 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Geometric Guidance for Probabilistic Human Pose Estimation with Diffusion Models
Feb 03, 20263D human pose estimation from 2D images is a challenging problem due to depth ambiguity and occlusion. Because of these challenges the task is underdetermined, where there exists multiple -- possibly infinite -- poses that are plausible given the image. Despite this, many prior works assume the existence of a deterministic mapping and estimate a single pose given an image. Furthermore, methods based on machine learning require a large amount of paired 2D-3D data to train and suffer from generalization issues to unseen scenarios. To address both of these issues, we propose a framework for pose estimation using diffusion models, which enables sampling from a probability distribution over plausible poses which are consistent with a 2D image. Our approach falls under the guidance framework for conditional generation, and guides samples from an unconditional diffusion model, trained only on 3D data, using the gradients of the heatmaps from a 2D keypoint detector. We evaluate our method on the Human 3.6M dataset under best-of-$m$ multiple hypothesis evaluation, showing state-of-the-art performance among methods which do not require paired 2D-3D data for training. We additionally evaluate the generalization ability using the MPI-INF-3DHP and 3DPW datasets and demonstrate competitive performance. Finally, we demonstrate the flexibility of our framework by using it for novel tasks including pose generation and pose completion, without the need to train bespoke conditional models. We make code available at https://github.com/fsnelgar/diffusion_pose .
Gromov Wasserstein Optimal Transport for Semantic Correspondences
Feb 03, 2026Establishing correspondences between image pairs is a long studied problem in computer vision. With recent large-scale foundation models showing strong zero-shot performance on downstream tasks including classification and segmentation, there has been interest in using the internal feature maps of these models for the semantic correspondence task. Recent works observe that features from DINOv2 and Stable Diffusion (SD) are complementary, the former producing accurate but sparse correspondences, while the latter produces spatially consistent correspondences. As a result, current state-of-the-art methods for semantic correspondence involve combining features from both models in an ensemble. While the performance of these methods is impressive, they are computationally expensive, requiring evaluating feature maps from large-scale foundation models. In this work we take a different approach, instead replacing SD features with a superior matching algorithm which is imbued with the desirable spatial consistency property. Specifically, we replace the standard nearest neighbours matching with an optimal transport algorithm that includes a Gromov Wasserstein spatial smoothness prior. We show that we can significantly boost the performance of the DINOv2 baseline, and be competitive and sometimes surpassing state-of-the-art methods using Stable Diffusion features, while being 5--10x more efficient. We make code available at https://github.com/fsnelgar/semantic_matching_gwot .
Efficient lattice field theory simulation using adaptive normalizing flow on a resistive memory-based neural differential equation solver
Sep 16, 2025Lattice field theory (LFT) simulations underpin advances in classical statistical mechanics and quantum field theory, providing a unified computational framework across particle, nuclear, and condensed matter physics. However, the application of these methods to high-dimensional systems remains severely constrained by several challenges, including the prohibitive computational cost and limited parallelizability of conventional sampling algorithms such as hybrid Monte Carlo (HMC), the substantial training expense associated with traditional normalizing flow models, and the inherent energy inefficiency of digital hardware architectures. Here, we introduce a software-hardware co-design that integrates an adaptive normalizing flow (ANF) model with a resistive memory-based neural differential equation solver, enabling efficient generation of LFT configurations. Software-wise, ANF enables efficient parallel generation of statistically independent configurations, thereby reducing computational costs, while low-rank adaptation (LoRA) allows cost-effective fine-tuning across diverse simulation parameters. Hardware-wise, in-memory computing with resistive memory substantially enhances both parallelism and energy efficiency. We validate our approach on the scalar phi4 theory and the effective field theory of graphene wires, using a hybrid analog-digital neural differential equation solver equipped with a 180 nm resistive memory in-memory computing macro. Our co-design enables low-cost computation, achieving approximately 8.2-fold and 13.9-fold reductions in integrated autocorrelation time over HMC, while requiring fine-tuning of less than 8% of the weights via LoRA. Compared to state-of-the-art GPUs, our co-design achieves up to approximately 16.1- and 17.0-fold speedups for the two tasks, as well as 73.7- and 138.0-fold improvements in energy efficiency.
PoseGRAF: Geometric-Reinforced Adaptive Fusion for Monocular 3D Human Pose Estimation
Jun 17, 2025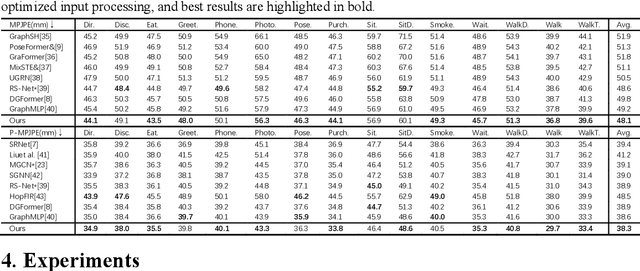
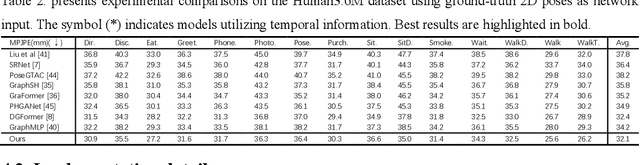
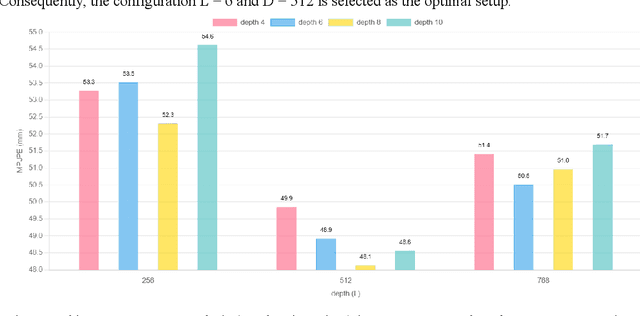
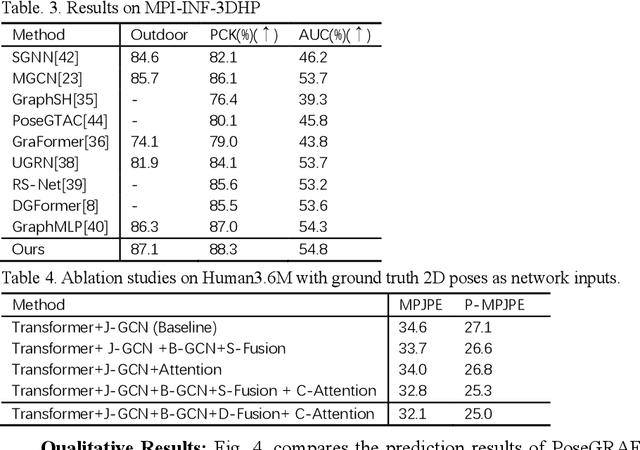
Existing monocular 3D pose estimation methods primarily rely on joint positional features, while overlooking intrinsic directional and angular correlations within the skeleton. As a result, they often produce implausible poses under joint occlusions or rapid motion changes. To address these challenges, we propose the PoseGRAF framework. We first construct a dual graph convolutional structure that separately processes joint and bone graphs, effectively capturing their local dependencies. A Cross-Attention module is then introduced to model interdependencies between bone directions and joint features. Building upon this, a dynamic fusion module is designed to adaptively integrate both feature types by leveraging the relational dependencies between joints and bones. An improved Transformer encoder is further incorporated in a residual manner to generate the final output. Experimental results on the Human3.6M and MPI-INF-3DHP datasets show that our method exceeds state-of-the-art approaches. Additional evaluations on in-the-wild videos further validate its generalizability. The code is publicly available at https://github.com/iCityLab/PoseGRAF.
DiSA: Diffusion Step Annealing in Autoregressive Image Generation
May 26, 2025An increasing number of autoregressive models, such as MAR, FlowAR, xAR, and Harmon adopt diffusion sampling to improve the quality of image generation. However, this strategy leads to low inference efficiency, because it usually takes 50 to 100 steps for diffusion to sample a token. This paper explores how to effectively address this issue. Our key motivation is that as more tokens are generated during the autoregressive process, subsequent tokens follow more constrained distributions and are easier to sample. To intuitively explain, if a model has generated part of a dog, the remaining tokens must complete the dog and thus are more constrained. Empirical evidence supports our motivation: at later generation stages, the next tokens can be well predicted by a multilayer perceptron, exhibit low variance, and follow closer-to-straight-line denoising paths from noise to tokens. Based on our finding, we introduce diffusion step annealing (DiSA), a training-free method which gradually uses fewer diffusion steps as more tokens are generated, e.g., using 50 steps at the beginning and gradually decreasing to 5 steps at later stages. Because DiSA is derived from our finding specific to diffusion in autoregressive models, it is complementary to existing acceleration methods designed for diffusion alone. DiSA can be implemented in only a few lines of code on existing models, and albeit simple, achieves $5-10\times$ faster inference for MAR and Harmon and $1.4-2.5\times$ for FlowAR and xAR, while maintaining the generation quality.
HetGL2R: Learning to Rank Critical Road Segments via Attributed Heterogeneous Graph Random Walks
Apr 27, 2025Accurately identifying critical nodes with high spatial influence in road networks is essential for enhancing the efficiency of traffic management and urban planning. However, existing node importance ranking methods mainly rely on structural features and topological information, often overlooking critical factors such as origin-destination (OD) demand and route information. This limitation leaves considerable room for improvement in ranking accuracy. To address this issue, we propose HetGL2R, an attributed heterogeneous graph learning approach for ranking node importance in road networks. This method introduces a tripartite graph (trip graph) to model the structure of the road network, integrating OD demand, route choice, and various structural features of road segments. Based on the trip graph, we design an embedding method to learn node representations that reflect the spatial influence of road segments. The method consists of a heterogeneous random walk sampling algorithm (HetGWalk) and a Transformer encoder. HetGWalk constructs multiple attribute-guided graphs based on the trip graph to enrich the diversity of semantic associations between nodes. It then applies a joint random walk mechanism to convert both topological structures and node attributes into sequences, enabling the encoder to capture spatial dependencies more effectively among road segments. Finally, a listwise ranking strategy is employed to evaluate node importance. To validate the performance of our method, we construct two synthetic datasets using SUMO based on simulated road networks. Experimental results demonstrate that HetGL2R significantly outperforms baselines in incorporating OD demand and route choice information, achieving more accurate and robust node ranking. Furthermore, we conduct a case study using real-world taxi trajectory data from Beijing, further verifying the practicality of the proposed method.
Interior Point Differential Dynamic Programming, Redux
Apr 11, 2025We present IPDDP2, a structure-exploiting algorithm for solving discrete-time, finite horizon optimal control problems with nonlinear constraints. Inequality constraints are handled using a primal-dual interior point formulation and step acceptance for equality constraints follows a line-search filter approach. The iterates of the algorithm are derived under the Differential Dynamic Programming (DDP) framework. Our numerical experiments evaluate IPDDP2 on four robotic motion planning problems. IPDDP2 reliably converges to low optimality error and exhibits local quadratic and global convergence from remote starting points. Notably, we showcase the robustness of IPDDP2 by using it to solve a contact-implicit, joint limited acrobot swing-up problem involving complementarity constraints from a range of initial conditions. We provide a full implementation of IPDDP2 in the Julia programming language.
Sparse Autoencoder as a Zero-Shot Classifier for Concept Erasing in Text-to-Image Diffusion Models
Mar 12, 2025Text-to-image (T2I) diffusion models have achieved remarkable progress in generating high-quality images but also raise people's concerns about generating harmful or misleading content. While extensive approaches have been proposed to erase unwanted concepts without requiring retraining from scratch, they inadvertently degrade performance on normal generation tasks. In this work, we propose Interpret then Deactivate (ItD), a novel framework to enable precise concept removal in T2I diffusion models while preserving overall performance. ItD first employs a sparse autoencoder (SAE) to interpret each concept as a combination of multiple features. By permanently deactivating the specific features associated with target concepts, we repurpose SAE as a zero-shot classifier that identifies whether the input prompt includes target concepts, allowing selective concept erasure in diffusion models. Moreover, we demonstrate that ItD can be easily extended to erase multiple concepts without requiring further training. Comprehensive experiments across celebrity identities, artistic styles, and explicit content demonstrate ItD's effectiveness in eliminating targeted concepts without interfering with normal concept generation. Additionally, ItD is also robust against adversarial prompts designed to circumvent content filters. Code is available at: https://github.com/NANSirun/Interpret-then-deactivate.
Talk2PC: Enhancing 3D Visual Grounding through LiDAR and Radar Point Clouds Fusion for Autonomous Driving
Mar 11, 2025Embodied outdoor scene understanding forms the foundation for autonomous agents to perceive, analyze, and react to dynamic driving environments. However, existing 3D understanding is predominantly based on 2D Vision-Language Models (VLMs), collecting and processing limited scene-aware contexts. Instead, compared to the 2D planar visual information, point cloud sensors like LiDAR offer rich depth information and fine-grained 3D representations of objects. Meanwhile, the emerging 4D millimeter-wave (mmWave) radar is capable of detecting the motion trend, velocity, and reflection intensity of each object. Therefore, the integration of these two modalities provides more flexible querying conditions for natural language, enabling more accurate 3D visual grounding. To this end, in this paper, we exploratively propose a novel method called TPCNet, the first outdoor 3D visual grounding model upon the paradigm of prompt-guided point cloud sensor combination, including both LiDAR and radar contexts. To adaptively balance the features of these two sensors required by the prompt, we have designed a multi-fusion paradigm called Two-Stage Heterogeneous Modal Adaptive Fusion. Specifically, this paradigm initially employs Bidirectional Agent Cross-Attention (BACA), which feeds dual-sensor features, characterized by global receptive fields, to the text features for querying. Additionally, we have designed a Dynamic Gated Graph Fusion (DGGF) module to locate the regions of interest identified by the queries. To further enhance accuracy, we innovatively devise an C3D-RECHead, based on the nearest object edge. Our experiments have demonstrated that our TPCNet, along with its individual modules, achieves the state-of-the-art performance on both the Talk2Radar and Talk2Car datasets.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.