 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training
Apr 01, 2021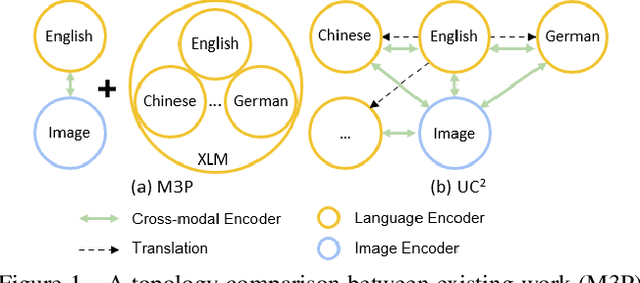
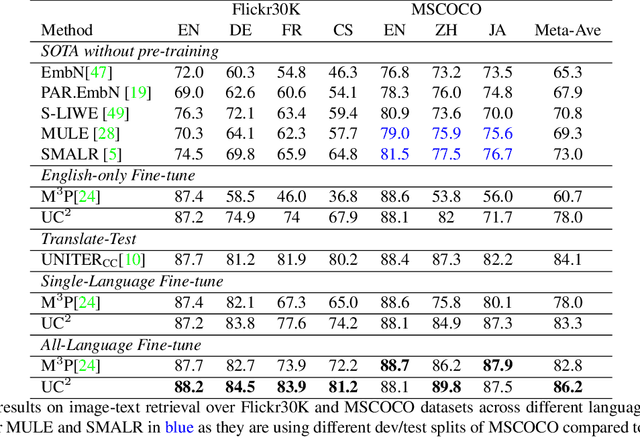
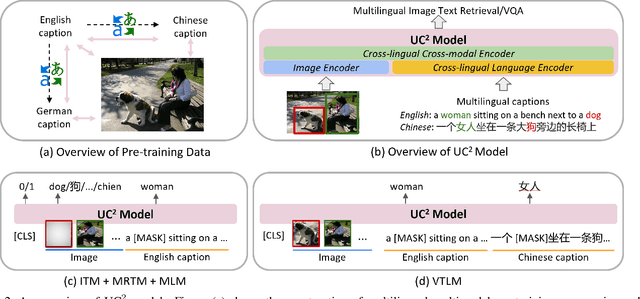
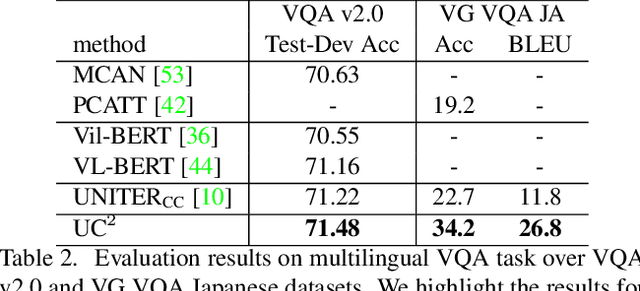
Vision-and-language pre-training has achieved impressive success in learning multimodal representations between vision and language. To generalize this success to non-English languages, we introduce UC2, the first machine translation-augmented framework for cross-lingual cross-modal representation learning. To tackle the scarcity problem of multilingual captions for image datasets, we first augment existing English-only datasets with other languages via machine translation (MT). Then we extend the standard Masked Language Modeling and Image-Text Matching training objectives to multilingual setting, where alignment between different languages is captured through shared visual context (i.e, using image as pivot). To facilitate the learning of a joint embedding space of images and all languages of interest, we further propose two novel pre-training tasks, namely Masked Region-to-Token Modeling (MRTM) and Visual Translation Language Modeling (VTLM), leveraging MT-enhanced translated data. Evaluation on multilingual image-text retrieval and multilingual visual question answering benchmarks demonstrates that our proposed framework achieves new state-of-the-art on diverse non-English benchmarks while maintaining comparable performance to monolingual pre-trained models on English tasks.
Less is More: ClipBERT for Video-and-Language Learning via Sparse Sampling
Feb 11, 2021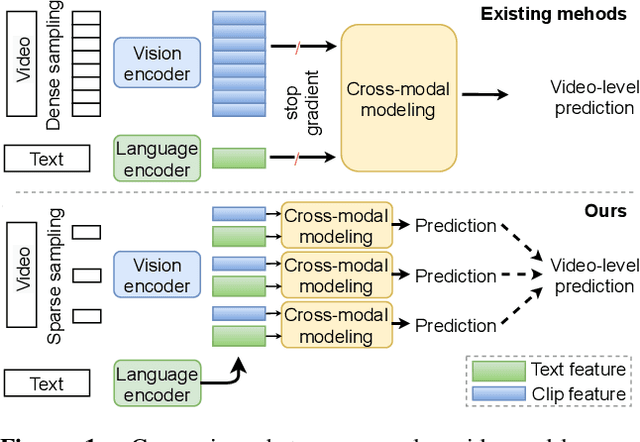
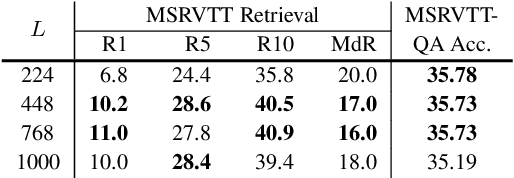
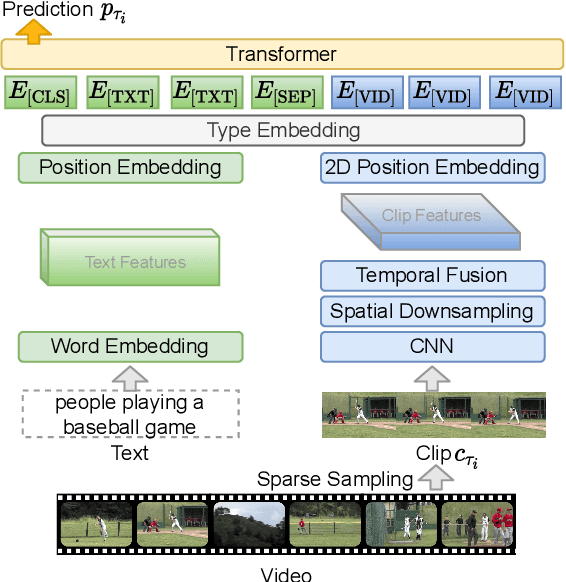
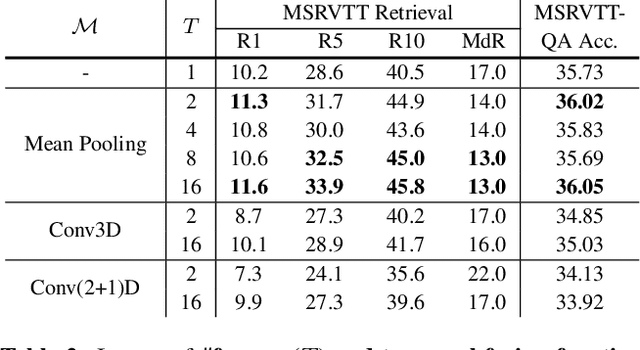
The canonical approach to video-and-language learning (e.g., video question answering) dictates a neural model to learn from offline-extracted dense video features from vision models and text features from language models. These feature extractors are trained independently and usually on tasks different from the target domains, rendering these fixed features sub-optimal for downstream tasks. Moreover, due to the high computational overload of dense video features, it is often difficult (or infeasible) to plug feature extractors directly into existing approaches for easy finetuning. To provide a remedy to this dilemma, we propose a generic framework ClipBERT that enables affordable end-to-end learning for video-and-language tasks, by employing sparse sampling, where only a single or a few sparsely sampled short clips from a video are used at each training step. Experiments on text-to-video retrieval and video question answering on six datasets demonstrate that ClipBERT outperforms (or is on par with) existing methods that exploit full-length videos, suggesting that end-to-end learning with just a few sparsely sampled clips is often more accurate than using densely extracted offline features from full-length videos, proving the proverbial less-is-more principle. Videos in the datasets are from considerably different domains and lengths, ranging from 3-second generic domain GIF videos to 180-second YouTube human activity videos, showing the generalization ability of our approach. Comprehensive ablation studies and thorough analyses are provided to dissect what factors lead to this success. Our code is publicly available at https://github.com/jayleicn/ClipBERT
Temporally Guided Articulated Hand Pose Tracking in Surgical Videos
Jan 12, 2021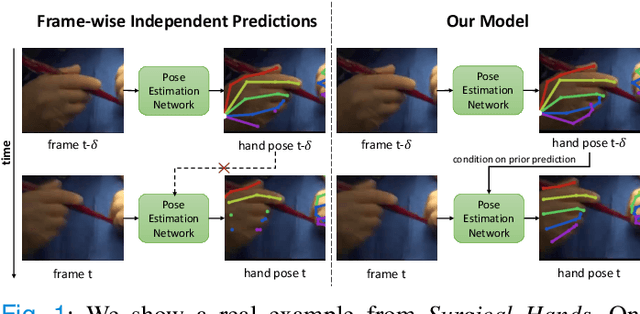
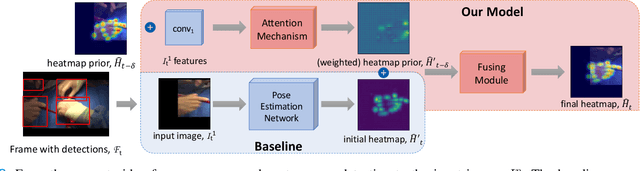
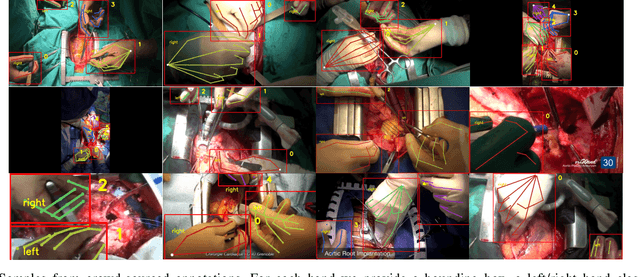
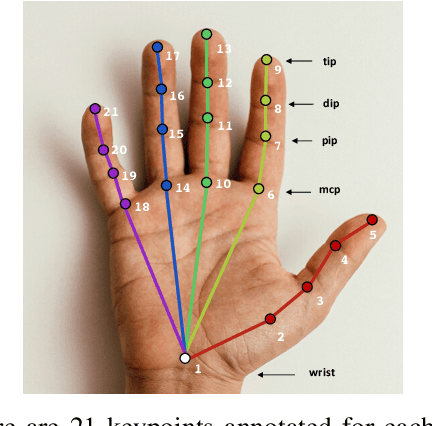
Articulated hand pose tracking is an underexplored problem that carries the potential for use in an extensive number of applications, especially in the medical domain. With a robust and accurate tracking system on in-vivo surgical videos, the motion dynamics and movement patterns of the hands can be captured and analyzed for rich tasks including skills assessment, training surgical residents, and temporal action recognition. In this work, we propose a novel hand pose estimation model, Res152- CondPose, which improves tracking accuracy by incorporating a hand pose prior into its pose prediction. We show improvements over state-of-the-art methods which provide frame-wise independent predictions, by following a temporally guided approach that effectively leverages past predictions. Additionally, we collect the first dataset, Surgical Hands, that provides multi-instance articulated hand pose annotations for in-vivo videos. Our dataset contains 76 video clips from 28 publicly available surgical videos and over 8.1k annotated hand pose instances. We provide bounding boxes, articulated hand pose annotations, and tracking IDs to enable multi-instance area-based and articulated tracking. When evaluated on Surgical Hands, we show our method outperforms the state-of-the-art method using mean Average Precision (mAP), to measure pose estimation accuracy, and Multiple Object Tracking Accuracy (MOTA), to assess pose tracking performance.
Cluster-Former: Clustering-based Sparse Transformer for Long-Range Dependency Encoding
Sep 13, 2020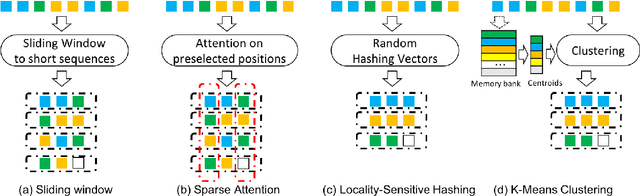
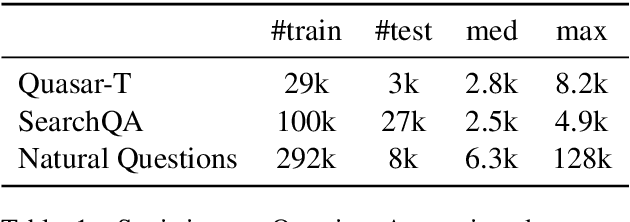
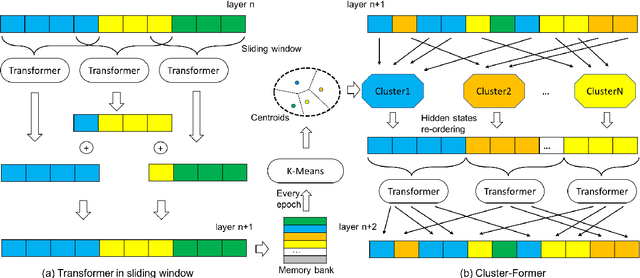
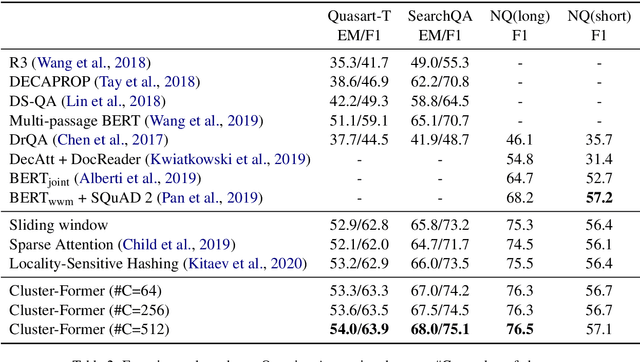
Transformer has become ubiquitous in the deep learning field. One of the key ingredients that destined its success is the self-attention mechanism, which allows fully-connected contextual encoding over input tokens. However, despite its effectiveness in modeling short sequences, self-attention suffers when handling inputs with extreme long-range dependencies, as its complexity grows quadratically with respect to the sequence length. Therefore, long sequences are often encoded by Transformer in chunks using a sliding window. In this paper, we propose Cluster-Former, a novel clustering-based sparse Transformer to perform attention across chunked sequences. Our proposed method allows information integration beyond local windows, which is especially beneficial for question answering (QA) and language modeling tasks that rely on long-range dependencies. Experiments show that Cluster-Former achieves state-of-the-art performance on several major QA benchmarks.
Unified Vision-Language Pre-Training for Image Captioning and VQA
Oct 03, 2019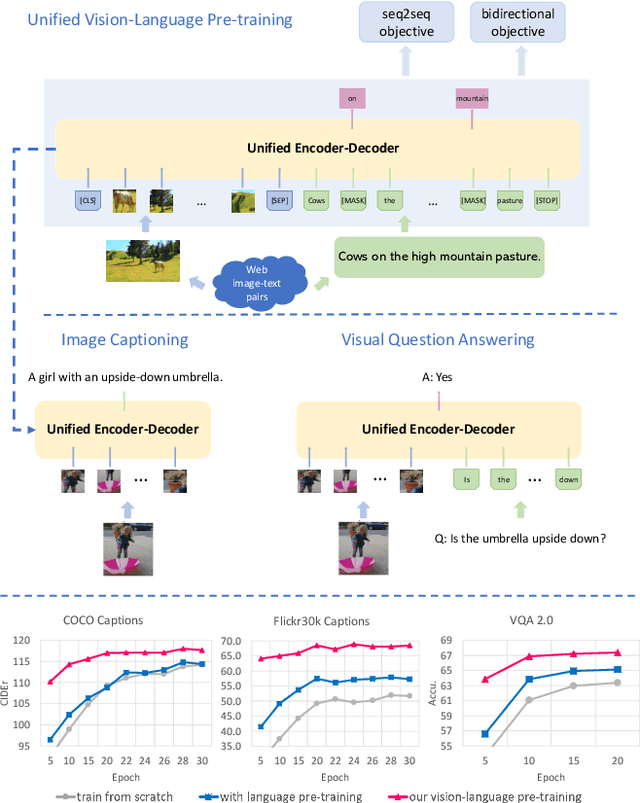
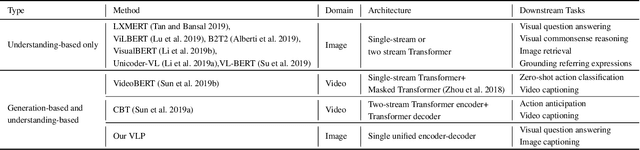
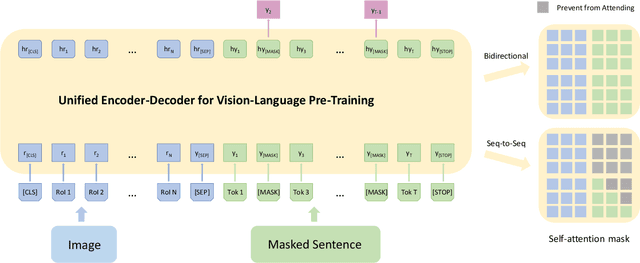
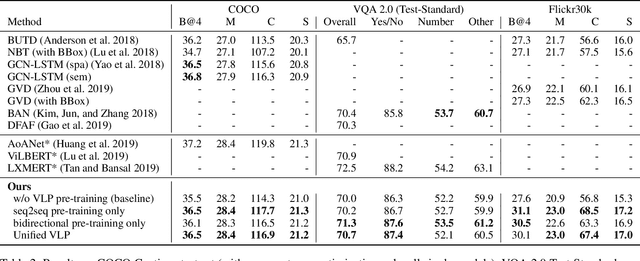
This paper presents a unified Vision-Language Pre-training (VLP) model. The model is unified in that (1) it can be fine-tuned for either vision-language generation (e.g., image captioning) or understanding (e.g., visual question answering) tasks, and (2) it uses a shared multi-layer transformer network for both encoding and decoding, which differs from many existing methods where the encoder and decoder are implemented using separate models. The unified VLP model is pre-trained on a large amount of image-text pairs using the unsupervised learning objectives of two tasks: bidirectional and sequence-to-sequence (seq2seq) masked vision-language prediction. The two tasks differ solely in what context the prediction conditions on. This is controlled by utilizing specific self-attention masks for the shared transformer network. To the best of our knowledge, VLP is the first reported model that achieves state-of-the-art results on both vision-language generation and understanding tasks, as disparate as image captioning and visual question answering, across three challenging benchmark datasets: COCO Captions, Flickr30k Captions, and VQA 2.0. The code and the pre-trained models are available at https://github.com/LuoweiZhou/VLP.
Grounded Video Description
Dec 17, 2018



Video description is one of the most challenging problems in vision and language understanding due to the large variability both on the video and language side. Models, hence, typically shortcut the difficulty in recognition and generate plausible sentences that are based on priors but are not necessarily grounded in the video. In this work, we explicitly link the sentence to the evidence in the video by annotating each noun phrase in a sentence with the corresponding bounding box in one of the frames of a video. Our novel dataset, ActivityNet-Entities, is based on the challenging ActivityNet Captions dataset and augments it with 158k bounding box annotations, each grounding a noun phrase. This allows training video description models with this data, and importantly, evaluate how grounded or "true" such model are to the video they describe. To generate grounded captions, we propose a novel video description model which is able to exploit these bounding box annotations. We demonstrate the effectiveness of our model on our ActivityNet-Entities, but also show how it can be applied to image description on the Flickr30k Entities dataset. We achieve state-of-the-art performance on video description, video paragraph description, and image description and demonstrate our generated sentences are better grounded in the video.
Dynamic Graph Modules for Modeling Higher-Order Interactions in Activity Recognition
Dec 13, 2018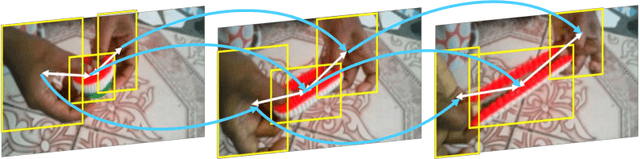

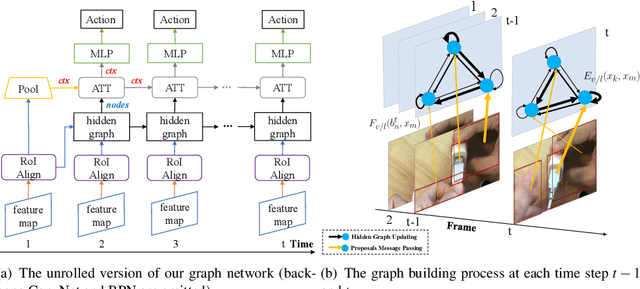
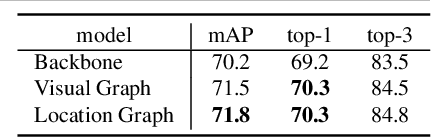
Video action recognition, as a critical problem towards video understanding, has attracted increasing attention recently. To identify an action involving higher-order object interactions, we need to consider: 1) spatial relations among objects in a single frame; 2) temporal relations between different/same objects across multiple frames. However, previous approaches, e.g., 2D ConvNet + LSTM or 3D ConvNet, are either incapable of capturing relations between objects, or unable to handle streaming videos. In this paper, we propose a novel dynamic graph module to model object interactions in videos. We also devise two instantiations of our graph module: (i) visual graph, to capture visual similarity changes between objects; (ii) location graph, to capture relative location changes between objects. Distinct from previous models, the proposed graph module has the ability to process streaming videos in an aggressive manner. Combined with existing 3D action recognition ConvNets, our graph module can also boost ConvNets' performance, which demonstrates the flexibility of the module. We test our graph module on Something-Something dataset and achieve the state-of-the-art performance.
Weakly-Supervised Video Object Grounding from Text by Loss Weighting and Object Interaction
Jul 20, 2018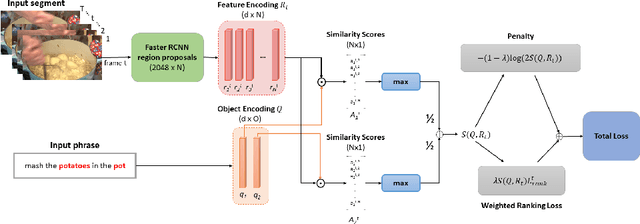
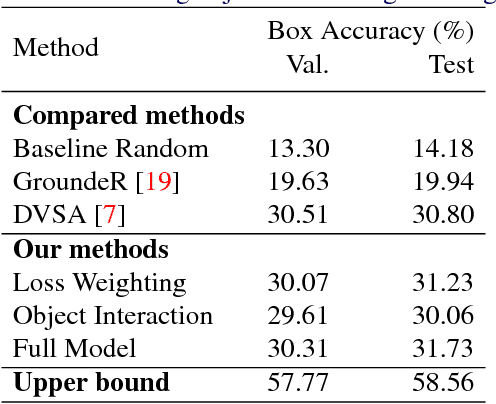
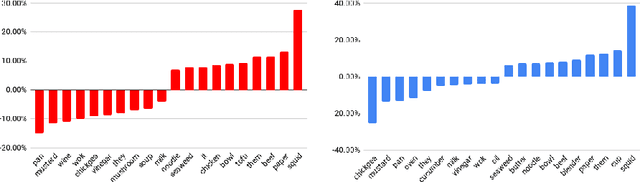
We study weakly-supervised video object grounding: given a video segment and a corresponding descriptive sentence, the goal is to localize objects that are mentioned from the sentence in the video. During training, no object bounding boxes are available, but the set of possible objects to be grounded is known beforehand. Existing approaches in the image domain use Multiple Instance Learning (MIL) to ground objects by enforcing matches between visual and semantic features. A naive extension of this approach to the video domain is to treat the entire segment as a bag of spatial object proposals. However, an object existing sparsely across multiple frames might not be detected completely since successfully spotting it from one single frame would trigger a satisfactory match. To this end, we propagate the weak supervisory signal from the segment level to frames that likely contain the target object. For frames that are unlikely to contain the target objects, we use an alternative penalty loss. We also leverage the interactions among objects as a textual guide for the grounding. We evaluate our model on the newly-collected benchmark YouCook2-BoundingBox and show improvements over competitive baselines.
End-to-End Dense Video Captioning with Masked Transformer
Apr 03, 2018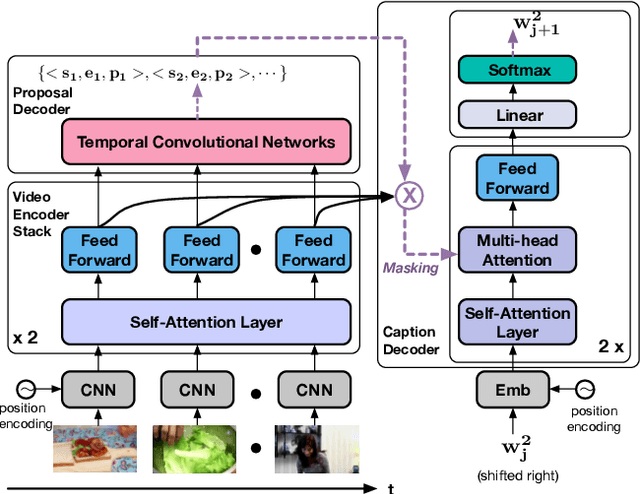
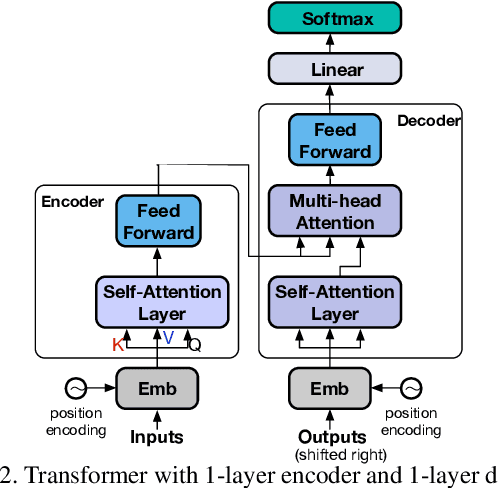
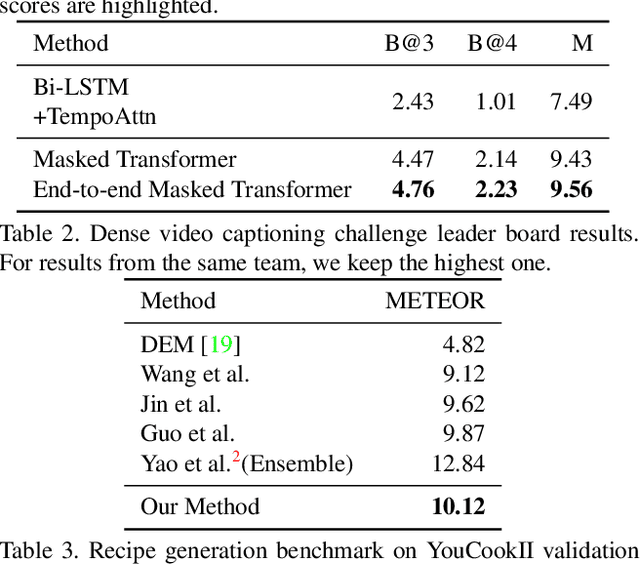
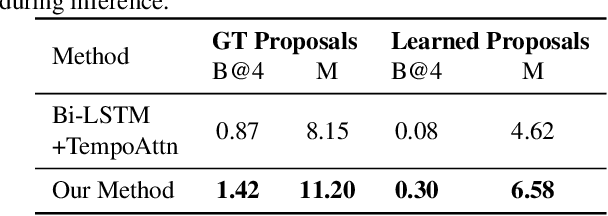
Dense video captioning aims to generate text descriptions for all events in an untrimmed video. This involves both detecting and describing events. Therefore, all previous methods on dense video captioning tackle this problem by building two models, i.e. an event proposal and a captioning model, for these two sub-problems. The models are either trained separately or in alternation. This prevents direct influence of the language description to the event proposal, which is important for generating accurate descriptions. To address this problem, we propose an end-to-end transformer model for dense video captioning. The encoder encodes the video into appropriate representations. The proposal decoder decodes from the encoding with different anchors to form video event proposals. The captioning decoder employs a masking network to restrict its attention to the proposal event over the encoding feature. This masking network converts the event proposal to a differentiable mask, which ensures the consistency between the proposal and captioning during training. In addition, our model employs a self-attention mechanism, which enables the use of efficient non-recurrent structure during encoding and leads to performance improvements. We demonstrate the effectiveness of this end-to-end model on ActivityNet Captions and YouCookII datasets, where we achieved 10.12 and 6.58 METEOR score, respectively.
Towards Automatic Learning of Procedures from Web Instructional Videos
Nov 21, 2017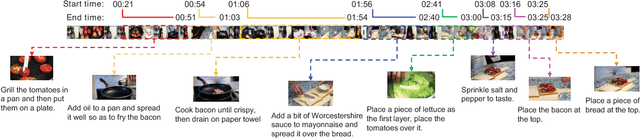
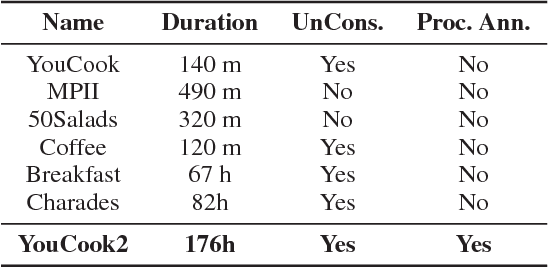

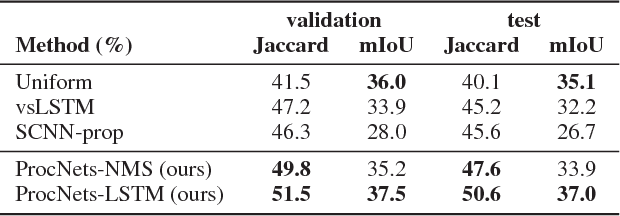
The potential for agents, whether embodied or software, to learn by observing other agents performing procedures involving objects and actions is rich. Current research on automatic procedure learning heavily relies on action labels or video subtitles, even during the evaluation phase, which makes them infeasible in real-world scenarios. This leads to our question: can the human-consensus structure of a procedure be learned from a large set of long, unconstrained videos (e.g., instructional videos from YouTube) with only visual evidence? To answer this question, we introduce the problem of procedure segmentation--to segment a video procedure into category-independent procedure segments. Given that no large-scale dataset is available for this problem, we collect a large-scale procedure segmentation dataset with procedure segments temporally localized and described; we use cooking videos and name the dataset YouCook2. We propose a segment-level recurrent network for generating procedure segments by modeling the dependencies across segments. The generated segments can be used as pre-processing for other tasks, such as dense video captioning and event parsing. We show in our experiments that the proposed model outperforms competitive baselines in procedure segmentation.