 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from many trajectories
Mar 31, 2022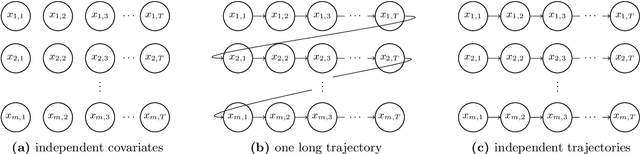
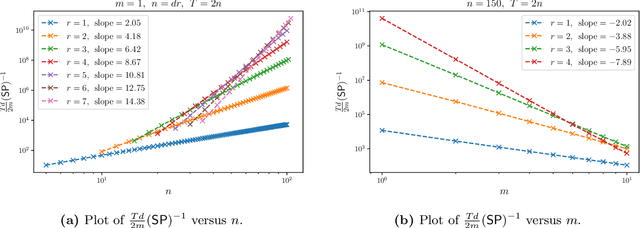
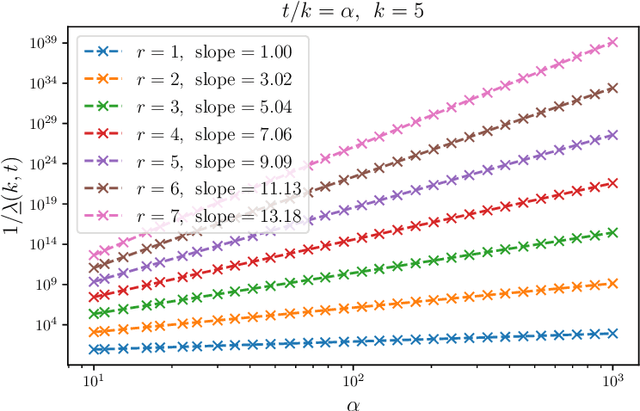
We initiate a study of supervised learning from many independent sequences ("trajectories") of non-independent covariates, reflecting tasks in sequence modeling, control, and reinforcement learning. Conceptually, our multi-trajectory setup sits between two traditional settings in statistical learning theory: learning from independent examples and learning from a single auto-correlated sequence. Our conditions for efficient learning generalize the former setting--trajectories must be non-degenerate in ways that extend standard requirements for independent examples. They do not require that trajectories be ergodic, long, nor strictly stable. For linear least-squares regression, given $n$-dimensional examples produced by $m$ trajectories, each of length $T$, we observe a notable change in statistical efficiency as the number of trajectories increases from a few (namely $m \lesssim n$) to many (namely $m \gtrsim n$). Specifically, we establish that the worst-case error rate this problem is $\Theta(n / m T)$ whenever $m \gtrsim n$. Meanwhile, when $m \lesssim n$, we establish a (sharp) lower bound of $\Omega(n^2 / m^2 T)$ on the worst-case error rate, realized by a simple, marginally unstable linear dynamical system. A key upshot is that, in domains where trajectories regularly reset, the error rate eventually behaves as if all of the examples were independent altogether, drawn from their marginals. As a corollary of our analysis, we also improve guarantees for the linear system identification problem.
HUMUS-Net: Hybrid unrolled multi-scale network architecture for accelerated MRI reconstruction
Mar 15, 2022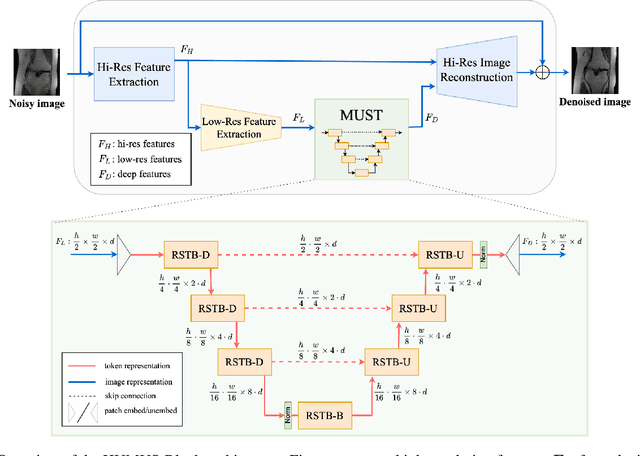

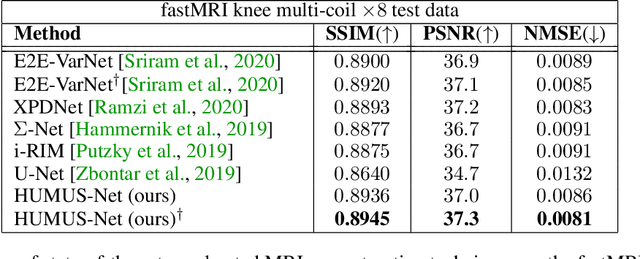
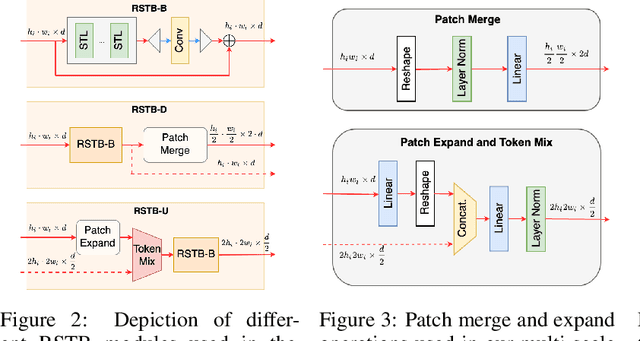
In accelerated MRI reconstruction, the anatomy of a patient is recovered from a set of under-sampled and noisy measurements. Deep learning approaches have been proven to be successful in solving this ill-posed inverse problem and are capable of producing very high quality reconstructions. However, current architectures heavily rely on convolutions, that are content-independent and have difficulties modeling long-range dependencies in images. Recently, Transformers, the workhorse of contemporary natural language processing, have emerged as powerful building blocks for a multitude of vision tasks. These models split input images into non-overlapping patches, embed the patches into lower-dimensional tokens and utilize a self-attention mechanism that does not suffer from the aforementioned weaknesses of convolutional architectures. However, Transformers incur extremely high compute and memory cost when 1) the input image resolution is high and 2) when the image needs to be split into a large number of patches to preserve fine detail information, both of which are typical in low-level vision problems such as MRI reconstruction, having a compounding effect. To tackle these challenges, we propose HUMUS-Net, a hybrid architecture that combines the beneficial implicit bias and efficiency of convolutions with the power of Transformer blocks in an unrolled and multi-scale network. HUMUS-Net extracts high-resolution features via convolutional blocks and refines low-resolution features via a novel Transformer-based multi-scale feature extractor. Features from both levels are then synthesized into a high-resolution output reconstruction. Our network establishes new state of the art on the largest publicly available MRI dataset, the fastMRI dataset. We further demonstrate the performance of HUMUS-Net on two other popular MRI datasets and perform fine-grained ablation studies to validate our design.
FedCV: A Federated Learning Framework for Diverse Computer Vision Tasks
Nov 22, 2021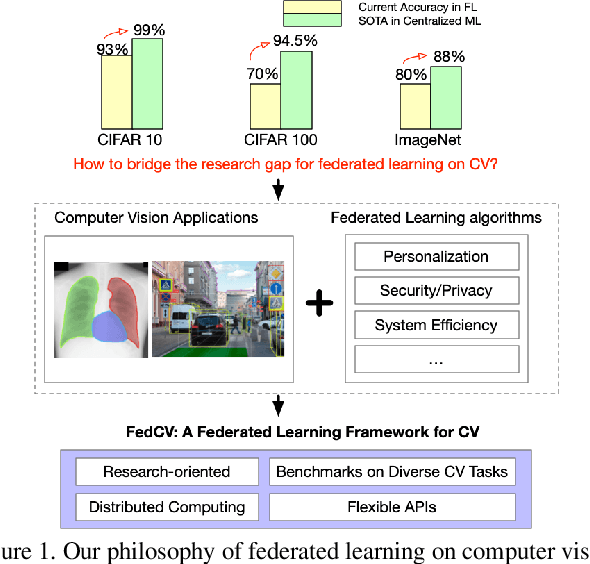
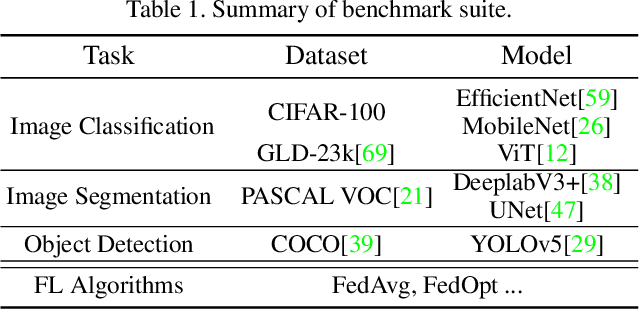
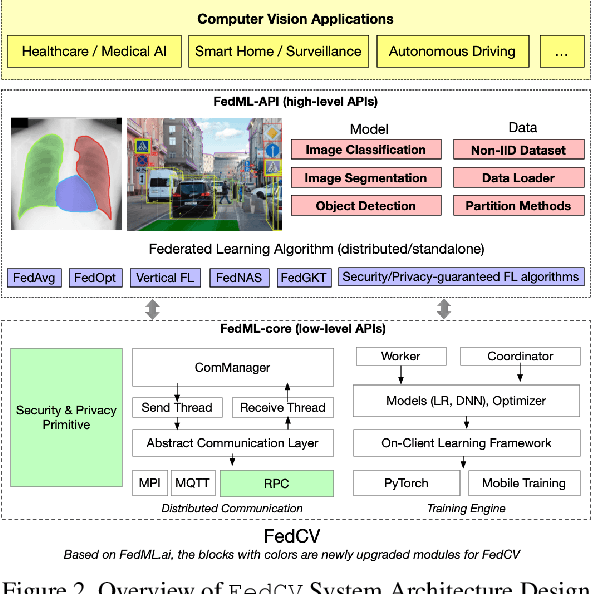
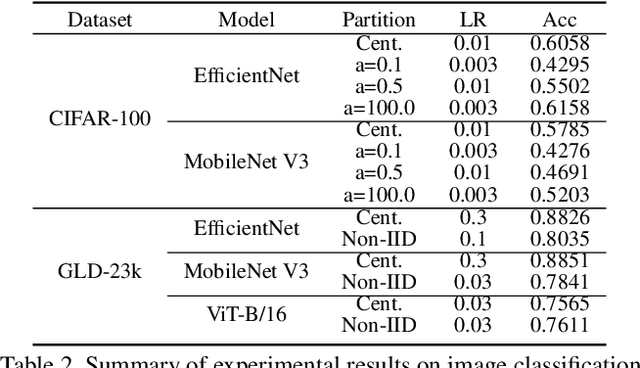
Federated Learning (FL) is a distributed learning paradigm that can learn a global or personalized model from decentralized datasets on edge devices. However, in the computer vision domain, model performance in FL is far behind centralized training due to the lack of exploration in diverse tasks with a unified FL framework. FL has rarely been demonstrated effectively in advanced computer vision tasks such as object detection and image segmentation. To bridge the gap and facilitate the development of FL for computer vision tasks, in this work, we propose a federated learning library and benchmarking framework, named FedCV, to evaluate FL on the three most representative computer vision tasks: image classification, image segmentation, and object detection. We provide non-I.I.D. benchmarking datasets, models, and various reference FL algorithms. Our benchmark study suggests that there are multiple challenges that deserve future exploration: centralized training tricks may not be directly applied to FL; the non-I.I.D. dataset actually downgrades the model accuracy to some degree in different tasks; improving the system efficiency of federated training is challenging given the huge number of parameters and the per-client memory cost. We believe that such a library and benchmark, along with comparable evaluation settings, is necessary to make meaningful progress in FL on computer vision tasks. FedCV is publicly available: https://github.com/FedML-AI/FedCV.
SSFL: Tackling Label Deficiency in Federated Learning via Personalized Self-Supervision
Oct 06, 2021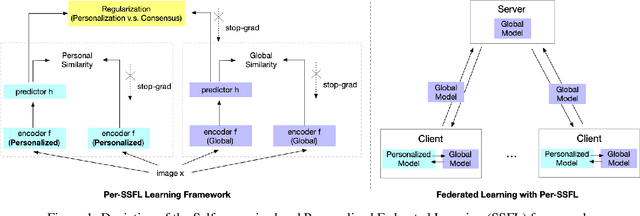

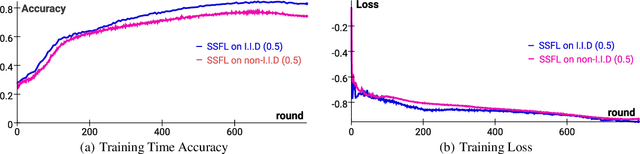
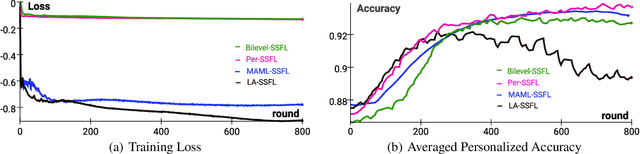
Federated Learning (FL) is transforming the ML training ecosystem from a centralized over-the-cloud setting to distributed training over edge devices in order to strengthen data privacy. An essential but rarely studied challenge in FL is label deficiency at the edge. This problem is even more pronounced in FL compared to centralized training due to the fact that FL users are often reluctant to label their private data. Furthermore, due to the heterogeneous nature of the data at edge devices, it is crucial to develop personalized models. In this paper we propose self-supervised federated learning (SSFL), a unified self-supervised and personalized federated learning framework, and a series of algorithms under this framework which work towards addressing these challenges. First, under the SSFL framework, we demonstrate that the standard FedAvg algorithm is compatible with recent breakthroughs in centralized self-supervised learning such as SimSiam networks. Moreover, to deal with data heterogeneity at the edge devices in this framework, we have innovated a series of algorithms that broaden existing supervised personalization algorithms into the setting of self-supervised learning. We further propose a novel personalized federated self-supervised learning algorithm, Per-SSFL, which balances personalization and consensus by carefully regulating the distance between the local and global representations of data. To provide a comprehensive comparative analysis of all proposed algorithms, we also develop a distributed training system and related evaluation protocol for SSFL. Our findings show that the gap of evaluation accuracy between supervised learning and unsupervised learning in FL is both small and reasonable. The performance comparison indicates the representation regularization-based personalization method is able to outperform other variants.
Outlier-Robust Sparse Estimation via Non-Convex Optimization
Sep 23, 2021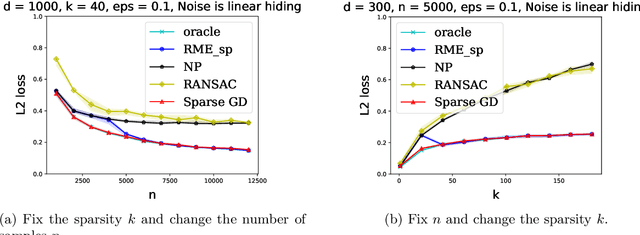
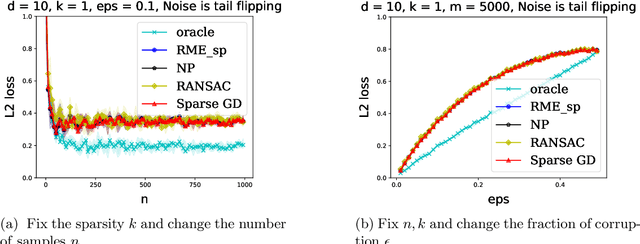
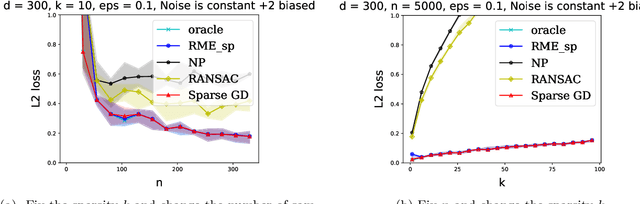
We explore the connection between outlier-robust high-dimensional statistics and non-convex optimization in the presence of sparsity constraints, with a focus on the fundamental tasks of robust sparse mean estimation and robust sparse PCA. We develop novel and simple optimization formulations for these problems such that any approximate stationary point of the associated optimization problem yields a near-optimal solution for the underlying robust estimation task. As a corollary, we obtain that any first-order method that efficiently converges to stationarity yields an efficient algorithm for these tasks. The obtained algorithms are simple, practical, and succeed under broader distributional assumptions compared to prior work.
A Field Guide to Federated Optimization
Jul 14, 2021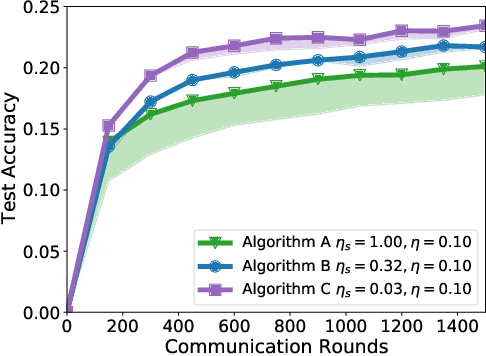


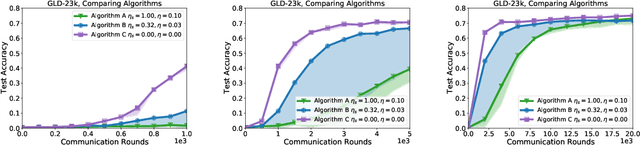
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Small random initialization is akin to spectral learning: Optimization and generalization guarantees for overparameterized low-rank matrix reconstruction
Jun 28, 2021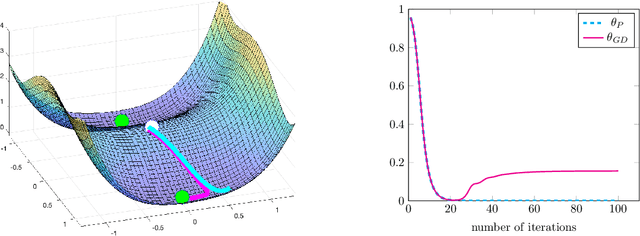
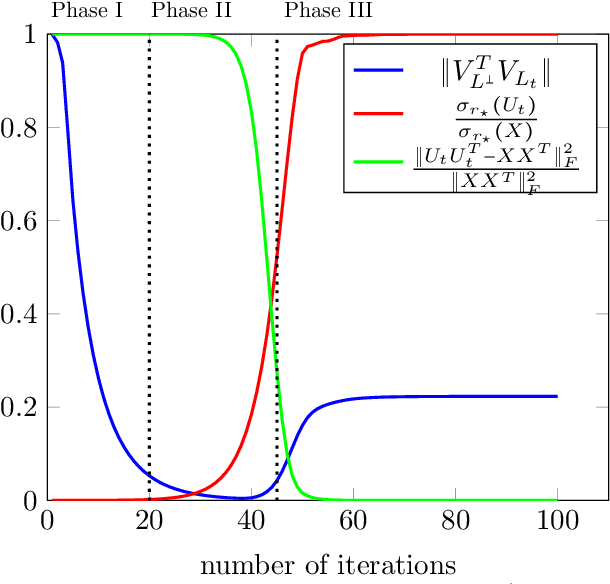
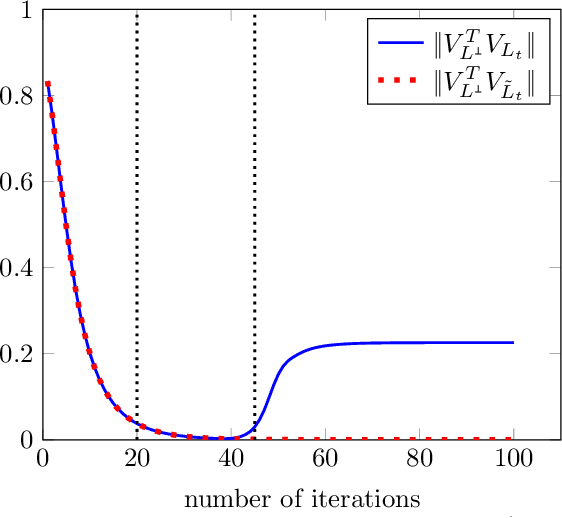
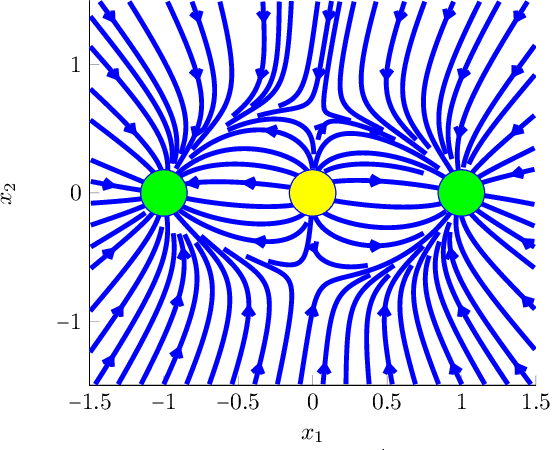
Recently there has been significant theoretical progress on understanding the convergence and generalization of gradient-based methods on nonconvex losses with overparameterized models. Nevertheless, many aspects of optimization and generalization and in particular the critical role of small random initialization are not fully understood. In this paper, we take a step towards demystifying this role by proving that small random initialization followed by a few iterations of gradient descent behaves akin to popular spectral methods. We also show that this implicit spectral bias from small random initialization, which is provably more prominent for overparameterized models, also puts the gradient descent iterations on a particular trajectory towards solutions that are not only globally optimal but also generalize well. Concretely, we focus on the problem of reconstructing a low-rank matrix from a few measurements via a natural nonconvex formulation. In this setting, we show that the trajectory of the gradient descent iterations from small random initialization can be approximately decomposed into three phases: (I) a spectral or alignment phase where we show that that the iterates have an implicit spectral bias akin to spectral initialization allowing us to show that at the end of this phase the column space of the iterates and the underlying low-rank matrix are sufficiently aligned, (II) a saddle avoidance/refinement phase where we show that the trajectory of the gradient iterates moves away from certain degenerate saddle points, and (III) a local refinement phase where we show that after avoiding the saddles the iterates converge quickly to the underlying low-rank matrix. Underlying our analysis are insights for the analysis of overparameterized nonconvex optimization schemes that may have implications for computational problems beyond low-rank reconstruction.
Data augmentation for deep learning based accelerated MRI reconstruction with limited data
Jun 28, 2021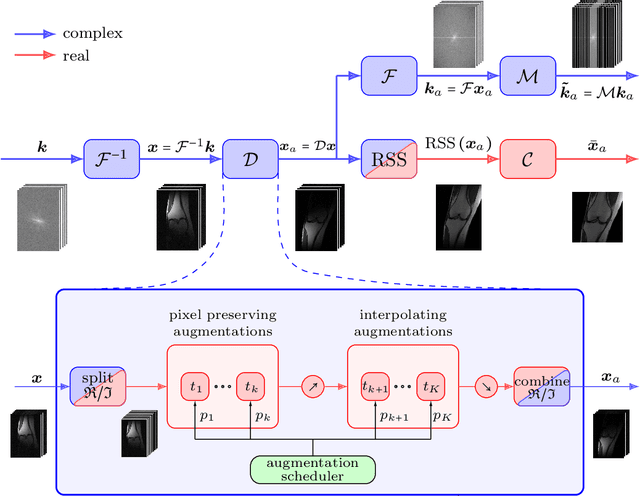
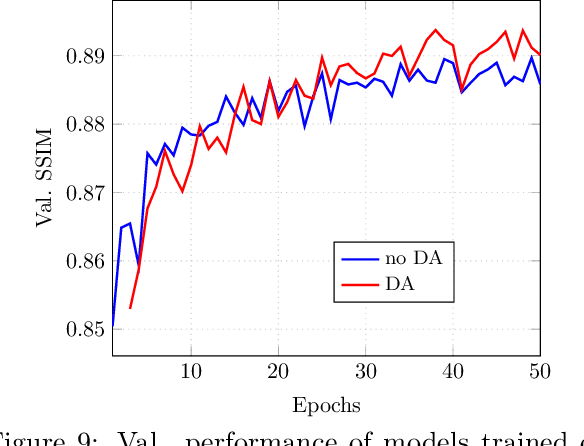
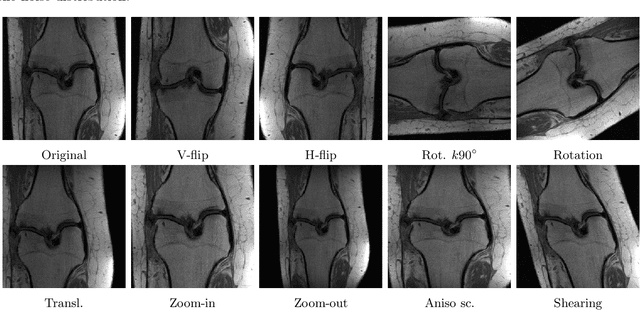
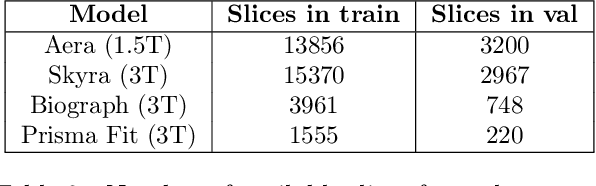
Deep neural networks have emerged as very successful tools for image restoration and reconstruction tasks. These networks are often trained end-to-end to directly reconstruct an image from a noisy or corrupted measurement of that image. To achieve state-of-the-art performance, training on large and diverse sets of images is considered critical. However, it is often difficult and/or expensive to collect large amounts of training images. Inspired by the success of Data Augmentation (DA) for classification problems, in this paper, we propose a pipeline for data augmentation for accelerated MRI reconstruction and study its effectiveness at reducing the required training data in a variety of settings. Our DA pipeline, MRAugment, is specifically designed to utilize the invariances present in medical imaging measurements as naive DA strategies that neglect the physics of the problem fail. Through extensive studies on multiple datasets we demonstrate that in the low-data regime DA prevents overfitting and can match or even surpass the state of the art while using significantly fewer training data, whereas in the high-data regime it has diminishing returns. Furthermore, our findings show that DA can improve the robustness of the model against various shifts in the test distribution.
Generalization Guarantees for Neural Architecture Search with Train-Validation Split
May 10, 2021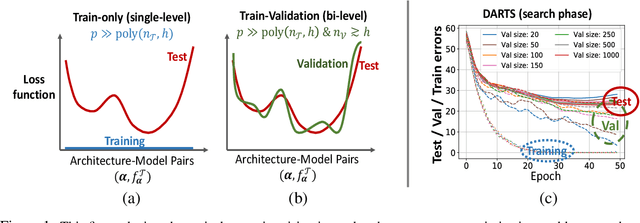
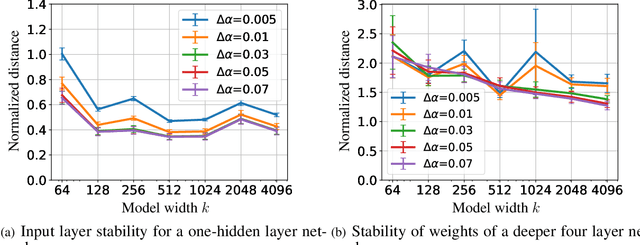
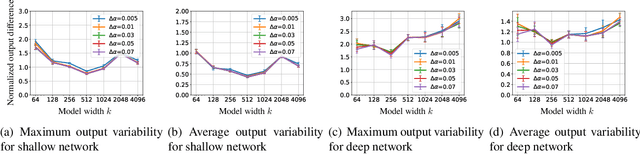
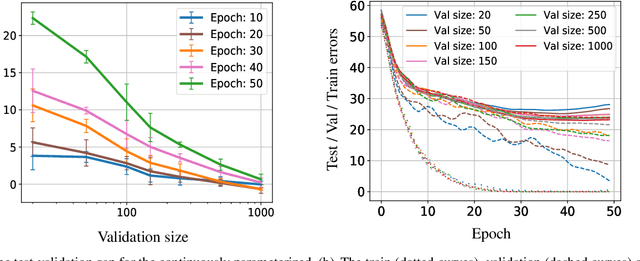
Neural Architecture Search (NAS) is a popular method for automatically designing optimized architectures for high-performance deep learning. In this approach, it is common to use bilevel optimization where one optimizes the model weights over the training data (lower-level problem) and various hyperparameters such as the configuration of the architecture over the validation data (upper-level problem). This paper explores the statistical aspects of such problems with train-validation splits. In practice, the lower-level problem is often overparameterized and can easily achieve zero loss. Thus, a-priori it seems impossible to distinguish the right hyperparameters based on training loss alone which motivates a better understanding of the role of train-validation split. To this aim this work establishes the following results. (1) We show that refined properties of the validation loss such as risk and hyper-gradients are indicative of those of the true test loss. This reveals that the upper-level problem helps select the most generalizable model and prevent overfitting with a near-minimal validation sample size. Importantly, this is established for continuous search spaces which are highly relevant for popular differentiable search schemes. (2) We establish generalization bounds for NAS problems with an emphasis on an activation search problem. When optimized with gradient-descent, we show that the train-validation procedure returns the best (model, architecture) pair even if all architectures can perfectly fit the training data to achieve zero error. (3) Finally, we highlight rigorous connections between NAS, multiple kernel learning, and low-rank matrix learning. The latter leads to novel algorithmic insights where the solution of the upper problem can be accurately learned via efficient spectral methods to achieve near-minimal risk.
FedNLP: A Research Platform for Federated Learning in Natural Language Processing
Apr 18, 2021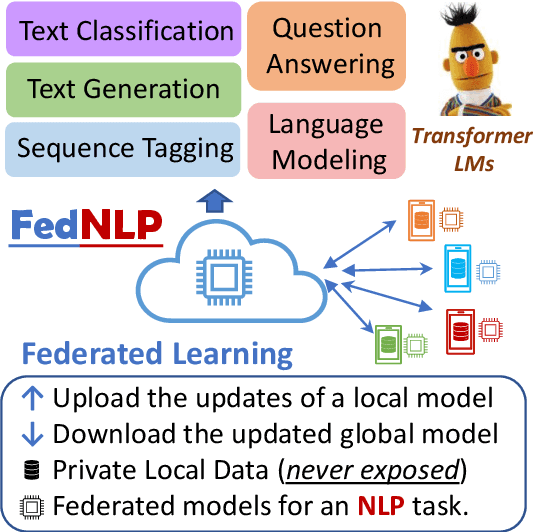
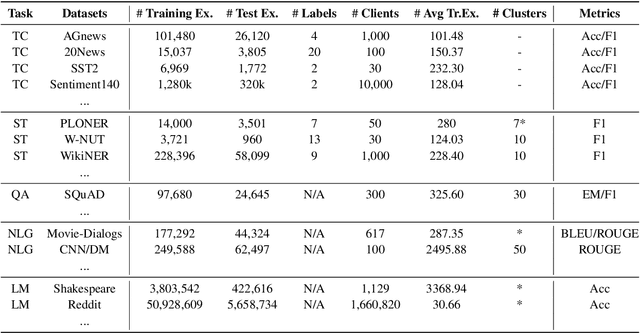
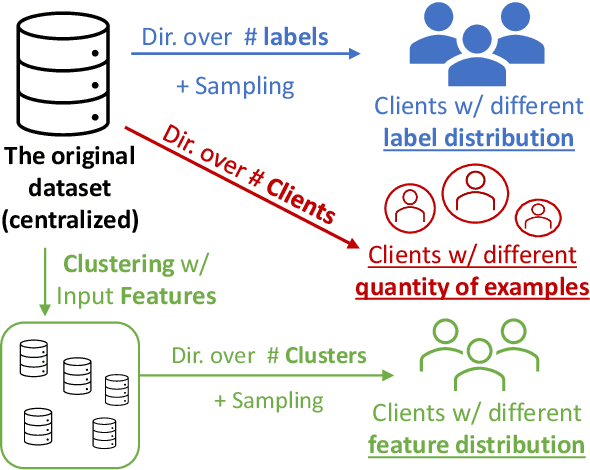
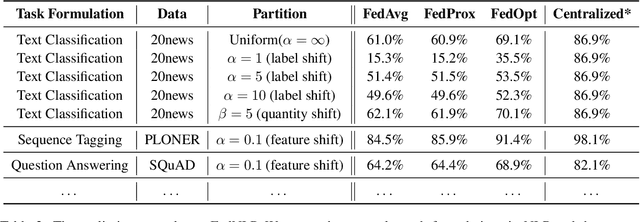
Increasing concerns and regulations about data privacy, necessitate the study of privacy-preserving methods for natural language processing (NLP) applications. Federated learning (FL) provides promising methods for a large number of clients (i.e., personal devices or organizations) to collaboratively learn a shared global model to benefit all clients, while allowing users to keep their data locally. To facilitate FL research in NLP, we present the FedNLP, a research platform for federated learning in NLP. FedNLP supports various popular task formulations in NLP such as text classification, sequence tagging, question answering, seq2seq generation, and language modeling. We also implement an interface between Transformer language models (e.g., BERT) and FL methods (e.g., FedAvg, FedOpt, etc.) for distributed training. The evaluation protocol of this interface supports a comprehensive collection of non-IID partitioning strategies. Our preliminary experiments with FedNLP reveal that there exists a large performance gap between learning on decentralized and centralized datasets -- opening intriguing and exciting future research directions aimed at developing FL methods suited to NLP tasks.