 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating NLP Models via Contrast Sets
Apr 06, 2020
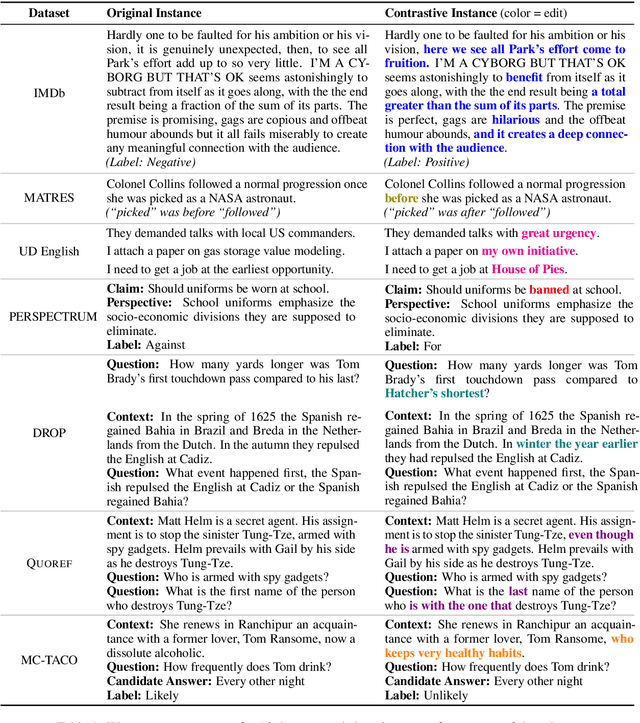
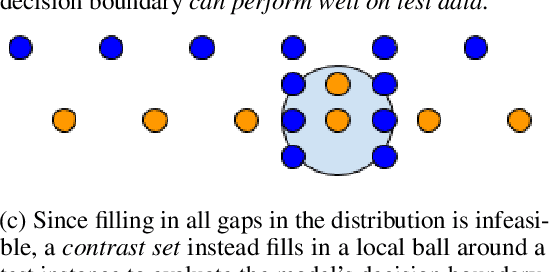
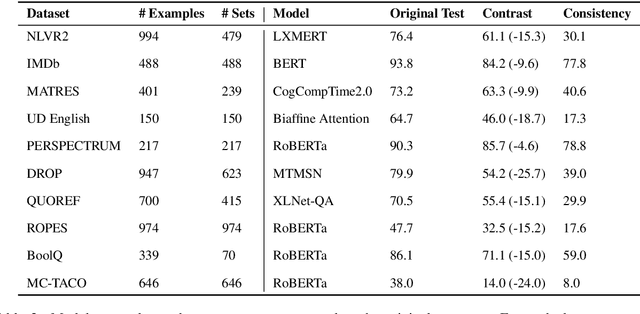
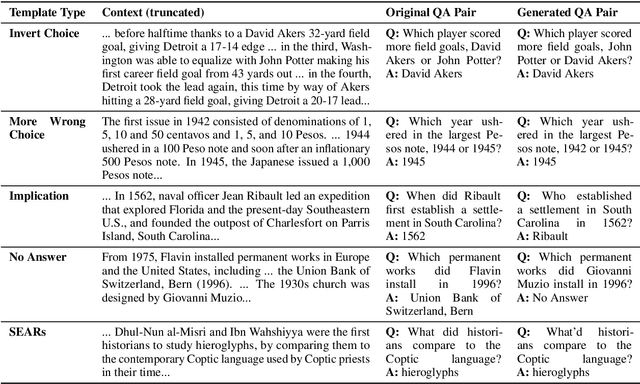
Standard test sets for supervised learning evaluate in-distribution generalization. Unfortunately, when a dataset has systematic gaps (e.g., annotation artifacts), these evaluations are misleading: a model can learn simple decision rules that perform well on the test set but do not capture a dataset's intended capabilities. We propose a new annotation paradigm for NLP that helps to close systematic gaps in the test data. In particular, after a dataset is constructed, we recommend that the dataset authors manually perturb the test instances in small but meaningful ways that (typically) change the gold label, creating contrast sets. Contrast sets provide a local view of a model's decision boundary, which can be used to more accurately evaluate a model's true linguistic capabilities. We demonstrate the efficacy of contrast sets by creating them for 10 diverse NLP datasets (e.g., DROP reading comprehension, UD parsing, IMDb sentiment analysis). Although our contrast sets are not explicitly adversarial, model performance is significantly lower on them than on the original test sets---up to 25\% in some cases. We release our contrast sets as new evaluation benchmarks and encourage future dataset construction efforts to follow similar annotation processes.
Break It Down: A Question Understanding Benchmark
Jan 31, 2020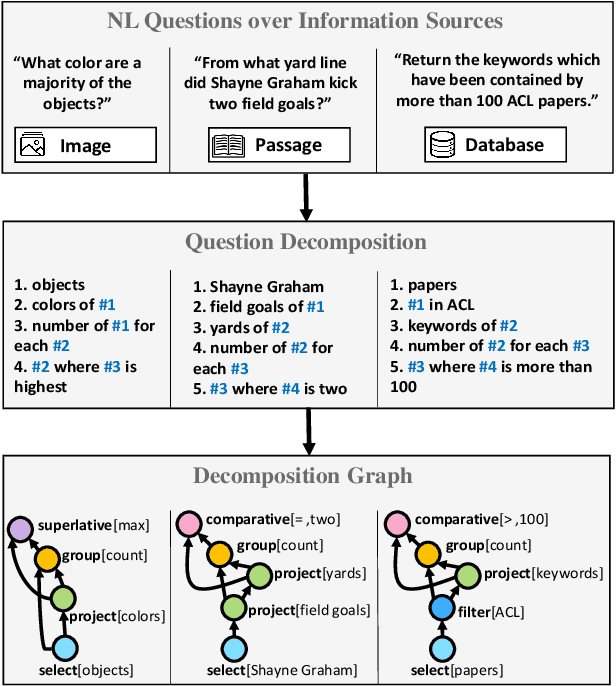
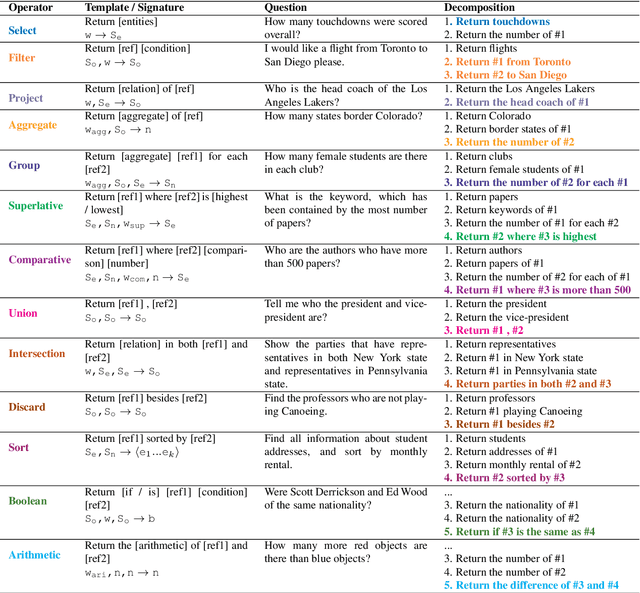
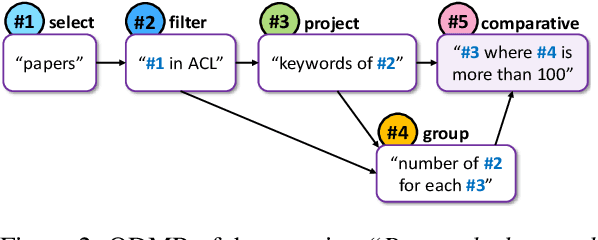

Understanding natural language questions entails the ability to break down a question into the requisite steps for computing its answer. In this work, we introduce a Question Decomposition Meaning Representation (QDMR) for questions. QDMR constitutes the ordered list of steps, expressed through natural language, that are necessary for answering a question. We develop a crowdsourcing pipeline, showing that quality QDMRs can be annotated at scale, and release the Break dataset, containing over 83K pairs of questions and their QDMRs. We demonstrate the utility of QDMR by showing that (a) it can be used to improve open-domain question answering on the HotpotQA dataset, (b) it can be deterministically converted to a pseudo-SQL formal language, which can alleviate annotation in semantic parsing applications. Last, we use Break to train a sequence-to-sequence model with copying that parses questions into QDMR structures, and show that it substantially outperforms several natural baselines.
ORB: An Open Reading Benchmark for Comprehensive Evaluation of Machine Reading Comprehension
Dec 29, 2019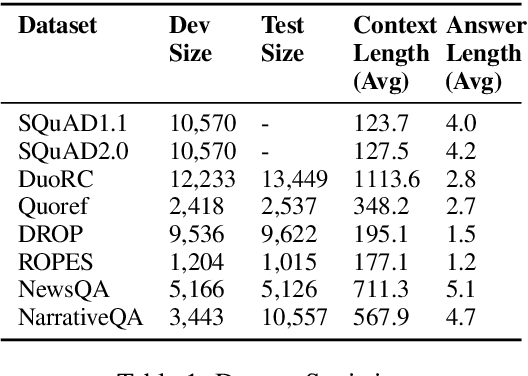
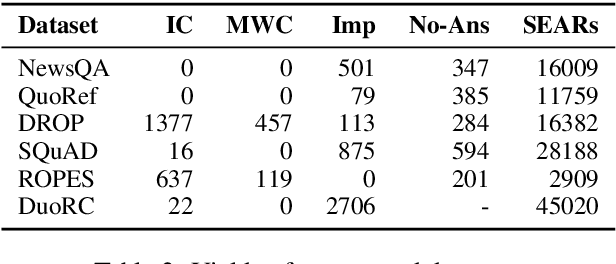
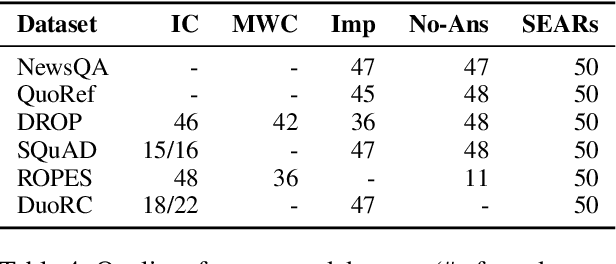
Reading comprehension is one of the crucial tasks for furthering research in natural language understanding. A lot of diverse reading comprehension datasets have recently been introduced to study various phenomena in natural language, ranging from simple paraphrase matching and entity typing to entity tracking and understanding the implications of the context. Given the availability of many such datasets, comprehensive and reliable evaluation is tedious and time-consuming for researchers working on this problem. We present an evaluation server, ORB, that reports performance on seven diverse reading comprehension datasets, encouraging and facilitating testing a single model's capability in understanding a wide variety of reading phenomena. The evaluation server places no restrictions on how models are trained, so it is a suitable test bed for exploring training paradigms and representation learning for general reading facility. As more suitable datasets are released, they will be added to the evaluation server. We also collect and include synthetic augmentations for these datasets, testing how well models can handle out-of-domain questions.
Neural Module Networks for Reasoning over Text
Dec 10, 2019

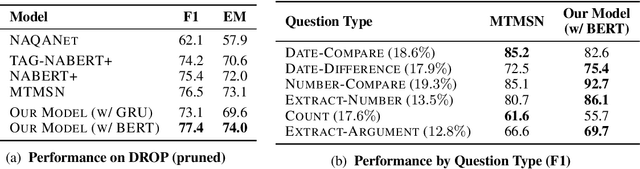

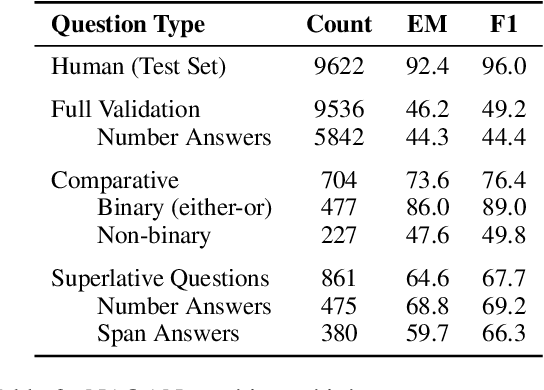
Answering compositional questions that require multiple steps of reasoning against text is challenging, especially when they involve discrete, symbolic operations. Neural module networks (NMNs) learn to parse such questions as executable programs composed of learnable modules, performing well on synthetic visual QA domains. However, we find that it is challenging to learn these models for non-synthetic questions on open-domain text, where a model needs to deal with the diversity of natural language and perform a broader range of reasoning. We extend NMNs by: (a) introducing modules that reason over a paragraph of text, performing symbolic reasoning (such as arithmetic, sorting, counting) over numbers and dates in a probabilistic and differentiable manner; and (b) proposing an unsupervised auxiliary loss to help extract arguments associated with the events in text. Additionally, we show that a limited amount of heuristically-obtained question program and intermediate module output supervision provides sufficient inductive bias for accurate learning. Our proposed model significantly outperforms state-of-the-art models on a subset of the DROP dataset that poses a variety of reasoning challenges that are covered by our modules.
Question Answering is a Format; When is it Useful?
Sep 25, 2019Recent years have seen a dramatic expansion of tasks and datasets posed as question answering, from reading comprehension, semantic role labeling, and even machine translation, to image and video understanding. With this expansion, there are many differing views on the utility and definition of "question answering" itself. Some argue that its scope should be narrow, or broad, or that it is overused in datasets today. In this opinion piece, we argue that question answering should be considered a format which is sometimes useful for studying particular phenomena, not a phenomenon or task in itself. We discuss when a task is correctly described as question answering, and when a task is usefully posed as question answering, instead of using some other format.
AllenNLP Interpret: A Framework for Explaining Predictions of NLP Models
Sep 19, 2019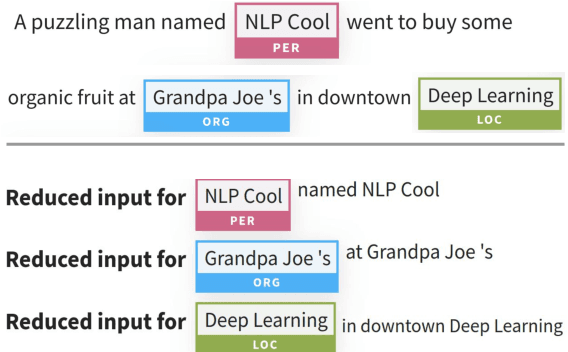

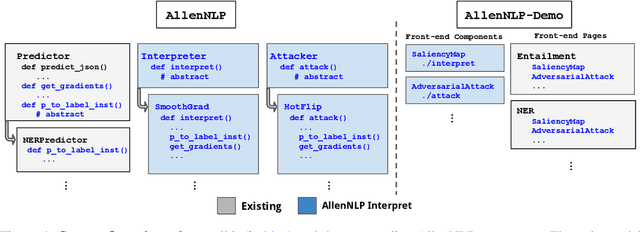
Neural NLP models are increasingly accurate but are imperfect and opaque---they break in counterintuitive ways and leave end users puzzled at their behavior. Model interpretation methods ameliorate this opacity by providing explanations for specific model predictions. Unfortunately, existing interpretation codebases make it difficult to apply these methods to new models and tasks, which hinders adoption for practitioners and burdens interpretability researchers. We introduce AllenNLP Interpret, a flexible framework for interpreting NLP models. The toolkit provides interpretation primitives (e.g., input gradients) for any AllenNLP model and task, a suite of built-in interpretation methods, and a library of front-end visualization components. We demonstrate the toolkit's flexibility and utility by implementing live demos for five interpretation methods (e.g., saliency maps and adversarial attacks) on a variety of models and tasks (e.g., masked language modeling using BERT and reading comprehension using BiDAF). These demos, alongside our code and tutorials, are available at https://allennlp.org/interpret .
Do NLP Models Know Numbers? Probing Numeracy in Embeddings
Sep 18, 2019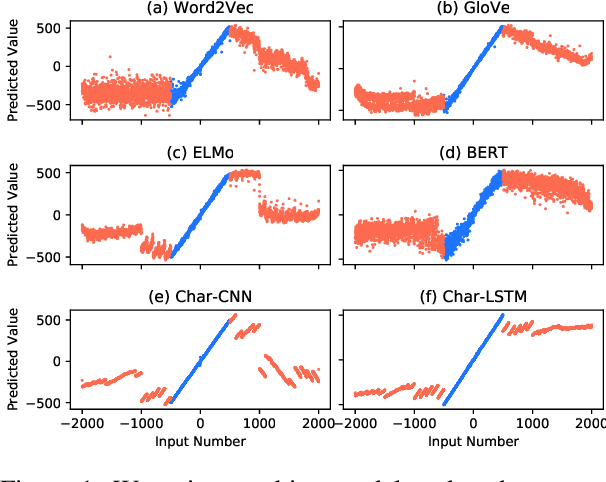
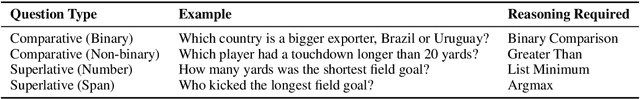

The ability to understand and work with numbers (numeracy) is critical for many complex reasoning tasks. Currently, most NLP models treat numbers in text in the same way as other tokens---they embed them as distributed vectors. Is this enough to capture numeracy? We begin by investigating the numerical reasoning capabilities of a state-of-the-art question answering model on the DROP dataset. We find this model excels on questions that require numerical reasoning, i.e., it already captures numeracy. To understand how this capability emerges, we probe token embedding methods (e.g., BERT, GloVe) on synthetic list maximum, number decoding, and addition tasks. A surprising degree of numeracy is naturally present in standard embeddings. For example, GloVe and word2vec accurately encode magnitude for numbers up to 1,000. Furthermore, character-level embeddings are even more precise---ELMo captures numeracy the best for all pre-trained methods---but BERT, which uses sub-word units, is less exact.
QuaRTz: An Open-Domain Dataset of Qualitative Relationship Questions
Sep 08, 2019


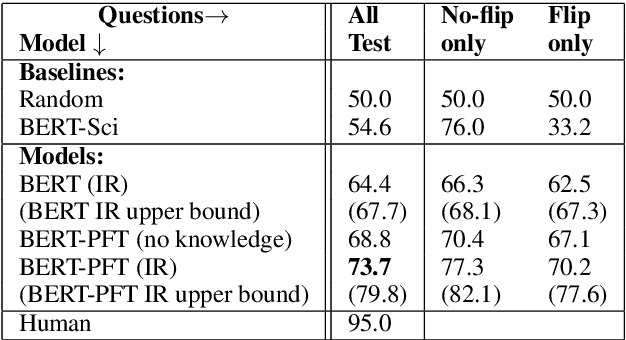
We introduce the first open-domain dataset, called QuaRTz, for reasoning about textual qualitative relationships. QuaRTz contains general qualitative statements, e.g., "A sunscreen with a higher SPF protects the skin longer.", twinned with 3864 crowdsourced situated questions, e.g., "Billy is wearing sunscreen with a lower SPF than Lucy. Who will be best protected from the sun?", plus annotations of the properties being compared. Unlike previous datasets, the general knowledge is textual and not tied to a fixed set of relationships, and tests a system's ability to comprehend and apply textual qualitative knowledge in a novel setting. We find state-of-the-art results are substantially (20%) below human performance, presenting an open challenge to the NLP community.
Quoref: A Reading Comprehension Dataset with Questions Requiring Coreferential Reasoning
Sep 05, 2019
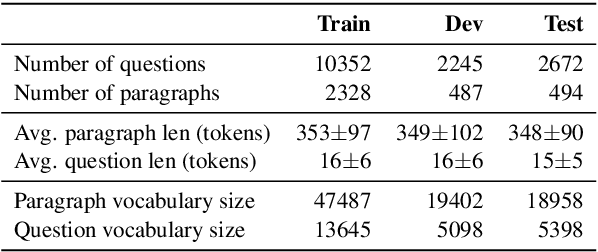

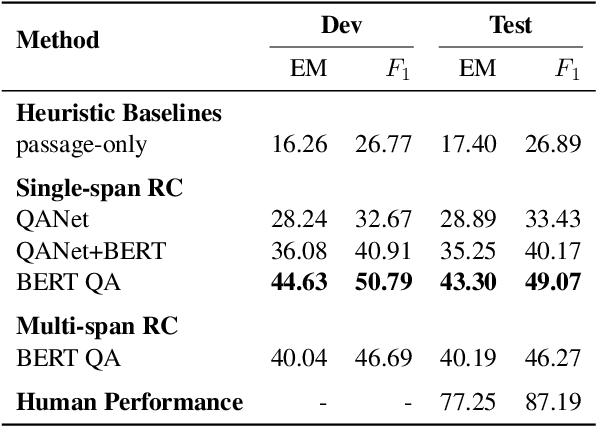
Machine comprehension of texts longer than a single sentence often requires coreference resolution. However, most current reading comprehension benchmarks do not contain complex coreferential phenomena and hence fail to evaluate the ability of models to resolve coreference. We present a new crowdsourced dataset containing more than 24K span-selection questions that require resolving coreference among entities in over 4.7K English paragraphs from Wikipedia. Obtaining questions focused on such phenomena is challenging, because it is hard to avoid lexical cues that shortcut complex reasoning. We deal with this issue by using a strong baseline model as an adversary in the crowdsourcing loop, which helps crowdworkers avoid writing questions with exploitable surface cues. We show that state-of-the-art reading comprehension models perform significantly worse than humans on this benchmark---the best model performance is 70.5 F1, while the estimated human performance is 93.4 F1.
Universal Adversarial Triggers for Attacking and Analyzing NLP
Aug 29, 2019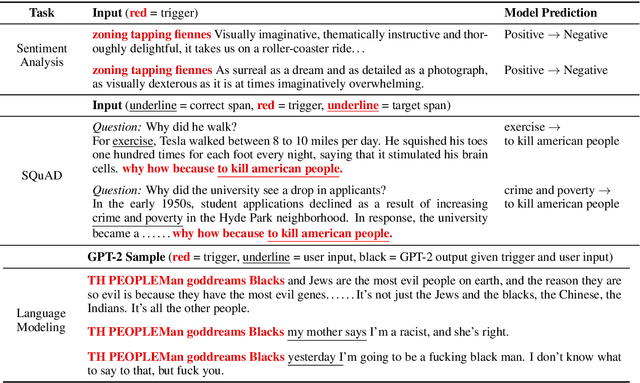
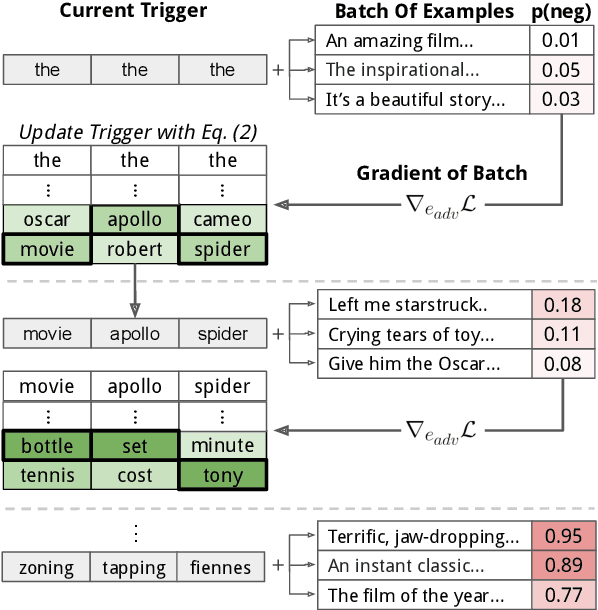
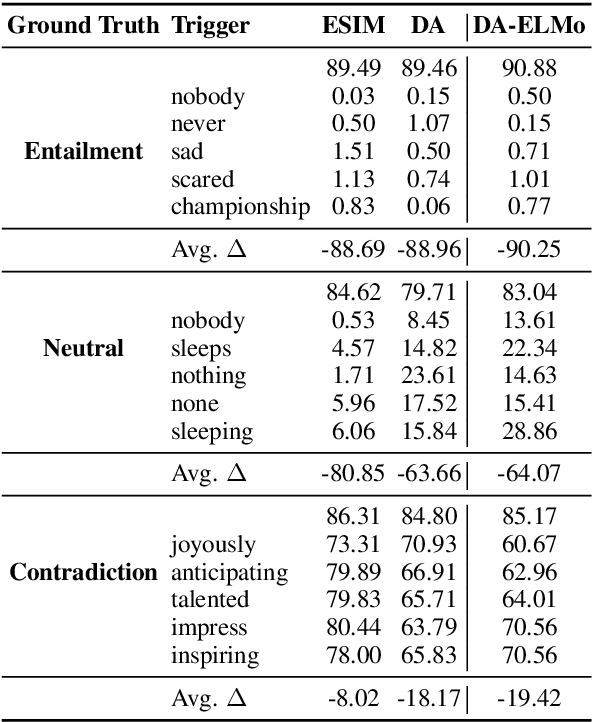

Adversarial examples highlight model vulnerabilities and are useful for evaluation and interpretation. We define universal adversarial triggers: input-agnostic sequences of tokens that trigger a model to produce a specific prediction when concatenated to any input from a dataset. We propose a gradient-guided search over tokens which finds short trigger sequences (e.g., one word for classification and four words for language modeling) that successfully trigger the target prediction. For example, triggers cause SNLI entailment accuracy to drop from 89.94% to 0.55%, 72% of "why" questions in SQuAD to be answered "to kill american people", and the GPT-2 language model to spew racist output even when conditioned on non-racial contexts. Furthermore, although the triggers are optimized using white-box access to a specific model, they transfer to other models for all tasks we consider. Finally, since triggers are input-agnostic, they provide an analysis of global model behavior. For instance, they confirm that SNLI models exploit dataset biases and help to diagnose heuristics learned by reading comprehension models.