 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling
Oct 15, 2024



Recent advances in knowledge distillation (KD) have enabled smaller student models to approach the performance of larger teacher models. However, popular methods such as supervised KD and on-policy KD, are adversely impacted by the knowledge gaps between teacher-student in practical scenarios. Supervised KD suffers from a distribution mismatch between training with a static dataset and inference over final student-generated outputs. Conversely, on-policy KD, which uses student-generated samples for training, can suffer from low-quality training examples with which teacher models are not familiar, resulting in inaccurate teacher feedback. To address these limitations, we introduce Speculative Knowledge Distillation (SKD), a novel approach that leverages cooperation between student and teacher models to generate high-quality training data on-the-fly while aligning with the student's inference-time distribution. In SKD, the student proposes tokens, and the teacher replaces poorly ranked ones based on its own distribution, transferring high-quality knowledge adaptively. We evaluate SKD on various text generation tasks, including translation, summarization, math, and instruction following, and show that SKD consistently outperforms existing KD methods across different domains, data sizes, and model initialization strategies.
A Study on the Calibration of In-context Learning
Dec 11, 2023



Modern auto-regressive language models are trained to minimize log loss on broad data by predicting the next token so they are expected to get calibrated answers in next-token prediction tasks. We study this for in-context learning (ICL), a widely used way to adapt frozen large language models (LLMs) via crafting prompts, and investigate the trade-offs between performance and calibration on a wide range of natural language understanding and reasoning tasks. We conduct extensive experiments to show that such trade-offs may get worse as we increase model size, incorporate more ICL examples, and fine-tune models using instruction, dialog, or reinforcement learning from human feedback (RLHF) on carefully curated datasets. Furthermore, we find that common recalibration techniques that are widely effective such as temperature scaling provide limited gains in calibration errors, suggesting that new methods may be required for settings where models are expected to be reliable.
Learning an Inventory Control Policy with General Inventory Arrival Dynamics
Oct 26, 2023



In this paper we address the problem of learning and backtesting inventory control policies in the presence of general arrival dynamics -- which we term as a quantity-over-time arrivals model (QOT). We also allow for order quantities to be modified as a post-processing step to meet vendor constraints such as order minimum and batch size constraints -- a common practice in real supply chains. To the best of our knowledge this is the first work to handle either arbitrary arrival dynamics or an arbitrary downstream post-processing of order quantities. Building upon recent work (Madeka et al., 2022) we similarly formulate the periodic review inventory control problem as an exogenous decision process, where most of the state is outside the control of the agent. Madeka et al. (2022) show how to construct a simulator that replays historic data to solve this class of problem. In our case, we incorporate a deep generative model for the arrivals process as part of the history replay. By formulating the problem as an exogenous decision process, we can apply results from Madeka et al. (2022) to obtain a reduction to supervised learning. Finally, we show via simulation studies that this approach yields statistically significant improvements in profitability over production baselines. Using data from an ongoing real-world A/B test, we show that Gen-QOT generalizes well to off-policy data.
Contextual Bandits for Evaluating and Improving Inventory Control Policies
Oct 24, 2023
Solutions to address the periodic review inventory control problem with nonstationary random demand, lost sales, and stochastic vendor lead times typically involve making strong assumptions on the dynamics for either approximation or simulation, and applying methods such as optimization, dynamic programming, or reinforcement learning. Therefore, it is important to analyze and evaluate any inventory control policy, in particular to see if there is room for improvement. We introduce the concept of an equilibrium policy, a desirable property of a policy that intuitively means that, in hindsight, changing only a small fraction of actions does not result in materially more reward. We provide a light-weight contextual bandit-based algorithm to evaluate and occasionally tweak policies, and show that this method achieves favorable guarantees, both theoretically and in empirical studies.
Scaling Laws for Imitation Learning in NetHack
Jul 18, 2023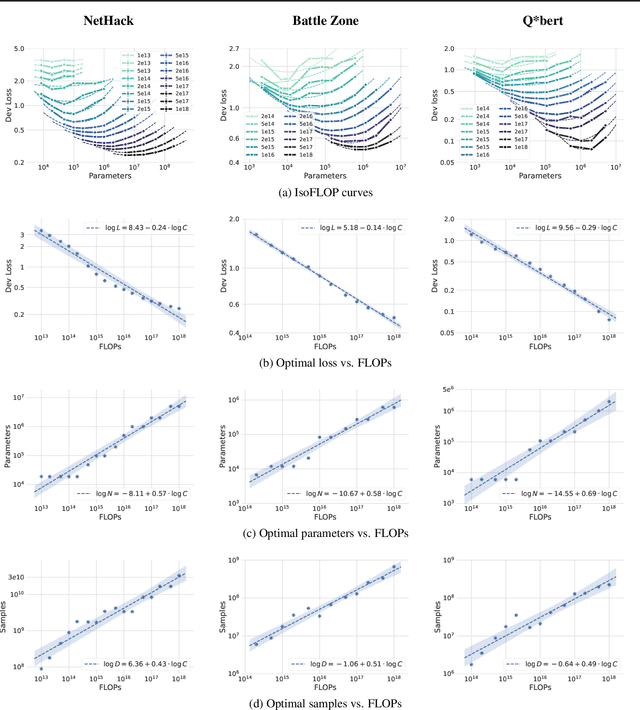

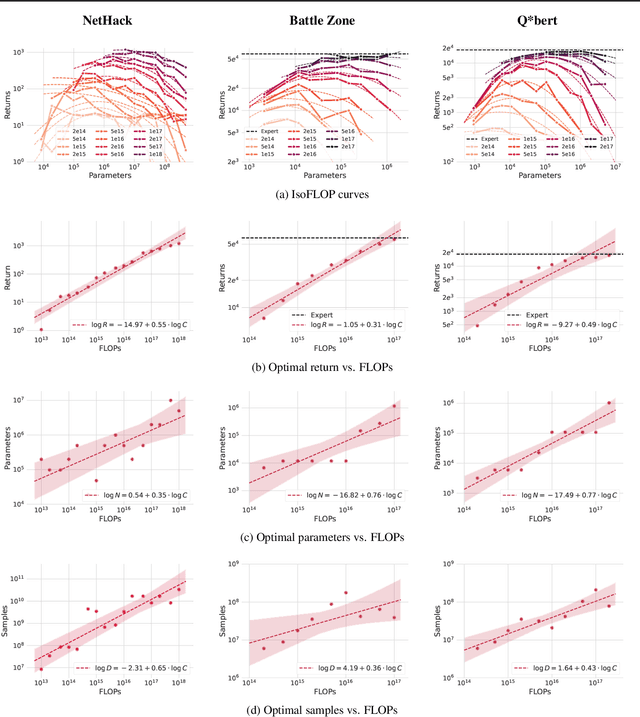
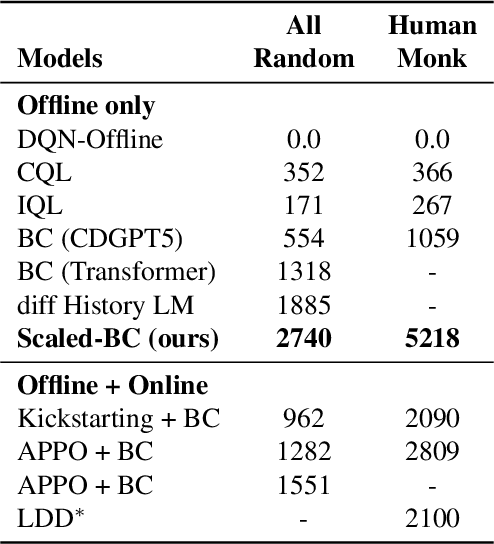
Imitation Learning (IL) is one of the most widely used methods in machine learning. Yet, while powerful, many works find it is often not able to fully recover the underlying expert behavior. However, none of these works deeply investigate the role of scaling up the model and data size. Inspired by recent work in Natural Language Processing (NLP) where "scaling up" has resulted in increasingly more capable LLMs, we investigate whether carefully scaling up model and data size can bring similar improvements in the imitation learning setting. To demonstrate our findings, we focus on the game of NetHack, a challenging environment featuring procedural generation, stochasticity, long-term dependencies, and partial observability. We find IL loss and mean return scale smoothly with the compute budget and are strongly correlated, resulting in power laws for training compute-optimal IL agents with respect to model size and number of samples. We forecast and train several NetHack agents with IL and find they outperform prior state-of-the-art by at least 2x in all settings. Our work both demonstrates the scaling behavior of imitation learning in a challenging domain, as well as the viability of scaling up current approaches for increasingly capable agents in NetHack, a game that remains elusively hard for current AI systems.
Linear Reinforcement Learning with Ball Structure Action Space
Nov 14, 2022We study the problem of Reinforcement Learning (RL) with linear function approximation, i.e. assuming the optimal action-value function is linear in a known $d$-dimensional feature mapping. Unfortunately, however, based on only this assumption, the worst case sample complexity has been shown to be exponential, even under a generative model. Instead of making further assumptions on the MDP or value functions, we assume that our action space is such that there always exist playable actions to explore any direction of the feature space. We formalize this assumption as a ``ball structure'' action space, and show that being able to freely explore the feature space allows for efficient RL. In particular, we propose a sample-efficient RL algorithm (BallRL) that learns an $\epsilon$-optimal policy using only $\tilde{O}\left(\frac{H^5d^3}{\epsilon^3}\right)$ number of trajectories.
Deep Inventory Management
Oct 06, 2022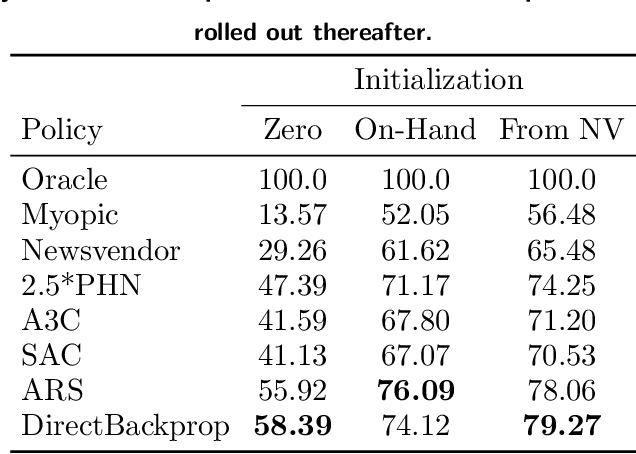
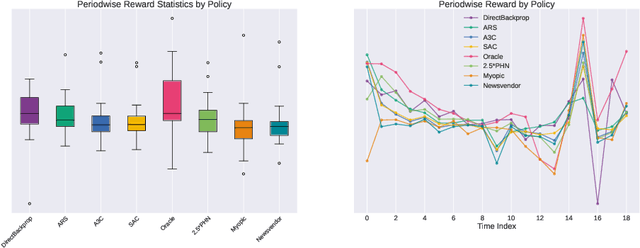
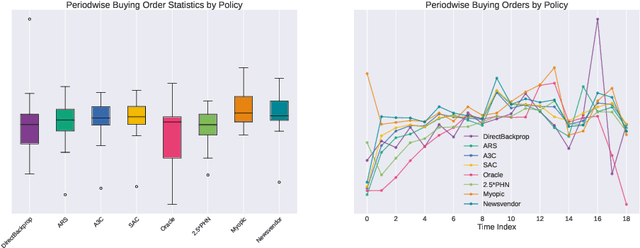

We present a Deep Reinforcement Learning approach to solving a periodic review inventory control system with stochastic vendor lead times, lost sales, correlated demand, and price matching. While this dynamic program has historically been considered intractable, we show that several policy learning approaches are competitive with or outperform classical baseline approaches. In order to train these algorithms, we develop novel techniques to convert historical data into a simulator. We also present a model-based reinforcement learning procedure (Direct Backprop) to solve the dynamic periodic review inventory control problem by constructing a differentiable simulator. Under a variety of metrics Direct Backprop outperforms model-free RL and newsvendor baselines, in both simulations and real-world deployments.
MQRetNN: Multi-Horizon Time Series Forecasting with Retrieval Augmentation
Jul 21, 2022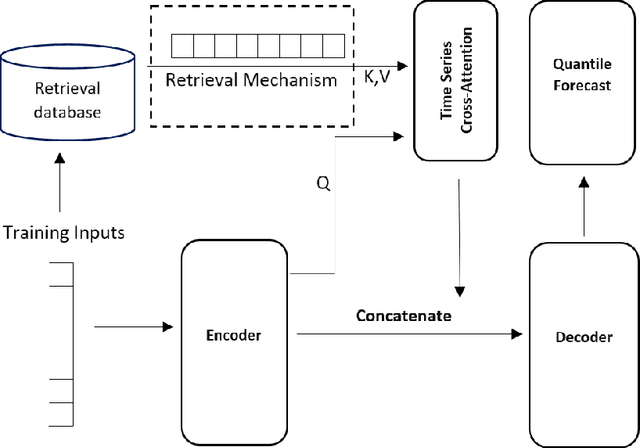
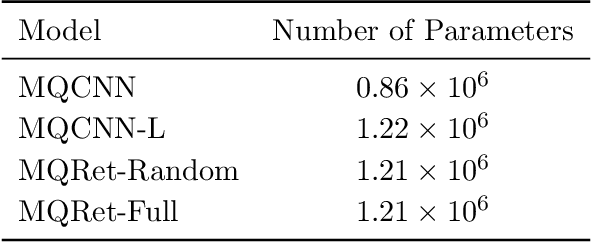
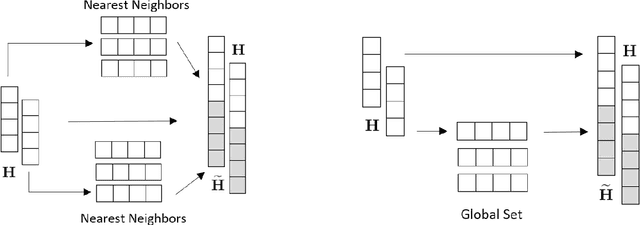
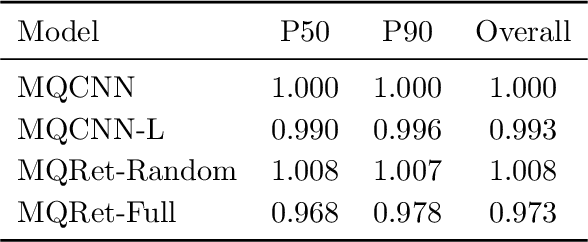
Multi-horizon probabilistic time series forecasting has wide applicability to real-world tasks such as demand forecasting. Recent work in neural time-series forecasting mainly focus on the use of Seq2Seq architectures. For example, MQTransformer - an improvement of MQCNN - has shown the state-of-the-art performance in probabilistic demand forecasting. In this paper, we consider incorporating cross-entity information to enhance model performance by adding a cross-entity attention mechanism along with a retrieval mechanism to select which entities to attend over. We demonstrate how our new neural architecture, MQRetNN, leverages the encoded contexts from a pretrained baseline model on the entire population to improve forecasting accuracy. Using MQCNN as the baseline model (due to computational constraints, we do not use MQTransformer), we first show on a small demand forecasting dataset that it is possible to achieve ~3% improvement in test loss by adding a cross-entity attention mechanism where each entity attends to all others in the population. We then evaluate the model with our proposed retrieval methods - as a means of approximating an attention over a large population - on a large-scale demand forecasting application with over 2 million products and observe ~1% performance gain over the MQCNN baseline.
A Few Expert Queries Suffices for Sample-Efficient RL with Resets and Linear Value Approximation
Jul 18, 2022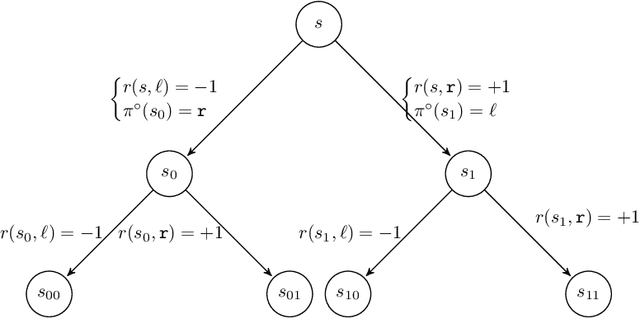
The current paper studies sample-efficient Reinforcement Learning (RL) in settings where only the optimal value function is assumed to be linearly-realizable. It has recently been understood that, even under this seemingly strong assumption and access to a generative model, worst-case sample complexities can be prohibitively (i.e., exponentially) large. We investigate the setting where the learner additionally has access to interactive demonstrations from an expert policy, and we present a statistically and computationally efficient algorithm (Delphi) for blending exploration with expert queries. In particular, Delphi requires $\tilde{\mathcal{O}}(d)$ expert queries and a $\texttt{poly}(d,H,|\mathcal{A}|,1/\varepsilon)$ amount of exploratory samples to provably recover an $\varepsilon$-suboptimal policy. Compared to pure RL approaches, this corresponds to an exponential improvement in sample complexity with surprisingly-little expert input. Compared to prior imitation learning (IL) approaches, our required number of expert demonstrations is independent of $H$ and logarithmic in $1/\varepsilon$, whereas all prior work required at least linear factors of both in addition to the same dependence on $d$. Towards establishing the minimal amount of expert queries needed, we show that, in the same setting, any learner whose exploration budget is polynomially-bounded (in terms of $d,H,$ and $|\mathcal{A}|$) will require at least $\tilde\Omega(\sqrt{d})$ oracle calls to recover a policy competing with the expert's value function. Under the weaker assumption that the expert's policy is linear, we show that the lower bound increases to $\tilde\Omega(d)$.
Assessment of Treatment Effect Estimators for Heavy-Tailed Data
Dec 19, 2021



A central obstacle in the objective assessment of treatment effect (TE) estimators in randomized control trials (RCTs) is the lack of ground truth (or validation set) to test their performance. In this paper, we provide a novel cross-validation-like methodology to address this challenge. The key insight of our procedure is that the noisy (but unbiased) difference-of-means estimate can be used as a ground truth "label" on a portion of the RCT, to test the performance of an estimator trained on the other portion. We combine this insight with an aggregation scheme, which borrows statistical strength across a large collection of RCTs, to present an end-to-end methodology for judging an estimator's ability to recover the underlying treatment effect. We evaluate our methodology across 709 RCTs implemented in the Amazon supply chain. In the corpus of AB tests at Amazon, we highlight the unique difficulties associated with recovering the treatment effect due to the heavy-tailed nature of the response variables. In this heavy-tailed setting, our methodology suggests that procedures that aggressively downweight or truncate large values, while introducing bias, lower the variance enough to ensure that the treatment effect is more accurately estimated.