 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHessian Eigenspectra of More Realistic Nonlinear Models
Mar 17, 2021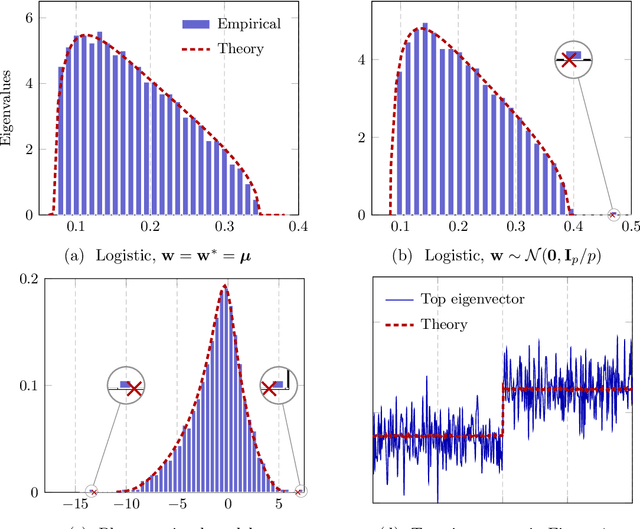
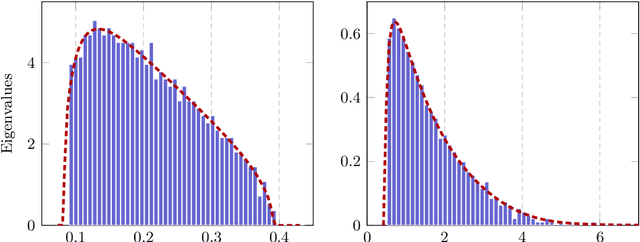
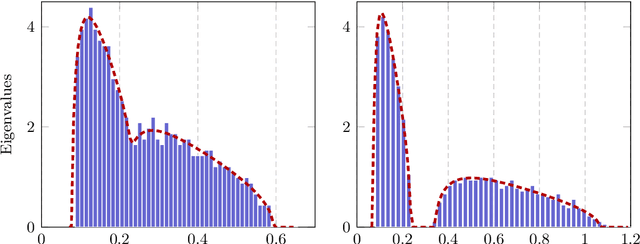
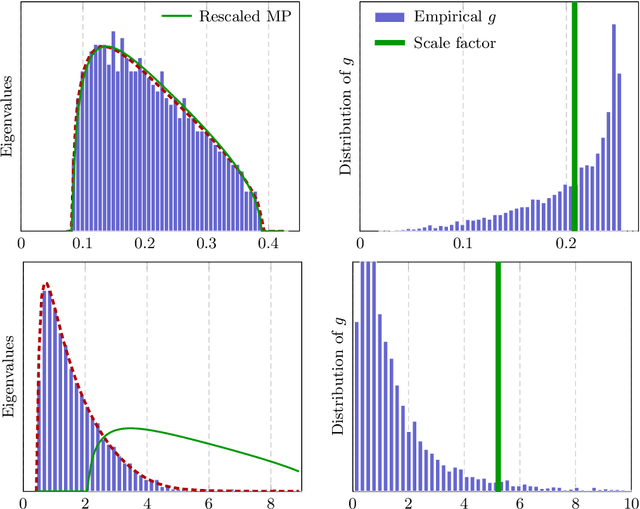
Given an optimization problem, the Hessian matrix and its eigenspectrum can be used in many ways, ranging from designing more efficient second-order algorithms to performing model analysis and regression diagnostics. When nonlinear models and non-convex problems are considered, strong simplifying assumptions are often made to make Hessian spectral analysis more tractable. This leads to the question of how relevant the conclusions of such analyses are for more realistic nonlinear models. In this paper, we exploit deterministic equivalent techniques from random matrix theory to make a \emph{precise} characterization of the Hessian eigenspectra for a broad family of nonlinear models, including models that generalize the classical generalized linear models, without relying on strong simplifying assumptions used previously. We show that, depending on the data properties, the nonlinear response model, and the loss function, the Hessian can have \emph{qualitatively} different spectral behaviors: of bounded or unbounded support, with single- or multi-bulk, and with isolated eigenvalues on the left- or right-hand side of the bulk. By focusing on such a simple but nontrivial nonlinear model, our analysis takes a step forward to unveil the theoretical origin of many visually striking features observed in more complex machine learning models.
A Differential Geometry Perspective on Orthogonal Recurrent Models
Feb 18, 2021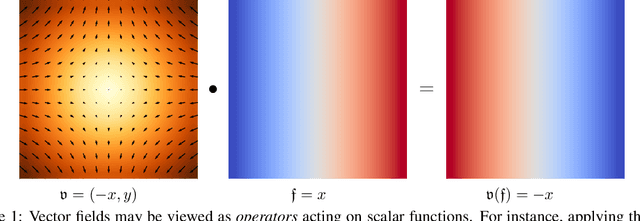
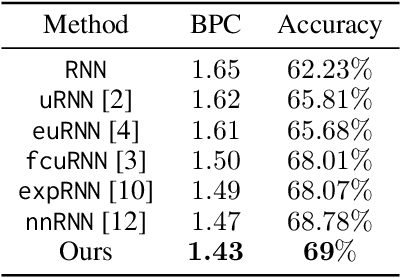
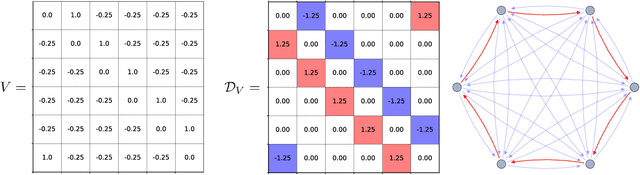
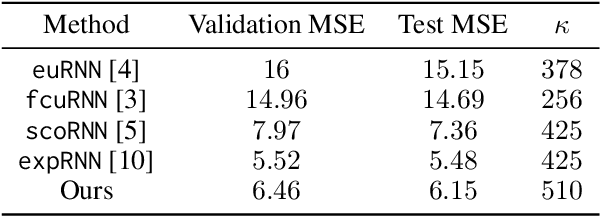
Recently, orthogonal recurrent neural networks (RNNs) have emerged as state-of-the-art models for learning long-term dependencies. This class of models mitigates the exploding and vanishing gradients problem by design. In this work, we employ tools and insights from differential geometry to offer a novel perspective on orthogonal RNNs. We show that orthogonal RNNs may be viewed as optimizing in the space of divergence-free vector fields. Specifically, based on a well-known result in differential geometry that relates vector fields and linear operators, we prove that every divergence-free vector field is related to a skew-symmetric matrix. Motivated by this observation, we study a new recurrent model, which spans the entire space of vector fields. Our method parameterizes vector fields via the directional derivatives of scalar functions. This requires the construction of latent inner product, gradient, and divergence operators. In comparison to state-of-the-art orthogonal RNNs, our approach achieves comparable or better results on a variety of benchmark tasks.
I-BERT: Integer-only BERT Quantization
Feb 11, 2021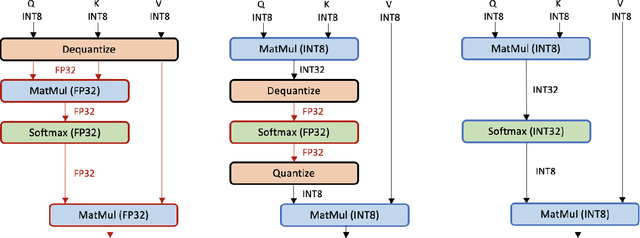
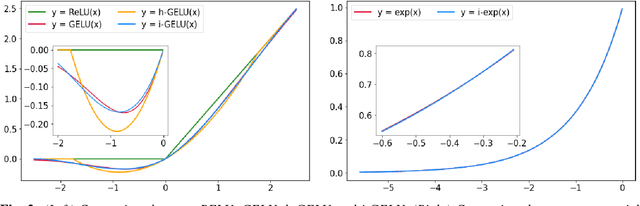
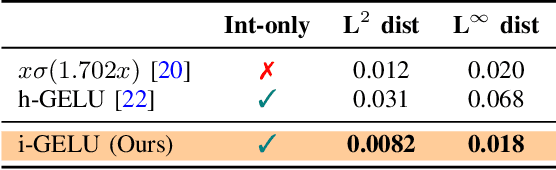
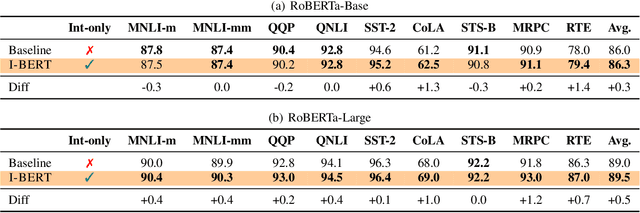
Transformer based models, like BERT and RoBERTa, have achieved state-of-the-art results in many Natural Language Processing tasks. However, their memory footprint, inference latency, and power consumption are prohibitive for efficient inference at the edge, and even at the data center. While quantization can be a viable solution for this, previous work on quantizing Transformer based models use floating-point arithmetic during inference, which cannot efficiently utilize integer-only logical units such as the recent Turing Tensor Cores, or traditional integer-only ARM processors. In this work, we propose I-BERT, a novel quantization scheme for Transformer based models that quantizes the entire inference with integer-only arithmetic. Based on lightweight integer-only approximation methods for nonlinear operations, e.g., GELU, Softmax, and Layer Normalization, I-BERT performs an end-to-end integer-only BERT inference without any floating point calculation. We evaluate our approach on GLUE downstream tasks using RoBERTa-Base/Large. We show that for both cases, I-BERT achieves similar (and slightly higher) accuracy as compared to the full-precision baseline. Furthermore, our preliminary implementation of I-BERT shows a speedup of 2.4 - 4.0x for INT8 inference on a T4 GPU system as compared to FP32 inference. The framework has been developed in PyTorch and has been open-sourced.
Noisy Recurrent Neural Networks
Feb 09, 2021
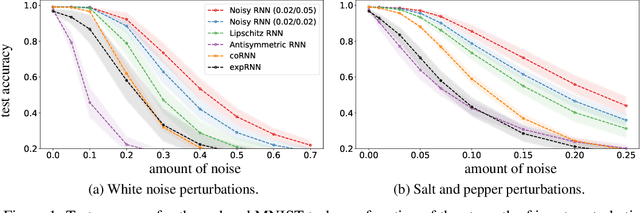

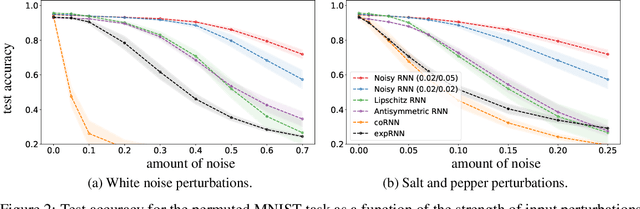
We provide a general framework for studying recurrent neural networks (RNNs) trained by injecting noise into hidden states. Specifically, we consider RNNs that can be viewed as discretizations of stochastic differential equations driven by input data. This framework allows us to study the implicit regularization effect of general noise injection schemes by deriving an approximate explicit regularizer in the small noise regime. We find that, under reasonable assumptions, this implicit regularization promotes flatter minima; it biases towards models with more stable dynamics; and, in classification tasks, it favors models with larger classification margin. Sufficient conditions for global stability are obtained, highlighting the phenomenon of stochastic stabilization, where noise injection can improve stability during training. Our theory is supported by empirical results which demonstrate improved robustness with respect to various input perturbations, while maintaining state-of-the-art performance.
Sparse sketches with small inversion bias
Nov 21, 2020For a tall $n\times d$ matrix $A$ and a random $m\times n$ sketching matrix $S$, the sketched estimate of the inverse covariance matrix $(A^\top A)^{-1}$ is typically biased: $E[(\tilde A^\top\tilde A)^{-1}]\ne(A^\top A)^{-1}$, where $\tilde A=SA$. This phenomenon, which we call inversion bias, arises, e.g., in statistics and distributed optimization, when averaging multiple independently constructed estimates of quantities that depend on the inverse covariance. We develop a framework for analyzing inversion bias, based on our proposed concept of an $(\epsilon,\delta)$-unbiased estimator for random matrices. We show that when the sketching matrix $S$ is dense and has i.i.d. sub-gaussian entries, then after simple rescaling, the estimator $(\frac m{m-d}\tilde A^\top\tilde A)^{-1}$ is $(\epsilon,\delta)$-unbiased for $(A^\top A)^{-1}$ with a sketch of size $m=O(d+\sqrt d/\epsilon)$. This implies that for $m=O(d)$, the inversion bias of this estimator is $O(1/\sqrt d)$, which is much smaller than the $\Theta(1)$ approximation error obtained as a consequence of the subspace embedding guarantee for sub-gaussian sketches. We then propose a new sketching technique, called LEverage Score Sparsified (LESS) embeddings, which uses ideas from both data-oblivious sparse embeddings as well as data-aware leverage-based row sampling methods, to get $\epsilon$ inversion bias for sketch size $m=O(d\log d+\sqrt d/\epsilon)$ in time $O(\text{nnz}(A)\log n+md^2)$, where nnz is the number of non-zeros. The key techniques enabling our analysis include an extension of a classical inequality of Bai and Silverstein for random quadratic forms, which we call the Restricted Bai-Silverstein inequality; and anti-concentration of the Binomial distribution via the Paley-Zygmund inequality, which we use to prove a lower bound showing that leverage score sampling sketches generally do not achieve small inversion bias.
HAWQV3: Dyadic Neural Network Quantization
Nov 20, 2020
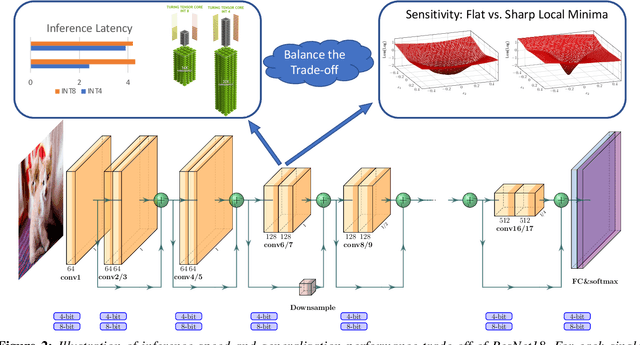
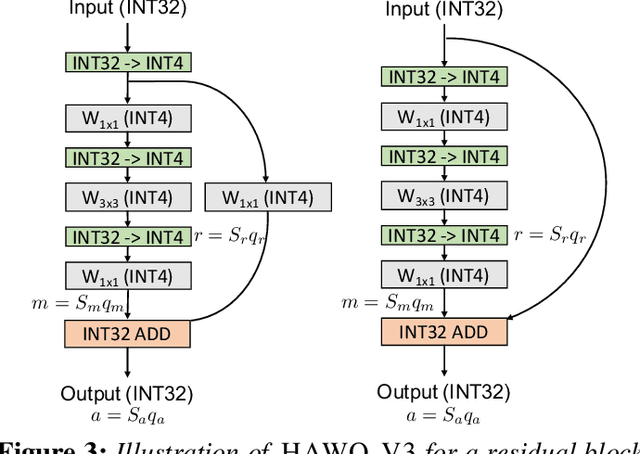
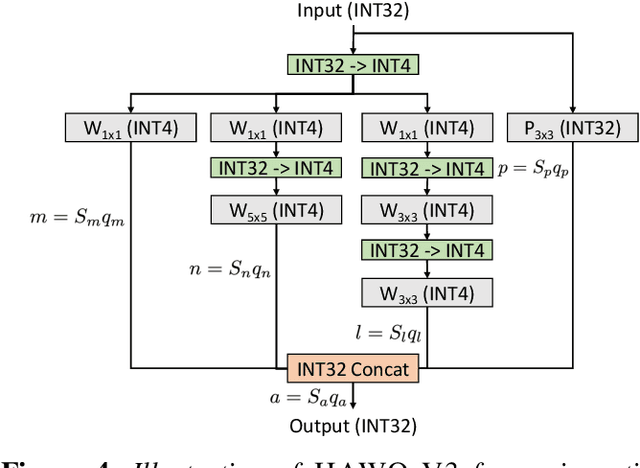
Quantization is one of the key techniques used to make Neural Networks (NNs) faster and more energy efficient. However, current low precision quantization algorithms often have the hidden cost of conversion back and forth from floating point to quantized integer values. This hidden cost limits the latency improvement realized by quantizing NNs. To address this, we present HAWQV3, a novel dyadic quantization framework. The contributions of HAWQV3 are the following. (i) The entire inference process consists of only integer multiplication, addition, and bit shifting in INT4/8 mixed precision, without any floating point operations/casting or even integer division. (ii) We pose the mixed-precision quantization as an integer linear programming problem, where the bit precision setting is computed to minimize model perturbation, while observing application specific constraints on memory footprint, latency, and BOPS. (iii) To verify our approach, we develop the first open source 4-bit mixed-precision quantization in TVM, and we directly deploy the quantized models to T4 GPUs using only the Turing Tensor Cores. We observe an average speed up of $1.45\times$ for uniform 4-bit, as compared to uniform 8-bit, precision for ResNet50. (iv) We extensively test the proposed dyadic quantization approach on multiple different NNs, including ResNet18/50 and InceptionV3, for various model compression levels with/without mixed precision. For instance, we achieve an accuracy of $78.50\%$ with dyadic INT8 quantization, which is more than $4\%$ higher than prior integer-only work for InceptionV3. Furthermore, we show that mixed-precision INT4/8 quantization can be used to achieve higher speed ups, as compared to INT8 inference, with minimal impact on accuracy. For example, for ResNet50 we can reduce INT8 latency by $23\%$ with mixed precision and still achieve $76.73\%$ accuracy.
A Statistical Framework for Low-bitwidth Training of Deep Neural Networks
Oct 27, 2020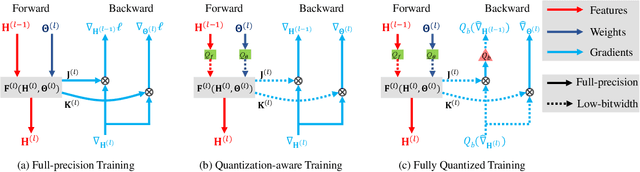
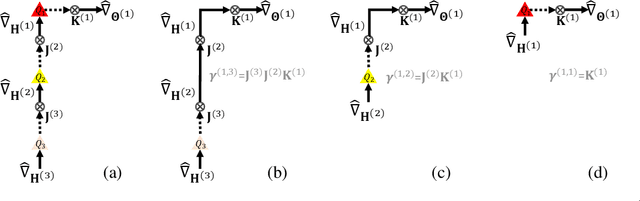
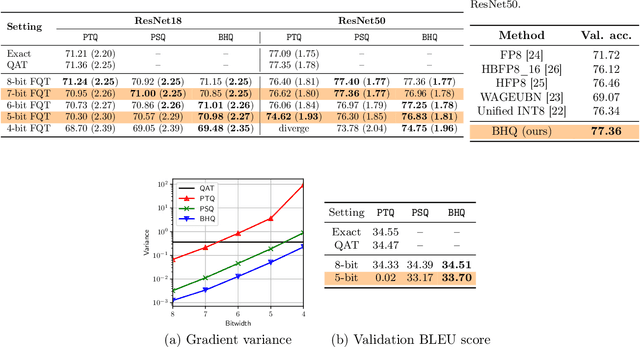
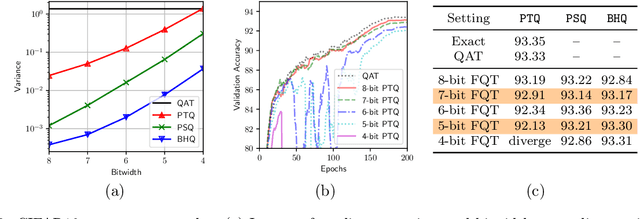
Fully quantized training (FQT), which uses low-bitwidth hardware by quantizing the activations, weights, and gradients of a neural network model, is a promising approach to accelerate the training of deep neural networks. One major challenge with FQT is the lack of theoretical understanding, in particular of how gradient quantization impacts convergence properties. In this paper, we address this problem by presenting a statistical framework for analyzing FQT algorithms. We view the quantized gradient of FQT as a stochastic estimator of its full precision counterpart, a procedure known as quantization-aware training (QAT). We show that the FQT gradient is an unbiased estimator of the QAT gradient, and we discuss the impact of gradient quantization on its variance. Inspired by these theoretical results, we develop two novel gradient quantizers, and we show that these have smaller variance than the existing per-tensor quantizer. For training ResNet-50 on ImageNet, our 5-bit block Householder quantizer achieves only 0.5% validation accuracy loss relative to QAT, comparable to the existing INT8 baseline.
Fast Distributed Training of Deep Neural Networks: Dynamic Communication Thresholding for Model and Data Parallelism
Oct 18, 2020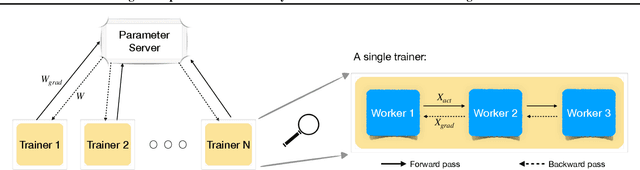
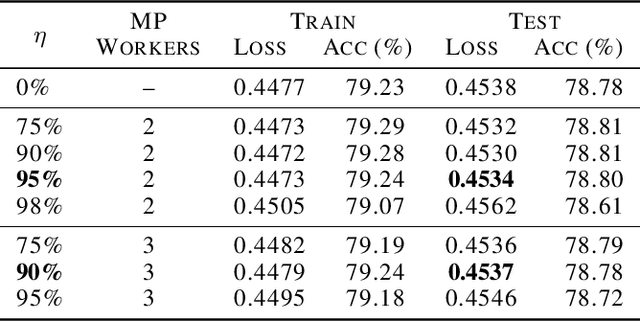
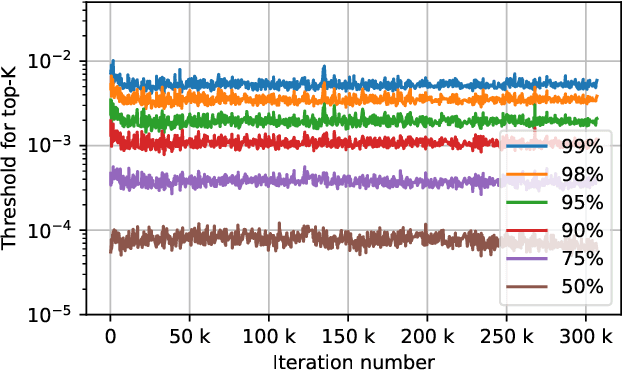
Data Parallelism (DP) and Model Parallelism (MP) are two common paradigms to enable large-scale distributed training of neural networks. Recent trends, such as the improved model performance of deeper and wider neural networks when trained with billions of data points, have prompted the use of hybrid parallelism---a paradigm that employs both DP and MP to scale further parallelization for machine learning. Hybrid training allows compute power to increase, but it runs up against the key bottleneck of communication overhead that hinders scalability. In this paper, we propose a compression framework called Dynamic Communication Thresholding (DCT) for communication-efficient hybrid training. DCT filters the entities to be communicated across the network through a simple hard-thresholding function, allowing only the most relevant information to pass through. For communication efficient DP, DCT compresses the parameter gradients sent to the parameter server during model synchronization, while compensating for the introduced errors with known techniques. For communication efficient MP, DCT incorporates a novel technique to compress the activations and gradients sent across the network during the forward and backward propagation, respectively. This is done by identifying and updating only the most relevant neurons of the neural network for each training sample in the data. Under modest assumptions, we show that the convergence of training is maintained with DCT. We evaluate DCT on natural language processing and recommender system models. DCT reduces overall communication by 20x, improving end-to-end training time on industry scale models by 37%. Moreover, we observe an improvement in the trained model performance, as the induced sparsity is possibly acting as an implicit sparsity based regularization.
MAF: Multimodal Alignment Framework for Weakly-Supervised Phrase Grounding
Oct 12, 2020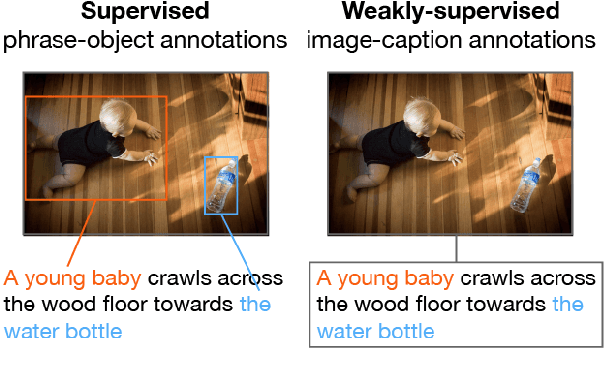
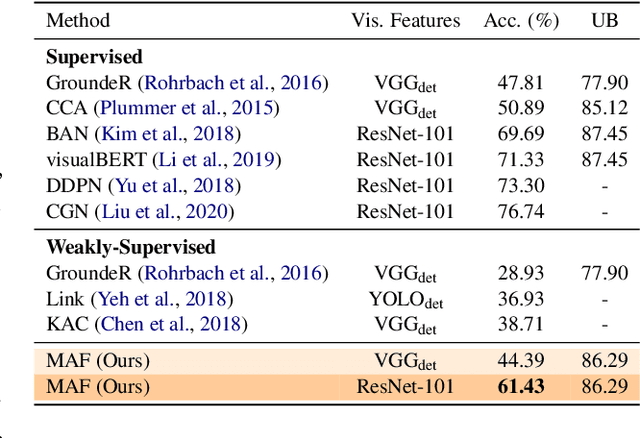
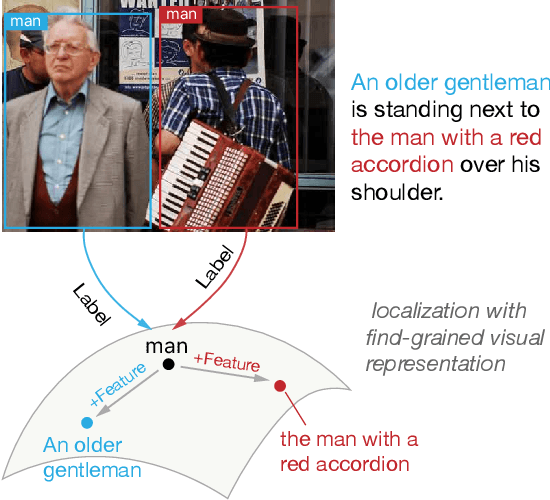
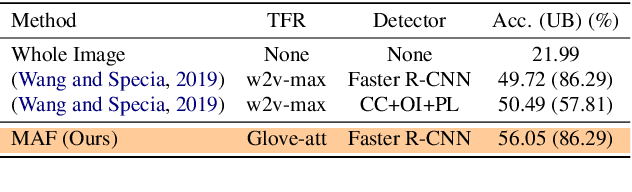
Phrase localization is a task that studies the mapping from textual phrases to regions of an image. Given difficulties in annotating phrase-to-object datasets at scale, we develop a Multimodal Alignment Framework (MAF) to leverage more widely-available caption-image datasets, which can then be used as a form of weak supervision. We first present algorithms to model phrase-object relevance by leveraging fine-grained visual representations and visually-aware language representations. By adopting a contrastive objective, our method uses information in caption-image pairs to boost the performance in weakly-supervised scenarios. Experiments conducted on the widely-adopted Flickr30k dataset show a significant improvement over existing weakly-supervised methods. With the help of the visually-aware language representations, we can also improve the previous best unsupervised result by 5.56%. We conduct ablation studies to show that both our novel model and our weakly-supervised strategies significantly contribute to our strong results.
Sparse Quantized Spectral Clustering
Oct 03, 2020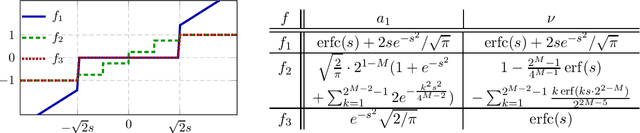

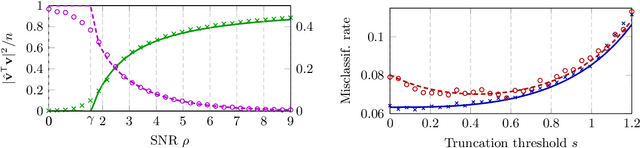
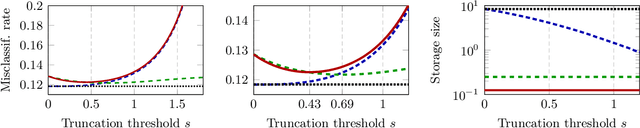
Given a large data matrix, sparsifying, quantizing, and/or performing other entry-wise nonlinear operations can have numerous benefits, ranging from speeding up iterative algorithms for core numerical linear algebra problems to providing nonlinear filters to design state-of-the-art neural network models. Here, we exploit tools from random matrix theory to make precise statements about how the eigenspectrum of a matrix changes under such nonlinear transformations. In particular, we show that very little change occurs in the informative eigenstructure even under drastic sparsification/quantization, and consequently that very little downstream performance loss occurs with very aggressively sparsified or quantized spectral clustering. We illustrate how these results depend on the nonlinearity, we characterize a phase transition beyond which spectral clustering becomes possible, and we show when such nonlinear transformations can introduce spurious non-informative eigenvectors.