 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexityMT: Benchmarking the Interaction Between Text Complexity and Machine Translation
Jun 03, 2026When a text is translated, does the translation retain the complexity of the original? We introduce ComplexityMT, a new challenge for assessing how text complexity and machine translation interact with and influence each other, using the Common European Framework of Reference for Languages (CEFR) levels as the measure of text complexity. Across six languages, including Arabic, Dutch, English, French, Hindi, and Russian, we evaluate three open-weight models, one closed model, and a commercial machine translation system on two tasks: i) correlation of CEFR with translation difficulty, and ii) shifts in CEFR levels of the source texts. Our experiments show that higher CEFR levels make texts more difficult to translate, and that machine translation shifts the CEFR level of the target text compared to the original source, for most languages. These findings provide new insights for researchers and practitioners working on multilingual pedagogical content generation and machine translation difficulty estimation.
Analysing Zero-Shot Readability-Controlled Sentence Simplification
Sep 30, 2024



Readability-controlled text simplification (RCTS) rewrites texts to lower readability levels while preserving their meaning. RCTS models often depend on parallel corpora with readability annotations on both source and target sides. Such datasets are scarce and difficult to curate, especially at the sentence level. To reduce reliance on parallel data, we explore using instruction-tuned large language models for zero-shot RCTS. Through automatic and manual evaluations, we examine: (1) how different types of contextual information affect a model's ability to generate sentences with the desired readability, and (2) the trade-off between achieving target readability and preserving meaning. Results show that all tested models struggle to simplify sentences (especially to the lowest levels) due to models' limitations and characteristics of the source sentences that impede adequate rewriting. Our experiments also highlight the need for better automatic evaluation metrics tailored to RCTS, as standard ones often misinterpret common simplification operations, and inaccurately assess readability and meaning preservation.
BLESS: Benchmarking Large Language Models on Sentence Simplification
Oct 24, 2023



We present BLESS, a comprehensive performance benchmark of the most recent state-of-the-art large language models (LLMs) on the task of text simplification (TS). We examine how well off-the-shelf LLMs can solve this challenging task, assessing a total of 44 models, differing in size, architecture, pre-training methods, and accessibility, on three test sets from different domains (Wikipedia, news, and medical) under a few-shot setting. Our analysis considers a suite of automatic metrics as well as a large-scale quantitative investigation into the types of common edit operations performed by the different models. Furthermore, we perform a manual qualitative analysis on a subset of model outputs to better gauge the quality of the generated simplifications. Our evaluation indicates that the best LLMs, despite not being trained on TS, perform comparably with state-of-the-art TS baselines. Additionally, we find that certain LLMs demonstrate a greater range and diversity of edit operations. Our performance benchmark will be available as a resource for the development of future TS methods and evaluation metrics.
A Practical Toolkit for Multilingual Question and Answer Generation
May 27, 2023Generating questions along with associated answers from a text has applications in several domains, such as creating reading comprehension tests for students, or improving document search by providing auxiliary questions and answers based on the query. Training models for question and answer generation (QAG) is not straightforward due to the expected structured output (i.e. a list of question and answer pairs), as it requires more than generating a single sentence. This results in a small number of publicly accessible QAG models. In this paper, we introduce AutoQG, an online service for multilingual QAG, along with lmqg, an all-in-one Python package for model fine-tuning, generation, and evaluation. We also release QAG models in eight languages fine-tuned on a few variants of pre-trained encoder-decoder language models, which can be used online via AutoQG or locally via lmqg. With these resources, practitioners of any level can benefit from a toolkit that includes a web interface for end users, and easy-to-use code for developers who require custom models or fine-grained controls for generation.
An Empirical Comparison of LM-based Question and Answer Generation Methods
May 26, 2023



Question and answer generation (QAG) consists of generating a set of question-answer pairs given a context (e.g. a paragraph). This task has a variety of applications, such as data augmentation for question answering (QA) models, information retrieval and education. In this paper, we establish baselines with three different QAG methodologies that leverage sequence-to-sequence language model (LM) fine-tuning. Experiments show that an end-to-end QAG model, which is computationally light at both training and inference times, is generally robust and outperforms other more convoluted approaches. However, there are differences depending on the underlying generative LM. Finally, our analysis shows that QA models fine-tuned solely on generated question-answer pairs can be competitive when compared to supervised QA models trained on human-labeled data.
Generative Language Models for Paragraph-Level Question Generation
Oct 08, 2022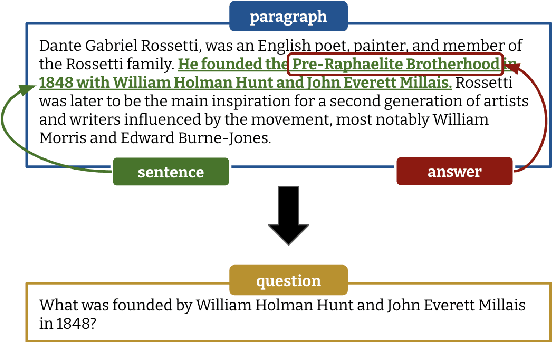
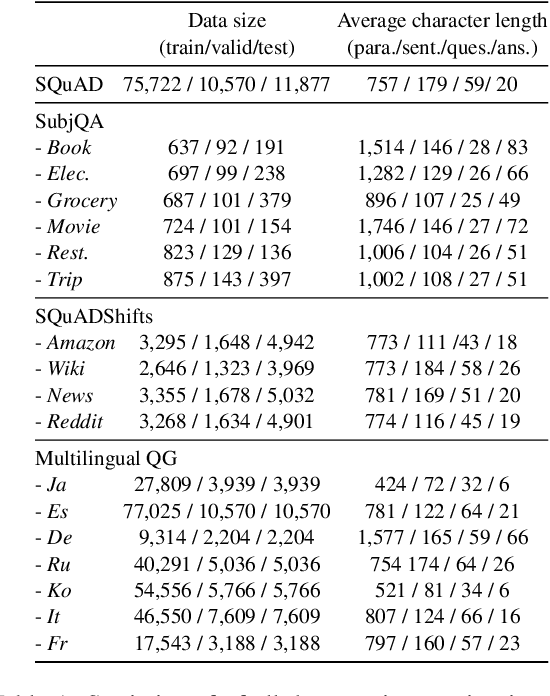
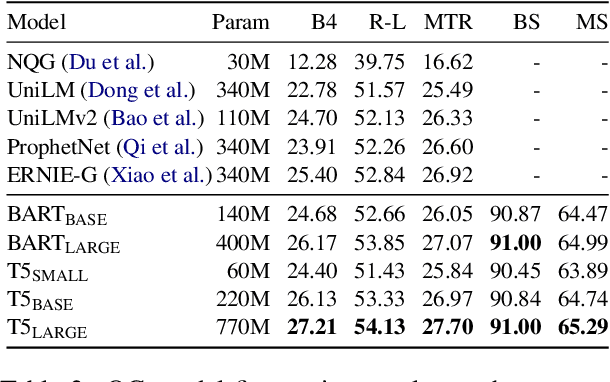
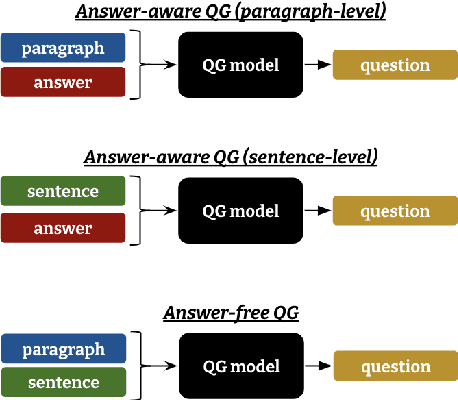
Powerful generative models have led to recent progress in question generation (QG). However, it is difficult to measure advances in QG research since there are no standardized resources that allow a uniform comparison among approaches. In this paper, we introduce QG-Bench, a multilingual and multidomain benchmark for QG that unifies existing question answering datasets by converting them to a standard QG setting. It includes general-purpose datasets such as SQuAD for English, datasets from ten domains and two styles, as well as datasets in eight different languages. Using QG-Bench as a reference, we perform an extensive analysis of the capabilities of language models for the task. First, we propose robust QG baselines based on fine-tuning generative language models. Then, we complement automatic evaluation based on standard metrics with an extensive manual evaluation, which in turn sheds light on the difficulty of evaluating QG models. Finally, we analyse both the domain adaptability of these models as well as the effectiveness of multilingual models in languages other than English. QG-Bench is released along with the fine-tuned models presented in the paper https://github.com/asahi417/lm-question-generation, which are also available as a demo https://autoqg.net/.
Knowledge Distillation for Quality Estimation
Jul 01, 2021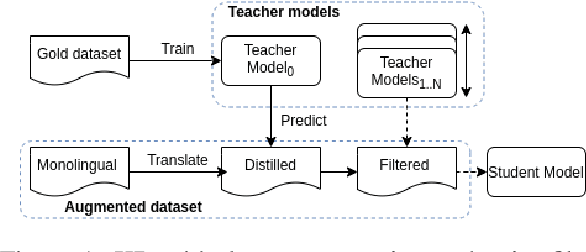
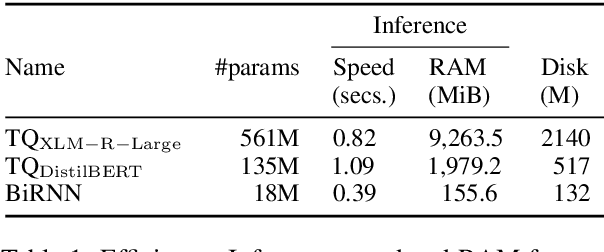
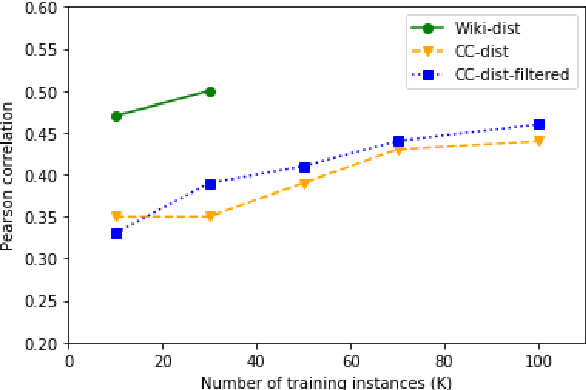
Quality Estimation (QE) is the task of automatically predicting Machine Translation quality in the absence of reference translations, making it applicable in real-time settings, such as translating online social media conversations. Recent success in QE stems from the use of multilingual pre-trained representations, where very large models lead to impressive results. However, the inference time, disk and memory requirements of such models do not allow for wide usage in the real world. Models trained on distilled pre-trained representations remain prohibitively large for many usage scenarios. We instead propose to directly transfer knowledge from a strong QE teacher model to a much smaller model with a different, shallower architecture. We show that this approach, in combination with data augmentation, leads to light-weight QE models that perform competitively with distilled pre-trained representations with 8x fewer parameters.
Controllable Text Simplification with Explicit Paraphrasing
Oct 21, 2020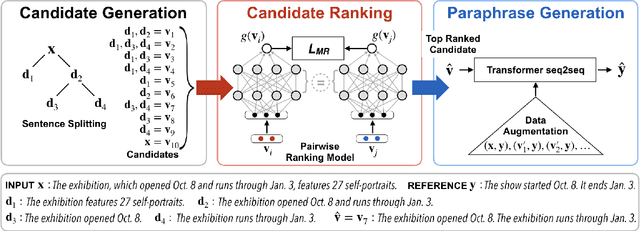
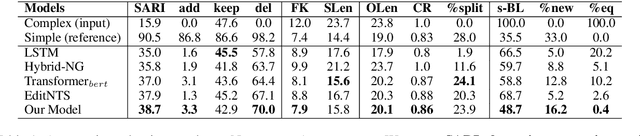
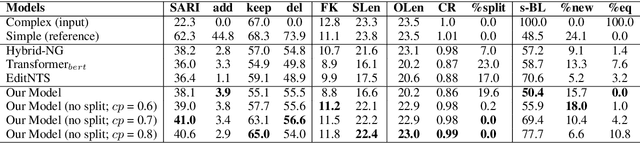
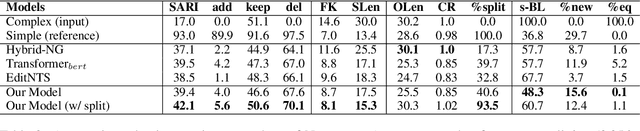
Text Simplification improves the readability of sentences through several rewriting transformations, such as lexical paraphrasing, deletion, and splitting. Current simplification systems are predominantly sequence-to-sequence models that are trained end-to-end to perform all these operations simultaneously. However, such systems limit themselves to mostly deleting words and cannot easily adapt to the requirements of different target audiences. In this paper, we propose a novel hybrid approach that leverages linguistically-motivated rules for splitting and deletion, and couples them with a neural paraphrasing model to produce varied rewriting styles. We introduce a new data augmentation method to improve the paraphrasing capability of our model. Through automatic and manual evaluations, we show that our proposed model establishes a new state-of-the-art for the task, paraphrasing more often than the existing systems, and can control the degree of each simplification operation applied to the input texts.
ASSET: A Dataset for Tuning and Evaluation of Sentence Simplification Models with Multiple Rewriting Transformations
May 01, 2020
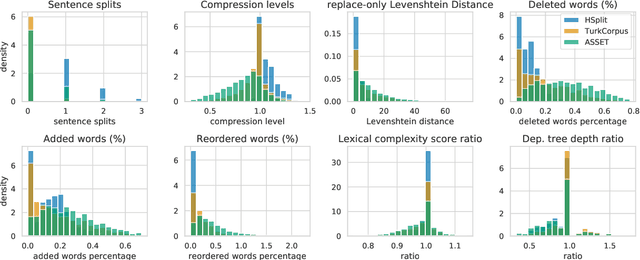
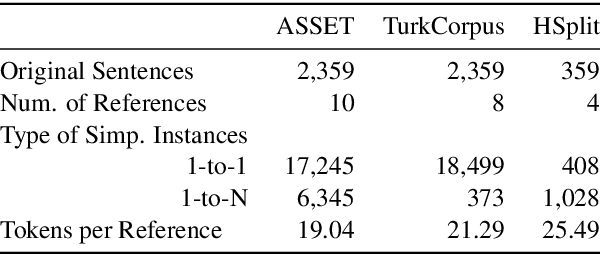
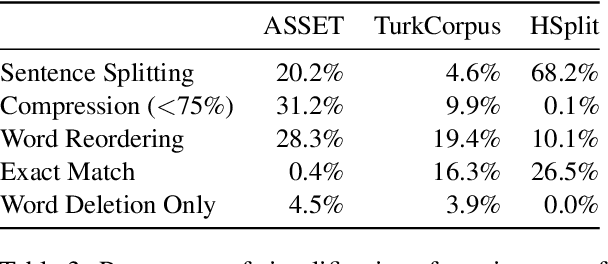
In order to simplify a sentence, human editors perform multiple rewriting transformations: they split it into several shorter sentences, paraphrase words (i.e. replacing complex words or phrases by simpler synonyms), reorder components, and/or delete information deemed unnecessary. Despite these varied range of possible text alterations, current models for automatic sentence simplification are evaluated using datasets that are focused on a single transformation, such as lexical paraphrasing or splitting. This makes it impossible to understand the ability of simplification models in more realistic settings. To alleviate this limitation, this paper introduces ASSET, a new dataset for assessing sentence simplification in English. ASSET is a crowdsourced multi-reference corpus where each simplification was produced by executing several rewriting transformations. Through quantitative and qualitative experiments, we show that simplifications in ASSET are better at capturing characteristics of simplicity when compared to other standard evaluation datasets for the task. Furthermore, we motivate the need for developing better methods for automatic evaluation using ASSET, since we show that current popular metrics may not be suitable when multiple simplification transformations are performed.
EASSE: Easier Automatic Sentence Simplification Evaluation
Sep 13, 2019

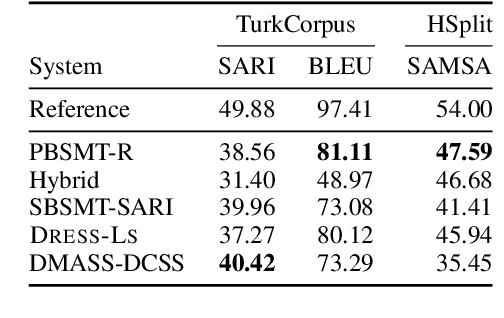
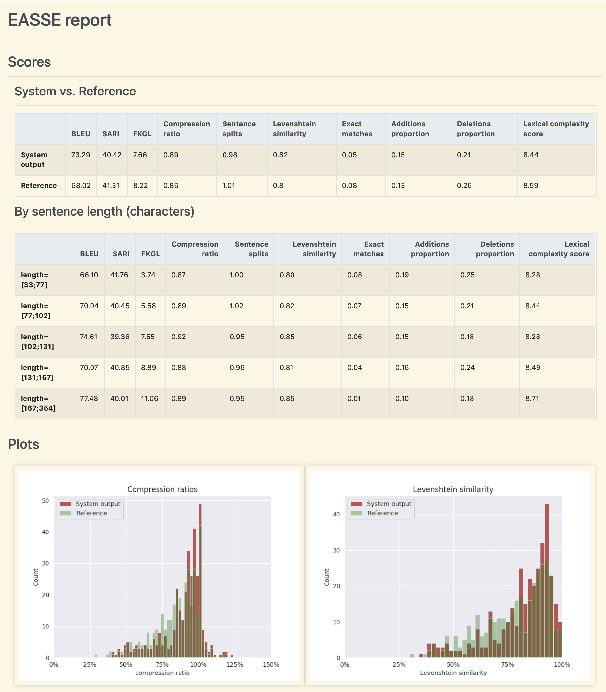
We introduce EASSE, a Python package aiming to facilitate and standardise automatic evaluation and comparison of Sentence Simplification (SS) systems. EASSE provides a single access point to a broad range of evaluation resources: standard automatic metrics for assessing SS outputs (e.g. SARI), word-level accuracy scores for certain simplification transformations, reference-independent quality estimation features (e.g. compression ratio), and standard test data for SS evaluation (e.g. TurkCorpus). Finally, EASSE generates easy-to-visualise reports on the various metrics and features above and on how a particular SS output fares against reference simplifications. Through experiments, we show that these functionalities allow for better comparison and understanding of the performance of SS systems.