 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Offline Metric for the Debiasedness of Click Models
Apr 19, 2023A well-known problem when learning from user clicks are inherent biases prevalent in the data, such as position or trust bias. Click models are a common method for extracting information from user clicks, such as document relevance in web search, or to estimate click biases for downstream applications such as counterfactual learning-to-rank, ad placement, or fair ranking. Recent work shows that the current evaluation practices in the community fail to guarantee that a well-performing click model generalizes well to downstream tasks in which the ranking distribution differs from the training distribution, i.e., under covariate shift. In this work, we propose an evaluation metric based on conditional independence testing to detect a lack of robustness to covariate shift in click models. We introduce the concept of debiasedness and a metric for measuring it. We prove that debiasedness is a necessary condition for recovering unbiased and consistent relevance scores and for the invariance of click prediction under covariate shift. In extensive semi-synthetic experiments, we show that our proposed metric helps to predict the downstream performance of click models under covariate shift and is useful in an off-policy model selection setting.
Learning to Tokenize for Generative Retrieval
Apr 09, 2023



Conventional document retrieval techniques are mainly based on the index-retrieve paradigm. It is challenging to optimize pipelines based on this paradigm in an end-to-end manner. As an alternative, generative retrieval represents documents as identifiers (docid) and retrieves documents by generating docids, enabling end-to-end modeling of document retrieval tasks. However, it is an open question how one should define the document identifiers. Current approaches to the task of defining document identifiers rely on fixed rule-based docids, such as the title of a document or the result of clustering BERT embeddings, which often fail to capture the complete semantic information of a document. We propose GenRet, a document tokenization learning method to address the challenge of defining document identifiers for generative retrieval. GenRet learns to tokenize documents into short discrete representations (i.e., docids) via a discrete auto-encoding approach. Three components are included in GenRet: (i) a tokenization model that produces docids for documents; (ii) a reconstruction model that learns to reconstruct a document based on a docid; and (iii) a sequence-to-sequence retrieval model that generates relevant document identifiers directly for a designated query. By using an auto-encoding framework, GenRet learns semantic docids in a fully end-to-end manner. We also develop a progressive training scheme to capture the autoregressive nature of docids and to stabilize training. We conduct experiments on the NQ320K, MS MARCO, and BEIR datasets to assess the effectiveness of GenRet. GenRet establishes the new state-of-the-art on the NQ320K dataset. Especially, compared to generative retrieval baselines, GenRet can achieve significant improvements on the unseen documents. GenRet also outperforms comparable baselines on MS MARCO and BEIR, demonstrating the method's generalizability.
A Self-Correcting Sequential Recommender
Mar 04, 2023



Sequential recommendations aim to capture users' preferences from their historical interactions so as to predict the next item that they will interact with. Sequential recommendation methods usually assume that all items in a user's historical interactions reflect her/his preferences and transition patterns between items. However, real-world interaction data is imperfect in that (i) users might erroneously click on items, i.e., so-called misclicks on irrelevant items, and (ii) users might miss items, i.e., unexposed relevant items due to inaccurate recommendations. To tackle the two issues listed above, we propose STEAM, a Self-correcTing sEquentiAl recoMmender. STEAM first corrects an input item sequence by adjusting the misclicked and/or missed items. It then uses the corrected item sequence to train a recommender and make the next item prediction.We design an item-wise corrector that can adaptively select one type of operation for each item in the sequence. The operation types are 'keep', 'delete' and 'insert.' In order to train the item-wise corrector without requiring additional labeling, we design two self-supervised learning mechanisms: (i) deletion correction (i.e., deleting randomly inserted items), and (ii) insertion correction (i.e., predicting randomly deleted items). We integrate the corrector with the recommender by sharing the encoder and by training them jointly. We conduct extensive experiments on three real-world datasets and the experimental results demonstrate that STEAM outperforms state-of-the-art sequential recommendation baselines. Our in-depth analyses confirm that STEAM benefits from learning to correct the raw item sequences.
Generative Slate Recommendation with Reinforcement Learning
Jan 24, 2023Recent research has employed reinforcement learning (RL) algorithms to optimize long-term user engagement in recommender systems, thereby avoiding common pitfalls such as user boredom and filter bubbles. They capture the sequential and interactive nature of recommendations, and thus offer a principled way to deal with long-term rewards and avoid myopic behaviors. However, RL approaches are intractable in the slate recommendation scenario - where a list of items is recommended at each interaction turn - due to the combinatorial action space. In that setting, an action corresponds to a slate that may contain any combination of items. While previous work has proposed well-chosen decompositions of actions so as to ensure tractability, these rely on restrictive and sometimes unrealistic assumptions. Instead, in this work we propose to encode slates in a continuous, low-dimensional latent space learned by a variational auto-encoder. Then, the RL agent selects continuous actions in this latent space, which are ultimately decoded into the corresponding slates. By doing so, we are able to (i) relax assumptions required by previous work, and (ii) improve the quality of the action selection by modeling full slates instead of independent items, in particular by enabling diversity. Our experiments performed on a wide array of simulated environments confirm the effectiveness of our generative modeling of slates over baselines in practical scenarios where the restrictive assumptions underlying the baselines are lifted. Our findings suggest that representation learning using generative models is a promising direction towards generalizable RL-based slate recommendation.
Scene-centric vs. Object-centric Image-Text Cross-modal Retrieval: A Reproducibility Study
Jan 12, 2023Most approaches to cross-modal retrieval (CMR) focus either on object-centric datasets, meaning that each document depicts or describes a single object, or on scene-centric datasets, meaning that each image depicts or describes a complex scene that involves multiple objects and relations between them. We posit that a robust CMR model should generalize well across both dataset types. Despite recent advances in CMR, the reproducibility of the results and their generalizability across different dataset types has not been studied before. We address this gap and focus on the reproducibility of the state-of-the-art CMR results when evaluated on object-centric and scene-centric datasets. We select two state-of-the-art CMR models with different architectures: (i) CLIP; and (ii) X-VLM. Additionally, we select two scene-centric datasets, and three object-centric datasets, and determine the relative performance of the selected models on these datasets. We focus on reproducibility, replicability, and generalizability of the outcomes of previously published CMR experiments. We discover that the experiments are not fully reproducible and replicable. Besides, the relative performance results partially generalize across object-centric and scene-centric datasets. On top of that, the scores obtained on object-centric datasets are much lower than the scores obtained on scene-centric datasets. For reproducibility and transparency we make our source code and the trained models publicly available.
Modeling Sequential Recommendation as Missing Information Imputation
Jan 04, 2023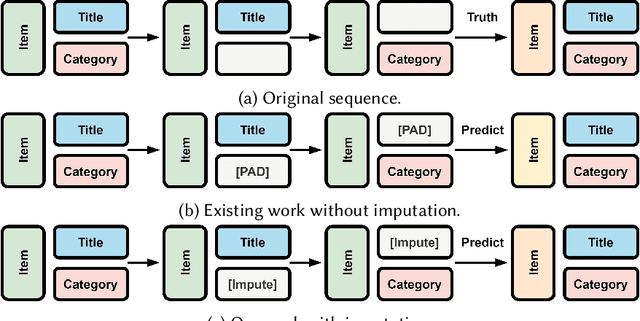
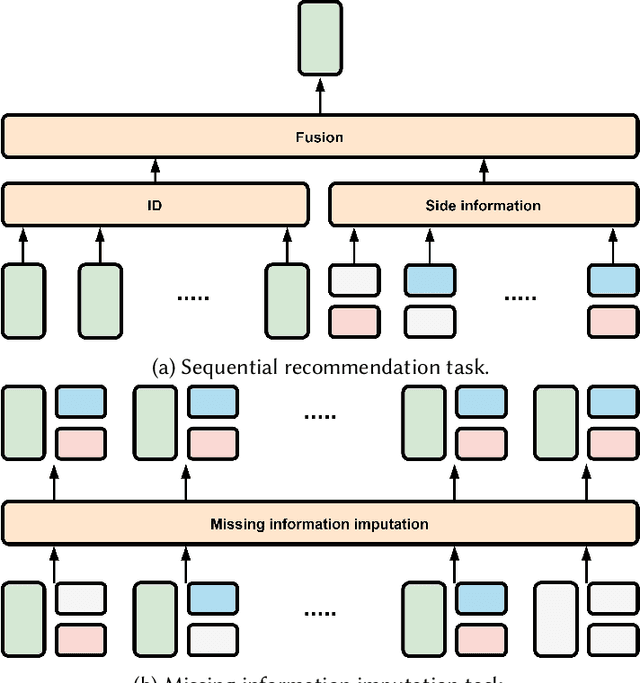
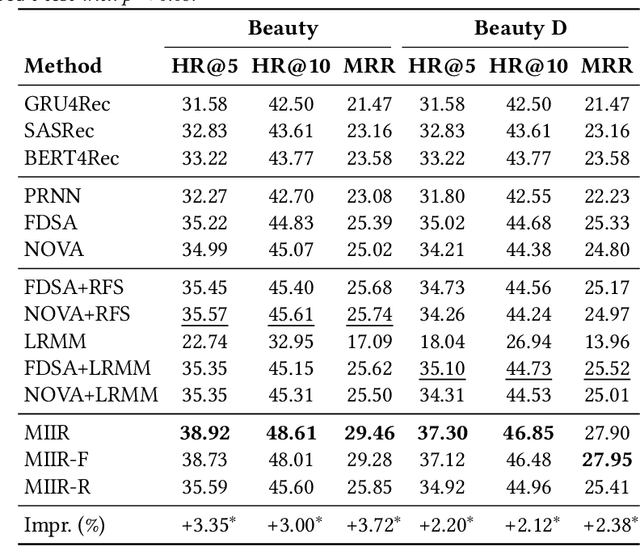
Side information is being used extensively to improve the effectiveness of sequential recommendation models. It is said to help capture the transition patterns among items. Most previous work on sequential recommendation that uses side information models item IDs and side information separately. This can only model part of relations between items and their side information. Moreover, in real-world systems, not all values of item feature fields are available. This hurts the performance of models that rely on side information. Existing methods tend to neglect the context of missing item feature fields, and fill them with generic or special values, e.g., unknown, which might lead to sub-optimal performance. To address the limitation of sequential recommenders with side information, we define a way to fuse side information and alleviate the problem of missing side information by proposing a unified task, namely the missing information imputation (MII), which randomly masks some feature fields in a given sequence of items, including item IDs, and then forces a predictive model to recover them. By considering the next item as a missing feature field, sequential recommendation can be formulated as a special case of MII. We propose a sequential recommendation model, called missing information imputation recommender (MIIR), that builds on the idea of MII and simultaneously imputes missing item feature values and predicts the next item. We devise a dense fusion self-attention (DFSA) for MIIR to capture all pairwise relations between items and their side information. Empirical studies on three benchmark datasets demonstrate that MIIR, supervised by MII, achieves a significantly better sequential recommendation performance than state-of-the-art baselines.
Offline Evaluation for Reinforcement Learning-based Recommendation: A Critical Issue and Some Alternatives
Jan 03, 2023In this paper, we argue that the paradigm commonly adopted for offline evaluation of sequential recommender systems is unsuitable for evaluating reinforcement learning-based recommenders. We find that most of the existing offline evaluation practices for reinforcement learning-based recommendation are based on a next-item prediction protocol, and detail three shortcomings of such an evaluation protocol. Notably, it cannot reflect the potential benefits that reinforcement learning (RL) is expected to bring while it hides critical deficiencies of certain offline RL agents. Our suggestions for alternative ways to evaluate RL-based recommender systems aim to shed light on the existing possibilities and inspire future research on reliable evaluation protocols.
Contrastive Learning Reduces Hallucination in Conversations
Dec 20, 2022



Pre-trained language models (LMs) store knowledge in their parameters and can generate informative responses when used in conversational systems. However, LMs suffer from the problem of "hallucination:" they may generate plausible-looking statements that are irrelevant or factually incorrect. To address this problem, we propose a contrastive learning scheme, named MixCL. A novel mixed contrastive objective is proposed to explicitly optimize the implicit knowledge elicitation process of LMs, and thus reduce their hallucination in conversations. We also examine negative sampling strategies of retrieved hard negatives and model-generated negatives. We conduct experiments on Wizard-of-Wikipedia, a public, open-domain knowledge-grounded dialogue benchmark, and assess the effectiveness of MixCL. MixCL effectively reduces the hallucination of LMs in conversations and achieves the highest performance among LM-based dialogue agents in terms of relevancy and factuality. We show that MixCL achieves comparable performance to state-of-the-art KB-based approaches while enjoying notable advantages in terms of efficiency and scalability.
Feature-Level Debiased Natural Language Understanding
Dec 18, 2022Natural language understanding (NLU) models often rely on dataset biases rather than intended task-relevant features to achieve high performance on specific datasets. As a result, these models perform poorly on datasets outside the training distribution. Some recent studies address this issue by reducing the weights of biased samples during the training process. However, these methods still encode biased latent features in representations and neglect the dynamic nature of bias, which hinders model prediction. We propose an NLU debiasing method, named debiasing contrastive learning (DCT), to simultaneously alleviate the above problems based on contrastive learning. We devise a debiasing, positive sampling strategy to mitigate biased latent features by selecting the least similar biased positive samples. We also propose a dynamic negative sampling strategy to capture the dynamic influence of biases by employing a bias-only model to dynamically select the most similar biased negative samples. We conduct experiments on three NLU benchmark datasets. Experimental results show that DCT outperforms state-of-the-art baselines on out-of-distribution datasets while maintaining in-distribution performance. We also verify that DCT can reduce biased latent features from the model's representation.
RADio -- Rank-Aware Divergence Metrics to Measure Normative Diversity in News Recommendations
Sep 17, 2022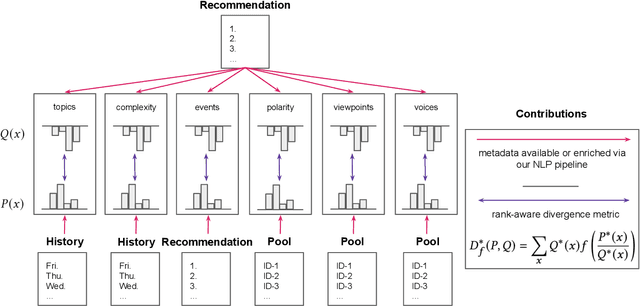

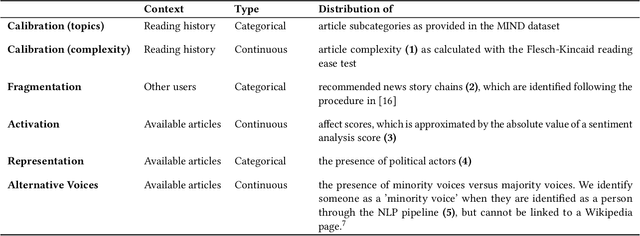
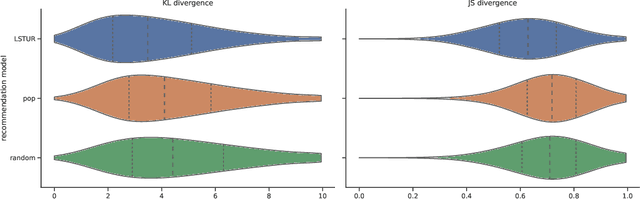
In traditional recommender system literature, diversity is often seen as the opposite of similarity, and typically defined as the distance between identified topics, categories or word models. However, this is not expressive of the social science's interpretation of diversity, which accounts for a news organization's norms and values and which we here refer to as normative diversity. We introduce RADio, a versatile metrics framework to evaluate recommendations according to these normative goals. RADio introduces a rank-aware Jensen Shannon (JS) divergence. This combination accounts for (i) a user's decreasing propensity to observe items further down a list and (ii) full distributional shifts as opposed to point estimates. We evaluate RADio's ability to reflect five normative concepts in news recommendations on the Microsoft News Dataset and six (neural) recommendation algorithms, with the help of our metadata enrichment pipeline. We find that RADio provides insightful estimates that can potentially be used to inform news recommender system design.