 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Reinforcement Learning Find Stackelberg-Nash Equilibria in General-Sum Markov Games with Myopic Followers?
Dec 27, 2021We study multi-player general-sum Markov games with one of the players designated as the leader and the other players regarded as followers. In particular, we focus on the class of games where the followers are myopic, i.e., they aim to maximize their instantaneous rewards. For such a game, our goal is to find a Stackelberg-Nash equilibrium (SNE), which is a policy pair $(\pi^*, \nu^*)$ such that (i) $\pi^*$ is the optimal policy for the leader when the followers always play their best response, and (ii) $\nu^*$ is the best response policy of the followers, which is a Nash equilibrium of the followers' game induced by $\pi^*$. We develop sample-efficient reinforcement learning (RL) algorithms for solving for an SNE in both online and offline settings. Our algorithms are optimistic and pessimistic variants of least-squares value iteration, and they are readily able to incorporate function approximation tools in the setting of large state spaces. Furthermore, for the case with linear function approximation, we prove that our algorithms achieve sublinear regret and suboptimality under online and offline setups respectively. To the best of our knowledge, we establish the first provably efficient RL algorithms for solving for SNEs in general-sum Markov games with myopic followers.
Assessment of Treatment Effect Estimators for Heavy-Tailed Data
Dec 19, 2021



A central obstacle in the objective assessment of treatment effect (TE) estimators in randomized control trials (RCTs) is the lack of ground truth (or validation set) to test their performance. In this paper, we provide a novel cross-validation-like methodology to address this challenge. The key insight of our procedure is that the noisy (but unbiased) difference-of-means estimate can be used as a ground truth "label" on a portion of the RCT, to test the performance of an estimator trained on the other portion. We combine this insight with an aggregation scheme, which borrows statistical strength across a large collection of RCTs, to present an end-to-end methodology for judging an estimator's ability to recover the underlying treatment effect. We evaluate our methodology across 709 RCTs implemented in the Amazon supply chain. In the corpus of AB tests at Amazon, we highlight the unique difficulties associated with recovering the treatment effect due to the heavy-tailed nature of the response variables. In this heavy-tailed setting, our methodology suggests that procedures that aggressively downweight or truncate large values, while introducing bias, lower the variance enough to ensure that the treatment effect is more accurately estimated.
ElegantRL-Podracer: Scalable and Elastic Library for Cloud-Native Deep Reinforcement Learning
Dec 11, 2021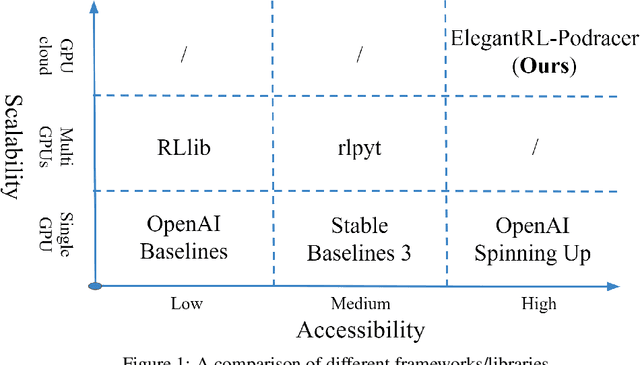
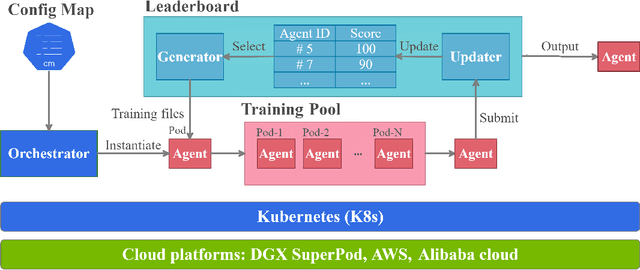

Deep reinforcement learning (DRL) has revolutionized learning and actuation in applications such as game playing and robotic control. The cost of data collection, i.e., generating transitions from agent-environment interactions, remains a major challenge for wider DRL adoption in complex real-world problems. Following a cloud-native paradigm to train DRL agents on a GPU cloud platform is a promising solution. In this paper, we present a scalable and elastic library ElegantRL-podracer for cloud-native deep reinforcement learning, which efficiently supports millions of GPU cores to carry out massively parallel training at multiple levels. At a high-level, ElegantRL-podracer employs a tournament-based ensemble scheme to orchestrate the training process on hundreds or even thousands of GPUs, scheduling the interactions between a leaderboard and a training pool with hundreds of pods. At a low-level, each pod simulates agent-environment interactions in parallel by fully utilizing nearly 7,000 GPU CUDA cores in a single GPU. Our ElegantRL-podracer library features high scalability, elasticity and accessibility by following the development principles of containerization, microservices and MLOps. Using an NVIDIA DGX SuperPOD cloud, we conduct extensive experiments on various tasks in locomotion and stock trading and show that ElegantRL-podracer substantially outperforms RLlib. Our codes are available on GitHub.
* 9 pages, 7 figures
An Instance-Dependent Analysis for the Cooperative Multi-Player Multi-Armed Bandit
Nov 08, 2021
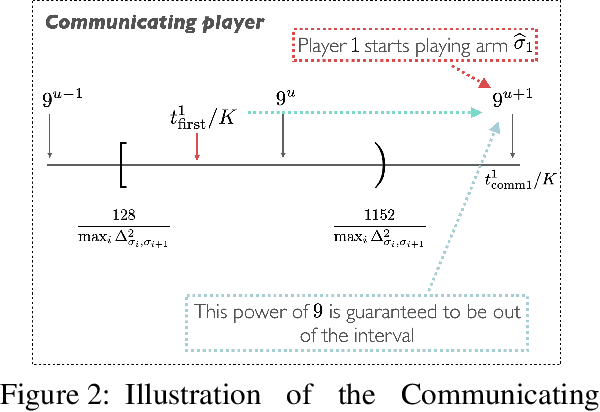
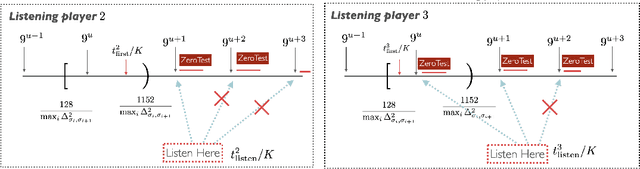
We study the problem of information sharing and cooperation in Multi-Player Multi-Armed bandits. We propose the first algorithm that achieves logarithmic regret for this problem. Our results are based on two innovations. First, we show that a simple modification to a successive elimination strategy can be used to allow the players to estimate their suboptimality gaps, up to constant factors, in the absence of collisions. Second, we leverage the first result to design a communication protocol that successfully uses the small reward of collisions to coordinate among players, while preserving meaningful instance-dependent logarithmic regret guarantees.
Cluster-and-Conquer: A Framework For Time-Series Forecasting
Oct 26, 2021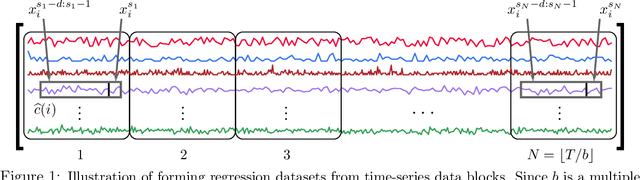
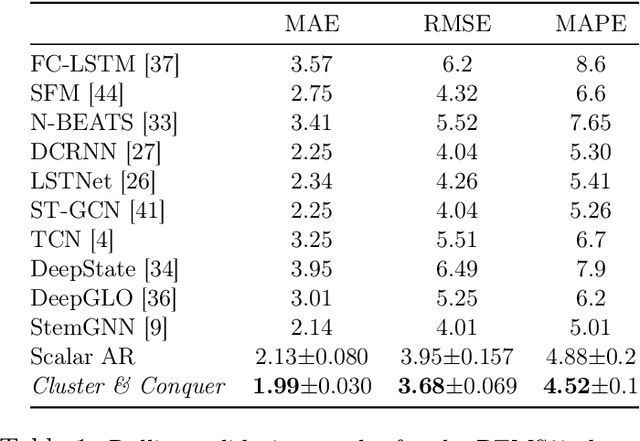
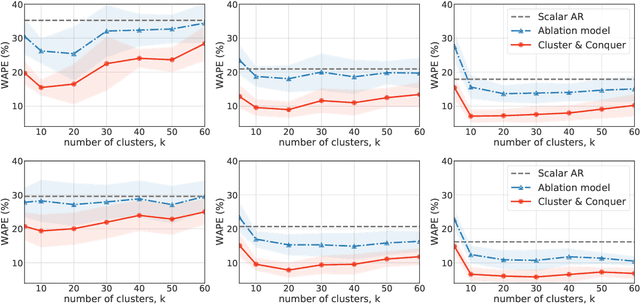
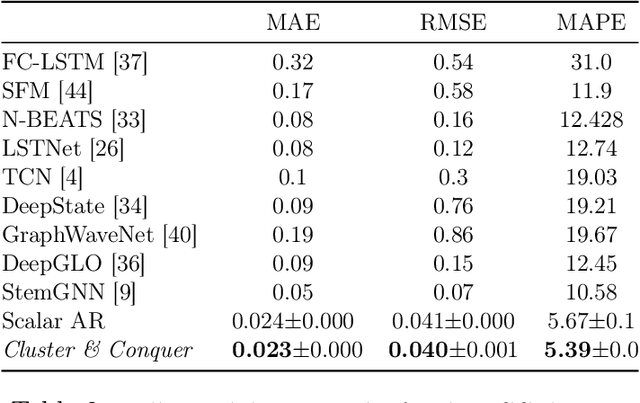
We propose a three-stage framework for forecasting high-dimensional time-series data. Our method first estimates parameters for each univariate time series. Next, we use these parameters to cluster the time series. These clusters can be viewed as multivariate time series, for which we then compute parameters. The forecasted values of a single time series can depend on the history of other time series in the same cluster, accounting for intra-cluster similarity while minimizing potential noise in predictions by ignoring inter-cluster effects. Our framework -- which we refer to as "cluster-and-conquer" -- is highly general, allowing for any time-series forecasting and clustering method to be used in each step. It is computationally efficient and embarrassingly parallel. We motivate our framework with a theoretical analysis in an idealized mixed linear regression setting, where we provide guarantees on the quality of the estimates. We accompany these guarantees with experimental results that demonstrate the advantages of our framework: when instantiated with simple linear autoregressive models, we are able to achieve state-of-the-art results on several benchmark datasets, sometimes outperforming deep-learning-based approaches.
Ranking and Tuning Pre-trained Models: A New Paradigm of Exploiting Model Hubs
Oct 20, 2021
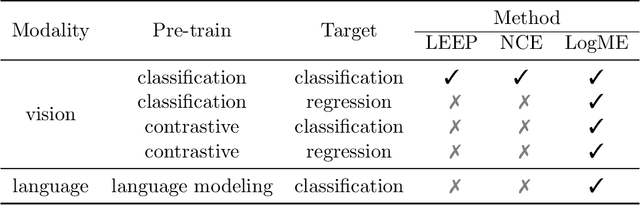
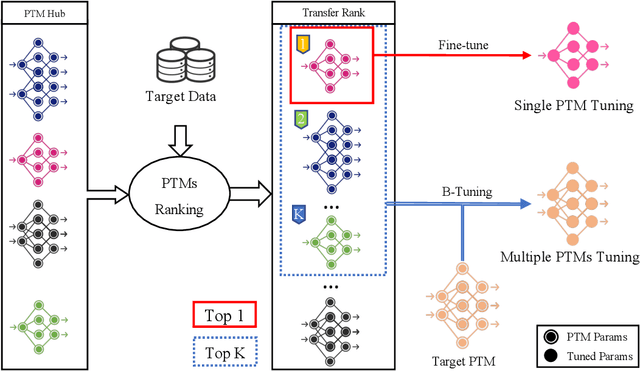
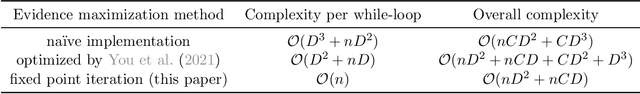
Pre-trained model hubs with many pre-trained models (PTMs) have been a cornerstone in deep learning. Although built at a high cost, they are in fact \emph{under-exploited}: practitioners usually pick one PTM from the provided model hub by popularity, and then fine-tune the PTM to solve the target task. This na\"ve but common practice poses two obstacles to sufficiently exploiting pre-trained model hubs: (1) the PTM selection procedure has no optimality guarantee; (2) only one PTM is used while the rest PTMs are overlooked. Ideally, to maximally exploit pre-trained model hubs, trying all combinations of PTMs and extensively fine-tuning each combination of PTMs are required, which incurs exponential combinations and unaffordable computational budget. In this paper, we propose a new paradigm of exploiting model hubs by ranking and tuning pre-trained models: (1) Our conference work~\citep{you_logme:_2021} proposed LogME to estimate the maximum value of label evidence given features extracted by pre-trained models, which can rank all the PTMs in a model hub for various types of PTMs and tasks \emph{before fine-tuning}. (2) the best ranked PTM can be fine-tuned and deployed if we have no preference for the model's architecture, or the target PTM can be tuned by top-K ranked PTMs via the proposed B-Tuning algorithm. The ranking part is based on the conference paper, and we complete its theoretical analysis (convergence proof of the heuristic evidence maximization procedure, and the influence of feature dimension) in this paper. The tuning part introduces a novel Bayesian Tuning (B-Tuning) method for multiple PTMs tuning, which surpasses dedicated methods designed for homogeneous PTMs tuning and sets up new state of the art for heterogeneous PTMs tuning. We believe the new paradigm of exploiting PTM hubs can interest a large audience of the community.
Learn then Test: Calibrating Predictive Algorithms to Achieve Risk Control
Oct 14, 2021
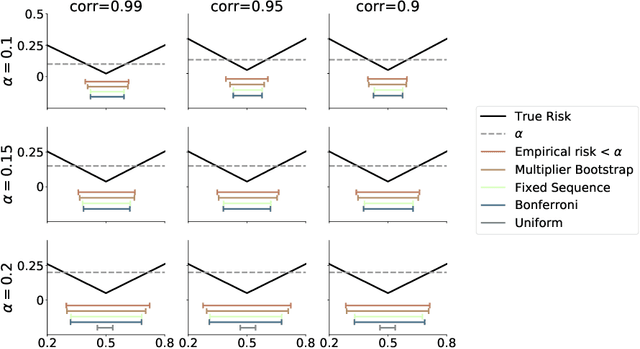

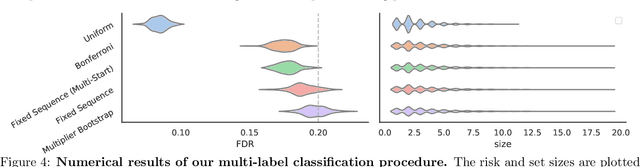
We introduce Learn then Test, a framework for calibrating machine learning models so that their predictions satisfy explicit, finite-sample statistical guarantees regardless of the underlying model and (unknown) data-generating distribution. The framework addresses, among other examples, false discovery rate control in multi-label classification, intersection-over-union control in instance segmentation, and the simultaneous control of the type-1 error of outlier detection and confidence set coverage in classification or regression. To accomplish this, we solve a key technical challenge: the control of arbitrary risks that are not necessarily monotonic. Our main insight is to reframe the risk-control problem as multiple hypothesis testing, enabling techniques and mathematical arguments different from those in the previous literature. We use our framework to provide new calibration methods for several core machine learning tasks with detailed worked examples in computer vision.
On the Self-Penalization Phenomenon in Feature Selection
Oct 12, 2021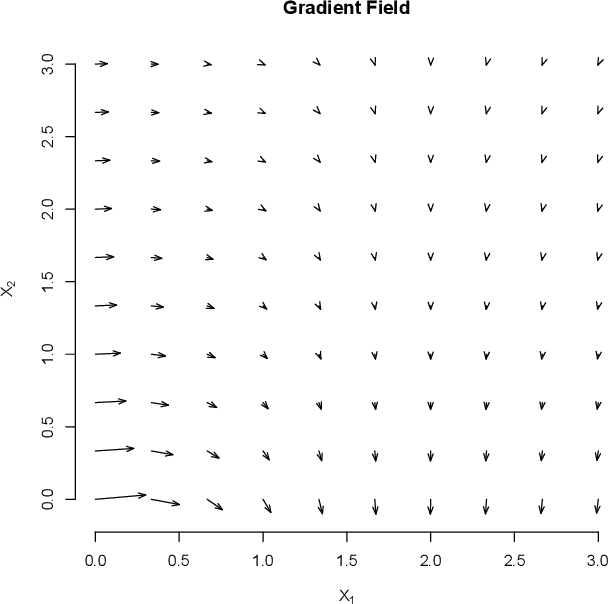
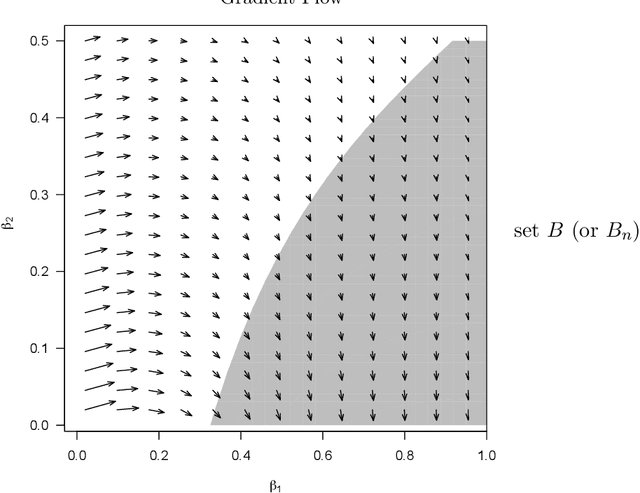
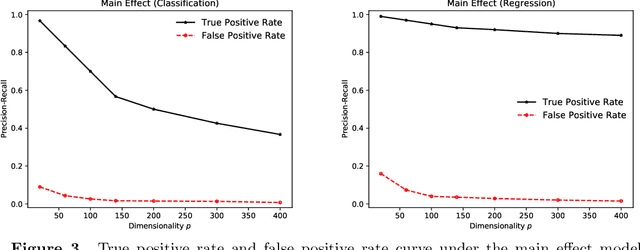
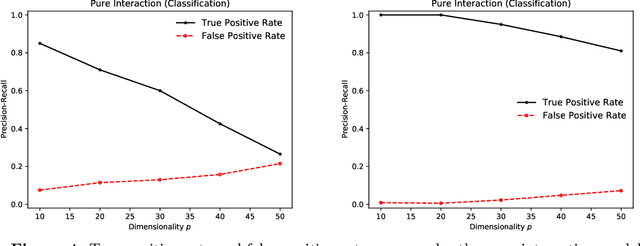
We describe an implicit sparsity-inducing mechanism based on minimization over a family of kernels: \begin{equation*} \min_{\beta, f}~\widehat{\mathbb{E}}[L(Y, f(\beta^{1/q} \odot X)] + \lambda_n \|f\|_{\mathcal{H}_q}^2~~\text{subject to}~~\beta \ge 0, \end{equation*} where $L$ is the loss, $\odot$ is coordinate-wise multiplication and $\mathcal{H}_q$ is the reproducing kernel Hilbert space based on the kernel $k_q(x, x') = h(\|x-x'\|_q^q)$, where $\|\cdot\|_q$ is the $\ell_q$ norm. Using gradient descent to optimize this objective with respect to $\beta$ leads to exactly sparse stationary points with high probability. The sparsity is achieved without using any of the well-known explicit sparsification techniques such as penalization (e.g., $\ell_1$), early stopping or post-processing (e.g., clipping). As an application, we use this sparsity-inducing mechanism to build algorithms consistent for feature selection.
SOUL: An Energy-Efficient Unsupervised Online Learning Seizure Detection Classifier
Oct 01, 2021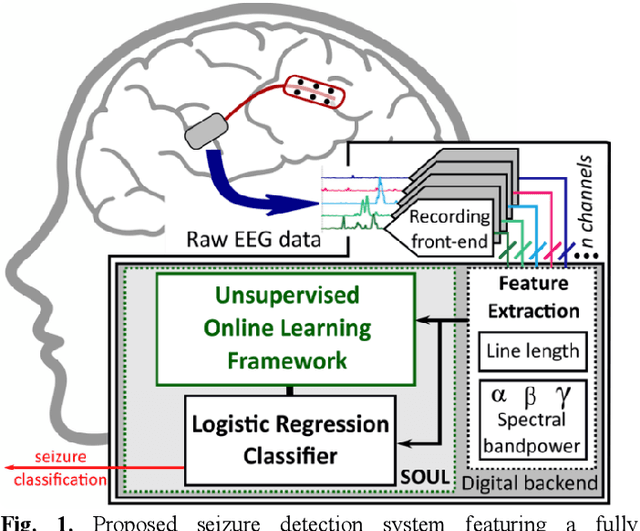
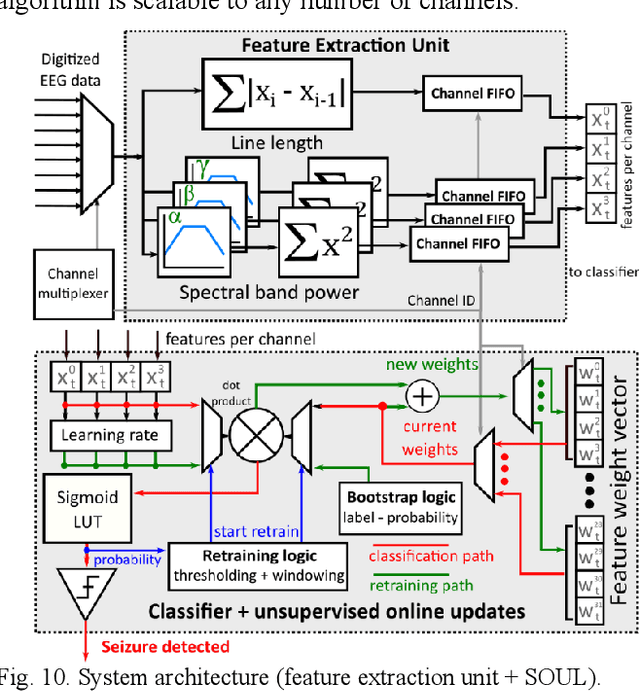
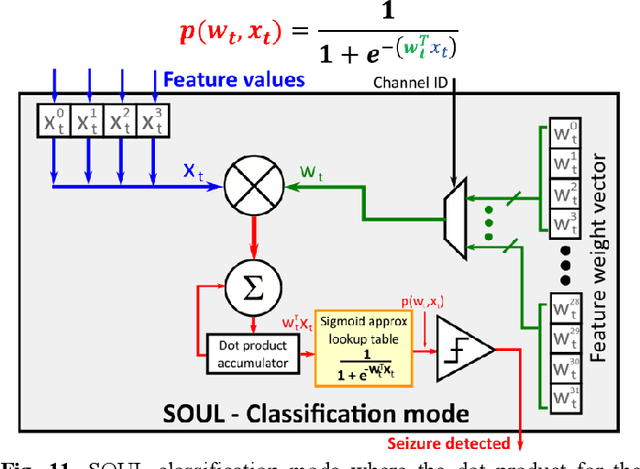
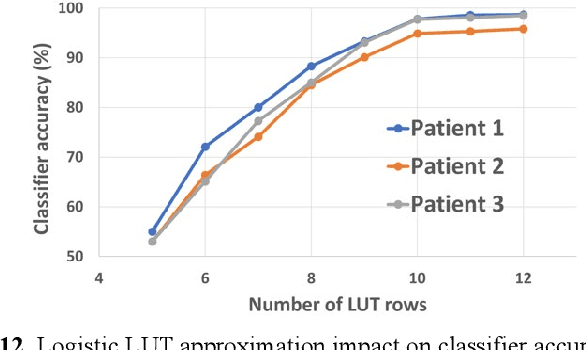
Implantable devices that record neural activity and detect seizures have been adopted to issue warnings or trigger neurostimulation to suppress epileptic seizures. Typical seizure detection systems rely on high-accuracy offline-trained machine learning classifiers that require manual retraining when seizure patterns change over long periods of time. For an implantable seizure detection system, a low power, at-the-edge, online learning algorithm can be employed to dynamically adapt to the neural signal drifts, thereby maintaining high accuracy without external intervention. This work proposes SOUL: Stochastic-gradient-descent-based Online Unsupervised Logistic regression classifier. After an initial offline training phase, continuous online unsupervised classifier updates are applied in situ, which improves sensitivity in patients with drifting seizure features. SOUL was tested on two human electroencephalography (EEG) datasets: the CHB-MIT scalp EEG dataset, and a long (>100 hours) NeuroVista intracranial EEG dataset. It was able to achieve an average sensitivity of 97.5% and 97.9% for the two datasets respectively, at >95% specificity. Sensitivity improved by at most 8.2% on long-term data when compared to a typical seizure detection classifier. SOUL was fabricated in TSMC's 28 nm process occupying 0.1 mm2 and achieves 1.5 nJ/classification energy efficiency, which is at least 24x more efficient than state-of-the-art.
Desiderata for Representation Learning: A Causal Perspective
Sep 08, 2021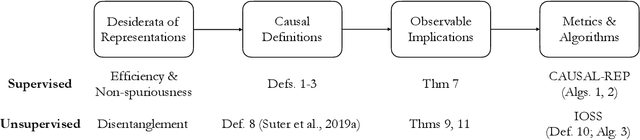
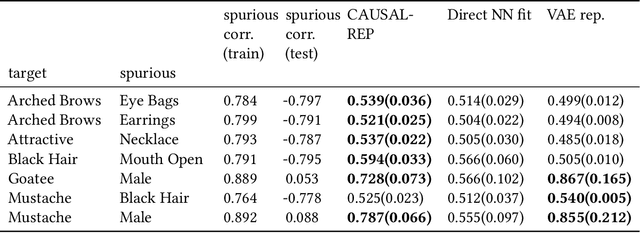
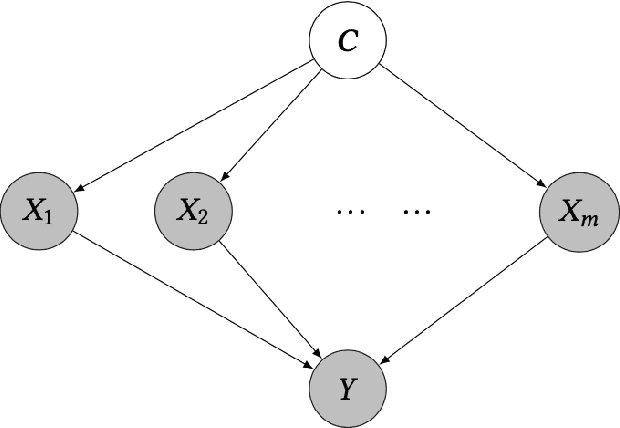

Representation learning constructs low-dimensional representations to summarize essential features of high-dimensional data. This learning problem is often approached by describing various desiderata associated with learned representations; e.g., that they be non-spurious, efficient, or disentangled. It can be challenging, however, to turn these intuitive desiderata into formal criteria that can be measured and enhanced based on observed data. In this paper, we take a causal perspective on representation learning, formalizing non-spuriousness and efficiency (in supervised representation learning) and disentanglement (in unsupervised representation learning) using counterfactual quantities and observable consequences of causal assertions. This yields computable metrics that can be used to assess the degree to which representations satisfy the desiderata of interest and learn non-spurious and disentangled representations from single observational datasets.