM) and Transformer, and jointly optimized. Experiments on public dataset demonstrate that the proposed models, which are competitive with many state-of-the-art approaches in terms of standard evaluation metrics, can be used to both distill interpretable multi-layer topics and generate diverse and coherent captions.
Contrastive Conditional Transport for Representation Learning
May 08, 2021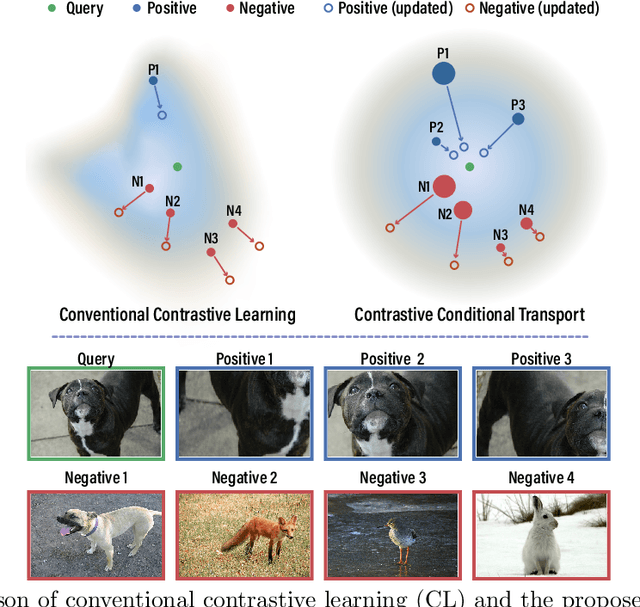
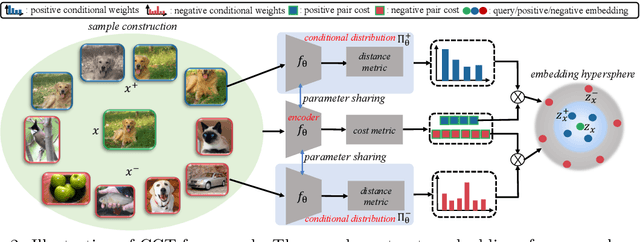
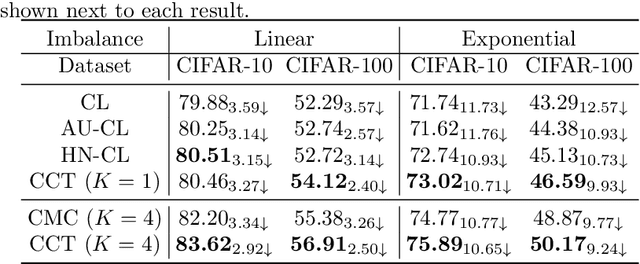
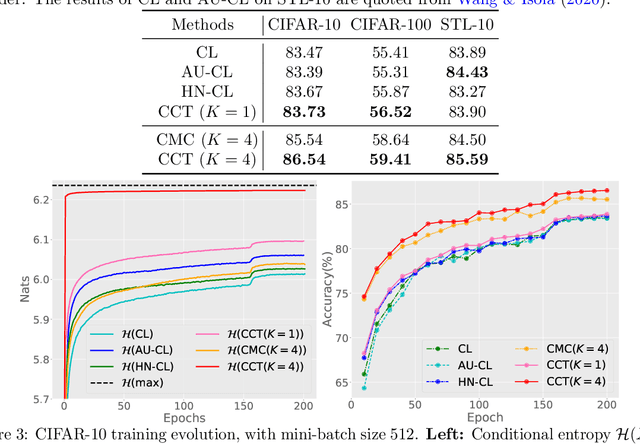
Contrastive learning (CL) has achieved remarkable success in learning data representations without label supervision. However, the conventional CL loss is sensitive to how many negative samples are included and how they are selected. This paper proposes contrastive conditional transport (CCT) that defines its CL loss over dependent sample-query pairs, which in practice is realized by drawing a random query, randomly selecting positive and negative samples, and contrastively reweighting these samples according to their distances to the query, exerting a greater force to both pull more distant positive samples towards the query and push closer negative samples away from the query. Theoretical analysis shows that this unique contrastive reweighting scheme helps in the representation space to both align the positive samples with the query and reduce the mutual information between the negative sample and query. Extensive large-scale experiments on standard vision tasks show that CCT not only consistently outperforms existing methods on benchmark datasets in contrastive representation learning but also provides interpretable contrastive weights and latent representations. PyTorch code will be provided.
Partition-Guided GANs
Apr 02, 2021
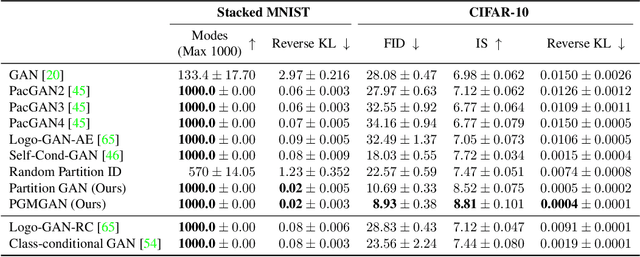
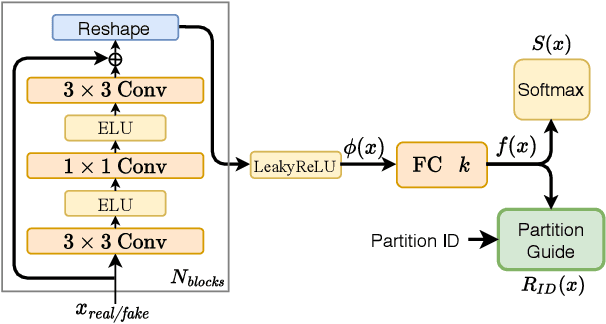

Despite the success of Generative Adversarial Networks (GANs), their training suffers from several well-known problems, including mode collapse and difficulties learning a disconnected set of manifolds. In this paper, we break down the challenging task of learning complex high dimensional distributions, supporting diverse data samples, to simpler sub-tasks. Our solution relies on designing a partitioner that breaks the space into smaller regions, each having a simpler distribution, and training a different generator for each partition. This is done in an unsupervised manner without requiring any labels. We formulate two desired criteria for the space partitioner that aid the training of our mixture of generators: 1) to produce connected partitions and 2) provide a proxy of distance between partitions and data samples, along with a direction for reducing that distance. These criteria are developed to avoid producing samples from places with non-existent data density, and also facilitate training by providing additional direction to the generators. We develop theoretical constraints for a space partitioner to satisfy the above criteria. Guided by our theoretical analysis, we design an effective neural architecture for the space partitioner that empirically assures these conditions. Experimental results on various standard benchmarks show that the proposed unsupervised model outperforms several recent methods.
Contextual Dropout: An Efficient Sample-Dependent Dropout Module
Mar 06, 2021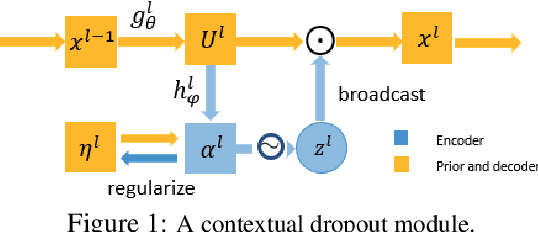
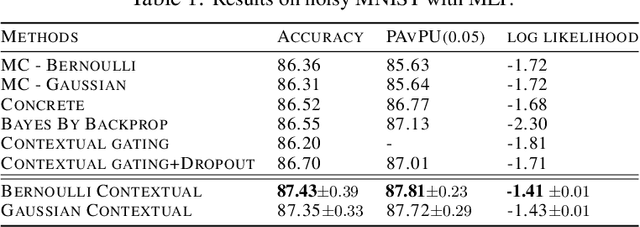
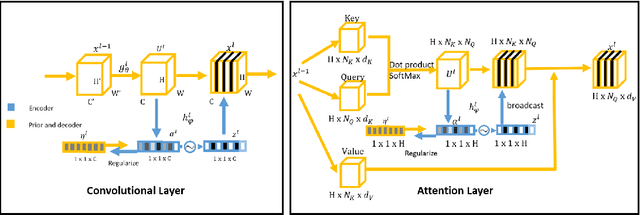
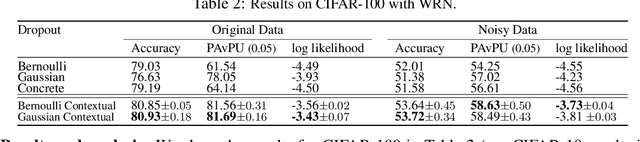
Dropout has been demonstrated as a simple and effective module to not only regularize the training process of deep neural networks, but also provide the uncertainty estimation for prediction. However, the quality of uncertainty estimation is highly dependent on the dropout probabilities. Most current models use the same dropout distributions across all data samples due to its simplicity. Despite the potential gains in the flexibility of modeling uncertainty, sample-dependent dropout, on the other hand, is less explored as it often encounters scalability issues or involves non-trivial model changes. In this paper, we propose contextual dropout with an efficient structural design as a simple and scalable sample-dependent dropout module, which can be applied to a wide range of models at the expense of only slightly increased memory and computational cost. We learn the dropout probabilities with a variational objective, compatible with both Bernoulli dropout and Gaussian dropout. We apply the contextual dropout module to various models with applications to image classification and visual question answering and demonstrate the scalability of the method with large-scale datasets, such as ImageNet and VQA 2.0. Our experimental results show that the proposed method outperforms baseline methods in terms of both accuracy and quality of uncertainty estimation.
Self-supervised Pre-training with Hard Examples Improves Visual Representations
Jan 04, 2021
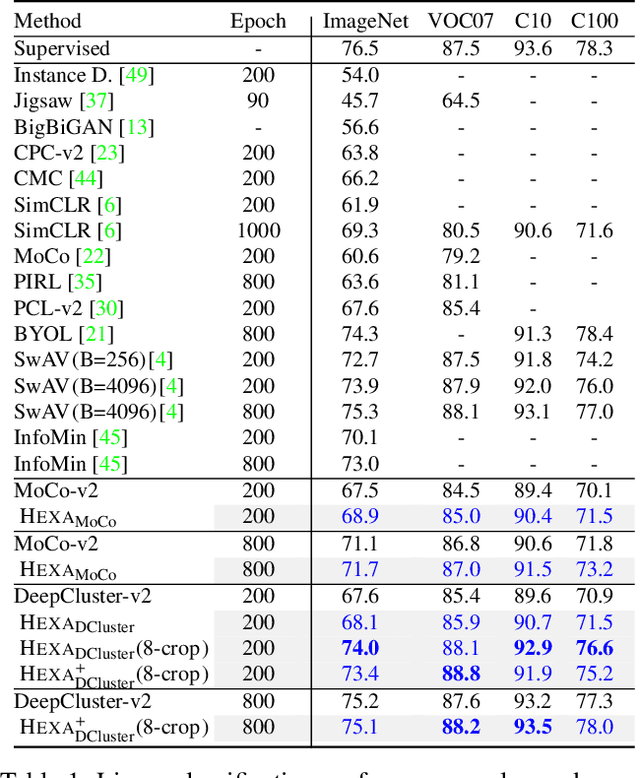
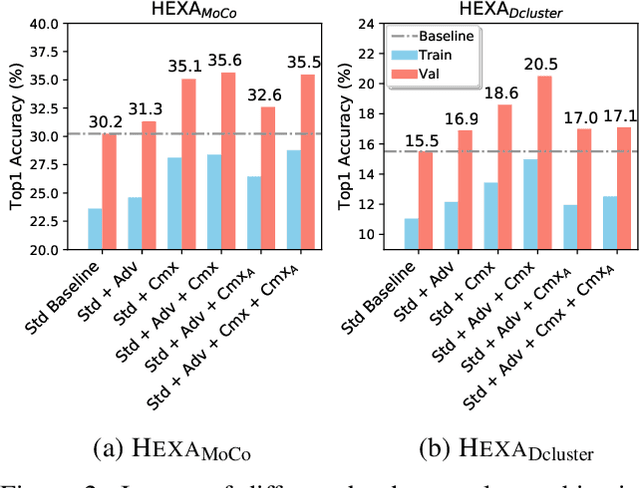
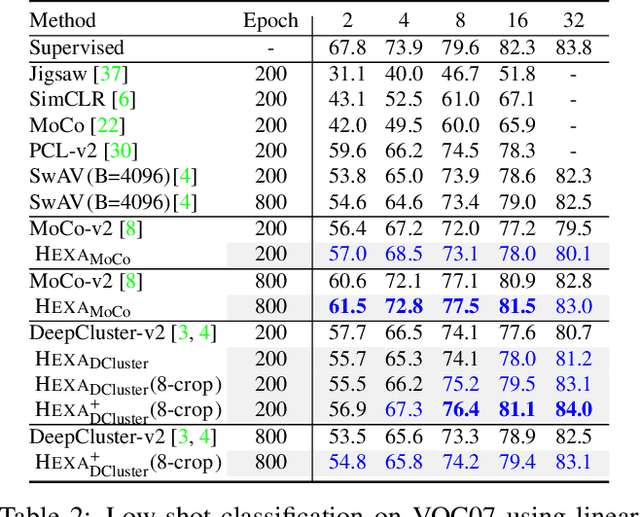
Self-supervised pre-training (SSP) employs random image transformations to generate training data for visual representation learning. In this paper, we first present a modeling framework that unifies existing SSP methods as learning to predict pseudo-labels. Then, we propose new data augmentation methods of generating training examples whose pseudo-labels are harder to predict than those generated via random image transformations. Specifically, we use adversarial training and CutMix to create hard examples (HEXA) to be used as augmented views for MoCo-v2 and DeepCluster-v2, leading to two variants HEXA_{MoCo} and HEXA_{DCluster}, respectively. In our experiments, we pre-train models on ImageNet and evaluate them on multiple public benchmarks. Our evaluation shows that the two new algorithm variants outperform their original counterparts, and achieve new state-of-the-art on a wide range of tasks where limited task supervision is available for fine-tuning. These results verify that hard examples are instrumental in improving the generalization of the pre-trained models.
ACT: Asymptotic Conditional Transport
Dec 28, 2020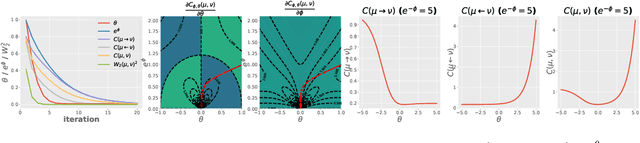
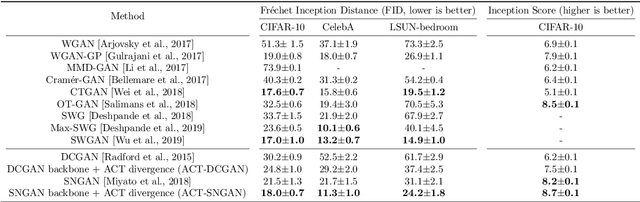
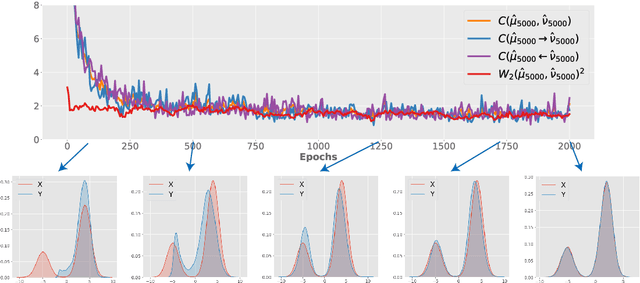
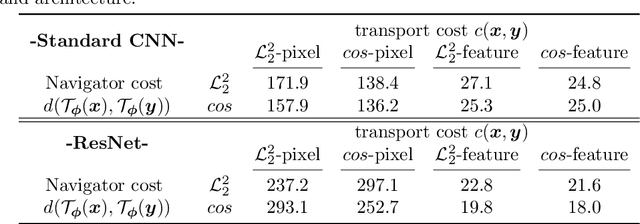
We propose conditional transport (CT) as a new divergence to measure the difference between two probability distributions. The CT divergence consists of the expected cost of a forward CT, which constructs a navigator to stochastically transport a data point of one distribution to the other distribution, and that of a backward CT which reverses the transport direction. To apply it to the distributions whose probability density functions are unknown but random samples are accessible, we further introduce asymptotic CT (ACT), whose estimation only requires access to mini-batch based discrete empirical distributions. Equipped with two navigators that amortize the computation of conditional transport plans, the ACT divergence comes with unbiased sample gradients that are straightforward to compute, making it amenable to mini-batch stochastic gradient descent based optimization. When applied to train a generative model, the ACT divergence is shown to strike a good balance between mode covering and seeking behaviors and strongly resist mode collapse. To model high-dimensional data, we show that it is sufficient to modify the adversarial game of an existing generative adversarial network (GAN) to a game played by a generator, a forward navigator, and a backward navigator, which try to minimize a distribution-to-distribution transport cost by optimizing both the distribution of the generator and conditional transport plans specified by the navigators, versus a critic that does the opposite by inflating the point-to-point transport cost. On a wide variety of benchmark datasets for generative modeling, substituting the default statistical distance of an existing GAN with the ACT divergence is shown to consistently improve the performance.
Hyperbolic Graph Embedding with Enhanced Semi-Implicit Variational Inference
Oct 31, 2020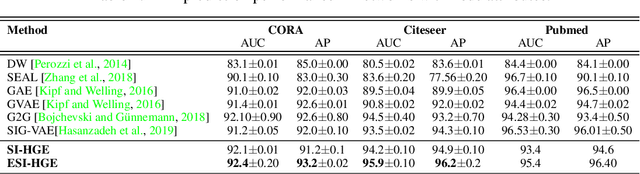
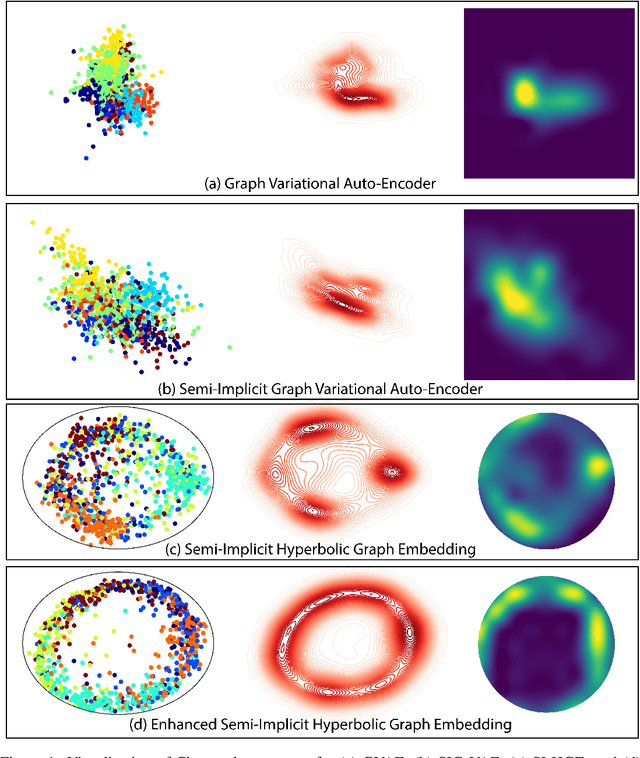
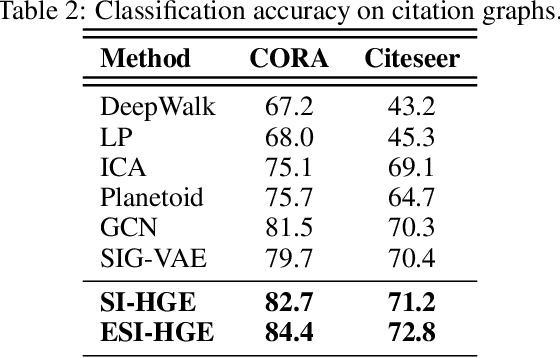
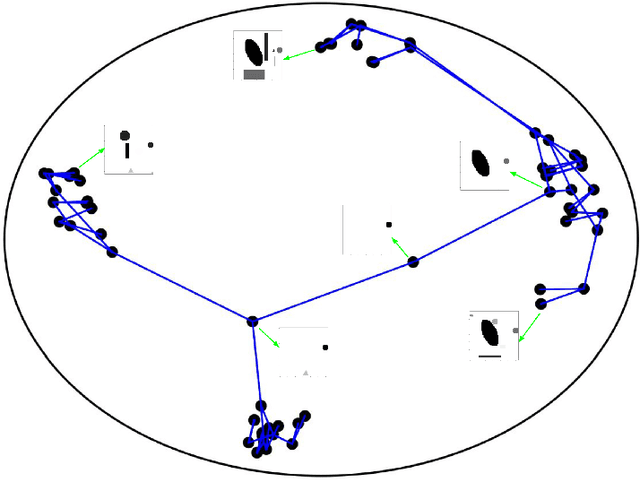
Efficient modeling of relational data arising in physical, social, and information sciences is challenging due to complicated dependencies within the data. In this work we build off of semi-implicit graph variational auto-encoders to capture higher order statistics in a low-dimensional graph latent representation. We incorporate hyperbolic geometry in the latent space through a \poincare embedding to efficiently represent graphs exhibiting hierarchical structure. To address the naive posterior latent distribution assumptions in classical variational inference, we use semi-implicit hierarchical variational Bayes to implicitly capture posteriors of given graph data, which may exhibit heavy tails, multiple modes, skewness, and highly correlated latent structures. We show that the existing semi-implicit variational inference objective provably reduces information in the observed graph. Based on this observation, we estimate and add an additional mutual information term to the semi-implicit variational inference learning objective to capture rich correlations arising between the input and latent spaces. We show that the inclusion of this regularization term in conjunction with the \poincare embedding boosts the quality of learned high-level representations and enables more flexible and faithful graphical modeling. We experimentally demonstrate that our approach outperforms existing graph variational auto-encoders both in Euclidean and in hyperbolic spaces for edge link prediction and node classification.
Convex Polytope Trees
Oct 21, 2020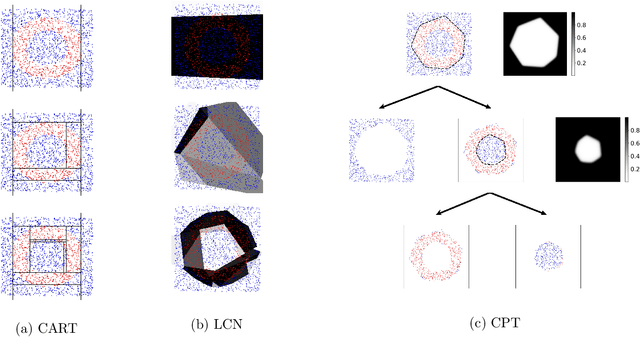

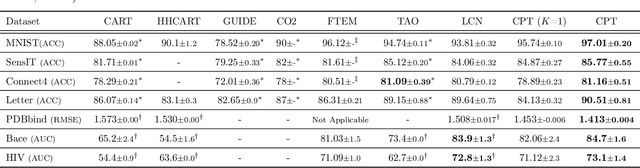
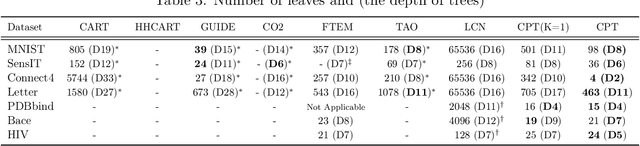
A decision tree is commonly restricted to use a single hyperplane to split the covariate space at each of its internal nodes. It often requires a large number of nodes to achieve high accuracy, hurting its interpretability. In this paper, we propose convex polytope trees (CPT) to expand the family of decision trees by an interpretable generalization of their decision boundary. The splitting function at each node of CPT is based on the logical disjunction of a community of differently weighted probabilistic linear decision-makers, which also geometrically corresponds to a convex polytope in the covariate space. We use a nonparametric Bayesian prior at each node to infer the community's size, encouraging simpler decision boundaries by shrinking the number of polytope facets. We develop a greedy method to efficiently construct CPT and scalable end-to-end training algorithms for the tree parameters when the tree structure is given. We empirically demonstrate the efficiency of CPT over existing state-of-the-art decision trees in several real-world classification and regression tasks from diverse domains.