 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Combining Entity Resolution and Query Answering in Knowledge Bases
Mar 13, 2023We propose a new framework for combining entity resolution and query answering in knowledge bases (KBs) with tuple-generating dependencies (tgds) and equality-generating dependencies (egds) as rules. We define the semantics of the KB in terms of special instances that involve equivalence classes of entities and sets of values. Intuitively, the former collect all entities denoting the same real-world object, while the latter collect all alternative values for an attribute. This approach allows us to both resolve entities and bypass possible inconsistencies in the data. We then design a chase procedure that is tailored to this new framework and has the feature that it never fails; moreover, when the chase procedure terminates, it produces a universal solution, which in turn can be used to obtain the certain answers to conjunctive queries. We finally discuss challenges arising when the chase does not terminate.
MILO: Model-Agnostic Subset Selection Framework for Efficient Model Training and Tuning
Feb 05, 2023



Training deep networks and tuning hyperparameters on large datasets is computationally intensive. One of the primary research directions for efficient training is to reduce training costs by selecting well-generalizable subsets of training data. Compared to simple adaptive random subset selection baselines, existing intelligent subset selection approaches are not competitive due to the time-consuming subset selection step, which involves computing model-dependent gradients and feature embeddings and applies greedy maximization of submodular objectives. Our key insight is that removing the reliance on downstream model parameters enables subset selection as a pre-processing step and enables one to train multiple models at no additional cost. In this work, we propose MILO, a model-agnostic subset selection framework that decouples the subset selection from model training while enabling superior model convergence and performance by using an easy-to-hard curriculum. Our empirical results indicate that MILO can train models $3\times - 10 \times$ faster and tune hyperparameters $20\times - 75 \times$ faster than full-dataset training or tuning without compromising performance.
Entity Set Co-Expansion in StackOverflow
Dec 05, 2022


Given a few seed entities of a certain type (e.g., Software or Programming Language), entity set expansion aims to discover an extensive set of entities that share the same type as the seeds. Entity set expansion in software-related domains such as StackOverflow can benefit many downstream tasks (e.g., software knowledge graph construction) and facilitate better IT operations and service management. Meanwhile, existing approaches are less concerned with two problems: (1) How to deal with multiple types of seed entities simultaneously? (2) How to leverage the power of pre-trained language models (PLMs)? Being aware of these two problems, in this paper, we study the entity set co-expansion task in StackOverflow, which extracts Library, OS, Application, and Language entities from StackOverflow question-answer threads. During the co-expansion process, we use PLMs to derive embeddings of candidate entities for calculating similarities between entities. Experimental results show that our proposed SECoExpan framework outperforms previous approaches significantly.
Domain Representative Keywords Selection: A Probabilistic Approach
Mar 19, 2022
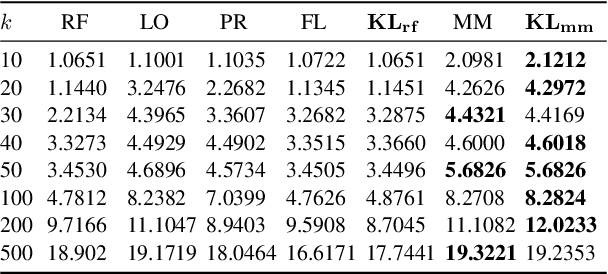
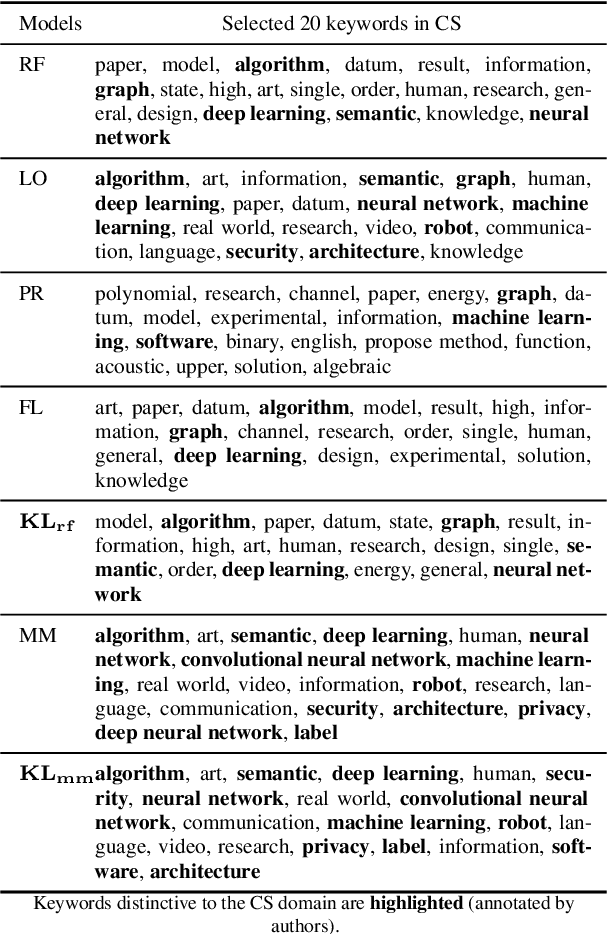
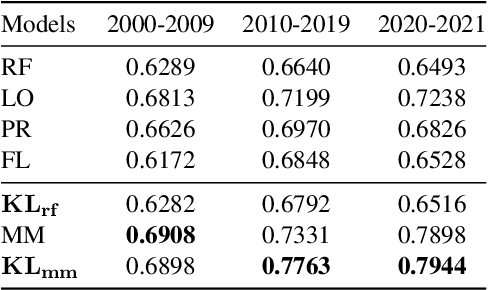
We propose a probabilistic approach to select a subset of a \textit{target domain representative keywords} from a candidate set, contrasting with a context domain. Such a task is crucial for many downstream tasks in natural language processing. To contrast the target domain and the context domain, we adapt the \textit{two-component mixture model} concept to generate a distribution of candidate keywords. It provides more importance to the \textit{distinctive} keywords of the target domain than common keywords contrasting with the context domain. To support the \textit{representativeness} of the selected keywords towards the target domain, we introduce an \textit{optimization algorithm} for selecting the subset from the generated candidate distribution. We have shown that the optimization algorithm can be efficiently implemented with a near-optimal approximation guarantee. Finally, extensive experiments on multiple domains demonstrate the superiority of our approach over other baselines for the tasks of keyword summary generation and trending keywords selection.
AUTOMATA: Gradient Based Data Subset Selection for Compute-Efficient Hyper-parameter Tuning
Mar 15, 2022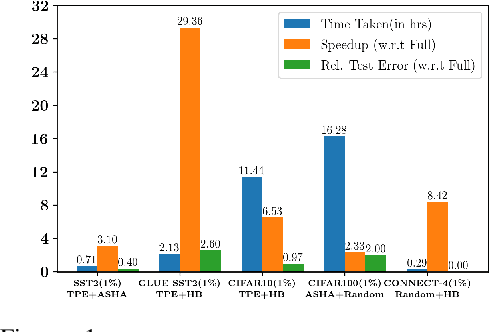


Deep neural networks have seen great success in recent years; however, training a deep model is often challenging as its performance heavily depends on the hyper-parameters used. In addition, finding the optimal hyper-parameter configuration, even with state-of-the-art (SOTA) hyper-parameter optimization (HPO) algorithms, can be time-consuming, requiring multiple training runs over the entire dataset for different possible sets of hyper-parameters. Our central insight is that using an informative subset of the dataset for model training runs involved in hyper-parameter optimization, allows us to find the optimal hyper-parameter configuration significantly faster. In this work, we propose AUTOMATA, a gradient-based subset selection framework for hyper-parameter tuning. We empirically evaluate the effectiveness of AUTOMATA in hyper-parameter tuning through several experiments on real-world datasets in the text, vision, and tabular domains. Our experiments show that using gradient-based data subsets for hyper-parameter tuning achieves significantly faster turnaround times and speedups of 3$\times$-30$\times$ while achieving comparable performance to the hyper-parameters found using the entire dataset.
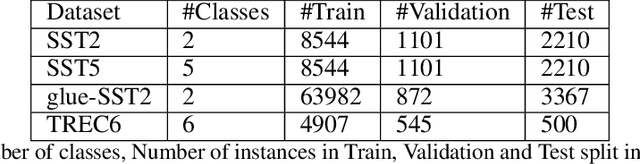
Learning to Robustly Aggregate Labeling Functions for Semi-supervised Data Programming
Sep 23, 2021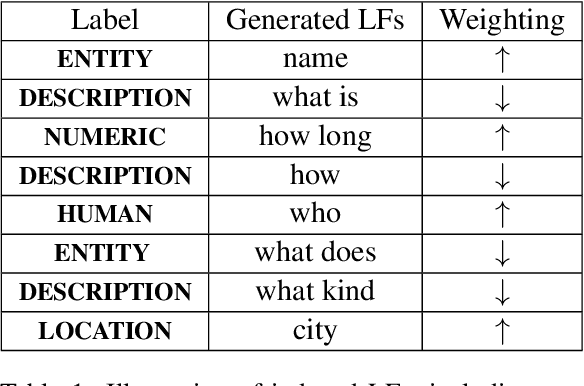
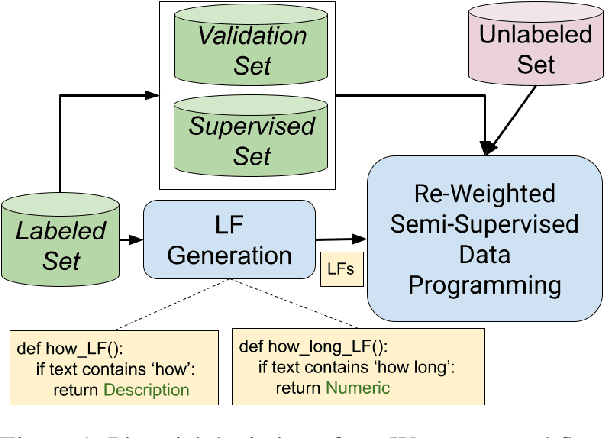
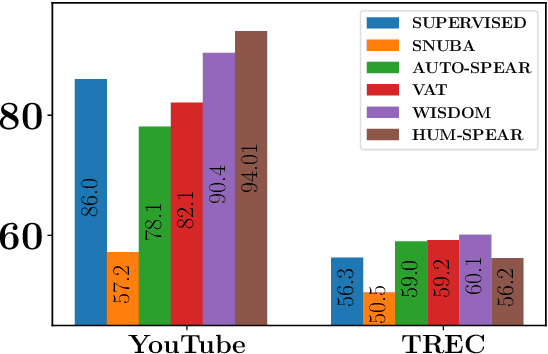
A critical bottleneck in supervised machine learning is the need for large amounts of labeled data which is expensive and time consuming to obtain. However, it has been shown that a small amount of labeled data, while insufficient to re-train a model, can be effectively used to generate human-interpretable labeling functions (LFs). These LFs, in turn, have been used to generate a large amount of additional noisy labeled data, in a paradigm that is now commonly referred to as data programming. However, previous approaches to automatically generate LFs make no attempt to further use the given labeled data for model training, thus giving up opportunities for improved performance. Moreover, since the LFs are generated from a relatively small labeled dataset, they are prone to being noisy, and naively aggregating these LFs can lead to very poor performance in practice. In this work, we propose an LF based reweighting framework \ouralgo{} to solve these two critical limitations. Our algorithm learns a joint model on the (same) labeled dataset used for LF induction along with any unlabeled data in a semi-supervised manner, and more critically, reweighs each LF according to its goodness, influencing its contribution to the semi-supervised loss using a robust bi-level optimization algorithm. We show that our algorithm significantly outperforms prior approaches on several text classification datasets.
LNN-EL: A Neuro-Symbolic Approach to Short-text Entity Linking
Jun 17, 2021
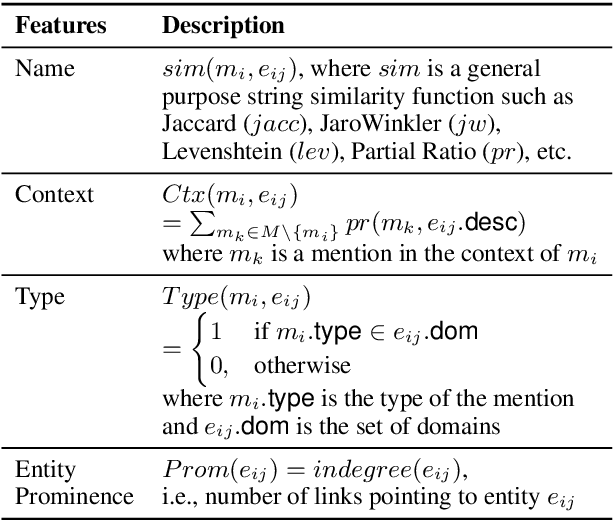
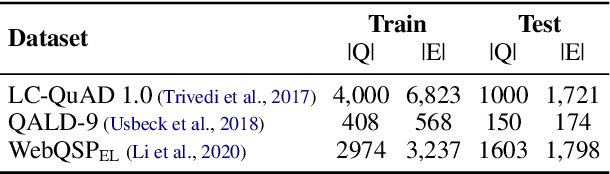
Entity linking (EL), the task of disambiguating mentions in text by linking them to entities in a knowledge graph, is crucial for text understanding, question answering or conversational systems. Entity linking on short text (e.g., single sentence or question) poses particular challenges due to limited context. While prior approaches use either heuristics or black-box neural methods, here we propose LNN-EL, a neuro-symbolic approach that combines the advantages of using interpretable rules based on first-order logic with the performance of neural learning. Even though constrained to using rules, LNN-EL performs competitively against SotA black-box neural approaches, with the added benefits of extensibility and transferability. In particular, we show that we can easily blend existing rule templates given by a human expert, with multiple types of features (priors, BERT encodings, box embeddings, etc), and even scores resulting from previous EL methods, thus improving on such methods. For instance, on the LC-QuAD-1.0 dataset, we show more than $4$\% increase in F1 score over previous SotA. Finally, we show that the inductive bias offered by using logic results in learned rules that transfer well across datasets, even without fine tuning, while maintaining high accuracy.
Question Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020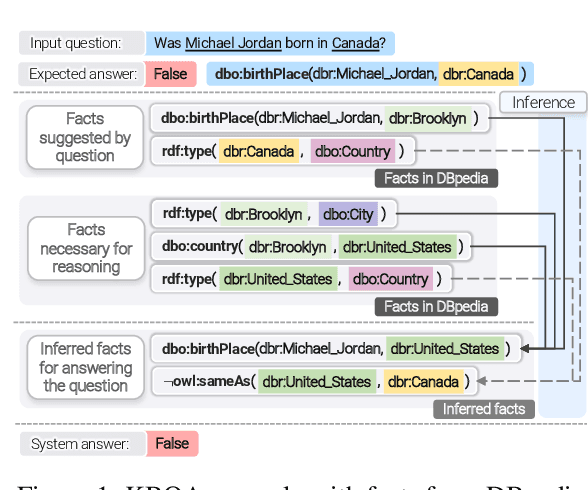
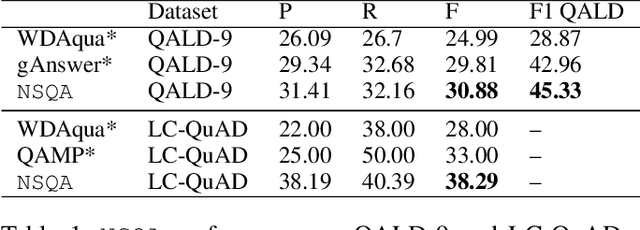
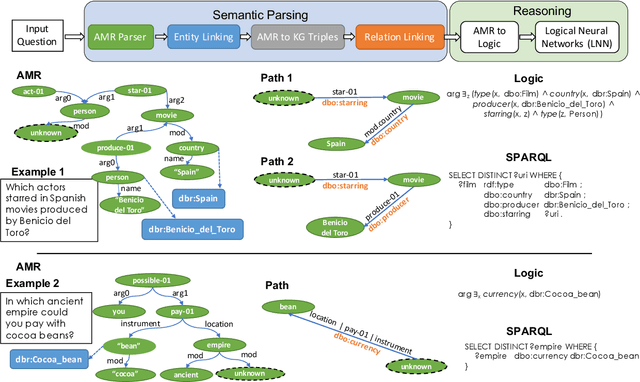

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
Learning Structured Representations of Entity Names using Active Learning and Weak Supervision
Oct 30, 2020
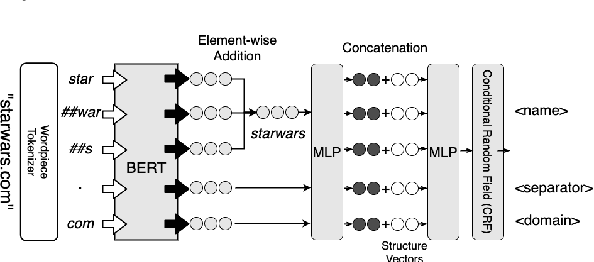

Structured representations of entity names are useful for many entity-related tasks such as entity normalization and variant generation. Learning the implicit structured representations of entity names without context and external knowledge is particularly challenging. In this paper, we present a novel learning framework that combines active learning and weak supervision to solve this problem. Our experimental evaluation show that this framework enables the learning of high-quality models from merely a dozen or so labeled examples.
Global Table Extractor : A Framework for Joint Table Identification and Cell Structure Recognition Using Visual Context
May 01, 2020
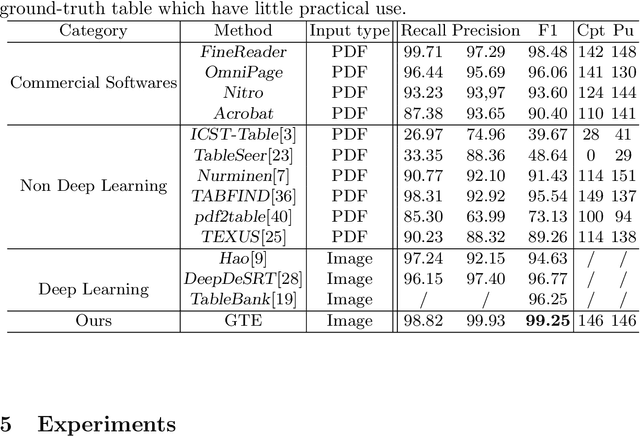
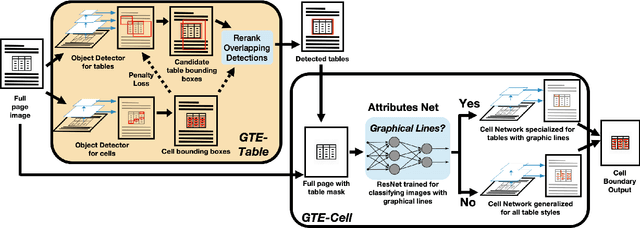

Documents are often the format of choice for knowledge sharing and preservation in business and science. Much of the critical data are captured in tables. Unfortunately, most documents are stored and distributed in PDF or scanned images, which fail to preserve table formatting. Recent vision-based deep learning approaches have been proposed to address this gap, but most still cannot achieve state-of-the-art results. We present Global Table Extractor (GTE), a vision-guided systematic framework for joint table detection and cell structured recognition, which could be built on top of any object detection model. With GTE-Table, we invent a new penalty based on the natural cell containment constraint of tables to train our table network aided by cell location predictions. GTE-Cell is a new hierarchical cell detection network that leverages table styles. Further, we design a method to automatically label table and cell structure in existing documents to cheaply create a large corpus of training and test data. We use this to create SD-tables and SEC-tables, real world and complex scientific and financial datasets with detailed table structure annotations to help train and test structure recognition. Our deep learning framework surpasses previous state-of-the-art results on the ICDAR 2013 table competition test dataset in both table detection and cell structure recognition, with a significant 6.8% improvement in the full table extraction system. We also show more than 30% improvement in cell structure recognition F1-score when compared to a vanilla RetinaNet object detection model in our out-of-domain financial dataset (SEC-Tables).