 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLowRL: Safe Low-Rank Adaptation Reinforcement Learning for Locomotion
Mar 17, 2026Sim-to-real transfer of locomotion policies often leads to performance degradation due to the inevitable sim-to-real gap. Naively fine-tuning these policies directly on hardware is problematic, as it poses risks of mechanical failure and suffers from high sample inefficiency. In this paper, we address the challenge of safely and efficiently fine-tuning reinforcement learning (RL) policies for dynamic locomotion tasks. Specifically, we focus on fine-tuning policies learned in simulation directly on hardware, while explicitly enforcing safety constraints. In doing so, we introduce SLowRL, a framework that combines Low-Rank Adaptation (LoRA) with training-time safety enforcement via a recovery policy. We evaluate our method both in simulation and on a real Unitree Go2 quadruped robot for jump and trot tasks. Experimental results show that our method achieves a $46.5\%$ reduction in fine-tuning time and near-zero safety violations compared to standard proximal policy optimization (PPO) baselines. Notably, we find that a rank-1 adaptation alone is sufficient to recover pre-trained performance in the real world, while maintaining stable and safe real-world fine-tuning. These results demonstrate the practicality of safe, efficient fine-tuning for dynamic real-world robotic applications.
A unified framework for walking and running of bipedal robots
Oct 18, 2021
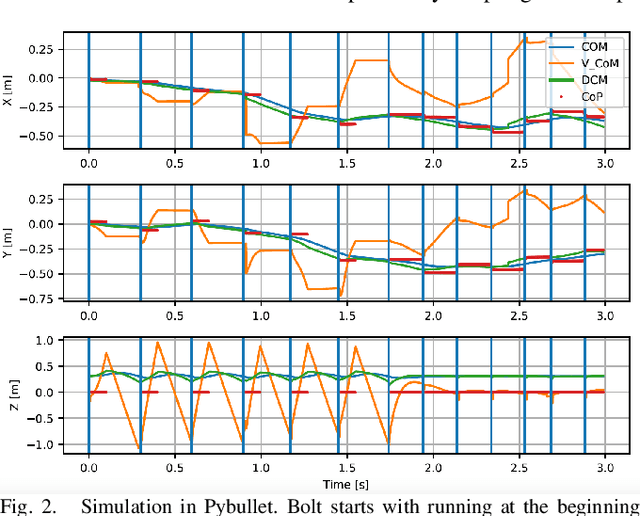
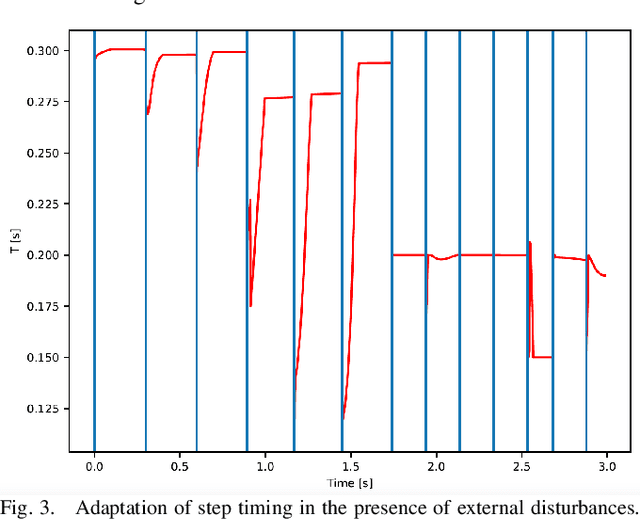
In this paper, we propose a novel framework capable of generating various walking and running gaits for bipedal robots. The main goal is to relax the fixed center of mass (CoM) height assumption of the linear inverted pendulum model (LIPM) and generate a wider range of walking and running motions, without a considerable increase in complexity. To do so, we use the concept of virtual constraints in the centroidal space which enables generating motions beyond walking while keeping the complexity at a minimum. By a proper choice of these virtual constraints, we show that we can generate different types of walking and running motions. More importantly, enforcing the virtual constraints through feedback renders the dynamics linear and enables us to design a feedback control mechanism which adapts the next step location and timing in face of disturbances, through a simple quadratic program (QP). To show the effectiveness of this framework, we showcase different walking and running simulations of the biped robot Bolt in the presence of both environmental uncertainties and external disturbances.
Bipedal Walking Control using Variable Horizon MPC
Oct 16, 2020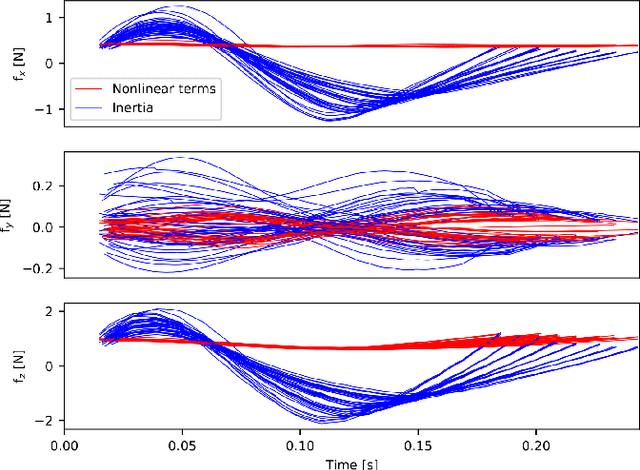
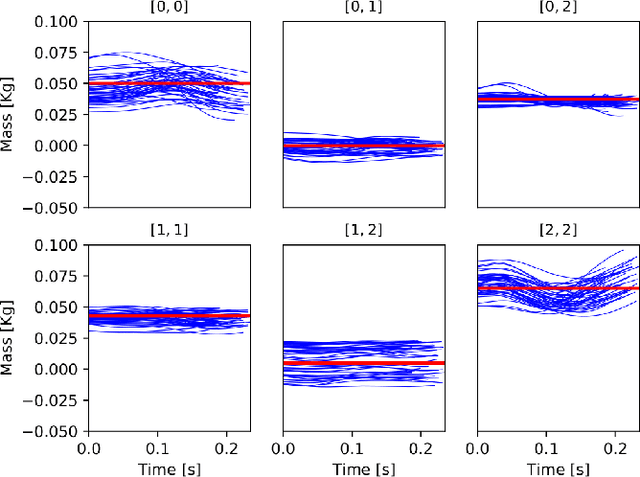
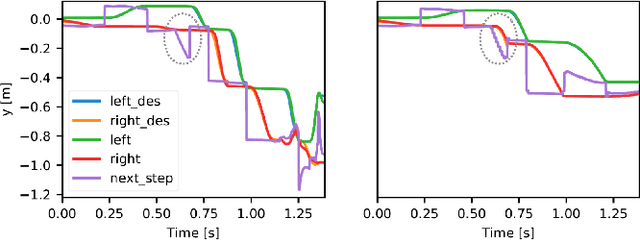
In this paper, we present a novel two-level variable Horizon Model Predictive Control (VH-MPC) framework for bipedal locomotion. In this framework, the higher level computes the landing location and timing (horizon length) of the swing foot to stabilize the unstable part of the center of mass (CoM) dynamics, using feedback from the CoM state. The lower level takes into account the swing foot dynamics and generates dynamically consistent trajectories for landing at the desired time as close as possible to the desired location. To do that, we use a simplified model of the robot dynamics projected in swing foot space that takes into account joint torque constraints as well as the friction cone constraints of the stance foot. We show the effectiveness of our proposed control framework by implementing robust walking patterns on our torque-controlled and open-source biped robot, Bolt. We report extensive simulations and real robot experiments in the presence of various disturbances and uncertainties.