 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePublic transit gains and spatially uneven travel demand changes after NYC congestion pricing
Jun 16, 2026New York City implemented the nation's first cordon-based congestion pricing program in January 2025, providing an opportunity to evaluate how system-wide urban mobility responds to large-scale pricing interventions. Because such policies generate spillovers across modes and locations, credible control groups are difficult to construct. We address this challenge using time series foundation models to generate probabilistic counterfactual demand forecasts with calibrated uncertainty. Applying this framework to bus, subway, and aggregate trip volume data, we find that post-policy bus and subway ridership increased significantly relative to expected no-policy demand, while overall travel demand decreased modestly. The effects are spatially heterogeneous: while reductions in overall travel demand are concentrated within the Congestion Relief Zone, transit gains extend beyond Manhattan's core. Socio-demographic analyses further reveal uneven adaptation across neighborhoods, highlighting spatial equity implications. Our framework provides a scalable approach for the uncertainty-aware evaluation of system-wide urban interventions when clean control groups are unavailable.
Envisioning global urban development with satellite imagery and generative AI
Mar 27, 2026Urban development has been a defining force in human history, shaping cities for centuries. However, past studies mostly analyze such development as predictive tasks, failing to reflect its generative nature. Therefore, this study designs a multimodal generative AI framework to envision sustainable urban development at a global scale. By integrating prompts and geospatial controls, our framework can generate high-fidelity, diverse, and realistic urban satellite imagery across the 500 largest metropolitan areas worldwide. It enables users to specify urban development goals, creating new images that align with them while offering diverse scenarios whose appearance can be controlled with text prompts and geospatial constraints. It also facilitates urban redevelopment practices by learning from the surrounding environment. Beyond visual synthesis, we find that it encodes and interprets latent representations of urban form for global cross-city learning, successfully transferring styles of urban environments across a global spatial network. The latent representations can also enhance downstream prediction tasks such as carbon emission prediction. Further, human expert evaluation confirms that our generated urban images are comparable to real urban images. Overall, this study presents innovative approaches for accelerated urban planning and supports scenario-based planning processes for worldwide cities.
TrustEnergy: A Unified Framework for Accurate and Reliable User-level Energy Usage Prediction
Jan 19, 2026Energy usage prediction is important for various real-world applications, including grid management, infrastructure planning, and disaster response. Although a plethora of deep learning approaches have been proposed to perform this task, most of them either overlook the essential spatial correlations across households or fail to scale to individualized prediction, making them less effective for accurate fine-grained user-level prediction. In addition, due to the dynamic and uncertain nature of energy usage caused by various factors such as extreme weather events, quantifying uncertainty for reliable prediction is also significant, but it has not been fully explored in existing work. In this paper, we propose a unified framework called TrustEnergy for accurate and reliable user-level energy usage prediction. There are two key technical components in TrustEnergy, (i) a Hierarchical Spatiotemporal Representation module to efficiently capture both macro and micro energy usage patterns with a novel memory-augmented spatiotemporal graph neural network, and (ii) an innovative Sequential Conformalized Quantile Regression module to dynamically adjust uncertainty bounds to ensure valid prediction intervals over time, without making strong assumptions about the underlying data distribution. We implement and evaluate our TrustEnergy framework by working with an electricity provider in Florida, and the results show our TrustEnergy can achieve a 5.4% increase in prediction accuracy and 5.7% improvement in uncertainty quantification compared to state-of-the-art baselines.
RAST-MoE-RL: A Regime-Aware Spatio-Temporal MoE Framework for Deep Reinforcement Learning in Ride-Hailing
Dec 13, 2025Ride-hailing platforms face the challenge of balancing passenger waiting times with overall system efficiency under highly uncertain supply-demand conditions. Adaptive delayed matching creates a trade-off between matching and pickup delays by deciding whether to assign drivers immediately or batch requests. Since outcomes accumulate over long horizons with stochastic dynamics, reinforcement learning (RL) is a suitable framework. However, existing approaches often oversimplify traffic dynamics or use shallow encoders that miss complex spatiotemporal patterns. We introduce the Regime-Aware Spatio-Temporal Mixture-of-Experts (RAST-MoE), which formalizes adaptive delayed matching as a regime-aware MDP equipped with a self-attention MoE encoder. Unlike monolithic networks, our experts specialize automatically, improving representation capacity while maintaining computational efficiency. A physics-informed congestion surrogate preserves realistic density-speed feedback, enabling millions of efficient rollouts, while an adaptive reward scheme guards against pathological strategies. With only 12M parameters, our framework outperforms strong baselines. On real-world Uber trajectory data (San Francisco), it improves total reward by over 13%, reducing average matching and pickup delays by 10% and 15% respectively. It demonstrates robustness across unseen demand regimes and stable training. These findings highlight the potential of MoE-enhanced RL for large-scale decision-making with complex spatiotemporal dynamics.
NestGNN: A Graph Neural Network Framework Generalizing the Nested Logit Model for Travel Mode Choice
Sep 08, 2025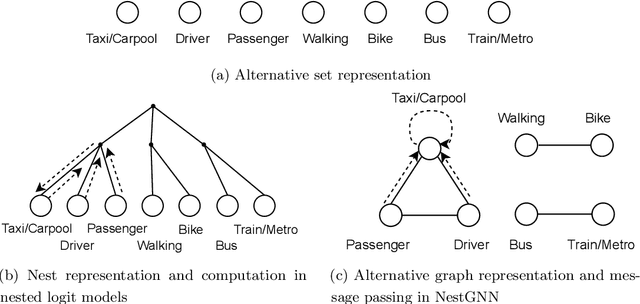
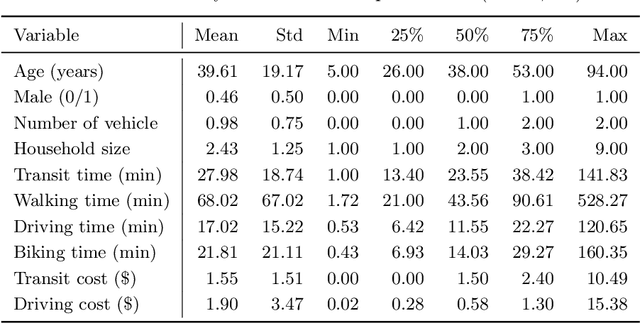
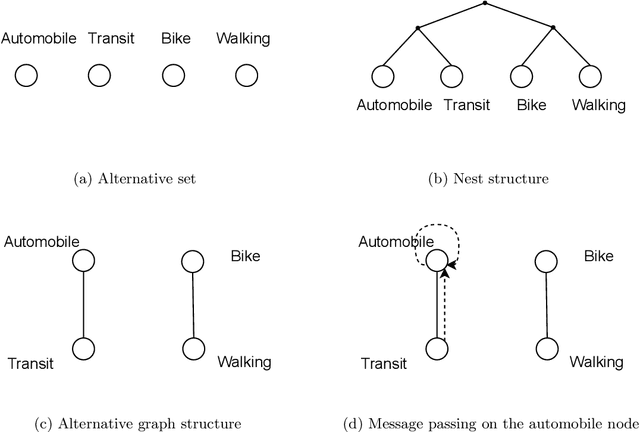

Nested logit (NL) has been commonly used for discrete choice analysis, including a wide range of applications such as travel mode choice, automobile ownership, or location decisions. However, the classical NL models are restricted by their limited representation capability and handcrafted utility specification. While researchers introduced deep neural networks (DNNs) to tackle such challenges, the existing DNNs cannot explicitly capture inter-alternative correlations in the discrete choice context. To address the challenges, this study proposes a novel concept - alternative graph - to represent the relationships among travel mode alternatives. Using a nested alternative graph, this study further designs a nested-utility graph neural network (NestGNN) as a generalization of the classical NL model in the neural network family. Theoretically, NestGNNs generalize the classical NL models and existing DNNs in terms of model representation, while retaining the crucial two-layer substitution patterns of the NL models: proportional substitution within a nest but non-proportional substitution beyond a nest. Empirically, we find that the NestGNNs significantly outperform the benchmark models, particularly the corresponding NL models by 9.2\%. As shown by elasticity tables and substitution visualization, NestGNNs retain the two-layer substitution patterns as the NL model, and yet presents more flexibility in its model design space. Overall, our study demonstrates the power of NestGNN in prediction, interpretation, and its flexibility of generalizing the classical NL model for analyzing travel mode choice.
UQGNN: Uncertainty Quantification of Graph Neural Networks for Multivariate Spatiotemporal Prediction
Aug 12, 2025



Spatiotemporal prediction plays a critical role in numerous real-world applications such as urban planning, transportation optimization, disaster response, and pandemic control. In recent years, researchers have made significant progress by developing advanced deep learning models for spatiotemporal prediction. However, most existing models are deterministic, i.e., predicting only the expected mean values without quantifying uncertainty, leading to potentially unreliable and inaccurate outcomes. While recent studies have introduced probabilistic models to quantify uncertainty, they typically focus on a single phenomenon (e.g., taxi, bike, crime, or traffic crashes), thereby neglecting the inherent correlations among heterogeneous urban phenomena. To address the research gap, we propose a novel Graph Neural Network with Uncertainty Quantification, termed UQGNN for multivariate spatiotemporal prediction. UQGNN introduces two key innovations: (i) an Interaction-aware Spatiotemporal Embedding Module that integrates a multivariate diffusion graph convolutional network and an interaction-aware temporal convolutional network to effectively capture complex spatial and temporal interaction patterns, and (ii) a multivariate probabilistic prediction module designed to estimate both expected mean values and associated uncertainties. Extensive experiments on four real-world multivariate spatiotemporal datasets from Shenzhen, New York City, and Chicago demonstrate that UQGNN consistently outperforms state-of-the-art baselines in both prediction accuracy and uncertainty quantification. For example, on the Shenzhen dataset, UQGNN achieves a 5% improvement in both prediction accuracy and uncertainty quantification.
Generative AI for Urban Design: A Stepwise Approach Integrating Human Expertise with Multimodal Diffusion Models
May 30, 2025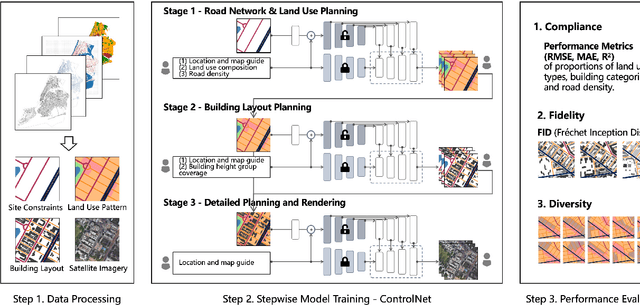
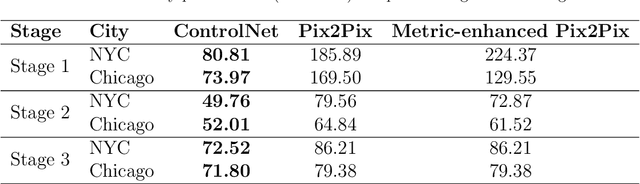
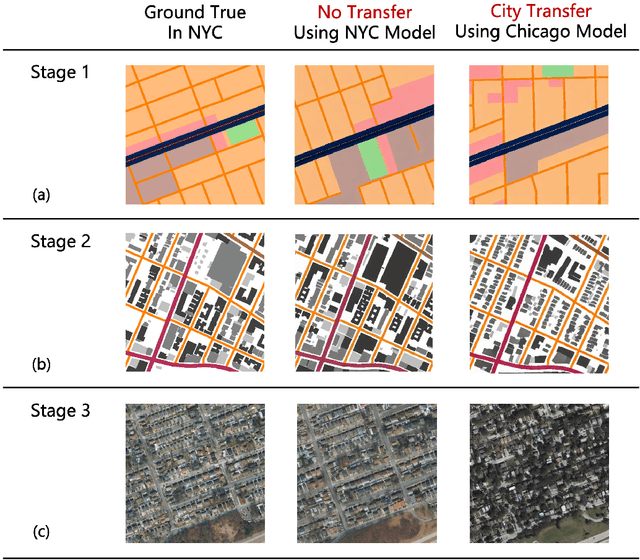
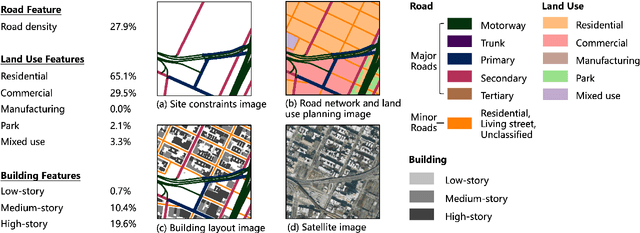
Urban design is a multifaceted process that demands careful consideration of site-specific constraints and collaboration among diverse professionals and stakeholders. The advent of generative artificial intelligence (GenAI) offers transformative potential by improving the efficiency of design generation and facilitating the communication of design ideas. However, most existing approaches are not well integrated with human design workflows. They often follow end-to-end pipelines with limited control, overlooking the iterative nature of real-world design. This study proposes a stepwise generative urban design framework that integrates multimodal diffusion models with human expertise to enable more adaptive and controllable design processes. Instead of generating design outcomes in a single end-to-end process, the framework divides the process into three key stages aligned with established urban design workflows: (1) road network and land use planning, (2) building layout planning, and (3) detailed planning and rendering. At each stage, multimodal diffusion models generate preliminary designs based on textual prompts and image-based constraints, which can then be reviewed and refined by human designers. We design an evaluation framework to assess the fidelity, compliance, and diversity of the generated designs. Experiments using data from Chicago and New York City demonstrate that our framework outperforms baseline models and end-to-end approaches across all three dimensions. This study underscores the benefits of multimodal diffusion models and stepwise generation in preserving human control and facilitating iterative refinements, laying the groundwork for human-AI interaction in urban design solutions.
Generative AI for Urban Planning: Synthesizing Satellite Imagery via Diffusion Models
May 13, 2025



Generative AI offers new opportunities for automating urban planning by creating site-specific urban layouts and enabling flexible design exploration. However, existing approaches often struggle to produce realistic and practical designs at scale. Therefore, we adapt a state-of-the-art Stable Diffusion model, extended with ControlNet, to generate high-fidelity satellite imagery conditioned on land use descriptions, infrastructure, and natural environments. To overcome data availability limitations, we spatially link satellite imagery with structured land use and constraint information from OpenStreetMap. Using data from three major U.S. cities, we demonstrate that the proposed diffusion model generates realistic and diverse urban landscapes by varying land-use configurations, road networks, and water bodies, facilitating cross-city learning and design diversity. We also systematically evaluate the impacts of varying language prompts and control imagery on the quality of satellite imagery generation. Our model achieves high FID and KID scores and demonstrates robustness across diverse urban contexts. Qualitative assessments from urban planners and the general public show that generated images align closely with design descriptions and constraints, and are often preferred over real images. This work establishes a benchmark for controlled urban imagery generation and highlights the potential of generative AI as a tool for enhancing planning workflows and public engagement.
Analyzing sequential activity and travel decisions with interpretable deep inverse reinforcement learning
Mar 17, 2025Travel demand modeling has shifted from aggregated trip-based models to behavior-oriented activity-based models because daily trips are essentially driven by human activities. To analyze the sequential activity-travel decisions, deep inverse reinforcement learning (DIRL) has proven effective in learning the decision mechanisms by approximating a reward function to represent preferences and a policy function to replicate observed behavior using deep neural networks (DNNs). However, most existing research has focused on using DIRL to enhance only prediction accuracy, with limited exploration into interpreting the underlying decision mechanisms guiding sequential decision-making. To address this gap, we introduce an interpretable DIRL framework for analyzing activity-travel decision processes, bridging the gap between data-driven machine learning and theory-driven behavioral models. Our proposed framework adapts an adversarial IRL approach to infer the reward and policy functions of activity-travel behavior. The policy function is interpreted through a surrogate interpretable model based on choice probabilities from the policy function, while the reward function is interpreted by deriving both short-term rewards and long-term returns for various activity-travel patterns. Our analysis of real-world travel survey data reveals promising results in two key areas: (i) behavioral pattern insights from the policy function, highlighting critical factors in decision-making and variations among socio-demographic groups, and (ii) behavioral preference insights from the reward function, indicating the utility individuals gain from specific activity sequences.
Mitigating Spatial Disparity in Urban Prediction Using Residual-Aware Spatiotemporal Graph Neural Networks: A Chicago Case Study
Jan 20, 2025Urban prediction tasks, such as forecasting traffic flow, temperature, and crime rates, are crucial for efficient urban planning and management. However, existing Spatiotemporal Graph Neural Networks (ST-GNNs) often rely solely on accuracy, overlooking spatial and demographic disparities in their predictions. This oversight can lead to imbalanced resource allocation and exacerbate existing inequities in urban areas. This study introduces a Residual-Aware Attention (RAA) Block and an equality-enhancing loss function to address these disparities. By adapting the adjacency matrix during training and incorporating spatial disparity metrics, our approach aims to reduce local segregation of residuals and errors. We applied our methodology to urban prediction tasks in Chicago, utilizing a travel demand dataset as an example. Our model achieved a 48% significant improvement in fairness metrics with only a 9% increase in error metrics. Spatial analysis of residual distributions revealed that models with RAA Blocks produced more equitable prediction results, particularly by reducing errors clustered in central regions. Attention maps demonstrated the model's ability to dynamically adjust focus, leading to more balanced predictions. Case studies of various community areas in Chicago further illustrated the effectiveness of our approach in addressing spatial and demographic disparities, supporting more balanced and equitable urban planning and policy-making.