 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline control of the false discovery rate with decaying memory
Oct 02, 2017
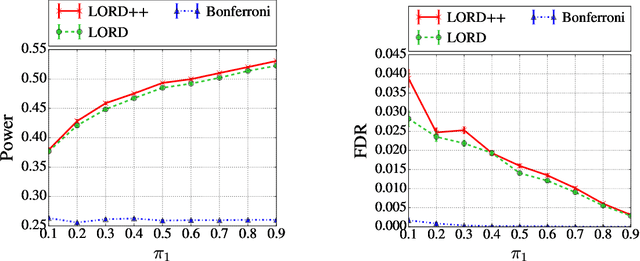

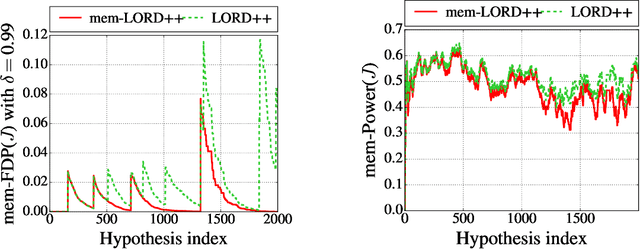
In the online multiple testing problem, p-values corresponding to different null hypotheses are observed one by one, and the decision of whether or not to reject the current hypothesis must be made immediately, after which the next p-value is observed. Alpha-investing algorithms to control the false discovery rate (FDR), formulated by Foster and Stine, have been generalized and applied to many settings, including quality-preserving databases in science and multiple A/B or multi-armed bandit tests for internet commerce. This paper improves the class of generalized alpha-investing algorithms (GAI) in four ways: (a) we show how to uniformly improve the power of the entire class of monotone GAI procedures by awarding more alpha-wealth for each rejection, giving a win-win resolution to a recent dilemma raised by Javanmard and Montanari, (b) we demonstrate how to incorporate prior weights to indicate domain knowledge of which hypotheses are likely to be non-null, (c) we allow for differing penalties for false discoveries to indicate that some hypotheses may be more important than others, (d) we define a new quantity called the decaying memory false discovery rate (mem-FDR) that may be more meaningful for truly temporal applications, and which alleviates problems that we describe and refer to as "piggybacking" and "alpha-death". Our GAI++ algorithms incorporate all four generalizations simultaneously, and reduce to more powerful variants of earlier algorithms when the weights and decay are all set to unity. Finally, we also describe a simple method to derive new online FDR rules based on an estimated false discovery proportion.
A unified treatment of multiple testing with prior knowledge using the p-filter
Sep 12, 2017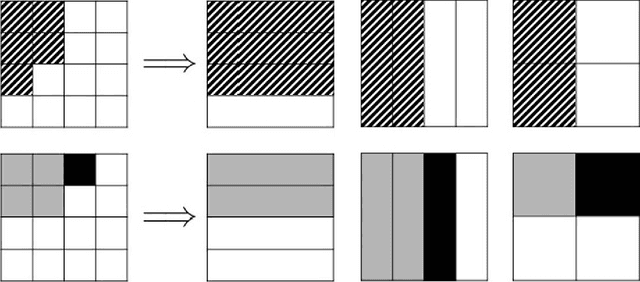
A significant literature studies ways of employing prior knowledge to improve power and precision of multiple testing procedures. Some common forms of prior knowledge may include (a) a priori beliefs about which hypotheses are null, modeled by non-uniform prior weights; (b) differing importances of hypotheses, modeled by differing penalties for false discoveries; (c) multiple arbitrary partitions of the hypotheses into known (possibly overlapping) groups, indicating (dis)similarity of hypotheses; and (d) knowledge of independence, positive or arbitrary dependence between hypotheses or groups, allowing for more aggressive or conservative procedures. We present a unified algorithmic framework called p-filter for global null testing and false discovery rate (FDR) control that allows the scientist to incorporate all four types of prior knowledge (a)-(d) simultaneously, recovering a wide variety of common algorithms as special cases.
Deep Transfer Learning with Joint Adaptation Networks
Aug 17, 2017



Deep networks have been successfully applied to learn transferable features for adapting models from a source domain to a different target domain. In this paper, we present joint adaptation networks (JAN), which learn a transfer network by aligning the joint distributions of multiple domain-specific layers across domains based on a joint maximum mean discrepancy (JMMD) criterion. Adversarial training strategy is adopted to maximize JMMD such that the distributions of the source and target domains are made more distinguishable. Learning can be performed by stochastic gradient descent with the gradients computed by back-propagation in linear-time. Experiments testify that our model yields state of the art results on standard datasets.
Partial Transfer Learning with Selective Adversarial Networks
Jul 25, 2017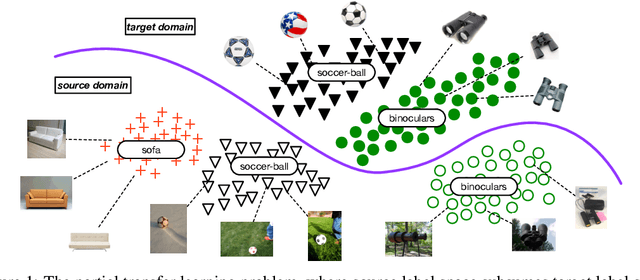
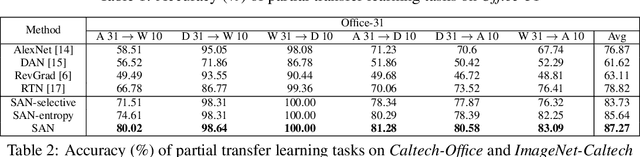
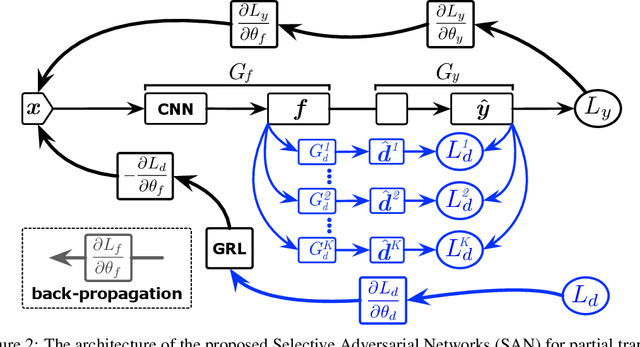
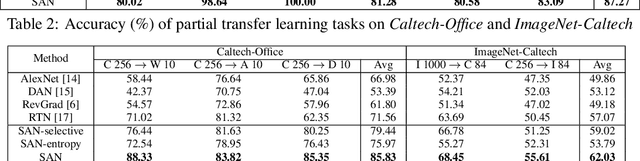
Adversarial learning has been successfully embedded into deep networks to learn transferable features, which reduce distribution discrepancy between the source and target domains. Existing domain adversarial networks assume fully shared label space across domains. In the presence of big data, there is strong motivation of transferring both classification and representation models from existing big domains to unknown small domains. This paper introduces partial transfer learning, which relaxes the shared label space assumption to that the target label space is only a subspace of the source label space. Previous methods typically match the whole source domain to the target domain, which are prone to negative transfer for the partial transfer problem. We present Selective Adversarial Network (SAN), which simultaneously circumvents negative transfer by selecting out the outlier source classes and promotes positive transfer by maximally matching the data distributions in the shared label space. Experiments demonstrate that our models exceed state-of-the-art results for partial transfer learning tasks on several benchmark datasets.
On kernel methods for covariates that are rankings
Jul 20, 2017Permutation-valued features arise in a variety of applications, either in a direct way when preferences are elicited over a collection of items, or an indirect way in which numerical ratings are converted to a ranking. To date, there has been relatively limited study of regression, classification, and testing problems based on permutation-valued features, as opposed to permutation-valued responses. This paper studies the use of reproducing kernel Hilbert space methods for learning from permutation-valued features. These methods embed the rankings into an implicitly defined function space, and allow for efficient estimation of regression and test functions in this richer space. Our first contribution is to characterize both the feature spaces and spectral properties associated with two kernels for rankings, the Kendall and Mallows kernels. Using tools from representation theory, we explain the limited expressive power of the Kendall kernel by characterizing its degenerate spectrum, and in sharp contrast, we prove that Mallows' kernel is universal and characteristic. We also introduce families of polynomial kernels that interpolate between the Kendall (degree one) and Mallows' (infinite degree) kernels. We show the practical effectiveness of our methods via applications to Eurobarometer survey data as well as a Movielens ratings dataset.
Less than a Single Pass: Stochastically Controlled Stochastic Gradient Method
Jul 03, 2017
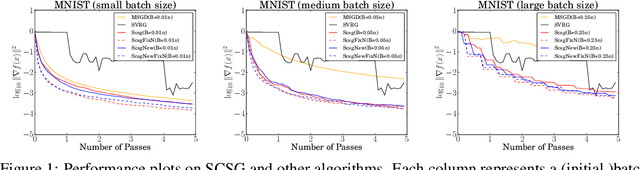

We develop and analyze a procedure for gradient-based optimization that we refer to as stochastically controlled stochastic gradient (SCSG). As a member of the SVRG family of algorithms, SCSG makes use of gradient estimates at two scales, with the number of updates at the faster scale being governed by a geometric random variable. Unlike most existing algorithms in this family, both the computation cost and the communication cost of SCSG do not necessarily scale linearly with the sample size $n$; indeed, these costs are independent of $n$ when the target accuracy is low. An experimental evaluation on real datasets confirms the effectiveness of SCSG.
Real-Time Machine Learning: The Missing Pieces
May 19, 2017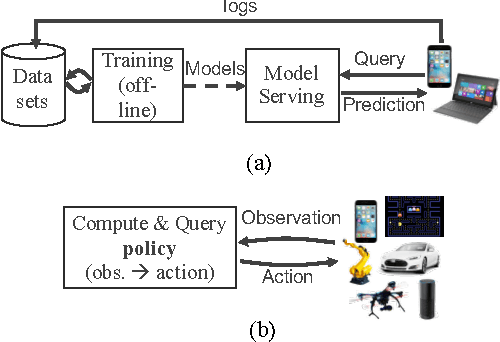
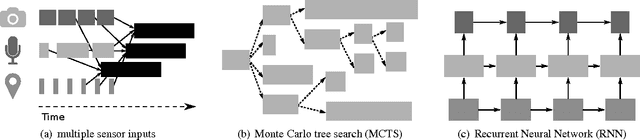
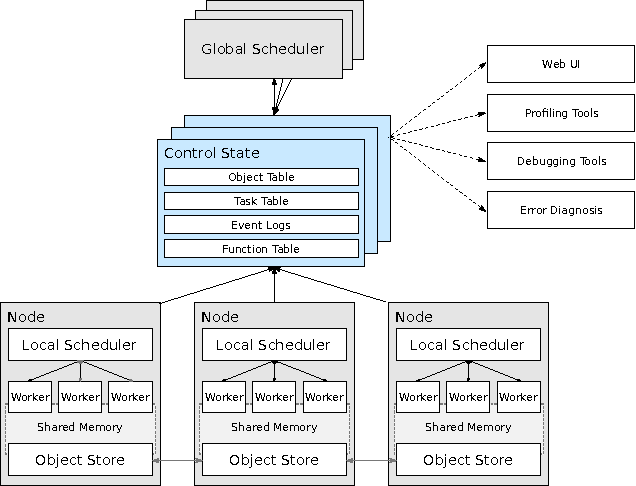
Machine learning applications are increasingly deployed not only to serve predictions using static models, but also as tightly-integrated components of feedback loops involving dynamic, real-time decision making. These applications pose a new set of requirements, none of which are difficult to achieve in isolation, but the combination of which creates a challenge for existing distributed execution frameworks: computation with millisecond latency at high throughput, adaptive construction of arbitrary task graphs, and execution of heterogeneous kernels over diverse sets of resources. We assert that a new distributed execution framework is needed for such ML applications and propose a candidate approach with a proof-of-concept architecture that achieves a 63x performance improvement over a state-of-the-art execution framework for a representative application.
Trust Region Policy Optimization
Apr 20, 2017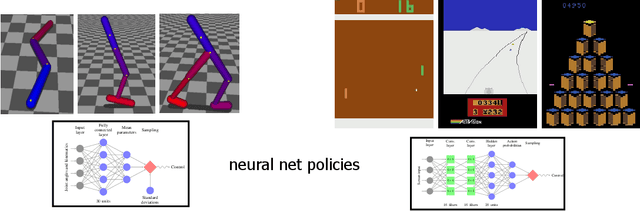
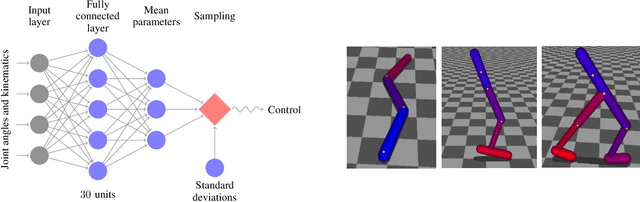
We describe an iterative procedure for optimizing policies, with guaranteed monotonic improvement. By making several approximations to the theoretically-justified procedure, we develop a practical algorithm, called Trust Region Policy Optimization (TRPO). This algorithm is similar to natural policy gradient methods and is effective for optimizing large nonlinear policies such as neural networks. Our experiments demonstrate its robust performance on a wide variety of tasks: learning simulated robotic swimming, hopping, and walking gaits; and playing Atari games using images of the screen as input. Despite its approximations that deviate from the theory, TRPO tends to give monotonic improvement, with little tuning of hyperparameters.
How to Escape Saddle Points Efficiently
Mar 02, 2017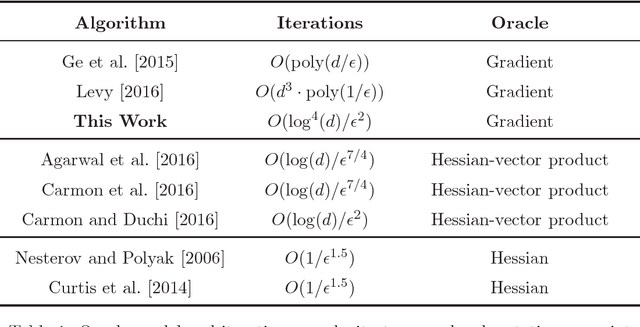
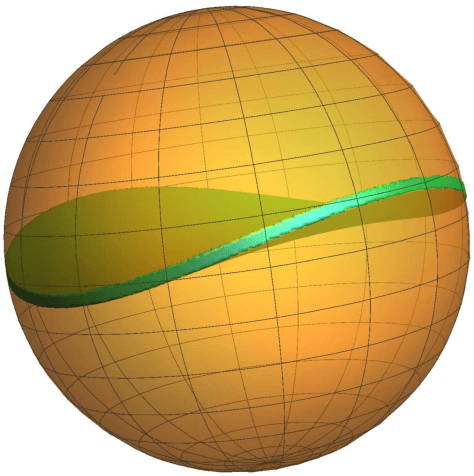
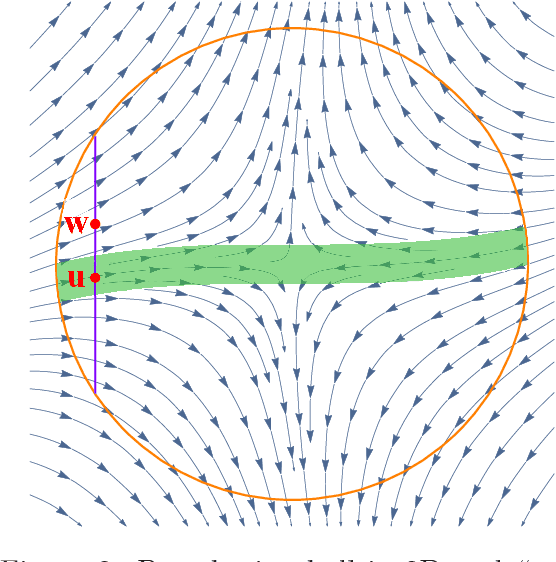
This paper shows that a perturbed form of gradient descent converges to a second-order stationary point in a number iterations which depends only poly-logarithmically on dimension (i.e., it is almost "dimension-free"). The convergence rate of this procedure matches the well-known convergence rate of gradient descent to first-order stationary points, up to log factors. When all saddle points are non-degenerate, all second-order stationary points are local minima, and our result thus shows that perturbed gradient descent can escape saddle points almost for free. Our results can be directly applied to many machine learning applications, including deep learning. As a particular concrete example of such an application, we show that our results can be used directly to establish sharp global convergence rates for matrix factorization. Our results rely on a novel characterization of the geometry around saddle points, which may be of independent interest to the non-convex optimization community.
Unsupervised Domain Adaptation with Residual Transfer Networks
Feb 16, 2017
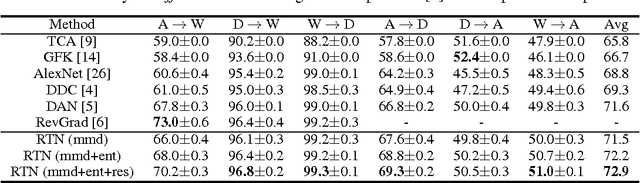
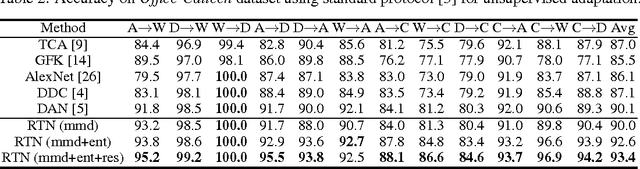
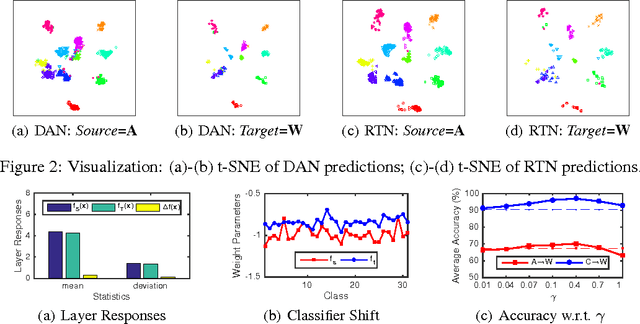
The recent success of deep neural networks relies on massive amounts of labeled data. For a target task where labeled data is unavailable, domain adaptation can transfer a learner from a different source domain. In this paper, we propose a new approach to domain adaptation in deep networks that can jointly learn adaptive classifiers and transferable features from labeled data in the source domain and unlabeled data in the target domain. We relax a shared-classifier assumption made by previous methods and assume that the source classifier and target classifier differ by a residual function. We enable classifier adaptation by plugging several layers into deep network to explicitly learn the residual function with reference to the target classifier. We fuse features of multiple layers with tensor product and embed them into reproducing kernel Hilbert spaces to match distributions for feature adaptation. The adaptation can be achieved in most feed-forward models by extending them with new residual layers and loss functions, which can be trained efficiently via back-propagation. Empirical evidence shows that the new approach outperforms state of the art methods on standard domain adaptation benchmarks.