 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Feature Selection via Conditional Covariance Minimization
Oct 20, 2018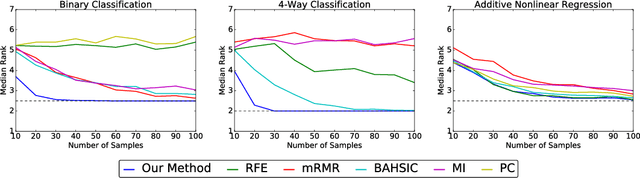

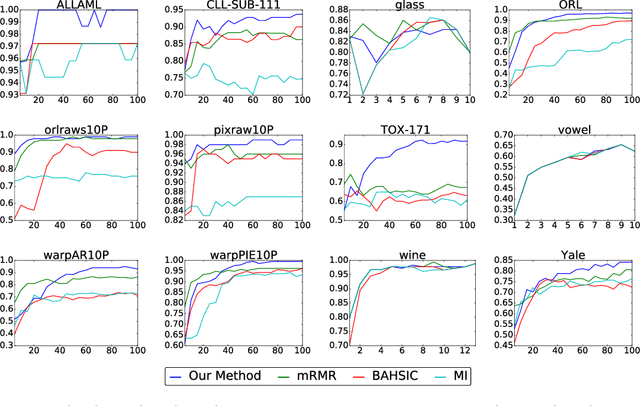
We propose a method for feature selection that employs kernel-based measures of independence to find a subset of covariates that is maximally predictive of the response. Building on past work in kernel dimension reduction, we show how to perform feature selection via a constrained optimization problem involving the trace of the conditional covariance operator. We prove various consistency results for this procedure, and also demonstrate that our method compares favorably with other state-of-the-art algorithms on a variety of synthetic and real data sets.
On the Local Minima of the Empirical Risk
Oct 17, 2018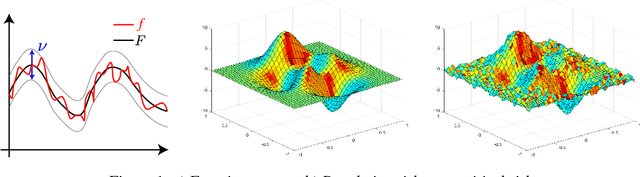
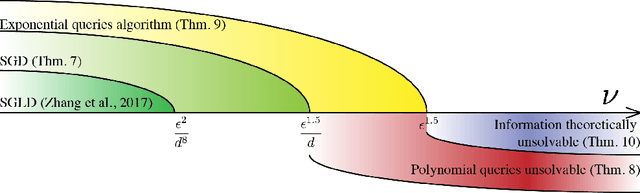
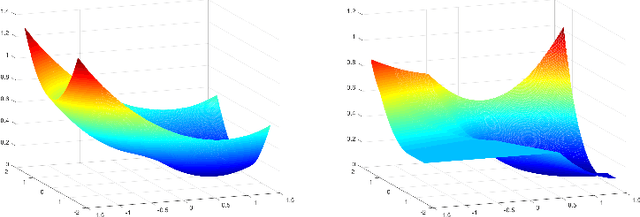
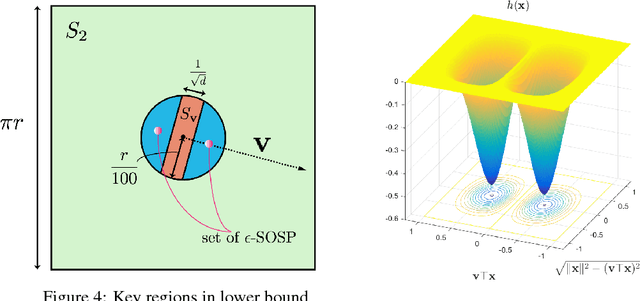
Population risk is always of primary interest in machine learning; however, learning algorithms only have access to the empirical risk. Even for applications with nonconvex nonsmooth losses (such as modern deep networks), the population risk is generally significantly more well-behaved from an optimization point of view than the empirical risk. In particular, sampling can create many spurious local minima. We consider a general framework which aims to optimize a smooth nonconvex function $F$ (population risk) given only access to an approximation $f$ (empirical risk) that is pointwise close to $F$ (i.e., $\|F-f\|_{\infty} \le \nu$). Our objective is to find the $\epsilon$-approximate local minima of the underlying function $F$ while avoiding the shallow local minima---arising because of the tolerance $\nu$---which exist only in $f$. We propose a simple algorithm based on stochastic gradient descent (SGD) on a smoothed version of $f$ that is guaranteed to achieve our goal as long as $\nu \le O(\epsilon^{1.5}/d)$. We also provide an almost matching lower bound showing that our algorithm achieves optimal error tolerance $\nu$ among all algorithms making a polynomial number of queries of $f$. As a concrete example, we show that our results can be directly used to give sample complexities for learning a ReLU unit.
Information Constraints on Auto-Encoding Variational Bayes
Oct 15, 2018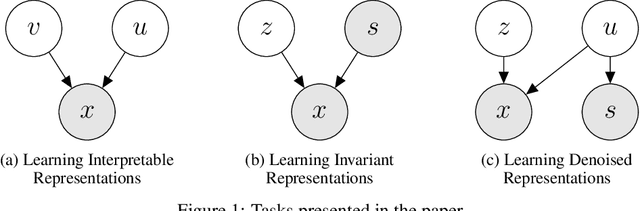
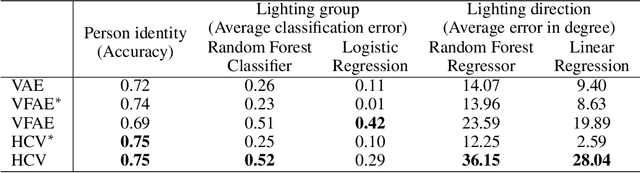
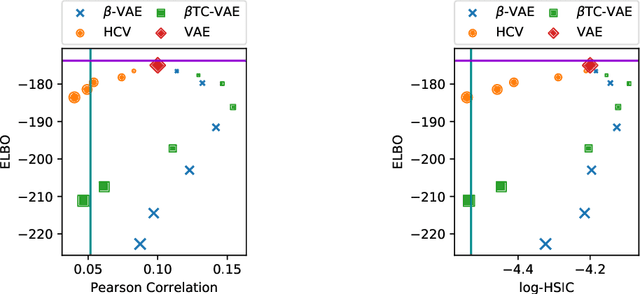

Parameterizing the approximate posterior of a generative model with neural networks has become a common theme in recent machine learning research. While providing appealing flexibility, this approach makes it difficult to impose or assess structural constraints such as conditional independence. We propose a framework for learning representations that relies on Auto-Encoding Variational Bayes and whose search space is constrained via kernel-based measures of independence. In particular, our method employs the $d$-variable Hilbert-Schmidt Independence Criterion (dHSIC) to enforce independence between the latent representations and arbitrary nuisance factors. We show how to apply this method to a range of problems, including the problems of learning invariant representations and the learning of interpretable representations. We also present a full-fledged application to single-cell RNA sequencing (scRNA-seq). In this setting the biological signal is mixed in complex ways with sequencing errors and sampling effects. We show that our method out-performs the state-of-the-art in this domain.
Rao-Blackwellized Stochastic Gradients for Discrete Distributions
Oct 10, 2018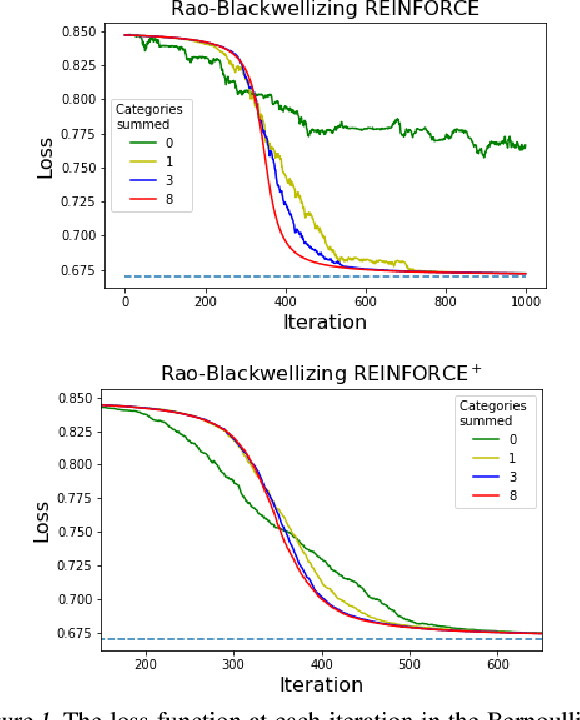
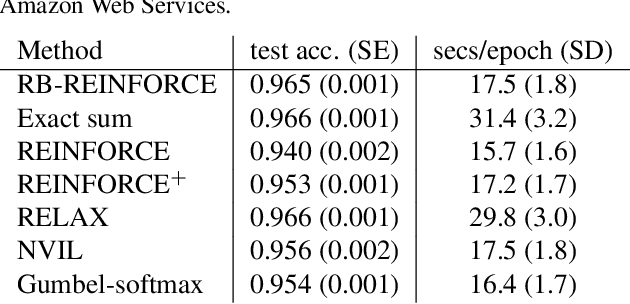
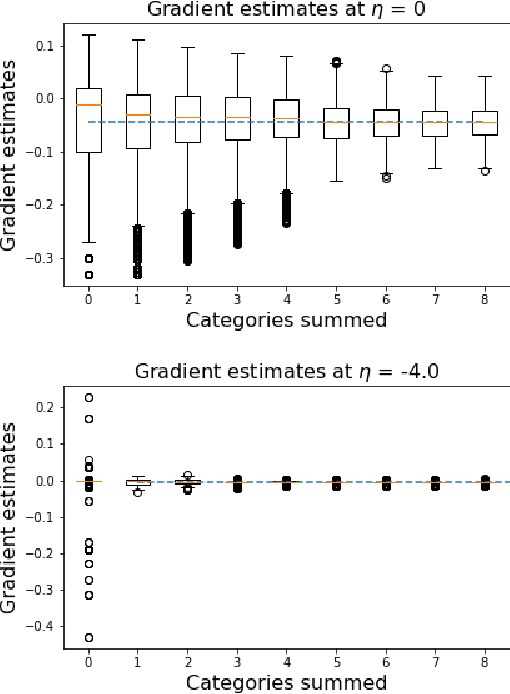
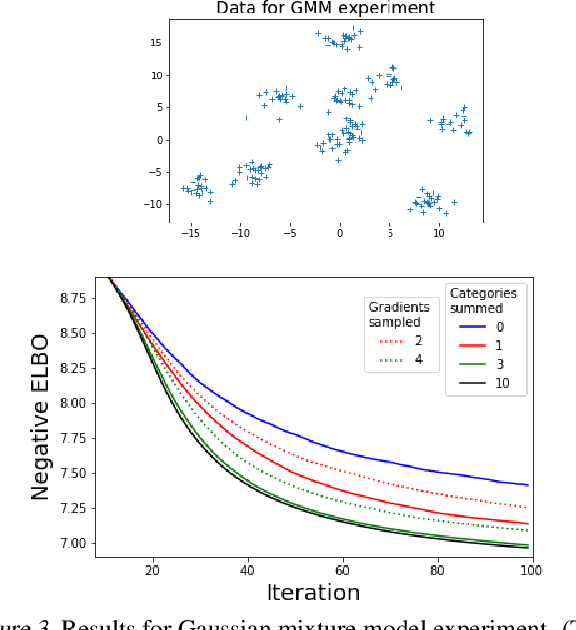
We wish to compute the gradient of an expectation over a finite or countably infinite sample space having $K \leq \infty$ categories. When $K$ is indeed infinite, or finite but very large, the relevant summation is intractable. Accordingly, various stochastic gradient estimators have been proposed. In this paper, we describe a technique that can be applied to reduce the variance of any such estimator, without changing its bias---in particular, unbiasedness is retained. We show that our technique is an instance of Rao-Blackwellization, and we demonstrate the improvement it yields in empirical studies on both synthetic and real-world data.
CoCoA: A General Framework for Communication-Efficient Distributed Optimization
Oct 10, 2018
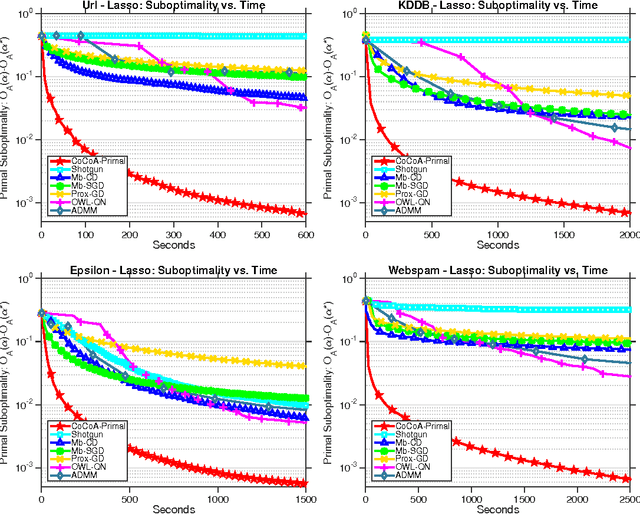

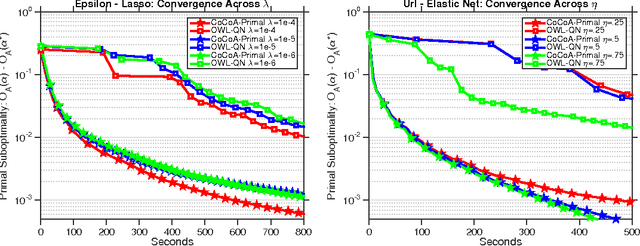
The scale of modern datasets necessitates the development of efficient distributed optimization methods for machine learning. We present a general-purpose framework for distributed computing environments, CoCoA, that has an efficient communication scheme and is applicable to a wide variety of problems in machine learning and signal processing. We extend the framework to cover general non-strongly-convex regularizers, including L1-regularized problems like lasso, sparse logistic regression, and elastic net regularization, and show how earlier work can be derived as a special case. We provide convergence guarantees for the class of convex regularized loss minimization objectives, leveraging a novel approach in handling non-strongly-convex regularizers and non-smooth loss functions. The resulting framework has markedly improved performance over state-of-the-art methods, as we illustrate with an extensive set of experiments on real distributed datasets.
Singularity, Misspecification, and the Convergence Rate of EM
Oct 01, 2018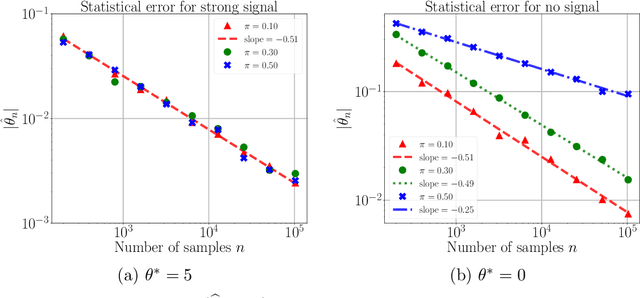
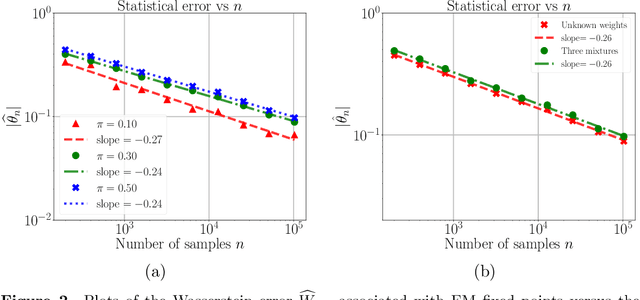
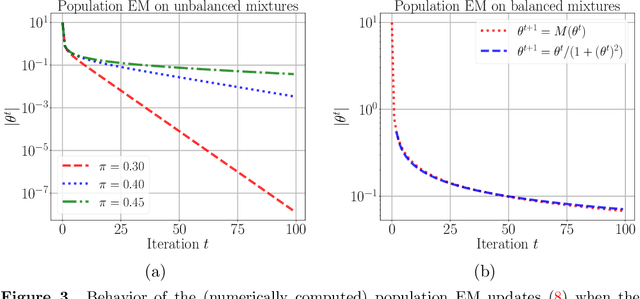
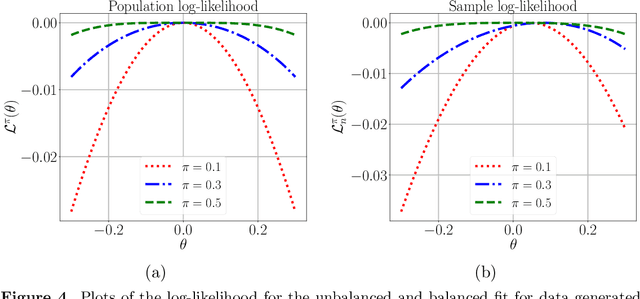
A line of recent work has characterized the behavior of the EM algorithm in favorable settings in which the population likelihood is locally strongly concave around its maximizing argument. Examples include suitably separated Gaussian mixture models and mixtures of linear regressions. We consider instead over-fitted settings in which the likelihood need not be strongly concave, or, equivalently, when the Fisher information matrix might be singular. In such settings, it is known that a global maximum of the MLE based on $n$ samples can have a non-standard $n^{-1/4}$ rate of convergence. How does the EM algorithm behave in such settings? Focusing on the simple setting of a two-component mixture fit to a multivariate Gaussian distribution, we study the behavior of the EM algorithm both when the mixture weights are different (unbalanced case), and are equal (balanced case). Our analysis reveals a sharp distinction between these cases: in the former, the EM algorithm converges geometrically to a point at Euclidean distance $O((d/n)^{1/2})$ from the true parameter, whereas in the latter case, the convergence rate is exponentially slower, and the fixed point has a much lower $O((d/n)^{1/4})$ accuracy. The slower convergence in the balanced over-fitted case arises from the singularity of the Fisher information matrix. Analysis of this singular case requires the introduction of some novel analysis techniques, in particular we make use of a careful form of localization in the associated empirical process, and develop a recursive argument to progressively sharpen the statistical rate.
Ray: A Distributed Framework for Emerging AI Applications
Sep 30, 2018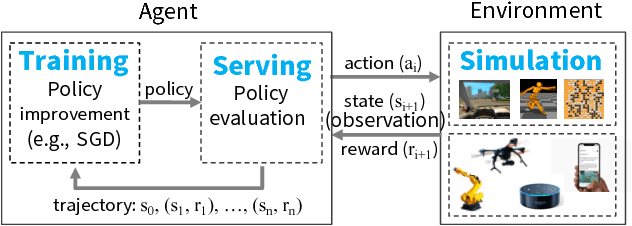


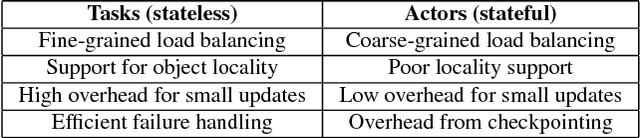
The next generation of AI applications will continuously interact with the environment and learn from these interactions. These applications impose new and demanding systems requirements, both in terms of performance and flexibility. In this paper, we consider these requirements and present Ray---a distributed system to address them. Ray implements a unified interface that can express both task-parallel and actor-based computations, supported by a single dynamic execution engine. To meet the performance requirements, Ray employs a distributed scheduler and a distributed and fault-tolerant store to manage the system's control state. In our experiments, we demonstrate scaling beyond 1.8 million tasks per second and better performance than existing specialized systems for several challenging reinforcement learning applications.
A Deep Generative Model for Semi-Supervised Classification with Noisy Labels
Sep 16, 2018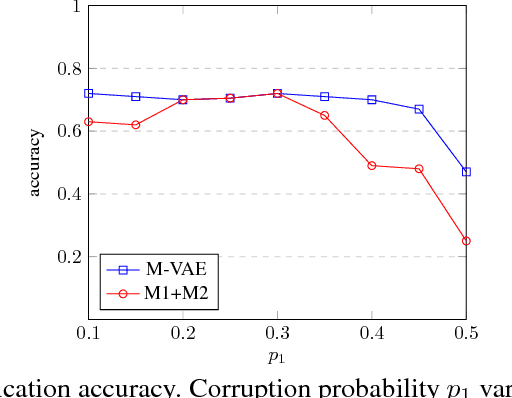
Class labels are often imperfectly observed, due to mistakes and to genuine ambiguity among classes. We propose a new semi-supervised deep generative model that explicitly models noisy labels, called the Mislabeled VAE (M-VAE). The M-VAE can perform better than existing deep generative models which do not account for label noise. Additionally, the derivation of M-VAE gives new theoretical insights into the popular M1+M2 semi-supervised model.
Sharp Convergence Rates for Langevin Dynamics in the Nonconvex Setting
Sep 07, 2018We study the problem of sampling from a distribution where the negative logarithm of the target density is $L$-smooth everywhere and $m$-strongly convex outside a ball of radius $R$, but potentially non-convex inside this ball. We study both overdamped and underdamped Langevin MCMC and prove upper bounds on the time required to obtain a sample from a distribution that is within $\epsilon$ of the target distribution in $1$-Wasserstein distance. For the first-order method (overdamped Langevin MCMC), the time complexity is $\tilde{\mathcal{O}}\left(e^{cLR^2}\frac{d}{\epsilon^2}\right)$, where $d$ is the dimension of the underlying space. For the second-order method (underdamped Langevin MCMC), the time complexity is $\tilde{\mathcal{O}}\left(e^{cLR^2}\frac{\sqrt{d}}{\epsilon}\right)$ for some explicit positive constant $c$. Surprisingly, the convergence rate is only polynomial in the dimension $d$ and the target accuracy $\epsilon$. It is however exponential in the problem parameter $LR^2$, which is a measure of non-logconcavity of the target distribution.
L-Shapley and C-Shapley: Efficient Model Interpretation for Structured Data
Aug 08, 2018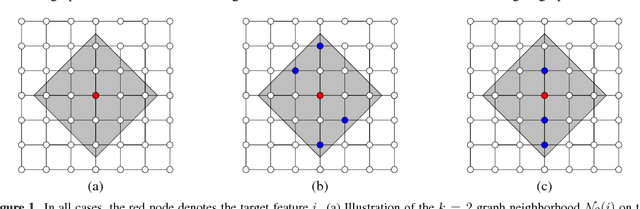

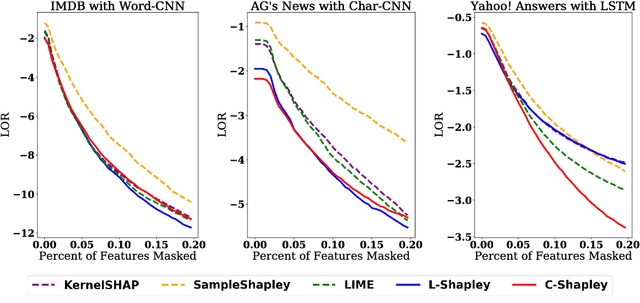

We study instancewise feature importance scoring as a method for model interpretation. Any such method yields, for each predicted instance, a vector of importance scores associated with the feature vector. Methods based on the Shapley score have been proposed as a fair way of computing feature attributions of this kind, but incur an exponential complexity in the number of features. This combinatorial explosion arises from the definition of the Shapley value and prevents these methods from being scalable to large data sets and complex models. We focus on settings in which the data have a graph structure, and the contribution of features to the target variable is well-approximated by a graph-structured factorization. In such settings, we develop two algorithms with linear complexity for instancewise feature importance scoring. We establish the relationship of our methods to the Shapley value and another closely related concept known as the Myerson value from cooperative game theory. We demonstrate on both language and image data that our algorithms compare favorably with other methods for model interpretation.