Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Value Estimation for Efficient Model-Free Reinforcement Learning
Paper and Code
Feb 28, 2018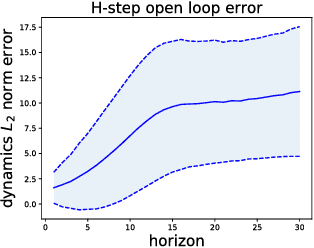

Recent model-free reinforcement learning algorithms have proposed incorporating learned dynamics models as a source of additional data with the intention of reducing sample complexity. Such methods hold the promise of incorporating imagined data coupled with a notion of model uncertainty to accelerate the learning of continuous control tasks. Unfortunately, they rely on heuristics that limit usage of the dynamics model. We present model-based value expansion, which controls for uncertainty in the model by only allowing imagination to fixed depth. By enabling wider use of learned dynamics models within a model-free reinforcement learning algorithm, we improve value estimation, which, in turn, reduces the sample complexity of learning.
View paper on