 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Spatially-aware Fashion Concept Discovery
Aug 03, 2017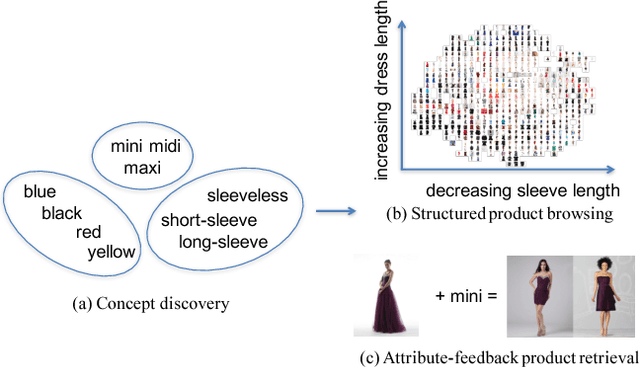
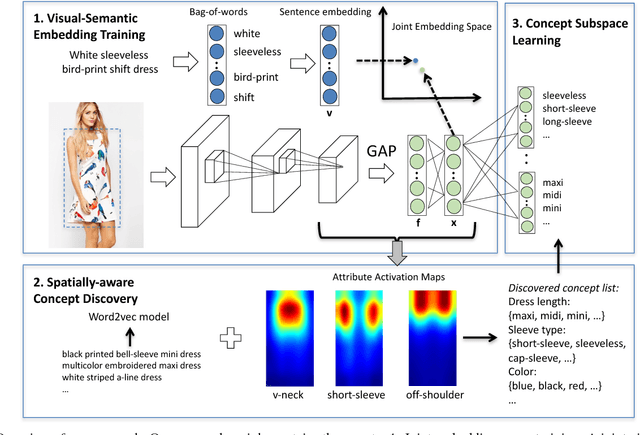


This paper proposes an automatic spatially-aware concept discovery approach using weakly labeled image-text data from shopping websites. We first fine-tune GoogleNet by jointly modeling clothing images and their corresponding descriptions in a visual-semantic embedding space. Then, for each attribute (word), we generate its spatially-aware representation by combining its semantic word vector representation with its spatial representation derived from the convolutional maps of the fine-tuned network. The resulting spatially-aware representations are further used to cluster attributes into multiple groups to form spatially-aware concepts (e.g., the neckline concept might consist of attributes like v-neck, round-neck, etc). Finally, we decompose the visual-semantic embedding space into multiple concept-specific subspaces, which facilitates structured browsing and attribute-feedback product retrieval by exploiting multimodal linguistic regularities. We conducted extensive experiments on our newly collected Fashion200K dataset, and results on clustering quality evaluation and attribute-feedback product retrieval task demonstrate the effectiveness of our automatically discovered spatially-aware concepts.
Speed/accuracy trade-offs for modern convolutional object detectors
Apr 25, 2017
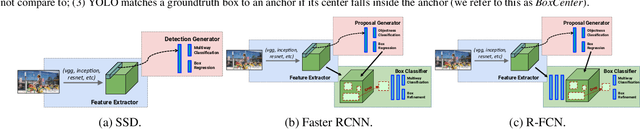

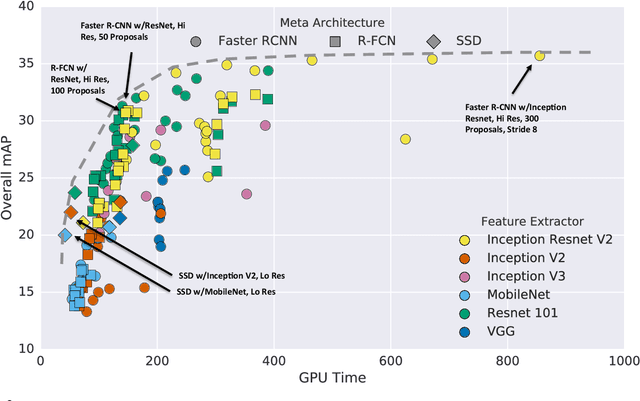
The goal of this paper is to serve as a guide for selecting a detection architecture that achieves the right speed/memory/accuracy balance for a given application and platform. To this end, we investigate various ways to trade accuracy for speed and memory usage in modern convolutional object detection systems. A number of successful systems have been proposed in recent years, but apples-to-apples comparisons are difficult due to different base feature extractors (e.g., VGG, Residual Networks), different default image resolutions, as well as different hardware and software platforms. We present a unified implementation of the Faster R-CNN [Ren et al., 2015], R-FCN [Dai et al., 2016] and SSD [Liu et al., 2015] systems, which we view as "meta-architectures" and trace out the speed/accuracy trade-off curve created by using alternative feature extractors and varying other critical parameters such as image size within each of these meta-architectures. On one extreme end of this spectrum where speed and memory are critical, we present a detector that achieves real time speeds and can be deployed on a mobile device. On the opposite end in which accuracy is critical, we present a detector that achieves state-of-the-art performance measured on the COCO detection task.
Sparse Representation for 3D Shape Estimation: A Convex Relaxation Approach
Jan 10, 2017
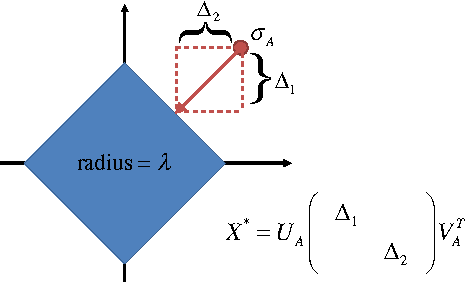
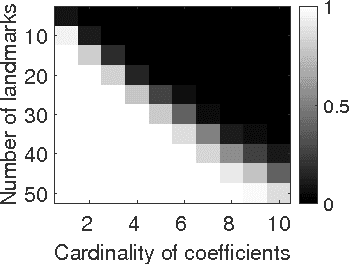
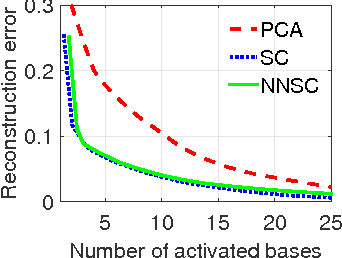
We investigate the problem of estimating the 3D shape of an object defined by a set of 3D landmarks, given their 2D correspondences in a single image. A successful approach to alleviating the reconstruction ambiguity is the 3D deformable shape model and a sparse representation is often used to capture complex shape variability. But the model inference is still a challenge due to the nonconvexity in optimization resulted from joint estimation of shape and viewpoint. In contrast to prior work that relies on a alternating scheme with solutions depending on initialization, we propose a convex approach to addressing this challenge and develop an efficient algorithm to solve the proposed convex program. Moreover, we propose a robust model to handle gross errors in the 2D correspondences. We demonstrate the exact recovery property of the proposed method, the advantage compared to the nonconvex baseline methods and the applicability to recover 3D human poses and car models from single images.
* Extended version of the paper: 3D Shape Estimation from 2D Landmarks: A Convex Relaxation Approach. X. Zhou et al., CVPR, 2015. arXiv admin note: substantial text overlap with arXiv:1411.2942
Sparseness Meets Deepness: 3D Human Pose Estimation from Monocular Video
Apr 28, 2016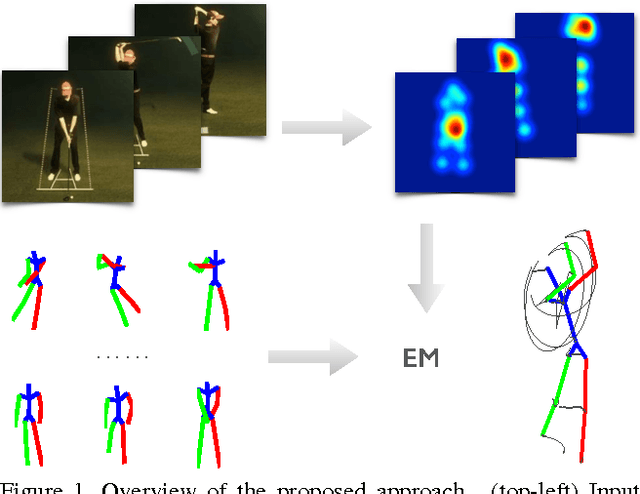

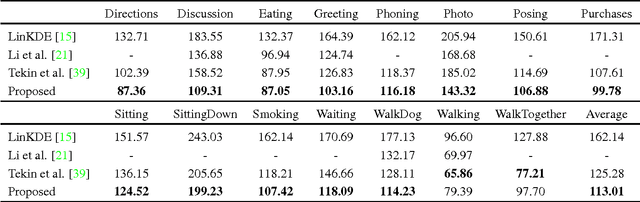
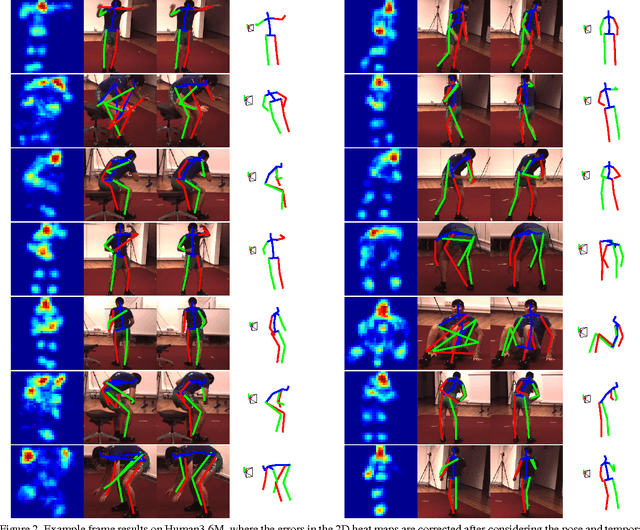
This paper addresses the challenge of 3D full-body human pose estimation from a monocular image sequence. Here, two cases are considered: (i) the image locations of the human joints are provided and (ii) the image locations of joints are unknown. In the former case, a novel approach is introduced that integrates a sparsity-driven 3D geometric prior and temporal smoothness. In the latter case, the former case is extended by treating the image locations of the joints as latent variables. A deep fully convolutional network is trained to predict the uncertainty maps of the 2D joint locations. The 3D pose estimates are realized via an Expectation-Maximization algorithm over the entire sequence, where it is shown that the 2D joint location uncertainties can be conveniently marginalized out during inference. Empirical evaluation on the Human3.6M dataset shows that the proposed approaches achieve greater 3D pose estimation accuracy over state-of-the-art baselines. Further, the proposed approach outperforms a publicly available 2D pose estimation baseline on the challenging PennAction dataset.
Multi-Image Matching via Fast Alternating Minimization
Dec 02, 2015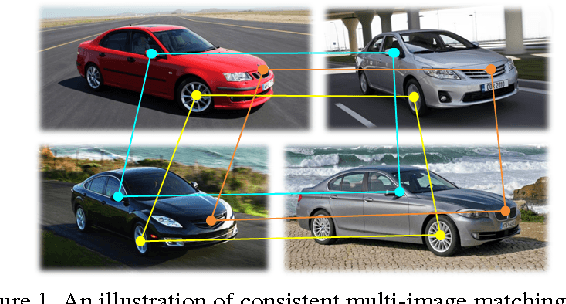
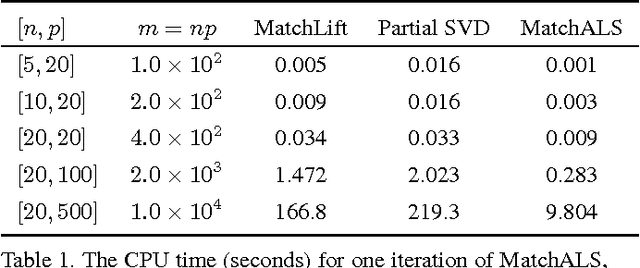
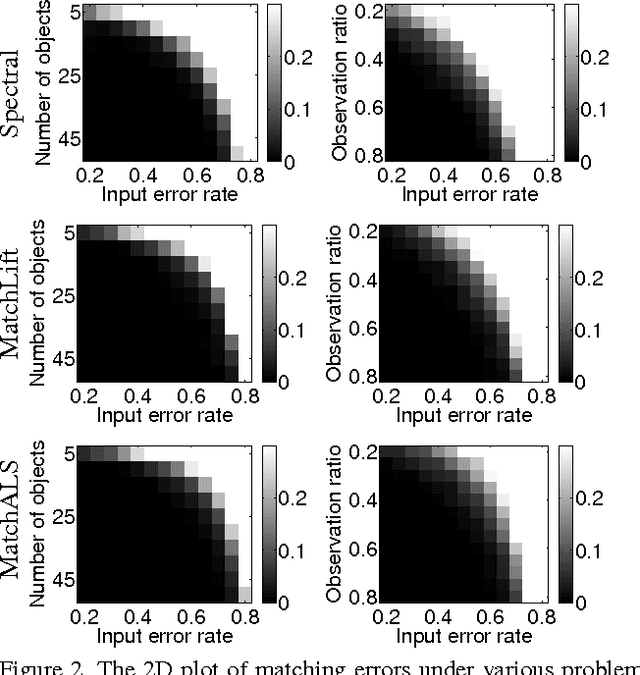
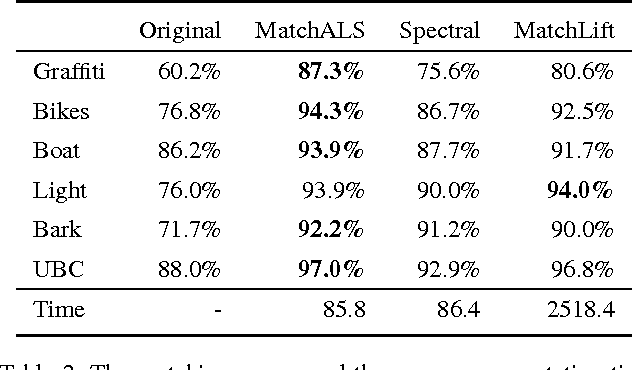
In this paper we propose a global optimization-based approach to jointly matching a set of images. The estimated correspondences simultaneously maximize pairwise feature affinities and cycle consistency across multiple images. Unlike previous convex methods relying on semidefinite programming, we formulate the problem as a low-rank matrix recovery problem and show that the desired semidefiniteness of a solution can be spontaneously fulfilled. The low-rank formulation enables us to derive a fast alternating minimization algorithm in order to handle practical problems with thousands of features. Both simulation and real experiments demonstrate that the proposed algorithm can achieve a competitive performance with an order of magnitude speedup compared to the state-of-the-art algorithm. In the end, we demonstrate the applicability of the proposed method to match the images of different object instances and as a result the potential to reconstruct category-specific object models from those images.
Pose and Shape Estimation with Discriminatively Learned Parts
Feb 01, 2015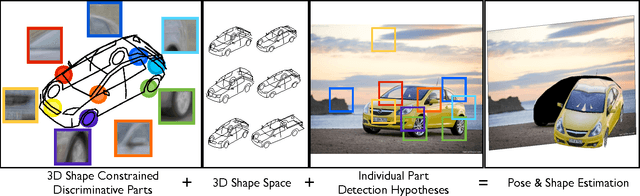

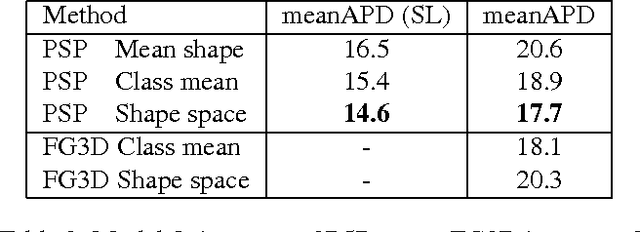
We introduce a new approach for estimating the 3D pose and the 3D shape of an object from a single image. Given a training set of view exemplars, we learn and select appearance-based discriminative parts which are mapped onto the 3D model from the training set through a facil- ity location optimization. The training set of 3D models is summarized into a sparse set of shapes from which we can generalize by linear combination. Given a test picture, we detect hypotheses for each part. The main challenge is to select from these hypotheses and compute the 3D pose and shape coefficients at the same time. To achieve this, we optimize a function that minimizes simultaneously the geometric reprojection error as well as the appearance matching of the parts. We apply the alternating direction method of multipliers (ADMM) to minimize the resulting convex function. We evaluate our approach on the Fine Grained 3D Car dataset with superior performance in shape and pose errors. Our main and novel contribution is the simultaneous solution for part localization, 3D pose and shape by maximizing both geometric and appearance compatibility.
Active Deformable Part Models
Apr 02, 2014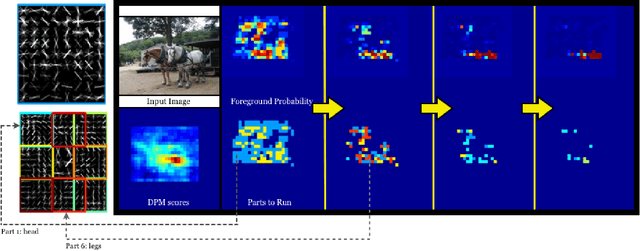

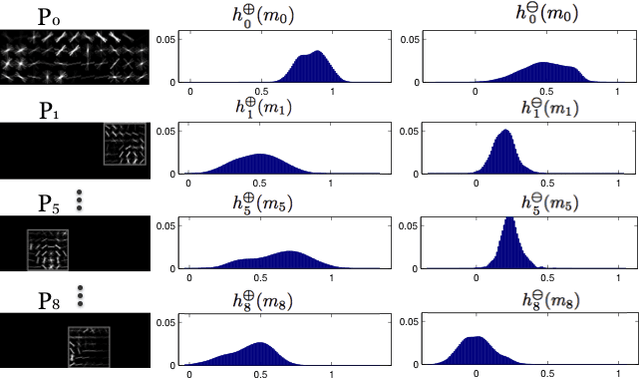
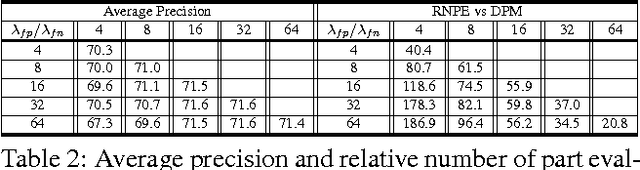
This paper presents an active approach for part-based object detection, which optimizes the order of part filter evaluations and the time at which to stop and make a prediction. Statistics, describing the part responses, are learned from training data and are used to formalize the part scheduling problem as an offline optimization. Dynamic programming is applied to obtain a policy, which balances the number of part evaluations with the classification accuracy. During inference, the policy is used as a look-up table to choose the part order and the stopping time based on the observed filter responses. The method is faster than cascade detection with deformable part models (which does not optimize the part order) with negligible loss in accuracy when evaluated on the PASCAL VOC 2007 and 2010 datasets.