 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC-NeRF: Physics Augmented Continuum Neural Radiance Fields for Geometry-Agnostic System Identification
Mar 09, 2023Existing approaches to system identification (estimating the physical parameters of an object) from videos assume known object geometries. This precludes their applicability in a vast majority of scenes where object geometries are complex or unknown. In this work, we aim to identify parameters characterizing a physical system from a set of multi-view videos without any assumption on object geometry or topology. To this end, we propose "Physics Augmented Continuum Neural Radiance Fields" (PAC-NeRF), to estimate both the unknown geometry and physical parameters of highly dynamic objects from multi-view videos. We design PAC-NeRF to only ever produce physically plausible states by enforcing the neural radiance field to follow the conservation laws of continuum mechanics. For this, we design a hybrid Eulerian-Lagrangian representation of the neural radiance field, i.e., we use the Eulerian grid representation for NeRF density and color fields, while advecting the neural radiance fields via Lagrangian particles. This hybrid Eulerian-Lagrangian representation seamlessly blends efficient neural rendering with the material point method (MPM) for robust differentiable physics simulation. We validate the effectiveness of our proposed framework on geometry and physical parameter estimation over a vast range of materials, including elastic bodies, plasticine, sand, Newtonian and non-Newtonian fluids, and demonstrate significant performance gain on most tasks.
DeepMAD: Mathematical Architecture Design for Deep Convolutional Neural Network
Mar 05, 2023



The rapid advances in Vision Transformer (ViT) refresh the state-of-the-art performances in various vision tasks, overshadowing the conventional CNN-based models. This ignites a few recent striking-back research in the CNN world showing that pure CNN models can achieve as good performance as ViT models when carefully tuned. While encouraging, designing such high-performance CNN models is challenging, requiring non-trivial prior knowledge of network design. To this end, a novel framework termed Mathematical Architecture Design for Deep CNN (DeepMAD) is proposed to design high-performance CNN models in a principled way. In DeepMAD, a CNN network is modeled as an information processing system whose expressiveness and effectiveness can be analytically formulated by their structural parameters. Then a constrained mathematical programming (MP) problem is proposed to optimize these structural parameters. The MP problem can be easily solved by off-the-shelf MP solvers on CPUs with a small memory footprint. In addition, DeepMAD is a pure mathematical framework: no GPU or training data is required during network design. The superiority of DeepMAD is validated on multiple large-scale computer vision benchmark datasets. Notably on ImageNet-1k, only using conventional convolutional layers, DeepMAD achieves 0.7% and 1.5% higher top-1 accuracy than ConvNeXt and Swin on Tiny level, and 0.8% and 0.9% higher on Small level.
Maximizing Spatio-Temporal Entropy of Deep 3D CNNs for Efficient Video Recognition
Mar 05, 20233D convolution neural networks (CNNs) have been the prevailing option for video recognition. To capture the temporal information, 3D convolutions are computed along the sequences, leading to cubically growing and expensive computations. To reduce the computational cost, previous methods resort to manually designed 3D/2D CNN structures with approximations or automatic search, which sacrifice the modeling ability or make training time-consuming. In this work, we propose to automatically design efficient 3D CNN architectures via a novel training-free neural architecture search approach tailored for 3D CNNs considering the model complexity. To measure the expressiveness of 3D CNNs efficiently, we formulate a 3D CNN as an information system and derive an analytic entropy score, based on the Maximum Entropy Principle. Specifically, we propose a spatio-temporal entropy score (STEntr-Score) with a refinement factor to handle the discrepancy of visual information in spatial and temporal dimensions, through dynamically leveraging the correlation between the feature map size and kernel size depth-wisely. Highly efficient and expressive 3D CNN architectures, \ie entropy-based 3D CNNs (E3D family), can then be efficiently searched by maximizing the STEntr-Score under a given computational budget, via an evolutionary algorithm without training the network parameters. Extensive experiments on Something-Something V1\&V2 and Kinetics400 demonstrate that the E3D family achieves state-of-the-art performance with higher computational efficiency. Code is available at https://github.com/alibaba/lightweight-neural-architecture-search.
GeoLCR: Attention-based Geometric Loop Closure and Registration
Mar 04, 2023We present a novel algorithm for learning-based loop-closure for SLAM (simultaneous localization and mapping) applications. Our approach is designed for general 3D point cloud data, including those from lidar, and is used to prevent accumulated drift over time for autonomous driving. We voxelize the point clouds into coarse voxels and calculate the overlap to estimate if the vehicle drives in a loop. We perform point-level registration to compute the current pose accurately. We have evaluated our approach on well-known datasets KITTI, KITTI-360, Nuscenes, Complex Urban, NCLT, and MulRan. We show at most 2 times improvement in accuracy estimation of translation and rotation. On some challenging sequences, our method is the first approach that can obtain a 100% success rate.
Learning the Relation between Similarity Loss and Clustering Loss in Self-Supervised Learning
Jan 08, 2023



Self-supervised learning enables networks to learn discriminative features from massive data itself. Most state-of-the-art methods maximize the similarity between two augmentations of one image based on contrastive learning. By utilizing the consistency of two augmentations, the burden of manual annotations can be freed. Contrastive learning exploits instance-level information to learn robust features. However, the learned information is probably confined to different views of the same instance. In this paper, we attempt to leverage the similarity between two distinct images to boost representation in self-supervised learning. In contrast to instance-level information, the similarity between two distinct images may provide more useful information. Besides, we analyze the relation between similarity loss and feature-level cross-entropy loss. These two losses are essential for most deep learning methods. However, the relation between these two losses is not clear. Similarity loss helps obtain instance-level representation, while feature-level cross-entropy loss helps mine the similarity between two distinct images. We provide theoretical analyses and experiments to show that a suitable combination of these two losses can get state-of-the-art results.
Differentiable Analog Quantum Computing for Optimization and Control
Oct 28, 2022



We formulate the first differentiable analog quantum computing framework with a specific parameterization design at the analog signal (pulse) level to better exploit near-term quantum devices via variational methods. We further propose a scalable approach to estimate the gradients of quantum dynamics using a forward pass with Monte Carlo sampling, which leads to a quantum stochastic gradient descent algorithm for scalable gradient-based training in our framework. Applying our framework to quantum optimization and control, we observe a significant advantage of differentiable analog quantum computing against SOTAs based on parameterized digital quantum circuits by orders of magnitude.
* Code available at https://github.com/YilingQiao/diffquantum
Robust Graph Structure Learning over Images via Multiple Statistical Tests
Oct 08, 2022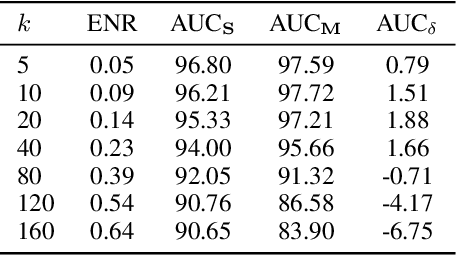
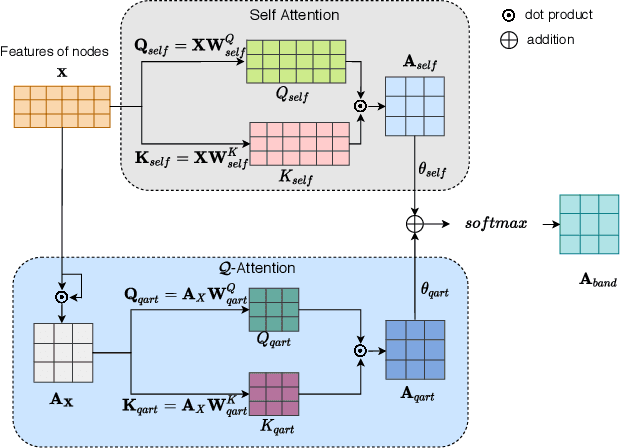
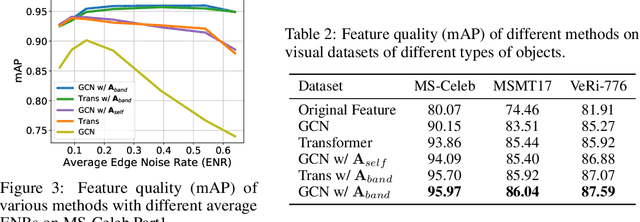
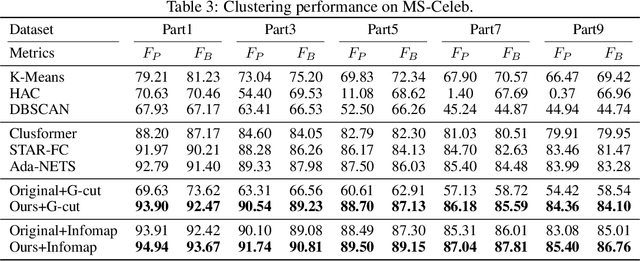
Graph structure learning aims to learn connectivity in a graph from data. It is particularly important for many computer vision related tasks since no explicit graph structure is available for images for most cases. A natural way to construct a graph among images is to treat each image as a node and assign pairwise image similarities as weights to corresponding edges. It is well known that pairwise similarities between images are sensitive to the noise in feature representations, leading to unreliable graph structures. We address this problem from the viewpoint of statistical tests. By viewing the feature vector of each node as an independent sample, the decision of whether creating an edge between two nodes based on their similarity in feature representation can be thought as a ${\it single}$ statistical test. To improve the robustness in the decision of creating an edge, multiple samples are drawn and integrated by ${\it multiple}$ statistical tests to generate a more reliable similarity measure, consequentially more reliable graph structure. The corresponding elegant matrix form named $\mathcal{B}\textbf{-Attention}$ is designed for efficiency. The effectiveness of multiple tests for graph structure learning is verified both theoretically and empirically on multiple clustering and ReID benchmark datasets. Source codes are available at https://github.com/Thomas-wyh/B-Attention.
WGICP: Differentiable Weighted GICP-Based Lidar Odometry
Oct 03, 2022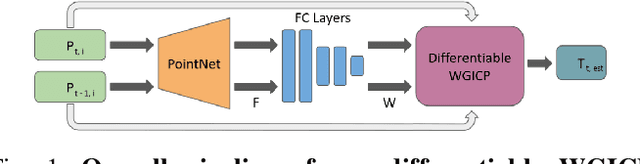
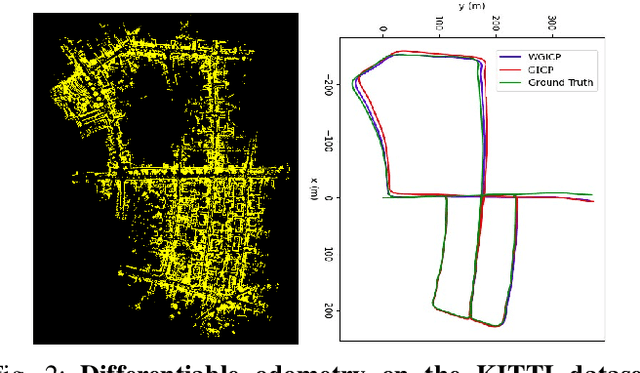
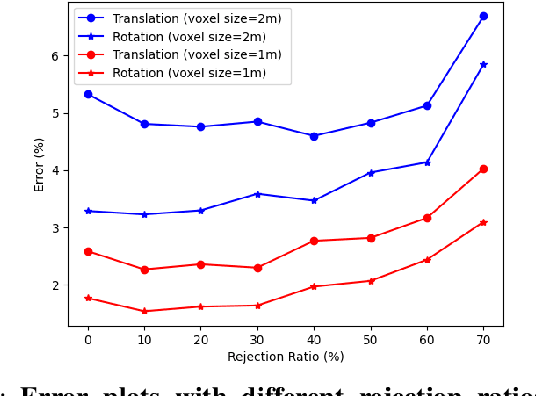
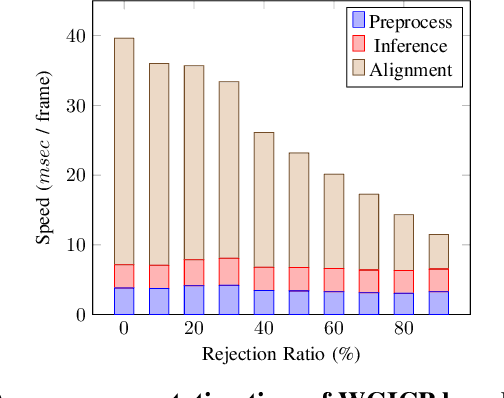
We present a novel differentiable weighted generalized iterative closest point (WGICP) method applicable to general 3D point cloud data, including that from Lidar. Our method builds on differentiable generalized ICP (GICP), and we propose using the differentiable K-Nearest Neighbor (KNN) algorithm to enhance differentiability. The differentiable GICP algorithm provides the gradient of output pose estimation with respect to each input point, which allows us to train a neural network to predict its importance, or weight, in estimating the correct pose. In contrast to the other ICP-based methods that use voxel-based downsampling or matching methods to reduce the computational cost, our method directly reduces the number of points used for GICP by only selecting those with the highest weights and ignoring redundant ones with lower weights. We show that our method improves both accuracy and speed of the GICP algorithm for the KITTI dataset and can be used to develop a more robust and efficient SLAM system.
Differentiable Frequency-based Disentanglement for Aerial Video Action Recognition
Sep 15, 2022
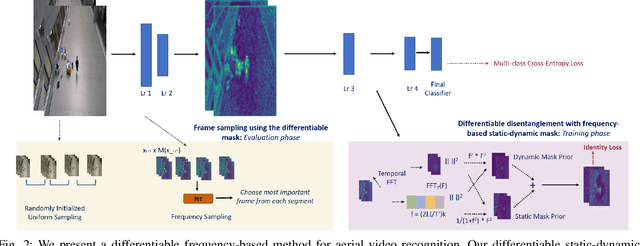

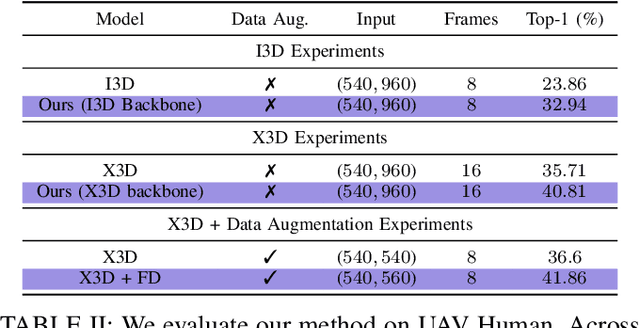
We present a learning algorithm for human activity recognition in videos. Our approach is designed for UAV videos, which are mainly acquired from obliquely placed dynamic cameras that contain a human actor along with background motion. Typically, the human actors occupy less than one-tenth of the spatial resolution. Our approach simultaneously harnesses the benefits of frequency domain representations, a classical analysis tool in signal processing, and data driven neural networks. We build a differentiable static-dynamic frequency mask prior to model the salient static and dynamic pixels in the video, crucial for the underlying task of action recognition. We use this differentiable mask prior to enable the neural network to intrinsically learn disentangled feature representations via an identity loss function. Our formulation empowers the network to inherently compute disentangled salient features within its layers. Further, we propose a cost-function encapsulating temporal relevance and spatial content to sample the most important frame within uniformly spaced video segments. We conduct extensive experiments on the UAV Human dataset and the NEC Drone dataset and demonstrate relative improvements of 5.72% - 13.00% over the state-of-the-art and 14.28% - 38.05% over the corresponding baseline model.
Fourier Disentangled Space-Time Attention for Aerial Video Recognition
Mar 21, 2022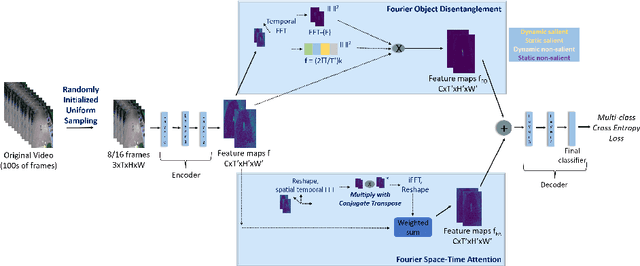


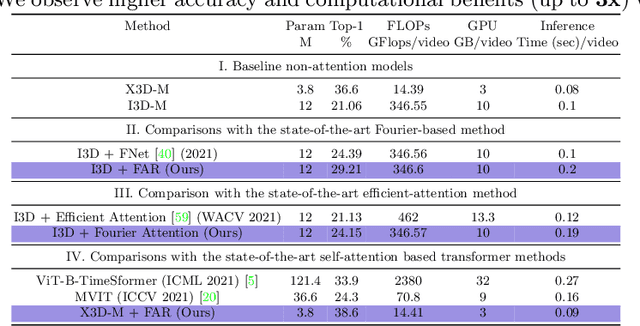
We present an algorithm, Fourier Activity Recognition (FAR), for UAV video activity recognition. Our formulation uses a novel Fourier object disentanglement method to innately separate out the human agent (which is typically small) from the background. Our disentanglement technique operates in the frequency domain to characterize the extent of temporal change of spatial pixels, and exploits convolution-multiplication properties of Fourier transform to map this representation to the corresponding object-background entangled features obtained from the network. To encapsulate contextual information and long-range space-time dependencies, we present a novel Fourier Attention algorithm, which emulates the benefits of self-attention by modeling the weighted outer product in the frequency domain. Our Fourier attention formulation uses much fewer computations than self-attention. We have evaluated our approach on multiple UAV datasets including UAV Human RGB, UAV Human Night, Drone Action, and NEC Drone. We demonstrate a relative improvement of 8.02% - 38.69% in top-1 accuracy and up to 3 times faster over prior works.