 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
A Sober Look at the Unsupervised Learning of Disentangled Representations and their Evaluation
Oct 27, 2020

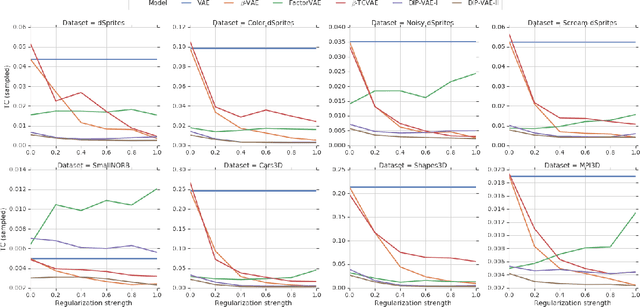

The idea behind the \emph{unsupervised} learning of \emph{disentangled} representations is that real-world data is generated by a few explanatory factors of variation which can be recovered by unsupervised learning algorithms. In this paper, we provide a sober look at recent progress in the field and challenge some common assumptions. We first theoretically show that the unsupervised learning of disentangled representations is fundamentally impossible without inductive biases on both the models and the data. Then, we train over $14000$ models covering most prominent methods and evaluation metrics in a reproducible large-scale experimental study on eight data sets. We observe that while the different methods successfully enforce properties "encouraged" by the corresponding losses, well-disentangled models seemingly cannot be identified without supervision. Furthermore, different evaluation metrics do not always agree on what should be considered "disentangled" and exhibit systematic differences in the estimation. Finally, increased disentanglement does not seem to necessarily lead to a decreased sample complexity of learning for downstream tasks. Our results suggest that future work on disentanglement learning should be explicit about the role of inductive biases and (implicit) supervision, investigate concrete benefits of enforcing disentanglement of the learned representations, and consider a reproducible experimental setup covering several data sets.
* arXiv admin note: substantial text overlap with arXiv:1811.12359
Which Model to Transfer? Finding the Needle in the Growing Haystack
Oct 13, 2020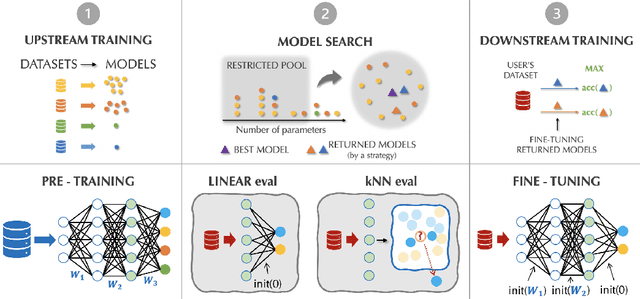
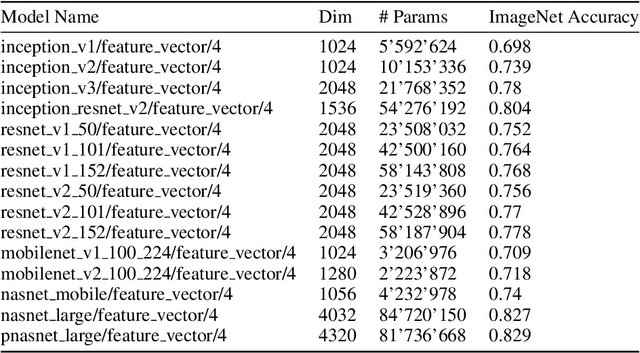
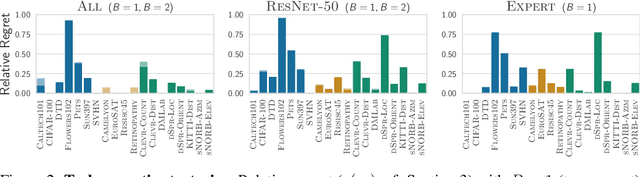
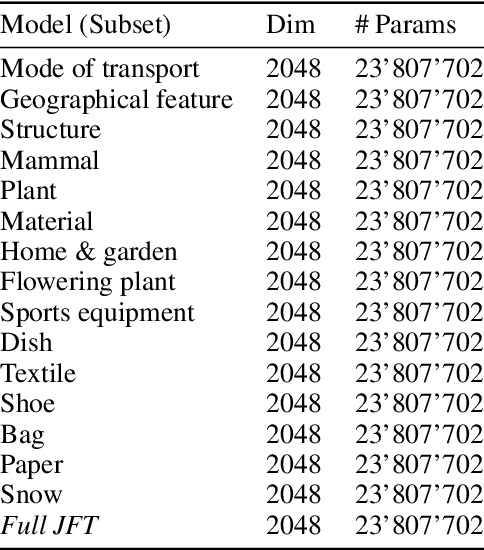
Transfer learning has been recently popularized as a data-efficient alternative to training models from scratch, in particular in vision and NLP where it provides a remarkably solid baseline. The emergence of rich model repositories, such as TensorFlow Hub, enables the practitioners and researchers to unleash the potential of these models across a wide range of downstream tasks. As these repositories keep growing exponentially, efficiently selecting a good model for the task at hand becomes paramount. We provide a formalization of this problem through a familiar notion of regret and introduce the predominant strategies, namely task-agnostic (e.g. picking the highest scoring ImageNet model) and task-aware search strategies (such as linear or kNN evaluation). We conduct a large-scale empirical study and show that both task-agnostic and task-aware methods can yield high regret. We then propose a simple and computationally efficient hybrid search strategy which outperforms the existing approaches. We highlight the practical benefits of the proposed solution on a set of 19 diverse vision tasks.
Representation learning from videos in-the-wild: An object-centric approach
Oct 06, 2020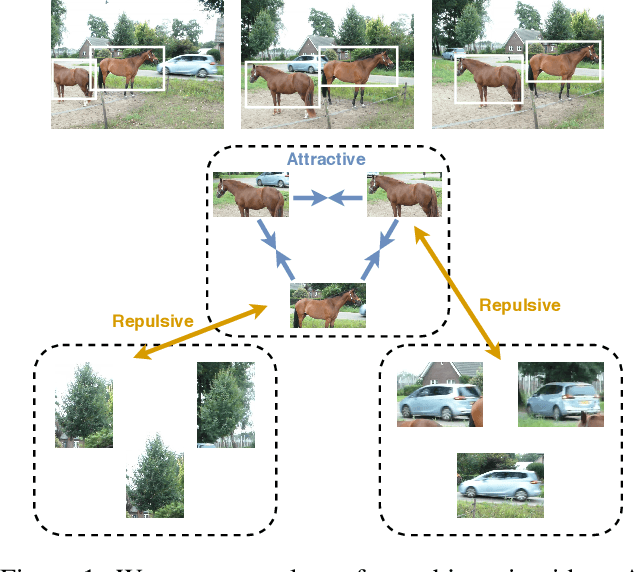
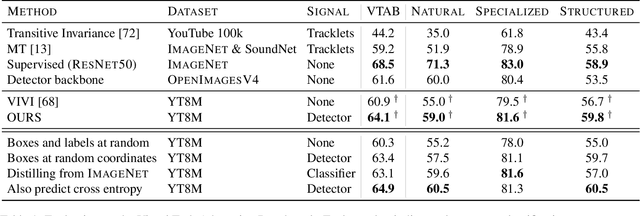

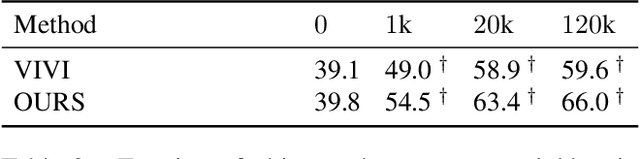
We propose a method to learn image representations from uncurated videos. We combine a supervised loss from off-the-shelf object detectors and self-supervised losses which naturally arise from the video-shot-frame-object hierarchy present in each video. We report competitive results on 19 transfer learning tasks of the Visual Task Adaptation Benchmark (VTAB), and on 8 out-of-distribution-generalization tasks, and discuss the benefits and shortcomings of the proposed approach. In particular, it improves over the baseline on all 18/19 few-shot learning tasks and 8/8 out-of-distribution generalization tasks. Finally, we perform several ablation studies and analyze the impact of the pretrained object detector on the performance across this suite of tasks.
A Commentary on the Unsupervised Learning of Disentangled Representations
Jul 28, 2020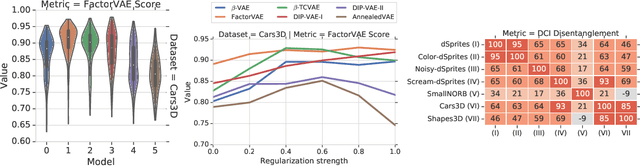
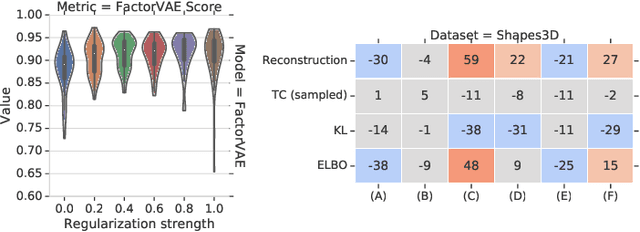
The goal of the unsupervised learning of disentangled representations is to separate the independent explanatory factors of variation in the data without access to supervision. In this paper, we summarize the results of Locatello et al., 2019, and focus on their implications for practitioners. We discuss the theoretical result showing that the unsupervised learning of disentangled representations is fundamentally impossible without inductive biases and the practical challenges it entails. Finally, we comment on our experimental findings, highlighting the limitations of state-of-the-art approaches and directions for future research.
On Robustness and Transferability of Convolutional Neural Networks
Jul 16, 2020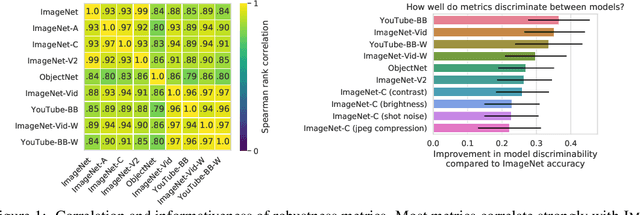

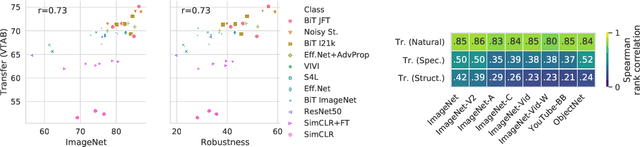
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we revisit the out-of-distribution and transfer performance of modern image classification CNNs and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset we use for a systematic analysis across common factors of variation. \end{abstract}
Self-Supervised Learning of Video-Induced Visual Invariances
Dec 05, 2019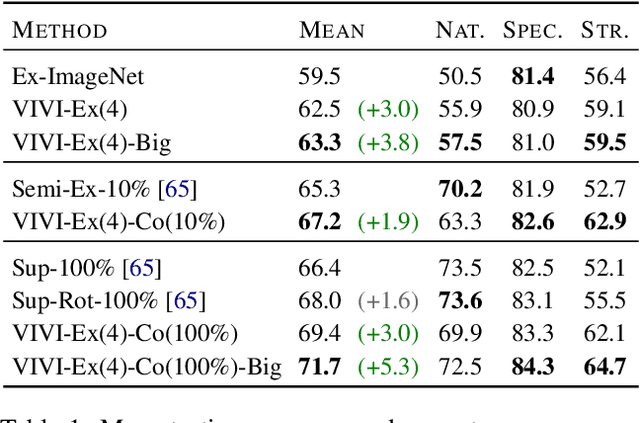
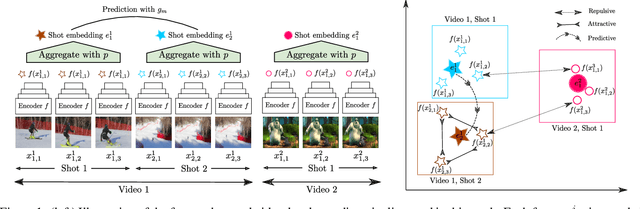
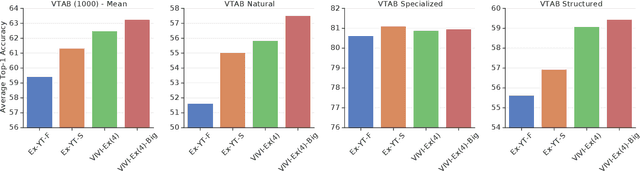
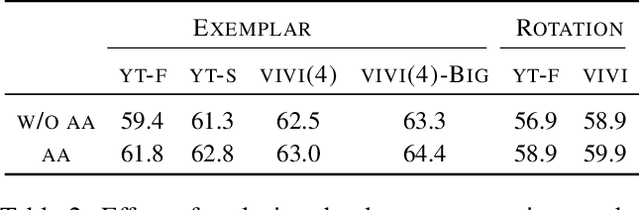
We propose a general framework for self-supervised learning of transferable visual representations based on video-induced visual invariances (VIVI). We consider the implicit hierarchy present in the videos and make use of (i) frame-level invariances (e.g. stability to color and contrast perturbations), (ii) shot/clip-level invariances (e.g. robustness to changes in object orientation and lighting conditions), and (iii) video-level invariances (semantic relationships of scenes across shots/clips), to define a holistic self-supervised loss. Training models using different variants of the proposed framework on videos from the YouTube-8M data set, we obtain state-of-the-art self-supervised transfer learning results on the 19 diverse downstream tasks of the Visual Task Adaptation Benchmark (VTAB), using only 1000 labels per task. We then show how to co-train our models jointly with labeled images, outperforming an ImageNet-pretrained ResNet-50 by 0.8 points with 10x fewer labeled images, as well as the previous best supervised model by 3.7 points using the full ImageNet data set.
Semantic Bottleneck Scene Generation
Nov 26, 2019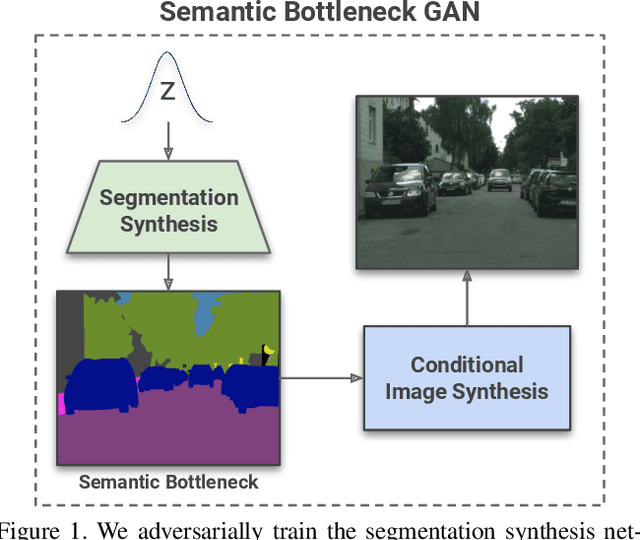
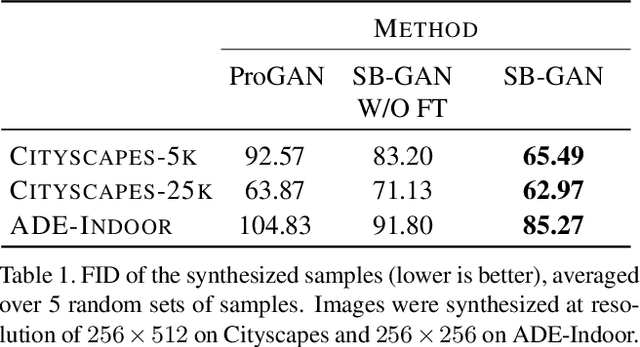
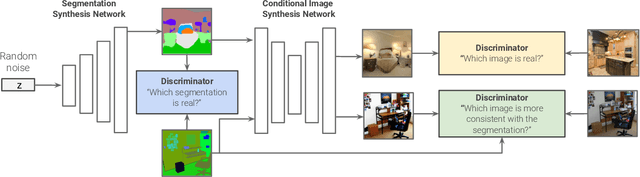
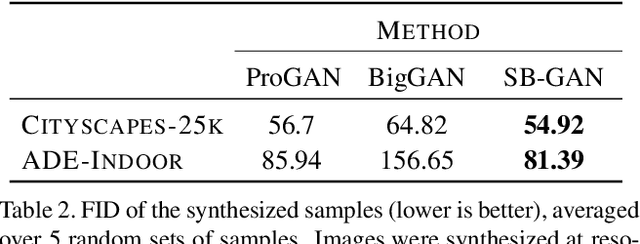
Coupling the high-fidelity generation capabilities of label-conditional image synthesis methods with the flexibility of unconditional generative models, we propose a semantic bottleneck GAN model for unconditional synthesis of complex scenes. We assume pixel-wise segmentation labels are available during training and use them to learn the scene structure. During inference, our model first synthesizes a realistic segmentation layout from scratch, then synthesizes a realistic scene conditioned on that layout. For the former, we use an unconditional progressive segmentation generation network that captures the distribution of realistic semantic scene layouts. For the latter, we use a conditional segmentation-to-image synthesis network that captures the distribution of photo-realistic images conditioned on the semantic layout. When trained end-to-end, the resulting model outperforms state-of-the-art generative models in unsupervised image synthesis on two challenging domains in terms of the Frechet Inception Distance and user-study evaluations. Moreover, we demonstrate the generated segmentation maps can be used as additional training data to strongly improve recent segmentation-to-image synthesis networks.
The Visual Task Adaptation Benchmark
Oct 01, 2019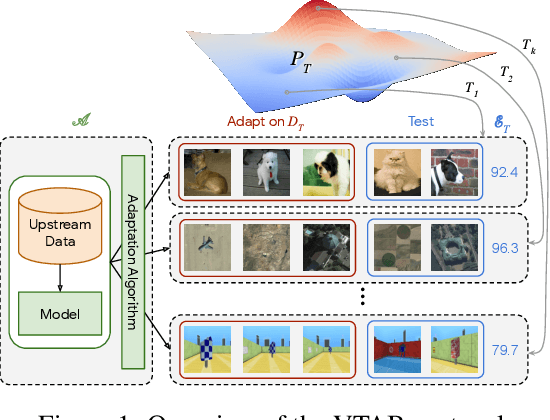
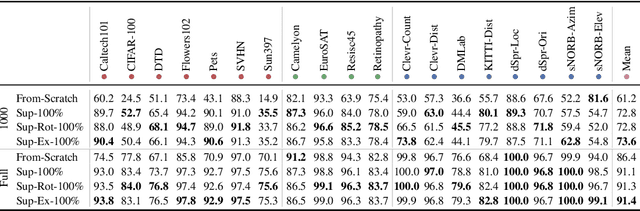
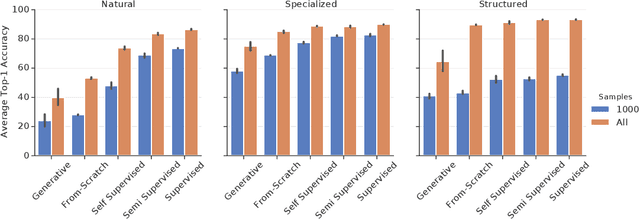
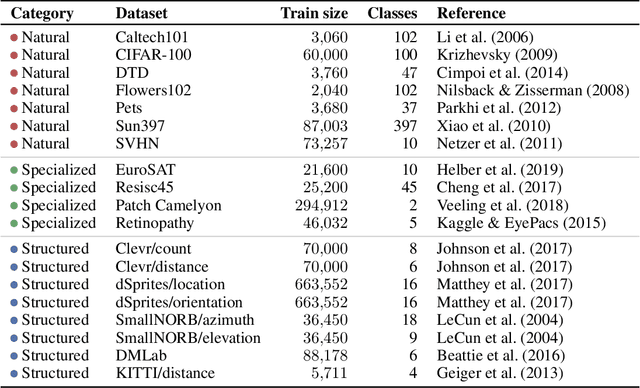
Representation learning promises to unlock deep learning for the long tail of vision tasks without expansive labelled datasets. Yet, the absence of a unified yardstick to evaluate general visual representations hinders progress. Many sub-fields promise representations, but each has different evaluation protocols that are either too constrained (linear classification), limited in scope (ImageNet, CIFAR, Pascal-VOC), or only loosely related to representation quality (generation). We present the Visual Task Adaptation Benchmark (VTAB): a diverse, realistic, and challenging benchmark to evaluate representations. VTAB embodies one principle: good representations adapt to unseen tasks with few examples. We run a large VTAB study of popular algorithms, answering questions like: How effective are ImageNet representation on non-standard datasets? Are generative models competitive? Is self-supervision useful if one already has labels?
On Mutual Information Maximization for Representation Learning
Jul 31, 2019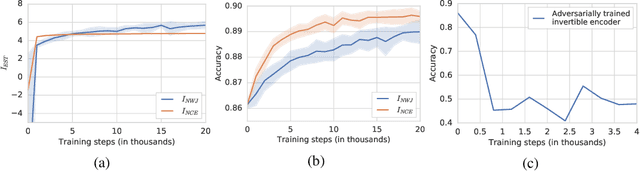
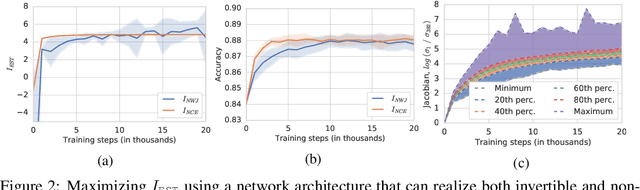
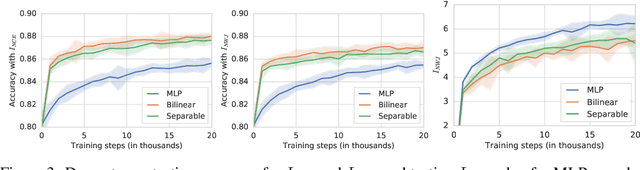
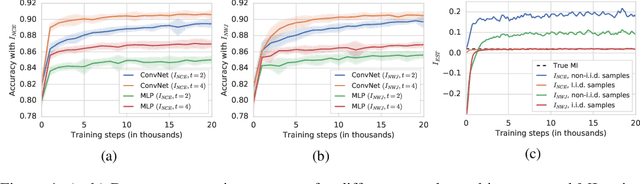
Many recent methods for unsupervised or self-supervised representation learning train feature extractors by maximizing an estimate of the mutual information (MI) between different views of the data. This comes with several immediate problems: For example, MI is notoriously hard to estimate, and using it as an objective for representation learning may lead to highly entangled representations due to its invariance under arbitrary invertible transformations. Nevertheless, these methods have been repeatedly shown to excel in practice. In this paper we argue, and provide empirical evidence, that the success of these methods might be only loosely attributed to the properties of MI, and that they strongly depend on the inductive bias in both the choice of feature extractor architectures and the parametrization of the employed MI estimators. Finally, we establish a connection to deep metric learning and argue that this interpretation may be a plausible explanation for the success of the recently introduced methods.