 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Variable Models for Visual Question Answering
Jan 16, 2021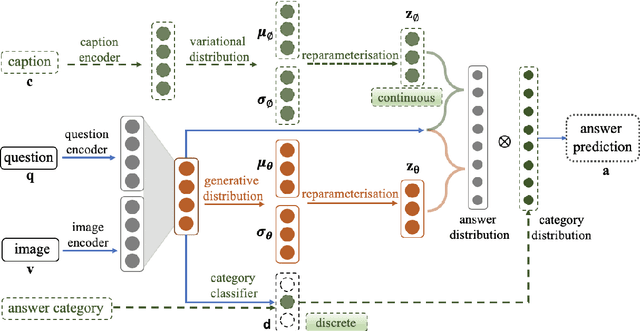
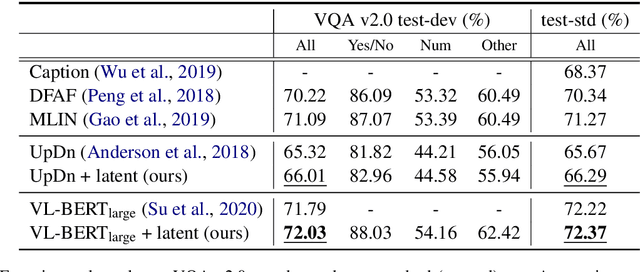

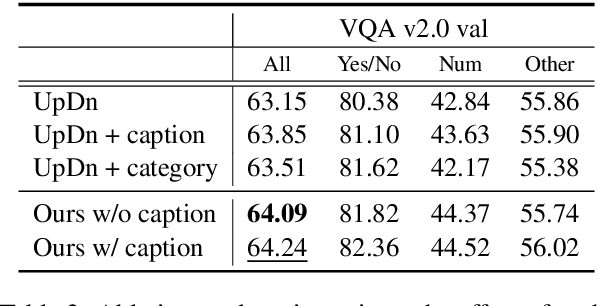
Conventional models for Visual Question Answering (VQA) explore deterministic approaches with various types of image features, question features, and attention mechanisms. However, there exist other modalities that can be explored in addition to image and question pairs to bring extra information to the models. In this work, we propose latent variable models for VQA where extra information (e.g. captions and answer categories) are incorporated as latent variables to improve inference, which in turn benefits question-answering performance. Experiments on the VQA v2.0 benchmarking dataset demonstrate the effectiveness of our proposed models in that they improve over strong baselines, especially those that do not rely on extensive language-vision pre-training.
MSVD-Turkish: A Comprehensive Multimodal Dataset for Integrated Vision and Language Research in Turkish
Dec 13, 2020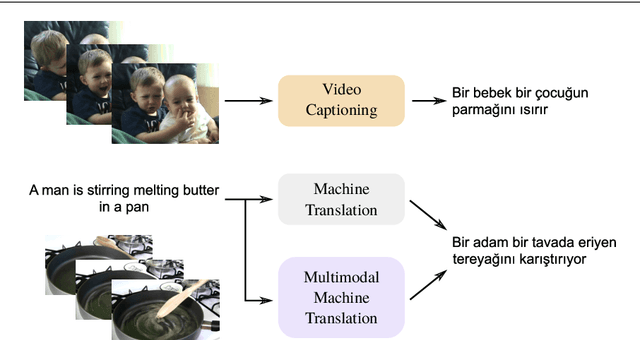
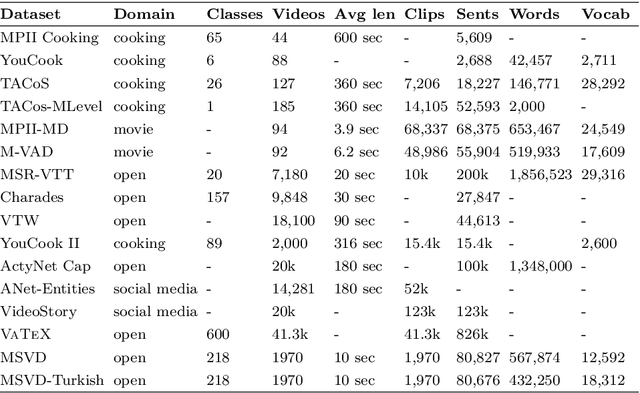
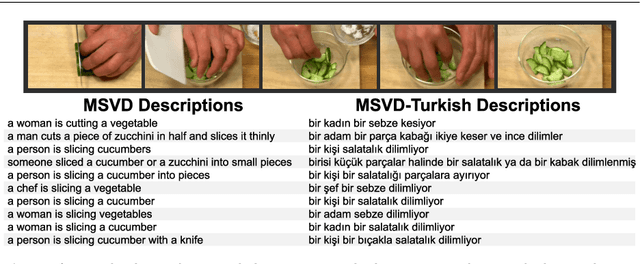

Automatic generation of video descriptions in natural language, also called video captioning, aims to understand the visual content of the video and produce a natural language sentence depicting the objects and actions in the scene. This challenging integrated vision and language problem, however, has been predominantly addressed for English. The lack of data and the linguistic properties of other languages limit the success of existing approaches for such languages. In this paper we target Turkish, a morphologically rich and agglutinative language that has very different properties compared to English. To do so, we create the first large scale video captioning dataset for this language by carefully translating the English descriptions of the videos in the MSVD (Microsoft Research Video Description Corpus) dataset into Turkish. In addition to enabling research in video captioning in Turkish, the parallel English-Turkish descriptions also enables the study of the role of video context in (multimodal) machine translation. In our experiments, we build models for both video captioning and multimodal machine translation and investigate the effect of different word segmentation approaches and different neural architectures to better address the properties of Turkish. We hope that the MSVD-Turkish dataset and the results reported in this work will lead to better video captioning and multimodal machine translation models for Turkish and other morphology rich and agglutinative languages.
Watch and Learn: Mapping Language and Noisy Real-world Videos with Self-supervision
Nov 19, 2020
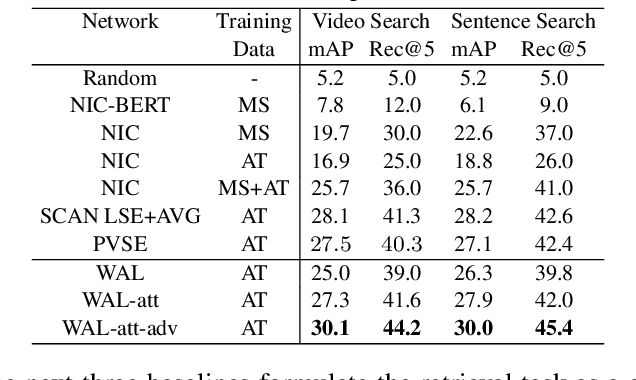
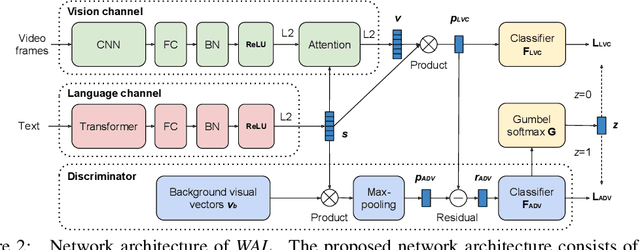
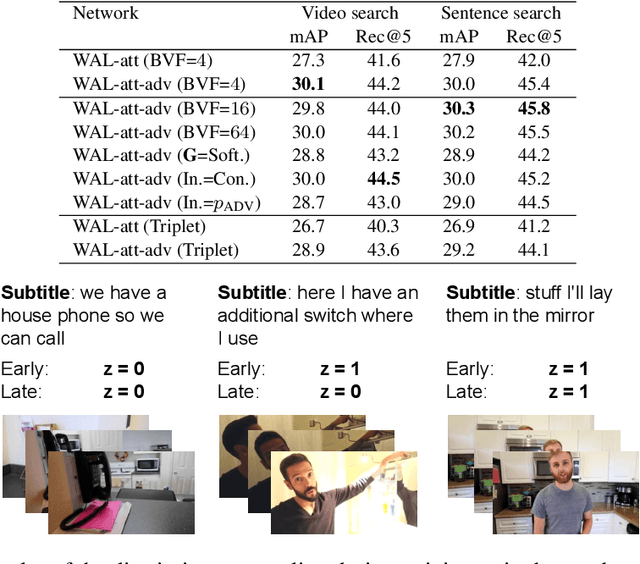
In this paper, we teach machines to understand visuals and natural language by learning the mapping between sentences and noisy video snippets without explicit annotations. Firstly, we define a self-supervised learning framework that captures the cross-modal information. A novel adversarial learning module is then introduced to explicitly handle the noises in the natural videos, where the subtitle sentences are not guaranteed to be strongly corresponded to the video snippets. For training and evaluation, we contribute a new dataset `ApartmenTour' that contains a large number of online videos and subtitles. We carry out experiments on the bidirectional retrieval tasks between sentences and videos, and the results demonstrate that our proposed model achieves the state-of-the-art performance on both retrieval tasks and exceeds several strong baselines. The dataset will be released soon.
Curious Case of Language Generation Evaluation Metrics: A Cautionary Tale
Oct 26, 2020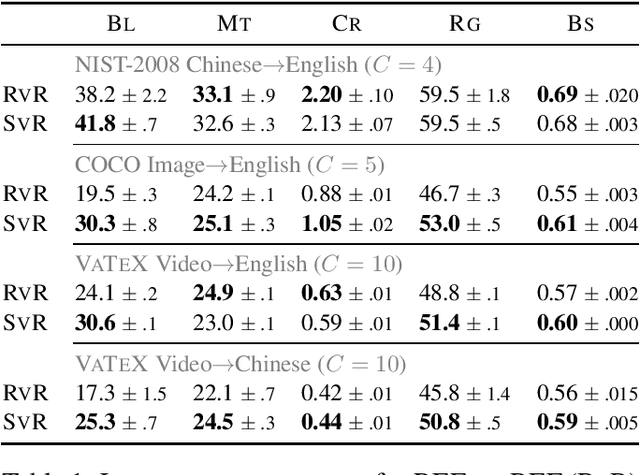
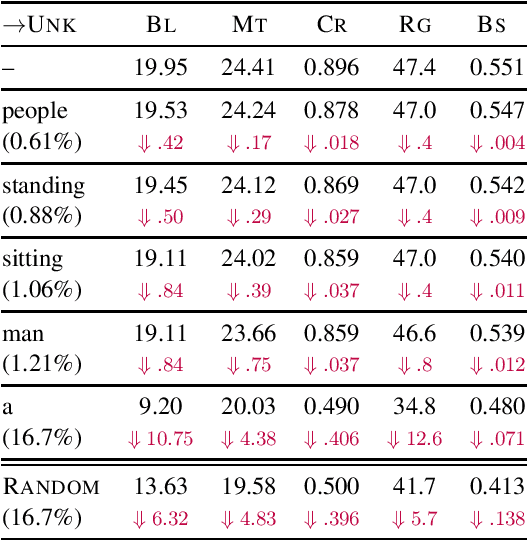
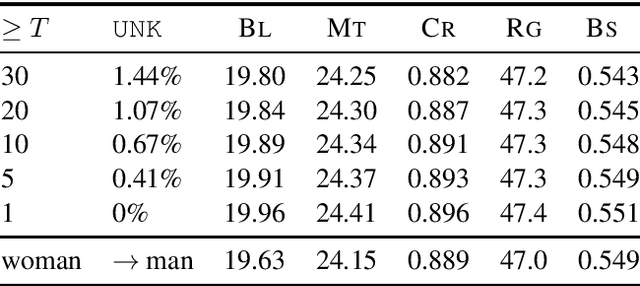
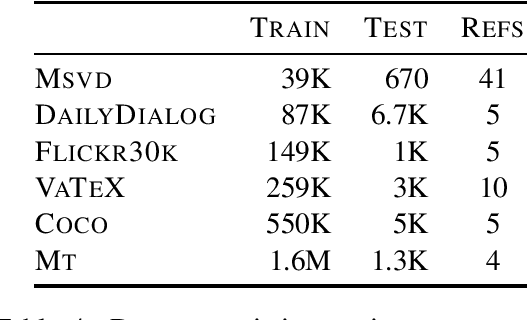
Automatic evaluation of language generation systems is a well-studied problem in Natural Language Processing. While novel metrics are proposed every year, a few popular metrics remain as the de facto metrics to evaluate tasks such as image captioning and machine translation, despite their known limitations. This is partly due to ease of use, and partly because researchers expect to see them and know how to interpret them. In this paper, we urge the community for more careful consideration of how they automatically evaluate their models by demonstrating important failure cases on multiple datasets, language pairs and tasks. Our experiments show that metrics (i) usually prefer system outputs to human-authored texts, (ii) can be insensitive to correct translations of rare words, (iii) can yield surprisingly high scores when given a single sentence as system output for the entire test set.
Simultaneous Machine Translation with Visual Context
Oct 13, 2020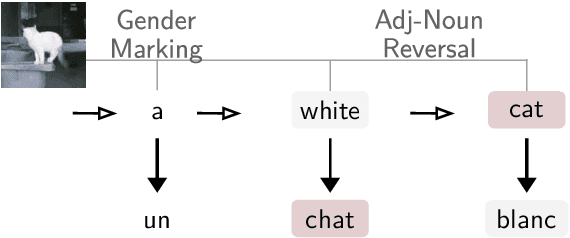
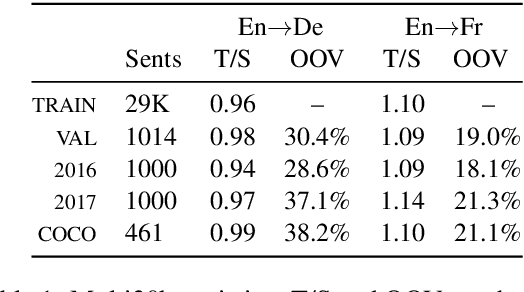
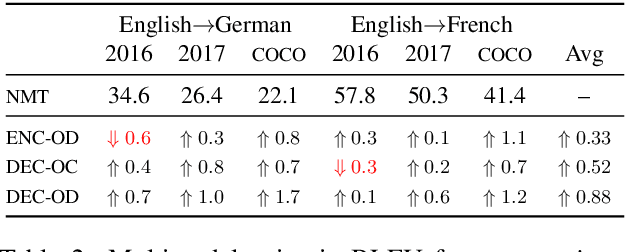
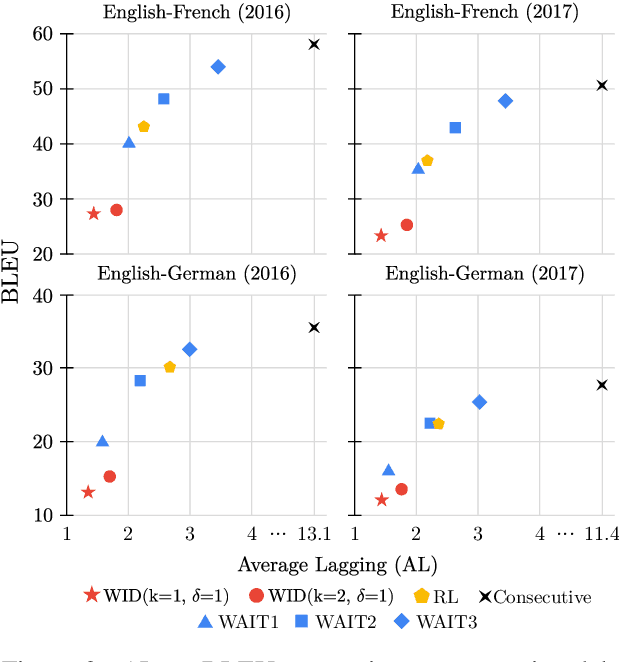
Simultaneous machine translation (SiMT) aims to translate a continuous input text stream into another language with the lowest latency and highest quality possible. The translation thus has to start with an incomplete source text, which is read progressively, creating the need for anticipation. In this paper, we seek to understand whether the addition of visual information can compensate for the missing source context. To this end, we analyse the impact of different multimodal approaches and visual features on state-of-the-art SiMT frameworks. Our results show that visual context is helpful and that visually-grounded models based on explicit object region information are much better than commonly used global features, reaching up to 3 BLEU points improvement under low latency scenarios. Our qualitative analysis illustrates cases where only the multimodal systems are able to translate correctly from English into gender-marked languages, as well as deal with differences in word order, such as adjective-noun placement between English and French.
FIND: Human-in-the-Loop Debugging Deep Text Classifiers
Oct 10, 2020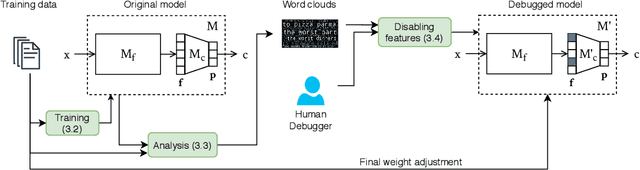
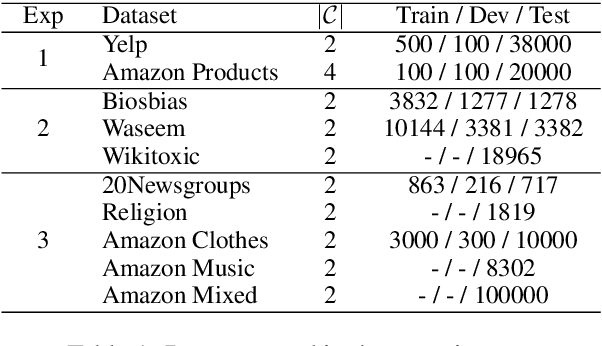
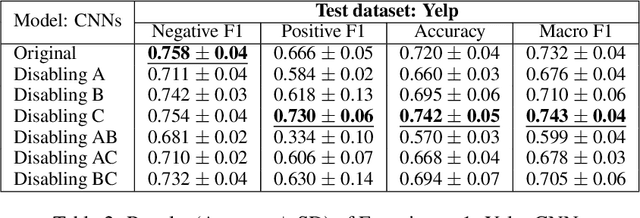
Since obtaining a perfect training dataset (i.e., a dataset which is considerably large, unbiased, and well-representative of unseen cases) is hardly possible, many real-world text classifiers are trained on the available, yet imperfect, datasets. These classifiers are thus likely to have undesirable properties. For instance, they may have biases against some sub-populations or may not work effectively in the wild due to overfitting. In this paper, we propose FIND -- a framework which enables humans to debug deep learning text classifiers by disabling irrelevant hidden features. Experiments show that by using FIND, humans can improve CNN text classifiers which were trained under different types of imperfect datasets (including datasets with biases and datasets with dissimilar train-test distributions).
MLQE-PE: A Multilingual Quality Estimation and Post-Editing Dataset
Oct 09, 2020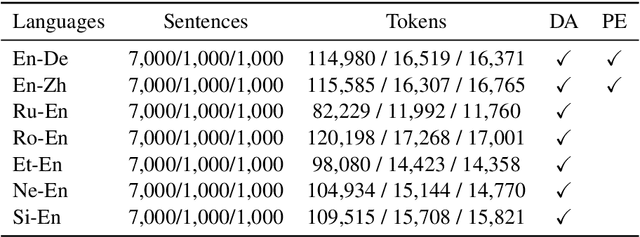
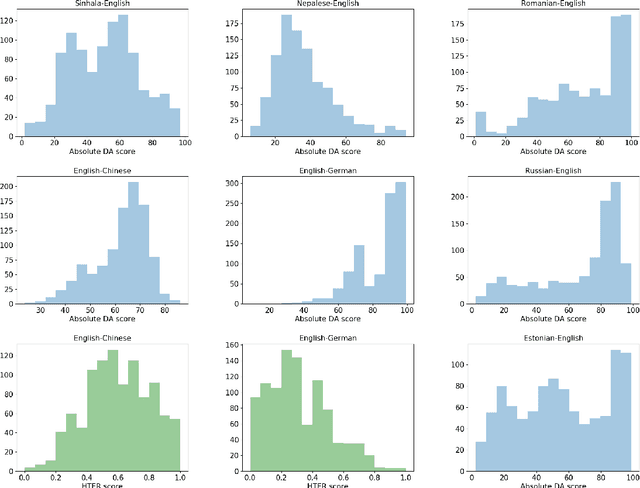
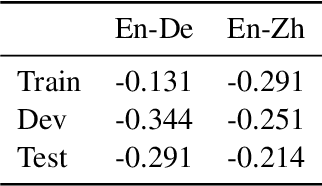
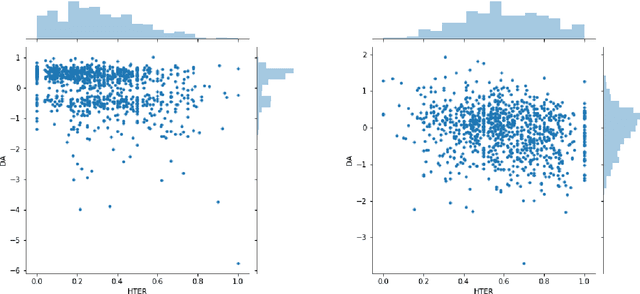
We present MLQE-PE, a new dataset for Machine Translation (MT) Quality Estimation (QE) and Automatic Post-Editing (APE). The dataset contains seven language pairs, with human labels for 9,000 translations per language pair in the following formats: sentence-level direct assessments and post-editing effort, and word-level good/bad labels. It also contains the post-edited sentences, as well as titles of the articles where the sentences were extracted from, and the neural MT models used to translate the text.
Unsupervised Quality Estimation for Neural Machine Translation
May 21, 2020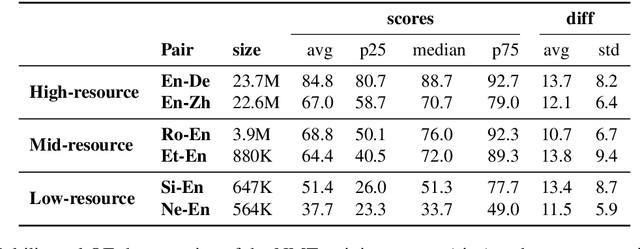
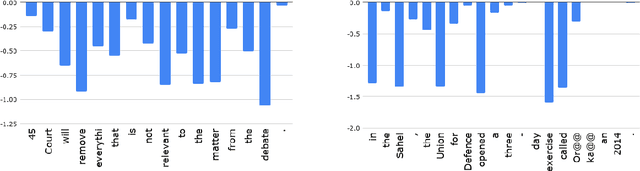
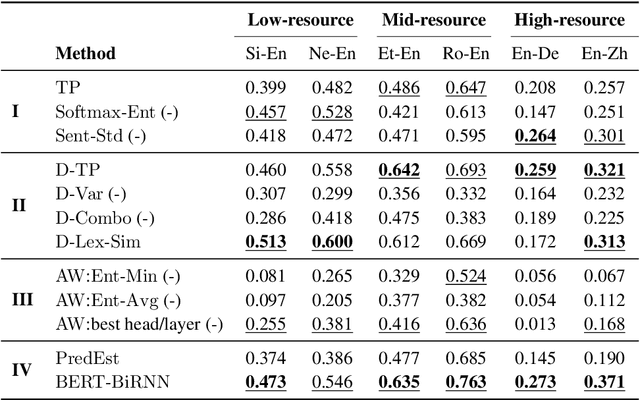
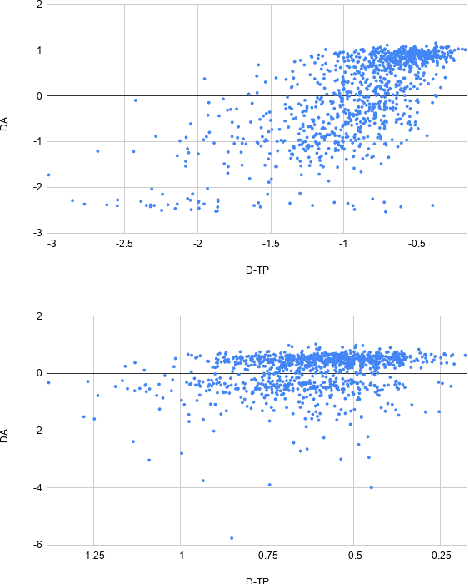
Quality Estimation (QE) is an important component in making Machine Translation (MT) useful in real-world applications, as it is aimed to inform the user on the quality of the MT output at test time. Existing approaches require large amounts of expert annotated data, computation and time for training. As an alternative, we devise an unsupervised approach to QE where no training or access to additional resources besides the MT system itself is required. Different from most of the current work that treats the MT system as a black box, we explore useful information that can be extracted from the MT system as a by-product of translation. By employing methods for uncertainty quantification, we achieve very good correlation with human judgments of quality, rivalling state-of-the-art supervised QE models. To evaluate our approach we collect the first dataset that enables work on both black-box and glass-box approaches to QE.
ASSET: A Dataset for Tuning and Evaluation of Sentence Simplification Models with Multiple Rewriting Transformations
May 01, 2020
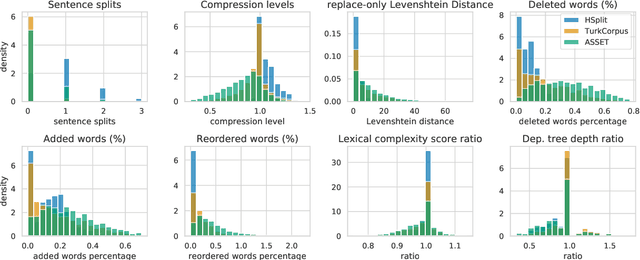
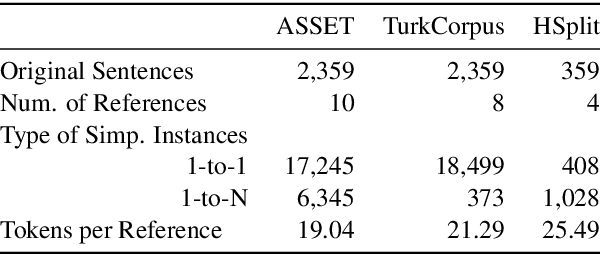
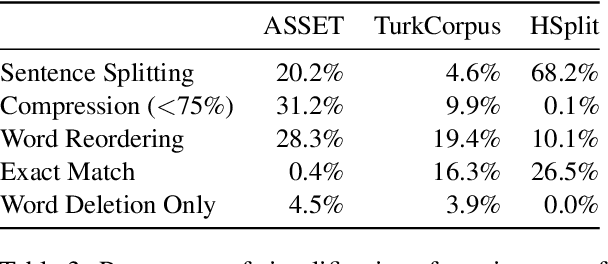
In order to simplify a sentence, human editors perform multiple rewriting transformations: they split it into several shorter sentences, paraphrase words (i.e. replacing complex words or phrases by simpler synonyms), reorder components, and/or delete information deemed unnecessary. Despite these varied range of possible text alterations, current models for automatic sentence simplification are evaluated using datasets that are focused on a single transformation, such as lexical paraphrasing or splitting. This makes it impossible to understand the ability of simplification models in more realistic settings. To alleviate this limitation, this paper introduces ASSET, a new dataset for assessing sentence simplification in English. ASSET is a crowdsourced multi-reference corpus where each simplification was produced by executing several rewriting transformations. Through quantitative and qualitative experiments, we show that simplifications in ASSET are better at capturing characteristics of simplicity when compared to other standard evaluation datasets for the task. Furthermore, we motivate the need for developing better methods for automatic evaluation using ASSET, since we show that current popular metrics may not be suitable when multiple simplification transformations are performed.
Multimodal Machine Translation through Visuals and Speech
Nov 28, 2019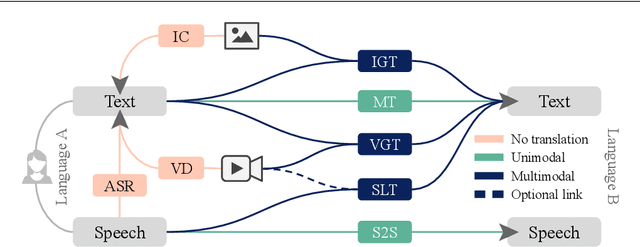
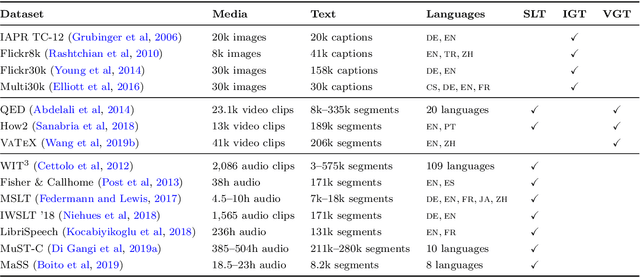

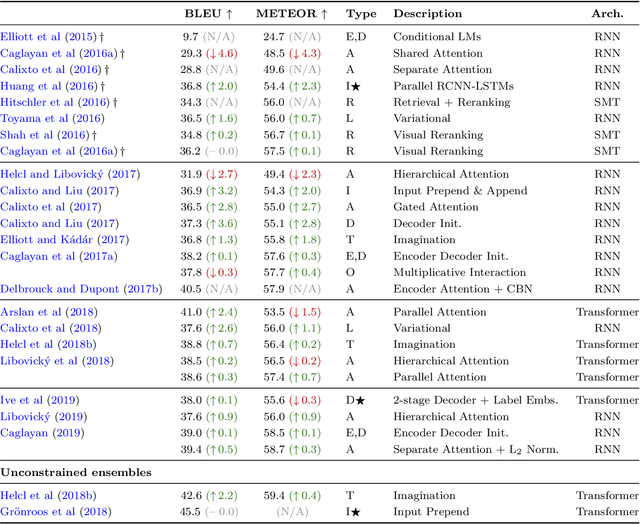
Multimodal machine translation involves drawing information from more than one modality, based on the assumption that the additional modalities will contain useful alternative views of the input data. The most prominent tasks in this area are spoken language translation, image-guided translation, and video-guided translation, which exploit audio and visual modalities, respectively. These tasks are distinguished from their monolingual counterparts of speech recognition, image captioning, and video captioning by the requirement of models to generate outputs in a different language. This survey reviews the major data resources for these tasks, the evaluation campaigns concentrated around them, the state of the art in end-to-end and pipeline approaches, and also the challenges in performance evaluation. The paper concludes with a discussion of directions for future research in these areas: the need for more expansive and challenging datasets, for targeted evaluations of model performance, and for multimodality in both the input and output space.