 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Sensitive Extended Kalman Filter
May 19, 2023



In robotics, designing robust algorithms in the face of estimation uncertainty is a challenging task. Indeed, controllers often do not consider the estimation uncertainty and only rely on the most likely estimated state. Consequently, sudden changes in the environment or the robot's dynamics can lead to catastrophic behaviors. In this work, we present a risk-sensitive Extended Kalman Filter that allows doing output-feedback Model Predictive Control (MPC) safely. This filter adapts its estimation to the control objective. By taking a pessimistic estimate concerning the value function resulting from the MPC controller, the filter provides increased robustness to the controller in phases of uncertainty as compared to a standard Extended Kalman Filter (EKF). Moreover, the filter has the same complexity as an EKF, so that it can be used for real-time model-predictive control. The paper evaluates the risk-sensitive behavior of the proposed filter when used in a nonlinear model-predictive control loop on a planar drone and industrial manipulator in simulation, as well as on an external force estimation task on a real quadruped robot. These experiments demonstrate the abilities of the approach to improve performance in the face of uncertainties significantly.
Path Planning Under Uncertainty to Localize mmWave Sources
Mar 08, 2023



In this paper, we study a navigation problem where a mobile robot needs to locate a mmWave wireless signal. Using the directionality properties of the signal, we propose an estimation and path planning algorithm that can efficiently navigate in cluttered indoor environments. We formulate Extended Kalman filters for emitter location estimation in cases where the signal is received in line-of-sight or after reflections. We then propose to plan motion trajectories based on belief-space dynamics in order to minimize the uncertainty of the position estimates. The associated non-linear optimization problem is solved by a state-of-the-art constrained iLQR solver. In particular, we propose a method that can handle a large number of obstacles (~300) with reasonable computation times. We validate the approach in an extensive set of simulations. We show that our estimators can help increase navigation success rate and that planning to reduce estimation uncertainty can improve the overall task completion speed.
Visual-Inertial and Leg Odometry Fusion for Dynamic Locomotion
Oct 10, 2022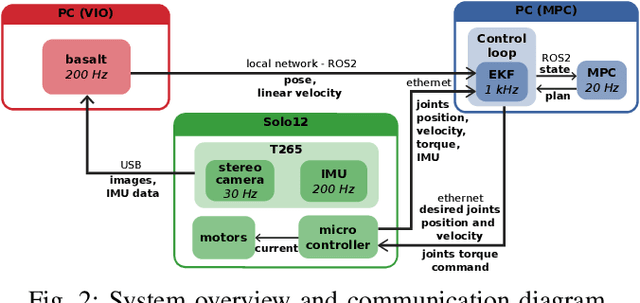
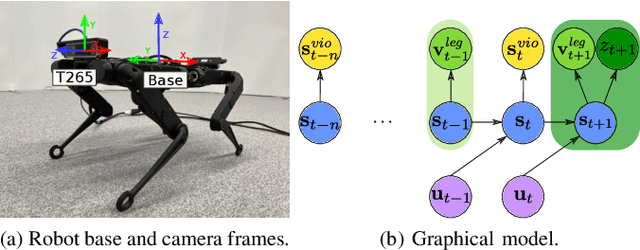
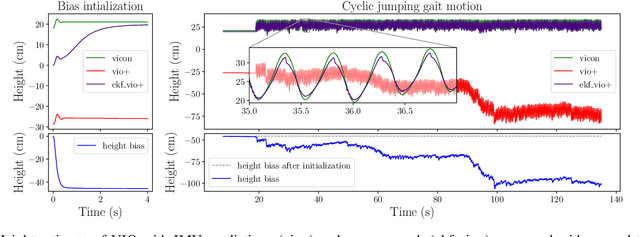
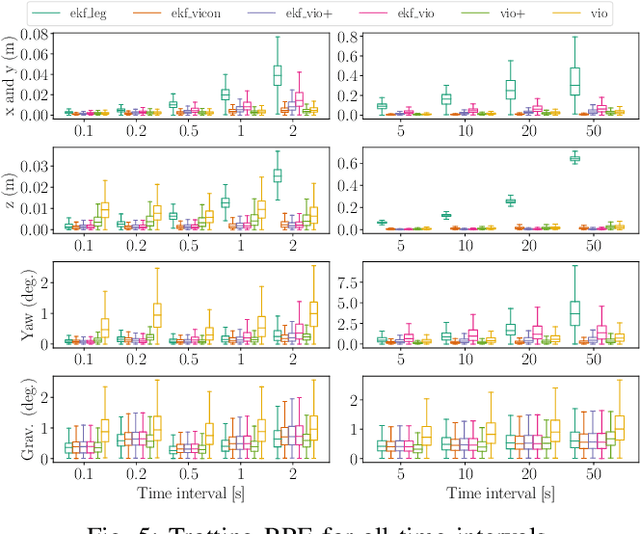
Implementing dynamic locomotion behaviors on legged robots requires a high-quality state estimation module. Especially when the motion includes flight phases, state-of-the-art approaches fail to produce reliable estimation of the robot posture, in particular base height. In this paper, we propose a novel approach for combining visual-inertial odometry (VIO) with leg odometry in an extended Kalman filter (EKF) based state estimator. The VIO module uses a stereo camera and IMU to yield low-drift 3D position and yaw orientation and drift-free pitch and roll orientation of the robot base link in the inertial frame. However, these values have a considerable amount of latency due to image processing and optimization, while the rate of update is quite low which is not suitable for low-level control. To reduce the latency, we predict the VIO state estimate at the rate of the IMU measurements of the VIO sensor. The EKF module uses the base pose and linear velocity predicted by VIO, fuses them further with a second high-rate IMU and leg odometry measurements, and produces robot state estimates with a high frequency and small latency suitable for control. We integrate this lightweight estimation framework with a nonlinear model predictive controller and show successful implementation of a set of agile locomotion behaviors, including trotting and jumping at varying horizontal speeds, on a torque-controlled quadruped robot.
ContactNet: Online Multi-Contact Planning for Acyclic Legged Robot Locomotion
Sep 30, 2022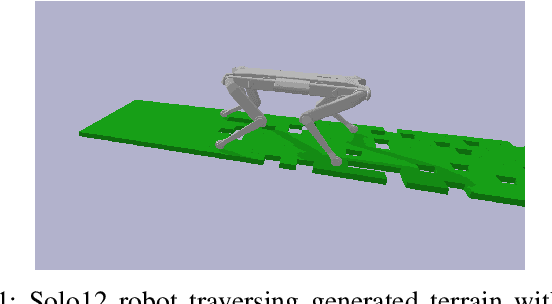

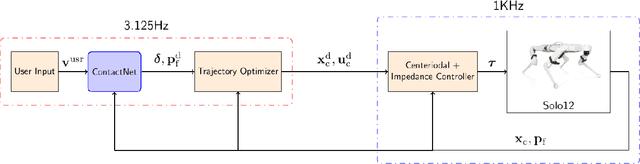
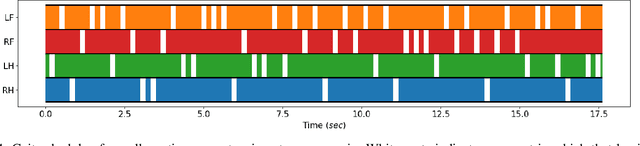
Online trajectory optimization techniques generally depend on heuristic-based contact planners in order to have low computation times and achieve high replanning frequencies. In this work, we propose ContactNet, a fast acyclic contact planner based on a multi-output regression neural network. ContactNet ranks discretized stepping regions, allowing to quickly choose the best feasible solution, even in complex environments. The low computation time, in the order of 1 ms, makes possible the execution of the contact planner concurrently with a trajectory optimizer in a Model Predictive Control (MPC) fashion. We demonstrate the effectiveness of the approach in simulation in different complex scenarios with the quadruped robot Solo12.
MPC with Sensor-Based Online Cost Adaptation
Sep 20, 2022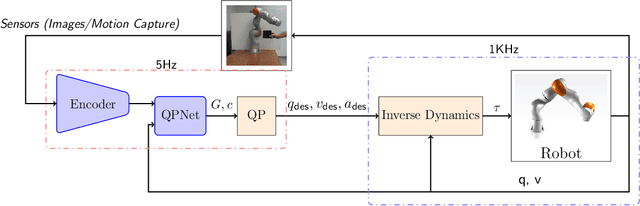
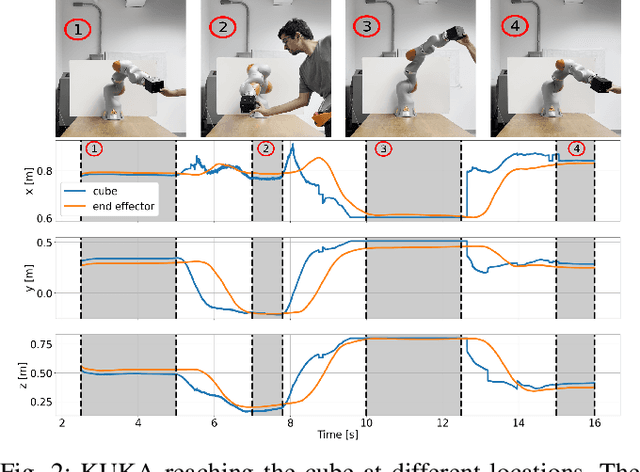


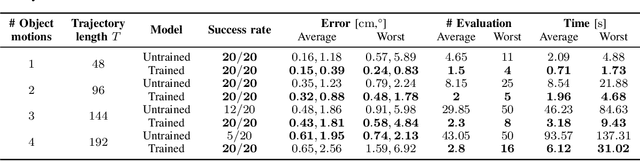
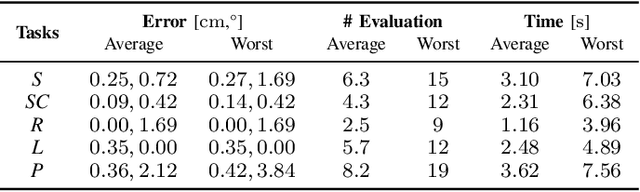
Model predictive control is a powerful tool to generate complex motions for robots. However, it often requires solving non-convex problems online to produce rich behaviors, which is computationally expensive and not always practical in real time. Additionally, direct integration of high dimensional sensor data (e.g. RGB-D images) in the feedback loop is challenging with current state-space methods. This paper aims to address both issues. It introduces a model predictive control scheme, where a neural network constantly updates the cost function of a quadratic program based on sensory inputs, aiming to minimize a general non-convex task loss without solving a non-convex problem online. By updating the cost, the robot is able to adapt to changes in the environment directly from sensor measurement without requiring a new cost design. Furthermore, since the quadratic program can be solved efficiently with hard constraints, a safe deployment on the robot is ensured. Experiments with a wide variety of reaching tasks on an industrial robot manipulator demonstrate that our method can efficiently solve complex non-convex problems with high-dimensional visual sensory inputs, while still being robust to external disturbances.
Efficient Object Manipulation Planning with Monte Carlo Tree Search
Jun 17, 2022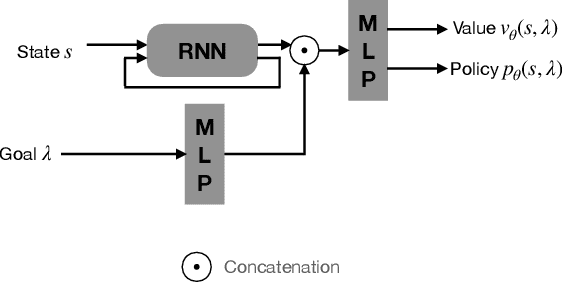

This paper presents an efficient approach to object manipulation planning using Monte Carlo Tree Search (MCTS) to find contact sequences and an efficient ADMM-based trajectory optimization algorithm to evaluate the dynamic feasibility of candidate contact sequences. To accelerate MCTS, we propose a methodology to learn a goal-conditioned policy-value network used to direct the search towards promising nodes. Further, manipulation-specific heuristics enable to drastically reduce the search space. Systematic object manipulation experiments in a physics simulator demonstrate the efficiency of our approach. In particular, our approach scales favorably for long manipulation sequences thanks to the learned policy-value network, significantly improving planning success rate.
Nonlinear Stochastic Trajectory Optimization for Centroidal Momentum Motion Generation of Legged Robots
May 26, 2022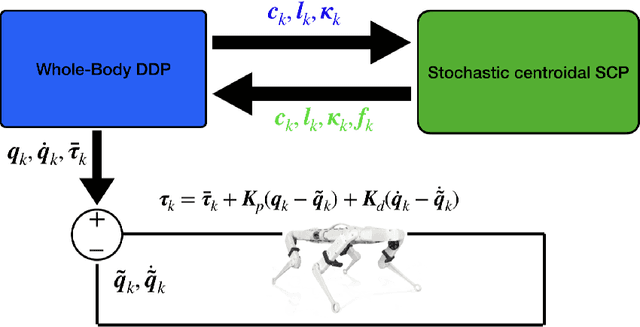
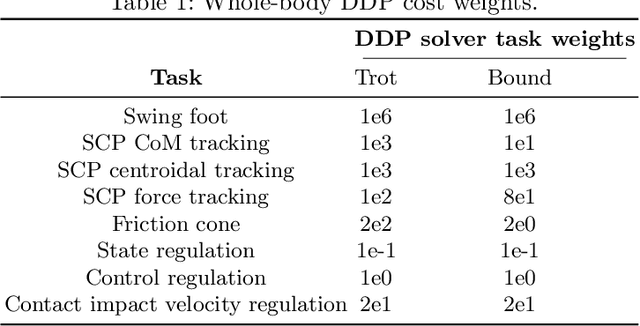


Generation of robust trajectories for legged robots remains a challenging task due to the underlying nonlinear, hybrid and intrinsically unstable dynamics which needs to be stabilized through limited contact forces. Furthermore, disturbances arising from unmodelled contact interactions with the environment and model mismatches can hinder the quality of the planned trajectories leading to unsafe motions. In this work, we propose to use stochastic trajectory optimization for generating robust centroidal momentum trajectories to account for additive uncertainties on the model dynamics and parametric uncertainties on contact locations. Through an alternation between the robust centroidal and whole-body trajectory optimizations, we generate robust momentum trajectories while being consistent with the whole-body dynamics. We perform an extensive set of simulations subject to different uncertainties on a quadruped robot showing that our stochastic trajectory optimization problem reduces the amount of foot slippage for different gaits while achieving better performance over deterministic planning.
Model Based Meta Learning of Critics for Policy Gradients
Apr 05, 2022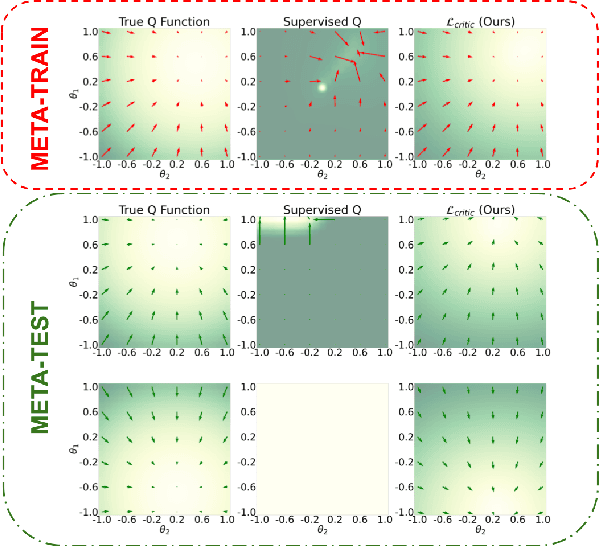
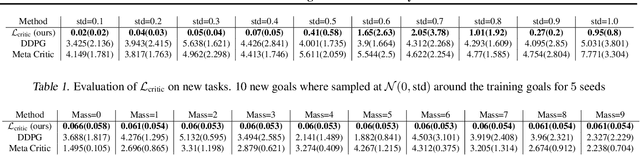
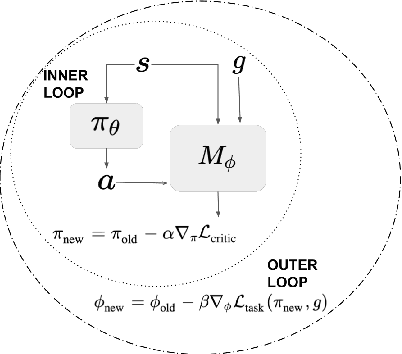
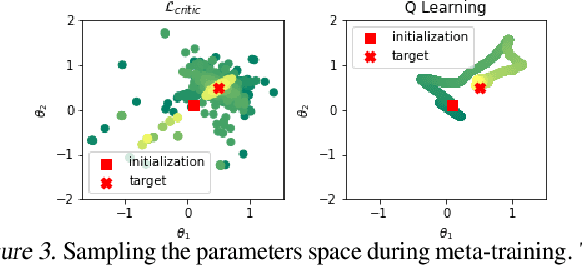
Being able to seamlessly generalize across different tasks is fundamental for robots to act in our world. However, learning representations that generalize quickly to new scenarios is still an open research problem in reinforcement learning. In this paper we present a framework to meta-learn the critic for gradient-based policy learning. Concretely, we propose a model-based bi-level optimization algorithm that updates the critics parameters such that the policy that is learned with the updated critic gets closer to solving the meta-training tasks. We illustrate that our algorithm leads to learned critics that resemble the ground truth Q function for a given task. Finally, after meta-training, the learned critic can be used to learn new policies for new unseen task and environment settings via model-free policy gradient optimization, without requiring a model. We present results that show the generalization capabilities of our learned critic to new tasks and dynamics when used to learn a new policy in a new scenario.
On the Use of Torque Measurement in Centroidal State Estimation
Feb 25, 2022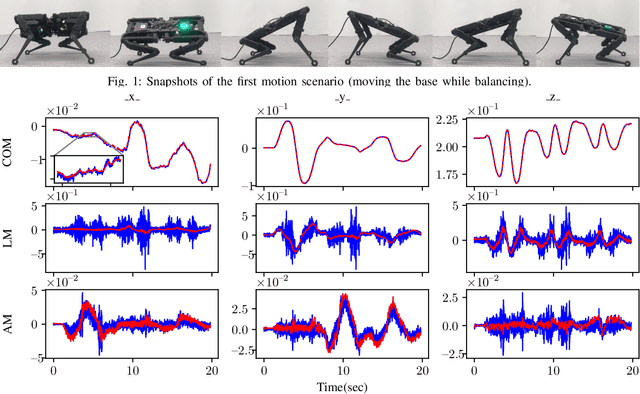
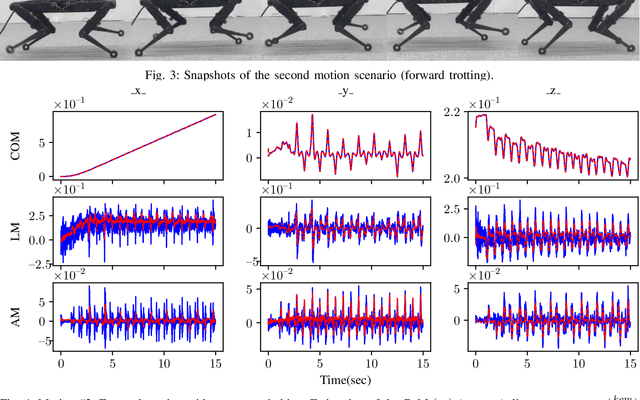
State of the art legged robots are either capable of measuring torque at the output of their drive systems, or have transparent drive systems which enable the computation of joint torques from motor currents. In either case, this sensor modality is seldom used in state estimation. In this paper, we propose to use joint torque measurements to estimate the centroidal states of legged robots. To do so, we project the whole-body dynamics of a legged robot into the nullspace of the contact constraints, allowing expression of the dynamics independent of the contact forces. Using the constrained dynamics and the centroidal momentum matrix, we are able to directly relate joint torques and centroidal states dynamics. Using the resulting model as the process model of an Extended Kalman Filter (EKF), we fuse the torque measurement in the centroidal state estimation problem. Through real-world experiments on a quadruped robot with different gaits, we demonstrate that the estimated centroidal states from our torque-based EKF drastically improve the estimation of these quantities compared to direct computation.
BiConMP: A Nonlinear Model Predictive Control Framework for Whole Body Motion Planning
Jan 19, 2022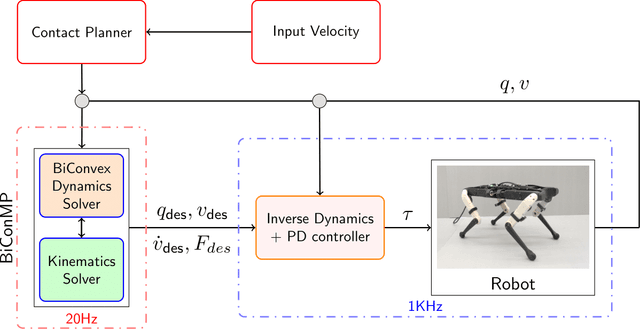
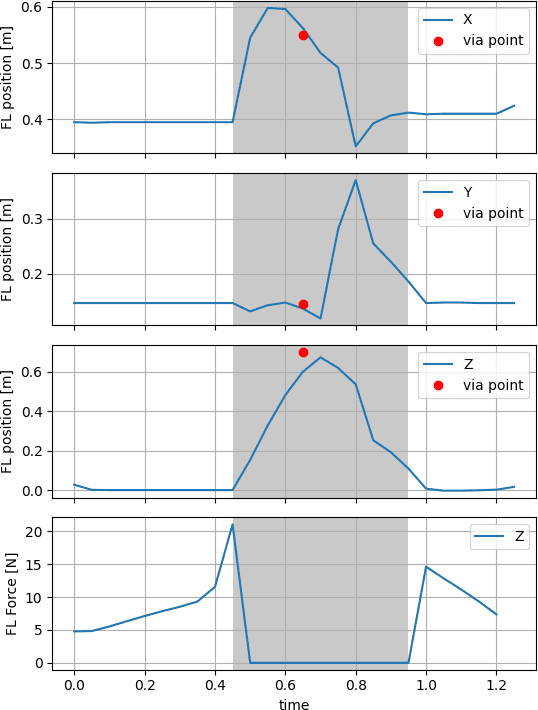
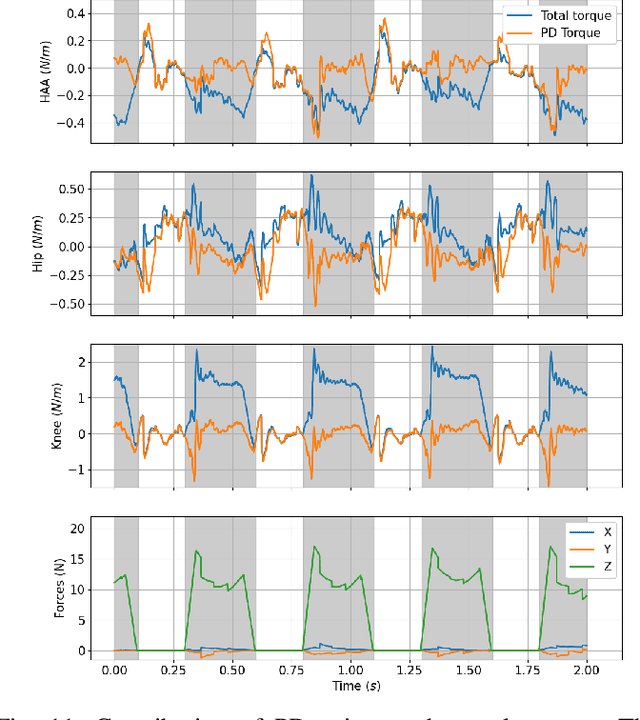
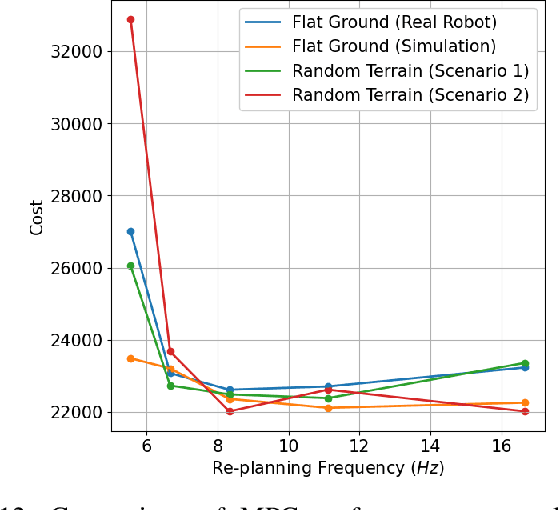
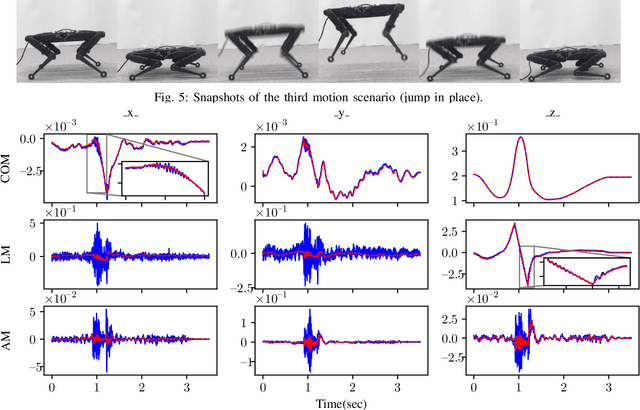
Online planning of whole-body motions for legged robots is challenging due to the inherent nonlinearity in the robot dynamics. In this work, we propose a nonlinear MPC framework, the BiConMP which can generate whole body trajectories online by efficiently exploiting the structure of the robot dynamics. BiConMP is used to generate various cyclic gaits on a real quadruped robot and its performance is evaluated on different terrain, countering unforeseen pushes and transitioning online between different gaits. Further, the ability of BiConMP to generate non-trivial acyclic whole-body dynamic motions on the robot is presented. Finally, an extensive empirical analysis on the effects of planning horizon and frequency on the nonlinear MPC framework is reported and discussed.