 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What Not to Impute: An Uncertainty-Aware Diffusion Framework for Meaningful Missingness
Jun 03, 2026Missing value imputation is a fundamental task in machine learning, with most existing methods assuming that all missing entries correspond to unobserved regular values. In many real-world datasets, however, missingness may arise from two distinct sources: some entries are meaningfully missing (intrinsically absent and semantically valid), while others are missing due to the observation process and should be imputed. We formalize this distinction as a selective imputation problem, where the goal is to jointly infer which missing entries should be preserved and which should be recovered. To address this challenge, we propose Diff-Joint, a diffusion-based framework that jointly models tabular data together with a latent missingness mask. The method alternates between conditional sampling and uncertainty-aware aggregation to iteratively refine both imputed values and missingness labels. Empirical results on synthetic and real-world datasets demonstrate that Diff-Joint effectively identifies meaningfully missing entries while achieving competitive imputation accuracy and improved downstream task performance.
Masked Diffusion Modeling for Anomaly Detection
May 28, 2026Anomaly detection aims to identify samples that deviate from the nominal data distribution and is central to many safety-critical applications. However, developing effective anomaly detection methods for categorical, mixed-type, and discrete sequence data remains challenging and relatively underexplored. Masked diffusion models provide a natural way to model such data by learning to recover masked values from the remaining visible context. In this paper, we propose Masked Diffusion for Anomaly Detection (MaskDiff-AD), a forward-only method based on masked diffusion models trained only on nominal data. Given a test sample, MaskDiff-AD constructs anomaly scores from the difficulty of reconstructing randomly masked coordinates, yielding a content-sensitive score that operates directly on discrete state spaces while avoiding reverse-time sampling. We also develop a non-parametric variant of MaskDiff-AD and provide theoretical guarantees by characterizing Type-I and Type-II errors under a fixed detection threshold. Experiments on fourteen categorical and mixed-type tabular datasets from ADBench and UADAD, as well as four text anomaly detection datasets from NLP-ADBench, show that MaskDiff-AD achieves competitive performance against classical, diffusion-based, and recent tabular/text anomaly detection baselines. Notably, MaskDiff-AD achieves the best overall average rank, outperforming all twelve tabular baseline methods.
HawkesLLM: Semantic Uncertainty Propagation in Agentic Text Simulation
May 21, 2026Agentic text-simulation systems write in sequence, with each item becoming possible context for later steps. That makes uncertainty path-dependent: an early ambiguity can affect later outputs. This paper studies this problem with HawkesLLM, a framework that separates temporal influence modeling from text generation. We represent the cascade as a network whose nodes are text-generating agents. A multivariate Hawkes process models how these nodes activate over time and which earlier node outputs should influence later prompts. A language model then writes each new event from the compact memory selected by this temporal model. We evaluate the framework on a held-out Global Database of Events, Language, and Tone (GDELT) news-cascade case study. The diagnostics track semantic alignment with local held-out references and separate local drift from global drift. In this setting, HawkesLLM improves late-stage semantic alignment under a compact prompt-memory budget.
Learning to Test: Physics-Informed Representation for Dynamical Instability Detection
Apr 13, 2026Many safety-critical scientific and engineering systems evolve according to differential-algebraic equations (DAEs), where dynamical behavior is constrained by physical laws and admissibility conditions. In practice, these systems operate under stochastically varying environmental inputs, so stability is not a static property but must be reassessed as the context distribution shifts. Repeated large-scale DAE simulation, however, is computationally prohibitive in high-dimensional or real-time settings. This paper proposes a test-oriented learning framework for stability assessment under distribution shift. Rather than re-estimating physical parameters or repeatedly solving the underlying DAE, we learn a physics-informed latent representation of contextual variables that captures stability-relevant structure and is regularized toward a tractable reference distribution. Trained on baseline data from a certified safe regime, the learned representation enables deployment-time safety monitoring to be formulated as a distributional hypothesis test in latent space, with controlled Type I error. By integrating neural dynamical surrogates, uncertainty-aware calibration, and uniformity-based testing, our approach provides a scalable and statistically grounded method for detecting instability risk in stochastic constrained dynamical systems without repeated simulation.
Score-Based Change-Point Detection and Region Localization for Spatio-Temporal Point Processes
Feb 04, 2026We study sequential change-point detection for spatio-temporal point processes, where actionable detection requires not only identifying when a distributional change occurs but also localizing where it manifests in space. While classical quickest change detection methods provide strong guarantees on detection delay and false-alarm rates, existing approaches for point-process data predominantly focus on temporal changes and do not explicitly infer affected spatial regions. We propose a likelihood-free, score-based detection framework that jointly estimates the change time and the change region in continuous space-time without assuming parametric knowledge of the pre- or post-change dynamics. The method leverages a localized and conditionally weighted Hyvärinen score to quantify event-level deviations from nominal behavior and aggregates these scores using a spatio-temporal CUSUM-type statistic over a prescribed class of spatial regions. Operating sequentially, the procedure outputs both a stopping time and an estimated change region, enabling real-time detection with spatial interpretability. We establish theoretical guarantees on false-alarm control, detection delay, and spatial localization accuracy, and demonstrate the effectiveness of the proposed approach through simulations and real-world spatio-temporal event data.
Training-Free Self-Correction for Multimodal Masked Diffusion Models
Feb 02, 2026Masked diffusion models have emerged as a powerful framework for text and multimodal generation. However, their sampling procedure updates multiple tokens simultaneously and treats generated tokens as immutable, which may lead to error accumulation when early mistakes cannot be revised. In this work, we revisit existing self-correction methods and identify limitations stemming from additional training requirements or reliance on misaligned likelihood estimates. We propose a training-free self-correction framework that exploits the inductive biases of pre-trained masked diffusion models. Without modifying model parameters or introducing auxiliary evaluators, our method significantly improves generation quality on text-to-image generation and multimodal understanding tasks with reduced sampling steps. Moreover, the proposed framework generalizes across different masked diffusion architectures, highlighting its robustness and practical applicability. Code can be found in https://github.com/huge123/FreeCorrection.
Alignment of Diffusion Model and Flow Matching for Text-to-Image Generation
Jan 31, 2026Diffusion models and flow matching have demonstrated remarkable success in text-to-image generation. While many existing alignment methods primarily focus on fine-tuning pre-trained generative models to maximize a given reward function, these approaches require extensive computational resources and may not generalize well across different objectives. In this work, we propose a novel alignment framework by leveraging the underlying nature of the alignment problem -- sampling from reward-weighted distributions -- and show that it applies to both diffusion models (via score guidance) and flow matching models (via velocity guidance). The score function (velocity field) required for the reward-weighted distribution can be decomposed into the pre-trained score (velocity field) plus a conditional expectation of the reward. For the alignment on the diffusion model, we identify a fundamental challenge: the adversarial nature of the guidance term can introduce undesirable artifacts in the generated images. Therefore, we propose a finetuning-free framework that trains a guidance network to estimate the conditional expectation of the reward. We achieve comparable performance to finetuning-based models with one-step generation with at least a 60% reduction in computational cost. For the alignment on flow matching, we propose a training-free framework that improves the generation quality without additional computational cost.
Corrected Samplers for Discrete Flow Models
Jan 30, 2026Discrete flow models (DFMs) have been proposed to learn the data distribution on a finite state space, offering a flexible framework as an alternative to discrete diffusion models. A line of recent work has studied samplers for discrete diffusion models, such as tau-leaping and Euler solver. However, these samplers require a large number of iterations to control discretization error, since the transition rates are frozen in time and evaluated at the initial state within each time interval. Moreover, theoretical results for these samplers often require boundedness conditions of the transition rate or they focus on a specific type of source distributions. To address those limitations, we establish non-asymptotic discretization error bounds for those samplers without any restriction on transition rates and source distributions, under the framework of discrete flow models. Furthermore, by analyzing a one-step lower bound of the Euler sampler, we propose two corrected samplers: \textit{time-corrected sampler} and \textit{location-corrected sampler}, which can reduce the discretization error of tau-leaping and Euler solver with almost no additional computational cost. We rigorously show that the location-corrected sampler has a lower iteration complexity than existing parallel samplers. We validate the effectiveness of the proposed method by demonstrating improved generation quality and reduced inference time on both simulation and text-to-image generation tasks. Code can be found in https://github.com/WanZhengyan/Corrected-Samplers-for-Discrete-Flow-Models.
Detecting Post-generation Edits to Watermarked LLM Outputs via Combinatorial Watermarking
Oct 02, 2025Watermarking has become a key technique for proprietary language models, enabling the distinction between AI-generated and human-written text. However, in many real-world scenarios, LLM-generated content may undergo post-generation edits, such as human revisions or even spoofing attacks, making it critical to detect and localize such modifications. In this work, we introduce a new task: detecting post-generation edits locally made to watermarked LLM outputs. To this end, we propose a combinatorial pattern-based watermarking framework, which partitions the vocabulary into disjoint subsets and embeds the watermark by enforcing a deterministic combinatorial pattern over these subsets during generation. We accompany the combinatorial watermark with a global statistic that can be used to detect the watermark. Furthermore, we design lightweight local statistics to flag and localize potential edits. We introduce two task-specific evaluation metrics, Type-I error rate and detection accuracy, and evaluate our method on open-source LLMs across a variety of editing scenarios, demonstrating strong empirical performance in edit localization.
Discrete Guidance Matching: Exact Guidance for Discrete Flow Matching
Sep 26, 2025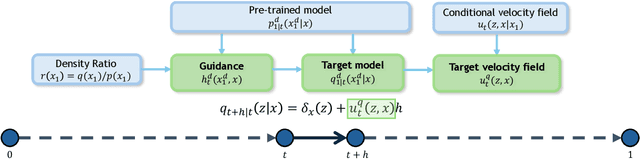

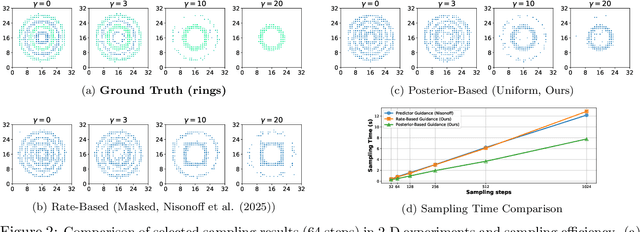
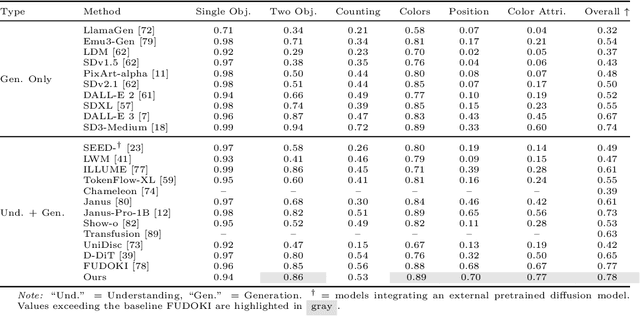
Guidance provides a simple and effective framework for posterior sampling by steering the generation process towards the desired distribution. When modeling discrete data, existing approaches mostly focus on guidance with the first-order Taylor approximation to improve the sampling efficiency. However, such an approximation is inappropriate in discrete state spaces since the approximation error could be large. A novel guidance framework for discrete data is proposed to address this problem: We derive the exact transition rate for the desired distribution given a learned discrete flow matching model, leading to guidance that only requires a single forward pass in each sampling step, significantly improving efficiency. This unified novel framework is general enough, encompassing existing guidance methods as special cases, and it can also be seamlessly applied to the masked diffusion model. We demonstrate the effectiveness of our proposed guidance on energy-guided simulations and preference alignment on text-to-image generation and multimodal understanding tasks. The code is available through https://github.com/WanZhengyan/Discrete-Guidance-Matching/tree/main.