 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tens of Hours to Tens of Thousands: Scaling Back-Translation for Speech Recognition
May 22, 2025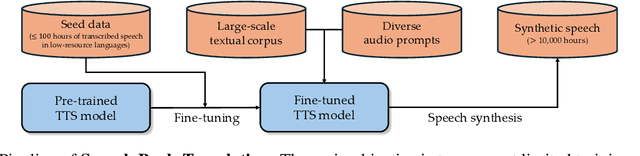
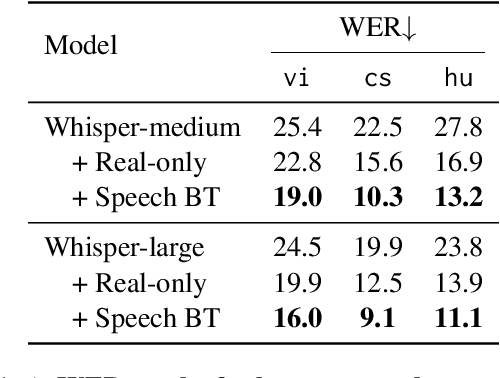
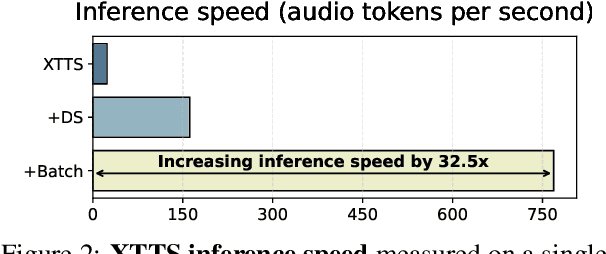

Recent advances in Automatic Speech Recognition (ASR) have been largely fueled by massive speech corpora. However, extending coverage to diverse languages with limited resources remains a formidable challenge. This paper introduces Speech Back-Translation, a scalable pipeline that improves multilingual ASR models by converting large-scale text corpora into synthetic speech via off-the-shelf text-to-speech (TTS) models. We demonstrate that just tens of hours of real transcribed speech can effectively train TTS models to generate synthetic speech at hundreds of times the original volume while maintaining high quality. To evaluate synthetic speech quality, we develop an intelligibility-based assessment framework and establish clear thresholds for when synthetic data benefits ASR training. Using Speech Back-Translation, we generate more than 500,000 hours of synthetic speech in ten languages and continue pre-training Whisper-large-v3, achieving average transcription error reductions of over 30\%. These results highlight the scalability and effectiveness of Speech Back-Translation for enhancing multilingual ASR systems.
RFUAV: A Benchmark Dataset for Unmanned Aerial Vehicle Detection and Identification
Mar 12, 2025



In this paper, we propose RFUAV as a new benchmark dataset for radio-frequency based (RF-based) unmanned aerial vehicle (UAV) identification and address the following challenges: Firstly, many existing datasets feature a restricted variety of drone types and insufficient volumes of raw data, which fail to meet the demands of practical applications. Secondly, existing datasets often lack raw data covering a broad range of signal-to-noise ratios (SNR), or do not provide tools for transforming raw data to different SNR levels. This limitation undermines the validity of model training and evaluation. Lastly, many existing datasets do not offer open-access evaluation tools, leading to a lack of unified evaluation standards in current research within this field. RFUAV comprises approximately 1.3 TB of raw frequency data collected from 37 distinct UAVs using the Universal Software Radio Peripheral (USRP) device in real-world environments. Through in-depth analysis of the RF data in RFUAV, we define a drone feature sequence called RF drone fingerprint, which aids in distinguishing drone signals. In addition to the dataset, RFUAV provides a baseline preprocessing method and model evaluation tools. Rigorous experiments demonstrate that these preprocessing methods achieve state-of-the-art (SOTA) performance using the provided evaluation tools. The RFUAV dataset and baseline implementation are publicly available at https://github.com/kitoweeknd/RFUAV/.
Towards Achieving Human Parity on End-to-end Simultaneous Speech Translation via LLM Agent
Jul 31, 2024



In this paper, we present Cross Language Agent -- Simultaneous Interpretation, CLASI, a high-quality and human-like Simultaneous Speech Translation (SiST) System. Inspired by professional human interpreters, we utilize a novel data-driven read-write strategy to balance the translation quality and latency. To address the challenge of translating in-domain terminologies, CLASI employs a multi-modal retrieving module to obtain relevant information to augment the translation. Supported by LLMs, our approach can generate error-tolerated translation by considering the input audio, historical context, and retrieved information. Experimental results show that our system outperforms other systems by significant margins. Aligned with professional human interpreters, we evaluate CLASI with a better human evaluation metric, valid information proportion (VIP), which measures the amount of information that can be successfully conveyed to the listeners. In the real-world scenarios, where the speeches are often disfluent, informal, and unclear, CLASI achieves VIP of 81.3% and 78.0% for Chinese-to-English and English-to-Chinese translation directions, respectively. In contrast, state-of-the-art commercial or open-source systems only achieve 35.4% and 41.6%. On the extremely hard dataset, where other systems achieve under 13% VIP, CLASI can still achieve 70% VIP.
NTIRE 2024 Challenge on Night Photography Rendering
Jun 18, 2024



This paper presents a review of the NTIRE 2024 challenge on night photography rendering. The goal of the challenge was to find solutions that process raw camera images taken in nighttime conditions, and thereby produce a photo-quality output images in the standard RGB (sRGB) space. Unlike the previous year's competition, the challenge images were collected with a mobile phone and the speed of algorithms was also measured alongside the quality of their output. To evaluate the results, a sufficient number of viewers were asked to assess the visual quality of the proposed solutions, considering the subjective nature of the task. There were 2 nominations: quality and efficiency. Top 5 solutions in terms of output quality were sorted by evaluation time (see Fig. 1). The top ranking participants' solutions effectively represent the state-of-the-art in nighttime photography rendering. More results can be found at https://nightimaging.org.
Beyond Raw Videos: Understanding Edited Videos with Large Multimodal Model
Jun 15, 2024



The emerging video LMMs (Large Multimodal Models) have achieved significant improvements on generic video understanding in the form of VQA (Visual Question Answering), where the raw videos are captured by cameras. However, a large portion of videos in real-world applications are edited videos, \textit{e.g.}, users usually cut and add effects/modifications to the raw video before publishing it on social media platforms. The edited videos usually have high view counts but they are not covered in existing benchmarks of video LMMs, \textit{i.e.}, ActivityNet-QA, or VideoChatGPT benchmark. In this paper, we leverage the edited videos on a popular short video platform, \textit{i.e.}, TikTok, and build a video VQA benchmark (named EditVid-QA) covering four typical editing categories, i.e., effect, funny, meme, and game. Funny and meme videos benchmark nuanced understanding and high-level reasoning, while effect and game evaluate the understanding capability of artificial design. Most of the open-source video LMMs perform poorly on the EditVid-QA benchmark, indicating a huge domain gap between edited short videos on social media and regular raw videos. To improve the generalization ability of LMMs, we collect a training set for the proposed benchmark based on both Panda-70M/WebVid raw videos and small-scale TikTok/CapCut edited videos, which boosts the performance on the proposed EditVid-QA benchmark, indicating the effectiveness of high-quality training data. We also identified a serious issue in the existing evaluation protocol using the GPT-3.5 judge, namely a "sorry" attack, where a sorry-style naive answer can achieve an extremely high rating from the GPT judge, e.g., over 4.3 for correctness score on VideoChatGPT evaluation protocol. To avoid the "sorry" attacks, we evaluate results with GPT-4 judge and keyword filtering. The datasets will be released for academic purposes only.
Sparsity- and Hybridity-Inspired Visual Parameter-Efficient Fine-Tuning for Medical Diagnosis
May 28, 2024



The success of Large Vision Models (LVMs) is accompanied by vast data volumes, which are prohibitively expensive in medical diagnosis.To address this, recent efforts exploit Parameter-Efficient Fine-Tuning (PEFT), which trains a small number of weights while freezing the rest.However, they typically assign trainable weights to the same positions in LVMs in a heuristic manner, regardless of task differences, making them suboptimal for professional applications like medical diagnosis.To address this, we statistically reveal the nature of sparsity and hybridity during diagnostic-targeted fine-tuning, i.e., a small portion of key weights significantly impacts performance, and these key weights are hybrid, including both task-specific and task-agnostic parts.Based on this, we propose a novel Sparsity- and Hybridity-inspired Parameter Efficient Fine-Tuning (SH-PEFT).It selects and trains a small portion of weights based on their importance, which is innovatively estimated by hybridizing both task-specific and task-agnostic strategies.Validated on six medical datasets of different modalities, we demonstrate that SH-PEFT achieves state-of-the-art performance in transferring LVMs to medical diagnosis in terms of accuracy. By tuning around 0.01% number of weights, it outperforms full model fine-tuning.Moreover, SH-PEFT also achieves comparable performance to other models deliberately optimized for specific medical tasks.Extensive experiments demonstrate the effectiveness of each design and reveal that large model transfer holds great potential in medical diagnosis.
CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts
May 09, 2024



Recent advancements in Multimodal Large Language Models (LLMs) have focused primarily on scaling by increasing text-image pair data and enhancing LLMs to improve performance on multimodal tasks. However, these scaling approaches are computationally expensive and overlook the significance of improving model capabilities from the vision side. Inspired by the successful applications of Mixture-of-Experts (MoE) in LLMs, which improves model scalability during training while keeping inference costs similar to those of smaller models, we propose CuMo. CuMo incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into both the vision encoder and the MLP connector, thereby enhancing the multimodal LLMs with minimal additional activated parameters during inference. CuMo first pre-trains the MLP blocks and then initializes each expert in the MoE block from the pre-trained MLP block during the visual instruction tuning stage. Auxiliary losses are used to ensure a balanced loading of experts. CuMo outperforms state-of-the-art multimodal LLMs across various VQA and visual-instruction-following benchmarks using models within each model size group, all while training exclusively on open-sourced datasets. The code and model weights for CuMo are open-sourced at https://github.com/SHI-Labs/CuMo.
End-to-end training of Multimodal Model and ranking Model
Apr 09, 2024



Traditional recommender systems heavily rely on ID features, which often encounter challenges related to cold-start and generalization. Modeling pre-extracted content features can mitigate these issues, but is still a suboptimal solution due to the discrepancies between training tasks and model parameters. End-to-end training presents a promising solution for these problems, yet most of the existing works mainly focus on retrieval models, leaving the multimodal techniques under-utilized. In this paper, we propose an industrial multimodal recommendation framework named EM3: End-to-end training of Multimodal Model and ranking Model, which sufficiently utilizes multimodal information and allows personalized ranking tasks to directly train the core modules in the multimodal model to obtain more task-oriented content features, without overburdening resource consumption. First, we propose Fusion-Q-Former, which consists of transformers and a set of trainable queries, to fuse different modalities and generate fixed-length and robust multimodal embeddings. Second, in our sequential modeling for user content interest, we utilize Low-Rank Adaptation technique to alleviate the conflict between huge resource consumption and long sequence length. Third, we propose a novel Content-ID-Contrastive learning task to complement the advantages of content and ID by aligning them with each other, obtaining more task-oriented content embeddings and more generalized ID embeddings. In experiments, we implement EM3 on different ranking models in two scenario, achieving significant improvements in both offline evaluation and online A/B test, verifying the generalizability of our method. Ablation studies and visualization are also performed. Furthermore, we also conduct experiments on two public datasets to show that our proposed method outperforms the state-of-the-art methods.
HUGS: Holistic Urban 3D Scene Understanding via Gaussian Splatting
Mar 19, 2024



Holistic understanding of urban scenes based on RGB images is a challenging yet important problem. It encompasses understanding both the geometry and appearance to enable novel view synthesis, parsing semantic labels, and tracking moving objects. Despite considerable progress, existing approaches often focus on specific aspects of this task and require additional inputs such as LiDAR scans or manually annotated 3D bounding boxes. In this paper, we introduce a novel pipeline that utilizes 3D Gaussian Splatting for holistic urban scene understanding. Our main idea involves the joint optimization of geometry, appearance, semantics, and motion using a combination of static and dynamic 3D Gaussians, where moving object poses are regularized via physical constraints. Our approach offers the ability to render new viewpoints in real-time, yielding 2D and 3D semantic information with high accuracy, and reconstruct dynamic scenes, even in scenarios where 3D bounding box detection are highly noisy. Experimental results on KITTI, KITTI-360, and Virtual KITTI 2 demonstrate the effectiveness of our approach.
Parameter-Efficient Conversational Recommender System as a Language Processing Task
Feb 03, 2024Conversational recommender systems (CRS) aim to recommend relevant items to users by eliciting user preference through natural language conversation. Prior work often utilizes external knowledge graphs for items' semantic information, a language model for dialogue generation, and a recommendation module for ranking relevant items. This combination of multiple components suffers from a cumbersome training process, and leads to semantic misalignment issues between dialogue generation and item recommendation. In this paper, we represent items in natural language and formulate CRS as a natural language processing task. Accordingly, we leverage the power of pre-trained language models to encode items, understand user intent via conversation, perform item recommendation through semantic matching, and generate dialogues. As a unified model, our PECRS (Parameter-Efficient CRS), can be optimized in a single stage, without relying on non-textual metadata such as a knowledge graph. Experiments on two benchmark CRS datasets, ReDial and INSPIRED, demonstrate the effectiveness of PECRS on recommendation and conversation. Our code is available at: https://github.com/Ravoxsg/efficient_unified_crs.