 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgAtlas: A Large-Scale Surgical Video-Language Dataset with 2,391 Hours of Open and Minimally Invasive Surgery
Jun 24, 2026We introduce SurgAtlas, the largest surgical video-language dataset to date, comprising 15,291 videos (2,391 hours) spanning 18 surgical specialties and over 5,000 procedure types, sourced entirely from publicly available YouTube content. SurgAtlas is also the first surgical video-language dataset to include open surgery at scale, with 6,182 open procedure videos alongside over 9,000 minimally invasive recordings, and the first to establish standardized benchmarks for open-surgery video understanding. We additionally provide an expert-validated subset with verified visual question-answer pairs across diverse open and minimally invasive procedures, serving as a clinically grounded benchmark for surgical reasoning. Compared with existing surgical video-language datasets, SurgAtlas provides one of the most diverse annotation schemas, combining segment-level captions, step- and phase-level descriptions, video-level surgical descriptions, and reasoning-oriented question-answer pairs organized within a hierarchical taxonomy. These annotations are constructed through an automated multi-tier pipeline with LLM-based enrichment and a staged VQA generation framework with explicit groundedness verification. The scale and diversity of SurgAtlas enable training surgical foundation models with broad procedural coverage: we finetune Qwen3-VL-8B through a two-stage captioning-then-instruction pipeline and achieve competitive or state-of-the-art results on multiple established surgical benchmarks, including phase recognition, triplet detection, and reasoning question answering. More broadly, SurgAtlas provides a large native public video corpus that can support future large-scale pretraining of multimodal surgical AI systems and contribute to the development of next-generation foundation models for surgery.
Temporally Guided Articulated Hand Pose Tracking in Surgical Videos
Jan 12, 2021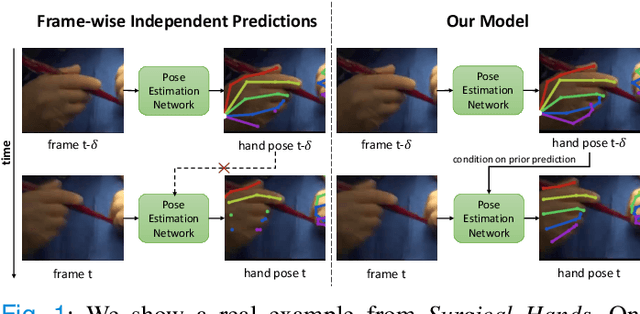
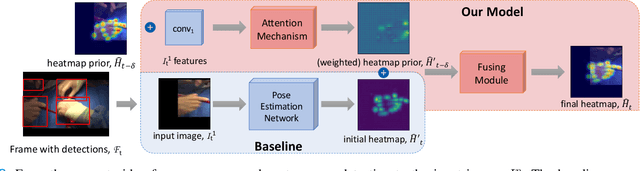
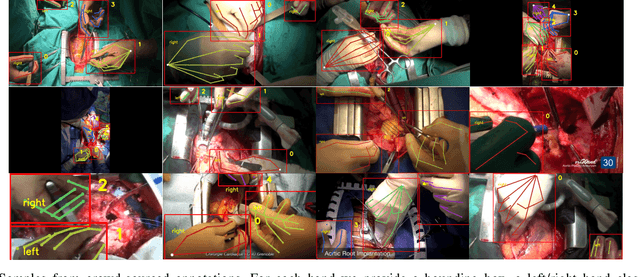
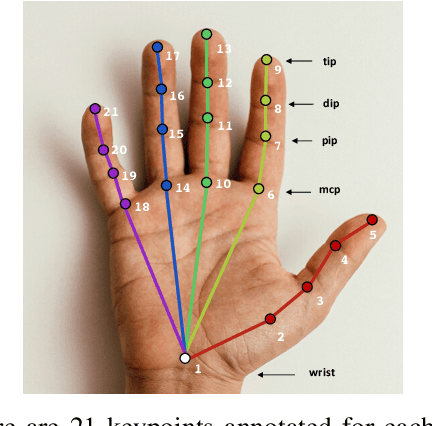
Articulated hand pose tracking is an underexplored problem that carries the potential for use in an extensive number of applications, especially in the medical domain. With a robust and accurate tracking system on in-vivo surgical videos, the motion dynamics and movement patterns of the hands can be captured and analyzed for rich tasks including skills assessment, training surgical residents, and temporal action recognition. In this work, we propose a novel hand pose estimation model, Res152- CondPose, which improves tracking accuracy by incorporating a hand pose prior into its pose prediction. We show improvements over state-of-the-art methods which provide frame-wise independent predictions, by following a temporally guided approach that effectively leverages past predictions. Additionally, we collect the first dataset, Surgical Hands, that provides multi-instance articulated hand pose annotations for in-vivo videos. Our dataset contains 76 video clips from 28 publicly available surgical videos and over 8.1k annotated hand pose instances. We provide bounding boxes, articulated hand pose annotations, and tracking IDs to enable multi-instance area-based and articulated tracking. When evaluated on Surgical Hands, we show our method outperforms the state-of-the-art method using mean Average Precision (mAP), to measure pose estimation accuracy, and Multiple Object Tracking Accuracy (MOTA), to assess pose tracking performance.