 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Geo-Culturally Grounded LLM Generations
Feb 20, 2025Generative large language models (LLMs) have been demonstrated to have gaps in diverse, cultural knowledge across the globe. We investigate the effect of retrieval augmented generation and search-grounding techniques on the ability of LLMs to display familiarity with a diverse range of national cultures. Specifically, we compare the performance of standard LLMs, LLMs augmented with retrievals from a bespoke knowledge base (i.e., KB grounding), and LLMs augmented with retrievals from a web search (i.e., search grounding) on a series of cultural familiarity benchmarks. We find that search grounding significantly improves the LLM performance on multiple-choice benchmarks that test propositional knowledge (e.g., the norms, artifacts, and institutions of national cultures), while KB grounding's effectiveness is limited by inadequate knowledge base coverage and a suboptimal retriever. However, search grounding also increases the risk of stereotypical judgments by language models, while failing to improve evaluators' judgments of cultural familiarity in a human evaluation with adequate statistical power. These results highlight the distinction between propositional knowledge about a culture and open-ended cultural fluency when it comes to evaluating the cultural familiarity of generative LLMs.
Can Capacitive Touch Images Enhance Mobile Keyboard Decoding?
Oct 03, 2024Capacitive touch sensors capture the two-dimensional spatial profile (referred to as a touch heatmap) of a finger's contact with a mobile touchscreen. However, the research and design of touchscreen mobile keyboards -- one of the most speed and accuracy demanding touch interfaces -- has focused on the location of the touch centroid derived from the touch image heatmap as the input, discarding the rest of the raw spatial signals. In this paper, we investigate whether touch heatmaps can be leveraged to further improve the tap decoding accuracy for mobile touchscreen keyboards. Specifically, we developed and evaluated machine-learning models that interpret user taps by using the centroids and/or the heatmaps as their input and studied the contribution of the heatmaps to model performance. The results show that adding the heatmap into the input feature set led to 21.4% relative reduction of character error rates on average, compared to using the centroid alone. Furthermore, we conducted a live user study with the centroid-based and heatmap-based decoders built into Pixel 6 Pro devices and observed lower error rate, faster typing speed, and higher self-reported satisfaction score based on the heatmap-based decoder than the centroid-based decoder. These findings underline the promise of utilizing touch heatmaps for improving typing experience in mobile keyboards.
Label-Aware Automatic Verbalizer for Few-Shot Text Classification
Oct 19, 2023



Prompt-based learning has shown its effectiveness in few-shot text classification. One important factor in its success is a verbalizer, which translates output from a language model into a predicted class. Notably, the simplest and widely acknowledged verbalizer employs manual labels to represent the classes. However, manual selection does not guarantee the optimality of the selected words when conditioned on the chosen language model. Therefore, we propose Label-Aware Automatic Verbalizer (LAAV), effectively augmenting the manual labels to achieve better few-shot classification results. Specifically, we use the manual labels along with the conjunction "and" to induce the model to generate more effective words for the verbalizer. The experimental results on five datasets across five languages demonstrate that LAAV significantly outperforms existing verbalizers. Furthermore, our analysis reveals that LAAV suggests more relevant words compared to similar approaches, especially in mid-to-low resource languages.
Towards Explainable Evaluation Metrics for Machine Translation
Jun 22, 2023



Unlike classical lexical overlap metrics such as BLEU, most current evaluation metrics for machine translation (for example, COMET or BERTScore) are based on black-box large language models. They often achieve strong correlations with human judgments, but recent research indicates that the lower-quality classical metrics remain dominant, one of the potential reasons being that their decision processes are more transparent. To foster more widespread acceptance of novel high-quality metrics, explainability thus becomes crucial. In this concept paper, we identify key properties as well as key goals of explainable machine translation metrics and provide a comprehensive synthesis of recent techniques, relating them to our established goals and properties. In this context, we also discuss the latest state-of-the-art approaches to explainable metrics based on generative models such as ChatGPT and GPT4. Finally, we contribute a vision of next-generation approaches, including natural language explanations. We hope that our work can help catalyze and guide future research on explainable evaluation metrics and, mediately, also contribute to better and more transparent machine translation systems.
Argumentative Explanations for Pattern-Based Text Classifiers
May 22, 2022
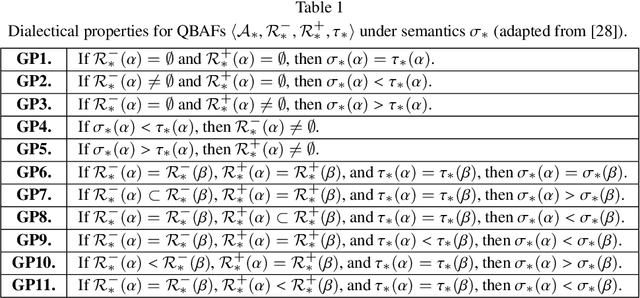
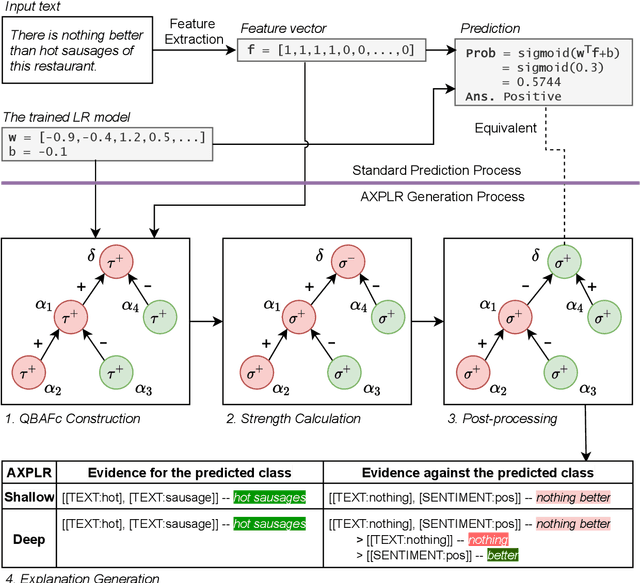

Recent works in Explainable AI mostly address the transparency issue of black-box models or create explanations for any kind of models (i.e., they are model-agnostic), while leaving explanations of interpretable models largely underexplored. In this paper, we fill this gap by focusing on explanations for a specific interpretable model, namely pattern-based logistic regression (PLR) for binary text classification. We do so because, albeit interpretable, PLR is challenging when it comes to explanations. In particular, we found that a standard way to extract explanations from this model does not consider relations among the features, making the explanations hardly plausible to humans. Hence, we propose AXPLR, a novel explanation method using (forms of) computational argumentation to generate explanations (for outputs computed by PLR) which unearth model agreements and disagreements among the features. Specifically, we use computational argumentation as follows: we see features (patterns) in PLR as arguments in a form of quantified bipolar argumentation frameworks (QBAFs) and extract attacks and supports between arguments based on specificity of the arguments; we understand logistic regression as a gradual semantics for these QBAFs, used to determine the arguments' dialectic strength; and we study standard properties of gradual semantics for QBAFs in the context of our argumentative re-interpretation of PLR, sanctioning its suitability for explanatory purposes. We then show how to extract intuitive explanations (for outputs computed by PLR) from the constructed QBAFs. Finally, we conduct an empirical evaluation and two experiments in the context of human-AI collaboration to demonstrate the advantages of our resulting AXPLR method.
Towards Explainable Evaluation Metrics for Natural Language Generation
Mar 21, 2022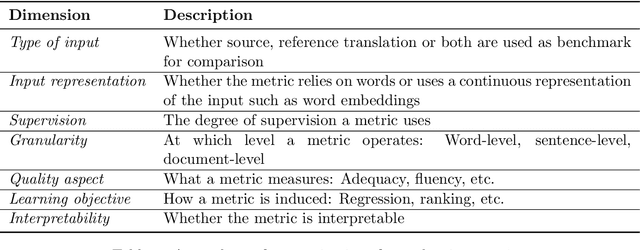

Unlike classical lexical overlap metrics such as BLEU, most current evaluation metrics (such as BERTScore or MoverScore) are based on black-box language models such as BERT or XLM-R. They often achieve strong correlations with human judgments, but recent research indicates that the lower-quality classical metrics remain dominant, one of the potential reasons being that their decision processes are transparent. To foster more widespread acceptance of the novel high-quality metrics, explainability thus becomes crucial. In this concept paper, we identify key properties and propose key goals of explainable machine translation evaluation metrics. We also provide a synthesizing overview over recent approaches for explainable machine translation metrics and discuss how they relate to those goals and properties. Further, we conduct own novel experiments, which (among others) find that current adversarial NLP techniques are unsuitable for automatically identifying limitations of high-quality black-box evaluation metrics, as they are not meaning-preserving. Finally, we provide a vision of future approaches to explainable evaluation metrics and their evaluation. We hope that our work can help catalyze and guide future research on explainable evaluation metrics and, mediately, also contribute to better and more transparent text generation systems.
The Eval4NLP Shared Task on Explainable Quality Estimation: Overview and Results
Oct 08, 2021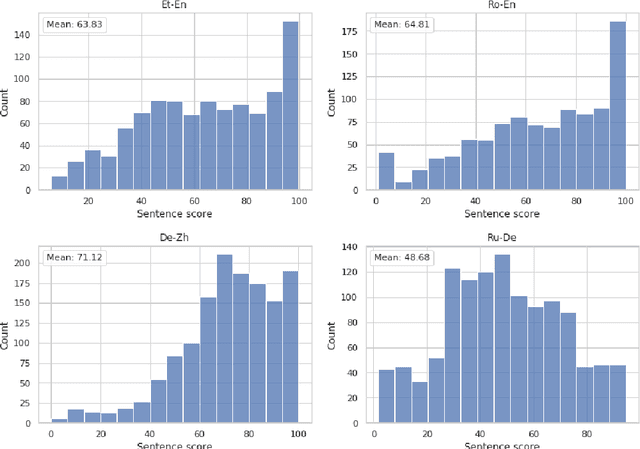
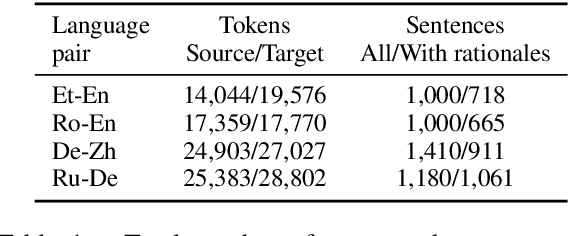
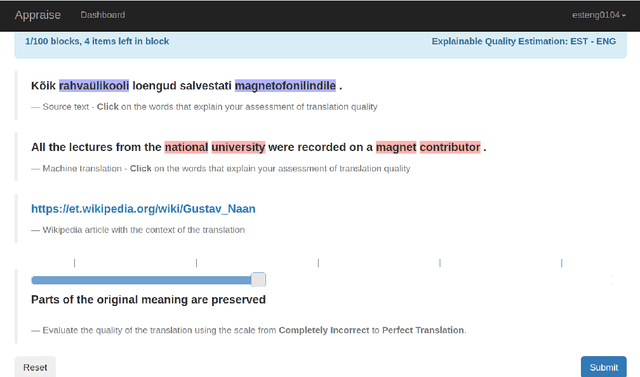
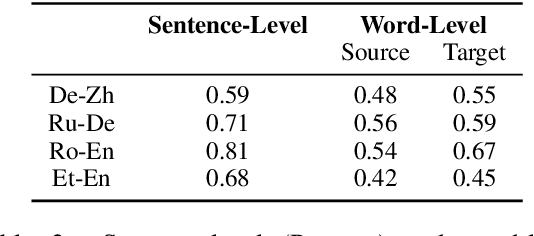
In this paper, we introduce the Eval4NLP-2021shared task on explainable quality estimation. Given a source-translation pair, this shared task requires not only to provide a sentence-level score indicating the overall quality of the translation, but also to explain this score by identifying the words that negatively impact translation quality. We present the data, annotation guidelines and evaluation setup of the shared task, describe the six participating systems, and analyze the results. To the best of our knowledge, this is the first shared task on explainable NLP evaluation metrics. Datasets and results are available at https://github.com/eval4nlp/SharedTask2021.
Explanation-Based Human Debugging of NLP Models: A Survey
Apr 30, 2021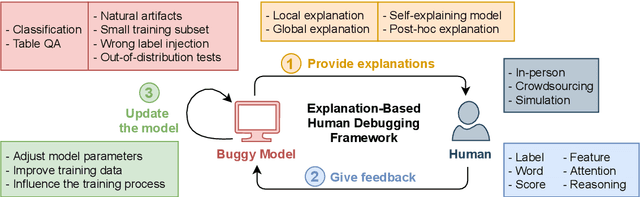
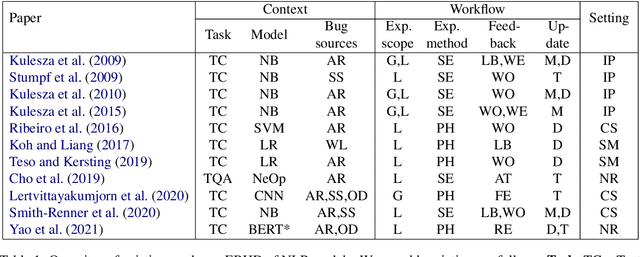
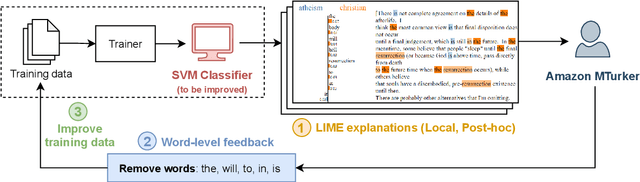
To fix a bug in a program, we need to locate where the bug is, understand why it causes the problem, and patch the code accordingly. This process becomes harder when the program is a trained machine learning model and even harder for opaque deep learning models. In this survey, we review papers that exploit explanations to enable humans to debug NLP models. We call this problem explanation-based human debugging (EBHD). In particular, we categorize and discuss existing works along three main dimensions of EBHD (the bug context, the workflow, and the experimental setting), compile findings on how EBHD components affect human debuggers, and highlight open problems that could be future research directions.
GrASP: A Library for Extracting and Exploring Human-Interpretable Textual Patterns
Apr 08, 2021
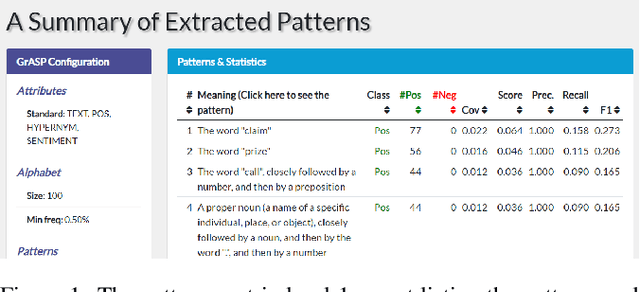
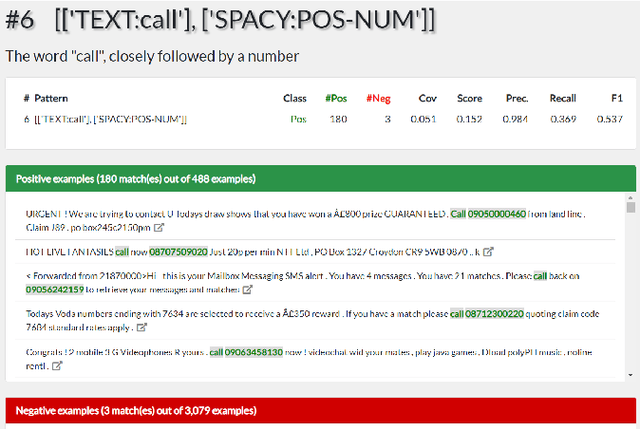
Data exploration is an important step of every data science and machine learning project, including those involving textual data. We provide a Python library for GrASP, an existing algorithm for drawing patterns from textual data. The library is equipped with a web-based interface empowering human users to conveniently explore the data and the extracted patterns. We also demonstrate the use of the library in two settings (spam detection and argument mining) and discuss future deployments of the library, e.g., beyond textual data exploration.
DAX: Deep Argumentative eXplanation for Neural Networks
Dec 10, 2020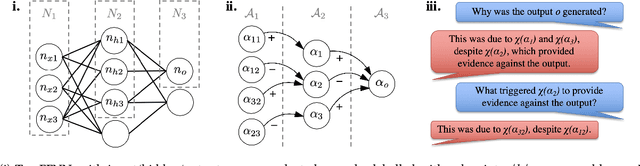
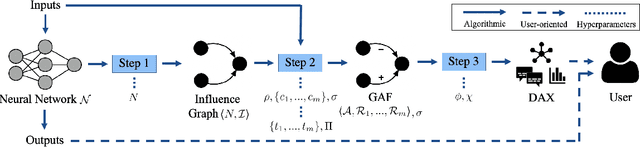
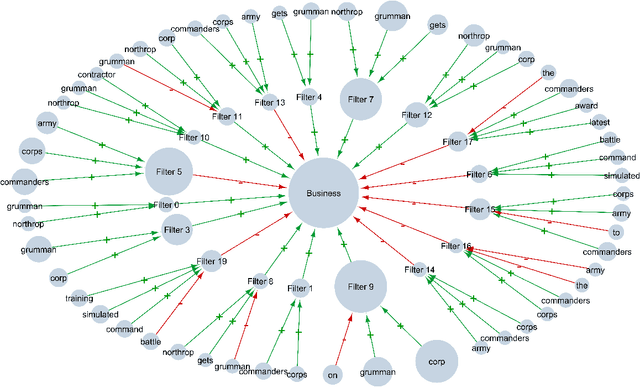
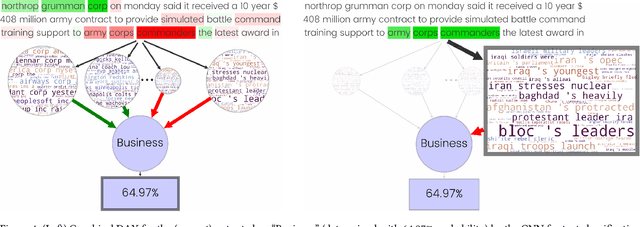
Despite the rapid growth in attention on eXplainable AI (XAI) of late, explanations in the literature provide little insight into the actual functioning of Neural Networks (NNs), significantly limiting their transparency. We propose a methodology for explaining NNs, providing transparency about their inner workings, by utilising computational argumentation (a form of symbolic AI offering reasoning abstractions for a variety of settings where opinions matter) as the scaffolding underpinning Deep Argumentative eXplanations (DAXs). We define three DAX instantiations (for various neural architectures and tasks) and evaluate them empirically in terms of stability, computational cost, and importance of depth. We also conduct human experiments with DAXs for text classification models, indicating that they are comprehensible to humans and align with their judgement, while also being competitive, in terms of user acceptance, with existing approaches to XAI that also have an argumentative spirit.