 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Linear Coregionalization for Realistic Synthetic Multivariate Time Series
Apr 06, 2026Synthetic data is essential for training foundation models for time series (FMTS), but most generators assume static correlations, and are typically missing realistic inter-channel dependencies. We introduce DynLMC, a Dynamic Linear Model of Coregionalization, that incorporates time-varying, regime-switching correlations and cross-channel lag structures. Our approach produces synthetic multivariate time series with correlation dynamics that closely resemble real data. Fine-tuning three foundational models on DynLMC-generated data yields consistent zero-shot forecasting improvements across nine benchmarks. Our results demonstrate that modeling dynamic inter-channel correlations enhances FMTS transferability, highlighting the importance of data-centric pretraining.
HOSL: Hybrid-Order Split Learning for Memory-Constrained Edge Training
Jan 16, 2026Split learning (SL) enables collaborative training of large language models (LLMs) between resource-constrained edge devices and compute-rich servers by partitioning model computation across the network boundary. However, existing SL systems predominantly rely on first-order (FO) optimization, which requires clients to store intermediate quantities such as activations for backpropagation. This results in substantial memory overhead, largely negating benefits of model partitioning. In contrast, zeroth-order (ZO) optimization eliminates backpropagation and significantly reduces memory usage, but often suffers from slow convergence and degraded performance. In this work, we propose HOSL, a novel Hybrid-Order Split Learning framework that addresses this fundamental trade-off between memory efficiency and optimization effectiveness by strategically integrating ZO optimization on the client side with FO optimization on the server side. By employing memory-efficient ZO gradient estimation at the client, HOSL eliminates backpropagation and activation storage, reducing client memory consumption. Meanwhile, server-side FO optimization ensures fast convergence and competitive performance. Theoretically, we show that HOSL achieves a $\mathcal{O}(\sqrt{d_c/TQ})$ rate, which depends on client-side model dimension $d_c$ rather than the full model dimension $d$, demonstrating that convergence improves as more computation is offloaded to the server. Extensive experiments on OPT models (125M and 1.3B parameters) across 6 tasks demonstrate that HOSL reduces client GPU memory by up to 3.7$\times$ compared to the FO method while achieving accuracy within 0.20%-4.23% of this baseline. Furthermore, HOSL outperforms the ZO baseline by up to 15.55%, validating the effectiveness of our hybrid strategy for memory-efficient training on edge devices.
AUTOMATA: Gradient Based Data Subset Selection for Compute-Efficient Hyper-parameter Tuning
Mar 15, 2022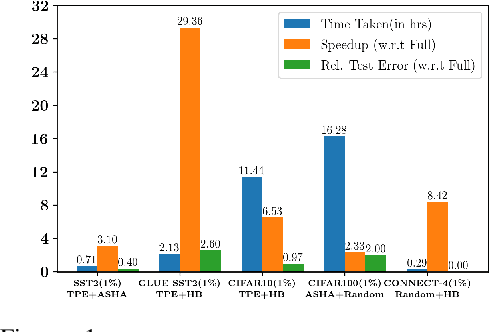
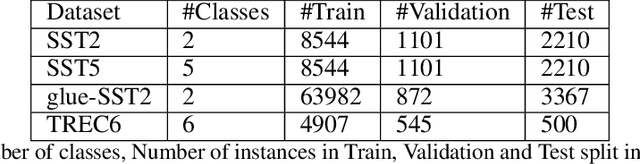


Deep neural networks have seen great success in recent years; however, training a deep model is often challenging as its performance heavily depends on the hyper-parameters used. In addition, finding the optimal hyper-parameter configuration, even with state-of-the-art (SOTA) hyper-parameter optimization (HPO) algorithms, can be time-consuming, requiring multiple training runs over the entire dataset for different possible sets of hyper-parameters. Our central insight is that using an informative subset of the dataset for model training runs involved in hyper-parameter optimization, allows us to find the optimal hyper-parameter configuration significantly faster. In this work, we propose AUTOMATA, a gradient-based subset selection framework for hyper-parameter tuning. We empirically evaluate the effectiveness of AUTOMATA in hyper-parameter tuning through several experiments on real-world datasets in the text, vision, and tabular domains. Our experiments show that using gradient-based data subsets for hyper-parameter tuning achieves significantly faster turnaround times and speedups of 3$\times$-30$\times$ while achieving comparable performance to the hyper-parameters found using the entire dataset.