 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVQNet: Sparse Voxel-Adjacent Query Network for 4D Spatio-Temporal LiDAR Semantic Segmentation
Aug 25, 2023



LiDAR-based semantic perception tasks are critical yet challenging for autonomous driving. Due to the motion of objects and static/dynamic occlusion, temporal information plays an essential role in reinforcing perception by enhancing and completing single-frame knowledge. Previous approaches either directly stack historical frames to the current frame or build a 4D spatio-temporal neighborhood using KNN, which duplicates computation and hinders realtime performance. Based on our observation that stacking all the historical points would damage performance due to a large amount of redundant and misleading information, we propose the Sparse Voxel-Adjacent Query Network (SVQNet) for 4D LiDAR semantic segmentation. To take full advantage of the historical frames high-efficiently, we shunt the historical points into two groups with reference to the current points. One is the Voxel-Adjacent Neighborhood carrying local enhancing knowledge. The other is the Historical Context completing the global knowledge. Then we propose new modules to select and extract the instructive features from the two groups. Our SVQNet achieves state-of-the-art performance in LiDAR semantic segmentation of the SemanticKITTI benchmark and the nuScenes dataset.
ClickSeg: 3D Instance Segmentation with Click-Level Weak Annotations
Jul 19, 2023



3D instance segmentation methods often require fully-annotated dense labels for training, which are costly to obtain. In this paper, we present ClickSeg, a novel click-level weakly supervised 3D instance segmentation method that requires one point per instance annotation merely. Such a problem is very challenging due to the extremely limited labels, which has rarely been solved before. We first develop a baseline weakly-supervised training method, which generates pseudo labels for unlabeled data by the model itself. To utilize the property of click-level annotation setting, we further propose a new training framework. Instead of directly using the model inference way, i.e., mean-shift clustering, to generate the pseudo labels, we propose to use k-means with fixed initial seeds: the annotated points. New similarity metrics are further designed for clustering. Experiments on ScanNetV2 and S3DIS datasets show that the proposed ClickSeg surpasses the previous best weakly supervised instance segmentation result by a large margin (e.g., +9.4% mAP on ScanNetV2). Using 0.02% supervision signals merely, ClickSeg achieves $\sim$90% of the accuracy of the fully-supervised counterpart. Meanwhile, it also achieves state-of-the-art semantic segmentation results among weakly supervised methods that use the same annotation settings.
EffLiFe: Efficient Light Field Generation via Hierarchical Sparse Gradient Descent
Jul 10, 2023



With the rise of Extended Reality (XR) technology, there is a growing need for real-time light field generation from sparse view inputs. Existing methods can be classified into offline techniques, which can generate high-quality novel views but at the cost of long inference/training time, and online methods, which either lack generalizability or produce unsatisfactory results. However, we have observed that the intrinsic sparse manifold of Multi-plane Images (MPI) enables a significant acceleration of light field generation while maintaining rendering quality. Based on this insight, we introduce EffLiFe, a novel light field optimization method, which leverages the proposed Hierarchical Sparse Gradient Descent (HSGD) to produce high-quality light fields from sparse view images in real time. Technically, the coarse MPI of a scene is first generated using a 3D CNN, and it is further sparsely optimized by focusing only on important MPI gradients in a few iterations. Nevertheless, relying solely on optimization can lead to artifacts at occlusion boundaries. Therefore, we propose an occlusion-aware iterative refinement module that removes visual artifacts in occluded regions by iteratively filtering the input. Extensive experiments demonstrate that our method achieves comparable visual quality while being 100x faster on average than state-of-the-art offline methods and delivering better performance (about 2 dB higher in PSNR) compared to other online approaches.
Crowd3D: Towards Hundreds of People Reconstruction from a Single Image
Jan 23, 2023
Image-based multi-person reconstruction in wide-field large scenes is critical for crowd analysis and security alert. However, existing methods cannot deal with large scenes containing hundreds of people, which encounter the challenges of large number of people, large variations in human scale, and complex spatial distribution. In this paper, we propose Crowd3D, the first framework to reconstruct the 3D poses, shapes and locations of hundreds of people with global consistency from a single large-scene image. The core of our approach is to convert the problem of complex crowd localization into pixel localization with the help of our newly defined concept, Human-scene Virtual Interaction Point (HVIP). To reconstruct the crowd with global consistency, we propose a progressive reconstruction network based on HVIP by pre-estimating a scene-level camera and a ground plane. To deal with a large number of persons and various human sizes, we also design an adaptive human-centric cropping scheme. Besides, we contribute a benchmark dataset, LargeCrowd, for crowd reconstruction in a large scene. Experimental results demonstrate the effectiveness of the proposed method. The code and datasets will be made public.
Geo-NI: Geometry-aware Neural Interpolation for Light Field Rendering
Jun 20, 2022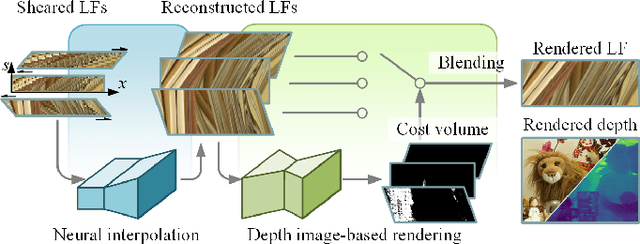
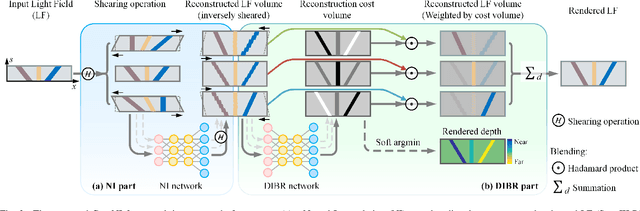


In this paper, we present a Geometry-aware Neural Interpolation (Geo-NI) framework for light field rendering. Previous learning-based approaches either rely on the capability of neural networks to perform direct interpolation, which we dubbed Neural Interpolation (NI), or explore scene geometry for novel view synthesis, also known as Depth Image-Based Rendering (DIBR). Instead, we incorporate the ideas behind these two kinds of approaches by launching the NI with a novel DIBR pipeline. Specifically, the proposed Geo-NI first performs NI using input light field sheared by a set of depth hypotheses. Then the DIBR is implemented by assigning the sheared light fields with a novel reconstruction cost volume according to the reconstruction quality under different depth hypotheses. The reconstruction cost is interpreted as a blending weight to render the final output light field by blending the reconstructed light fields along the dimension of depth hypothesis. By combining the superiorities of NI and DIBR, the proposed Geo-NI is able to render views with large disparity with the help of scene geometry while also reconstruct non-Lambertian effect when depth is prone to be ambiguous. Extensive experiments on various datasets demonstrate the superior performance of the proposed geometry-aware light field rendering framework.
A^2-FPN: Attention Aggregation based Feature Pyramid Network for Instance Segmentation
May 07, 2021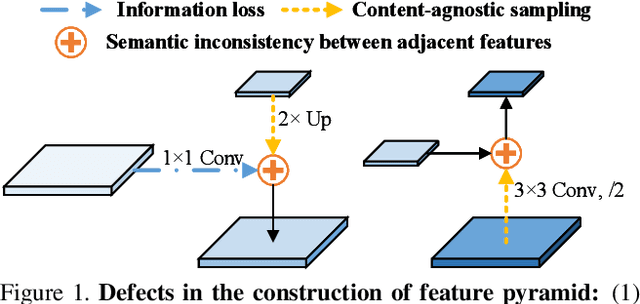
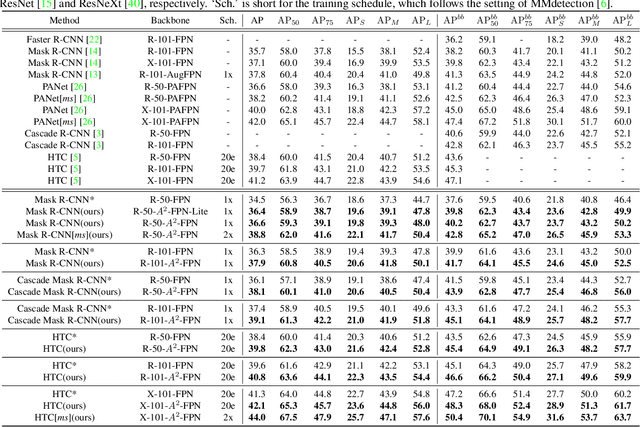
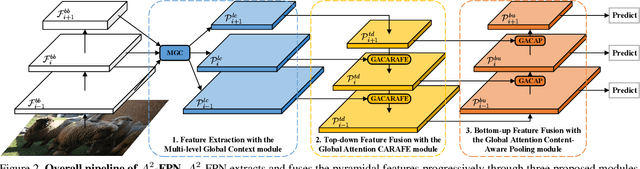
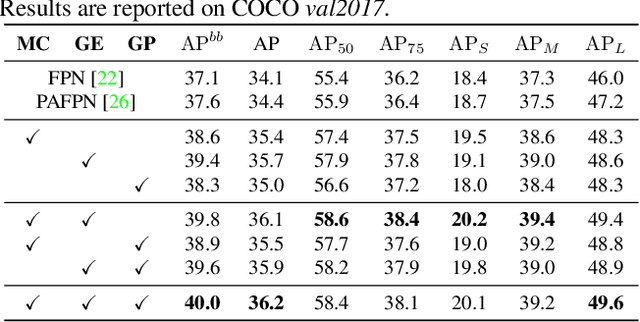
Learning pyramidal feature representations is crucial for recognizing object instances at different scales. Feature Pyramid Network (FPN) is the classic architecture to build a feature pyramid with high-level semantics throughout. However, intrinsic defects in feature extraction and fusion inhibit FPN from further aggregating more discriminative features. In this work, we propose Attention Aggregation based Feature Pyramid Network (A^2-FPN), to improve multi-scale feature learning through attention-guided feature aggregation. In feature extraction, it extracts discriminative features by collecting-distributing multi-level global context features, and mitigates the semantic information loss due to drastically reduced channels. In feature fusion, it aggregates complementary information from adjacent features to generate location-wise reassembly kernels for content-aware sampling, and employs channel-wise reweighting to enhance the semantic consistency before element-wise addition. A^2-FPN shows consistent gains on different instance segmentation frameworks. By replacing FPN with A^2-FPN in Mask R-CNN, our model boosts the performance by 2.1% and 1.6% mask AP when using ResNet-50 and ResNet-101 as backbone, respectively. Moreover, A^2-FPN achieves an improvement of 2.0% and 1.4% mask AP when integrated into the strong baselines such as Cascade Mask R-CNN and Hybrid Task Cascade.
RobustFusion: Robust Volumetric Performance Reconstruction under Human-object Interactions from Monocular RGBD Stream
Apr 30, 2021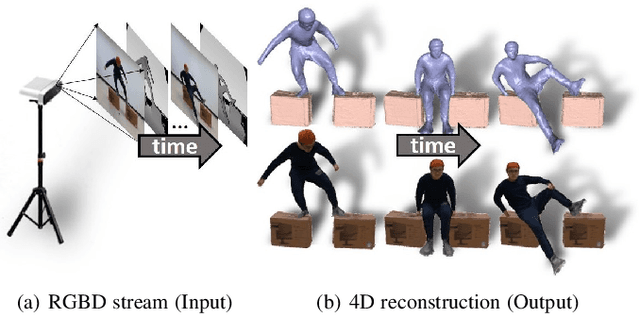
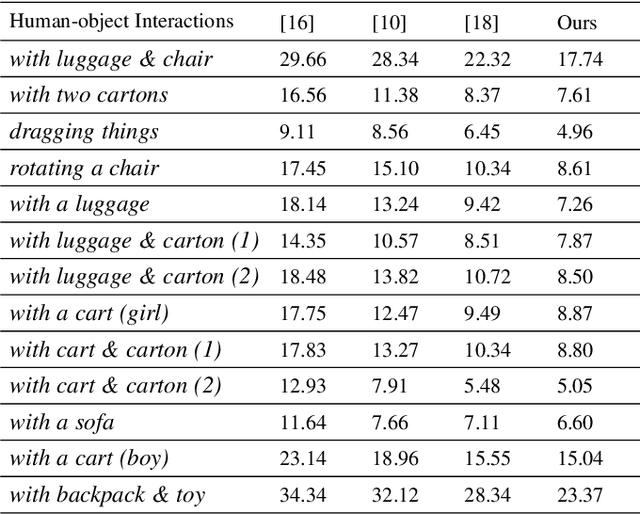
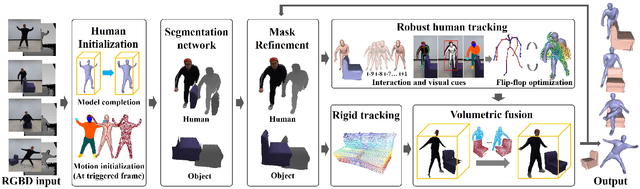

High-quality 4D reconstruction of human performance with complex interactions to various objects is essential in real-world scenarios, which enables numerous immersive VR/AR applications. However, recent advances still fail to provide reliable performance reconstruction, suffering from challenging interaction patterns and severe occlusions, especially for the monocular setting. To fill this gap, in this paper, we propose RobustFusion, a robust volumetric performance reconstruction system for human-object interaction scenarios using only a single RGBD sensor, which combines various data-driven visual and interaction cues to handle the complex interaction patterns and severe occlusions. We propose a semantic-aware scene decoupling scheme to model the occlusions explicitly, with a segmentation refinement and robust object tracking to prevent disentanglement uncertainty and maintain temporal consistency. We further introduce a robust performance capture scheme with the aid of various data-driven cues, which not only enables re-initialization ability, but also models the complex human-object interaction patterns in a data-driven manner. To this end, we introduce a spatial relation prior to prevent implausible intersections, as well as data-driven interaction cues to maintain natural motions, especially for those regions under severe human-object occlusions. We also adopt an adaptive fusion scheme for temporally coherent human-object reconstruction with occlusion analysis and human parsing cue. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality 4D human performance reconstruction under complex human-object interactions whilst still maintaining the lightweight monocular setting.
Revisiting Light Field Rendering with Deep Anti-Aliasing Neural Network
Apr 28, 2021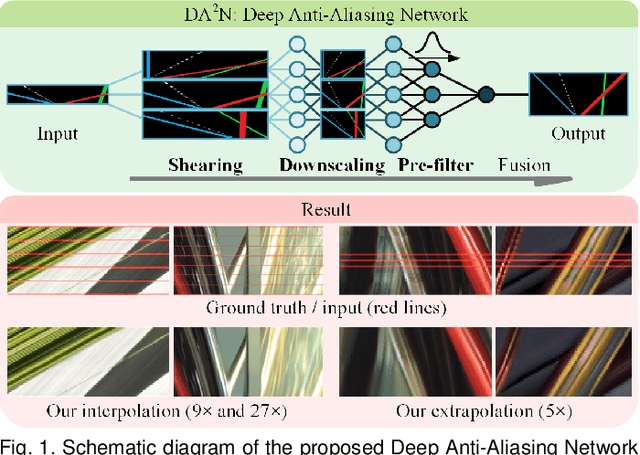

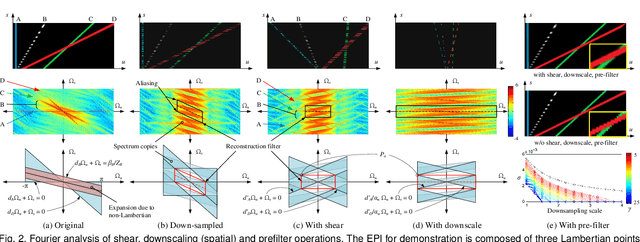
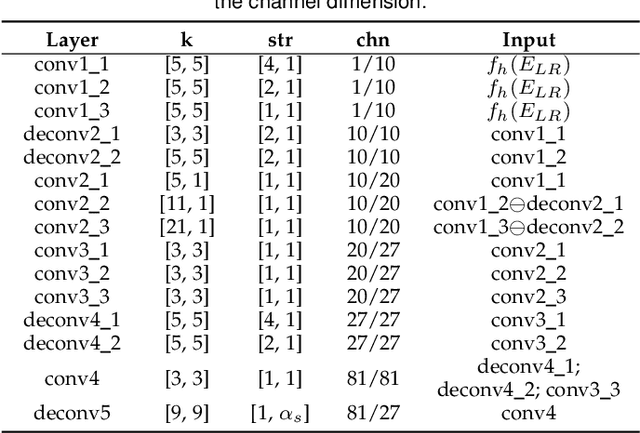
The light field (LF) reconstruction is mainly confronted with two challenges, large disparity and the non-Lambertian effect. Typical approaches either address the large disparity challenge using depth estimation followed by view synthesis or eschew explicit depth information to enable non-Lambertian rendering, but rarely solve both challenges in a unified framework. In this paper, we revisit the classic LF rendering framework to address both challenges by incorporating it with advanced deep learning techniques. First, we analytically show that the essential issue behind the large disparity and non-Lambertian challenges is the aliasing problem. Classic LF rendering approaches typically mitigate the aliasing with a reconstruction filter in the Fourier domain, which is, however, intractable to implement within a deep learning pipeline. Instead, we introduce an alternative framework to perform anti-aliasing reconstruction in the image domain and analytically show comparable efficacy on the aliasing issue. To explore the full potential, we then embed the anti-aliasing framework into a deep neural network through the design of an integrated architecture and trainable parameters. The network is trained through end-to-end optimization using a peculiar training set, including regular LFs and unstructured LFs. The proposed deep learning pipeline shows a substantial superiority in solving both the large disparity and the non-Lambertian challenges compared with other state-of-the-art approaches. In addition to the view interpolation for an LF, we also show that the proposed pipeline also benefits light field view extrapolation.
* 15 pages, 12 figures. Accepted by IEEE TPAMI
Data-Uncertainty Guided Multi-Phase Learning for Semi-Supervised Object Detection
Mar 29, 2021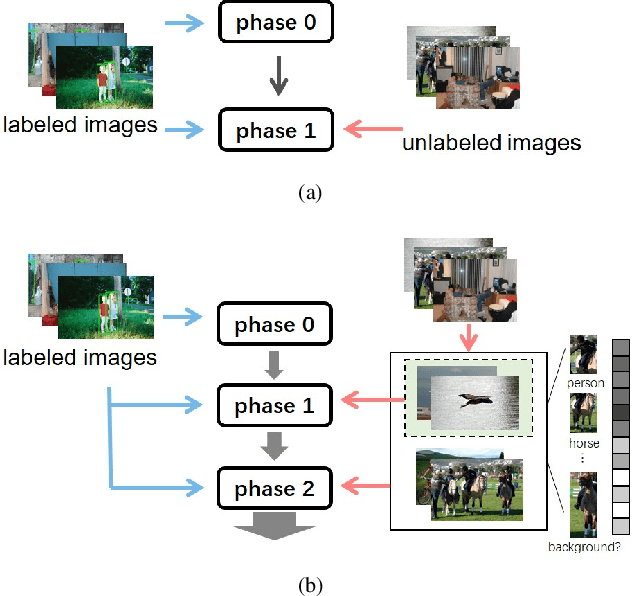
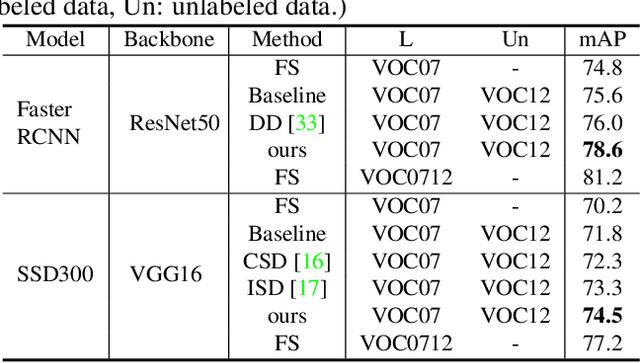
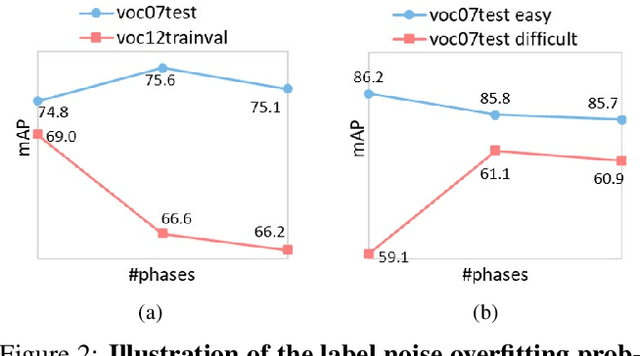
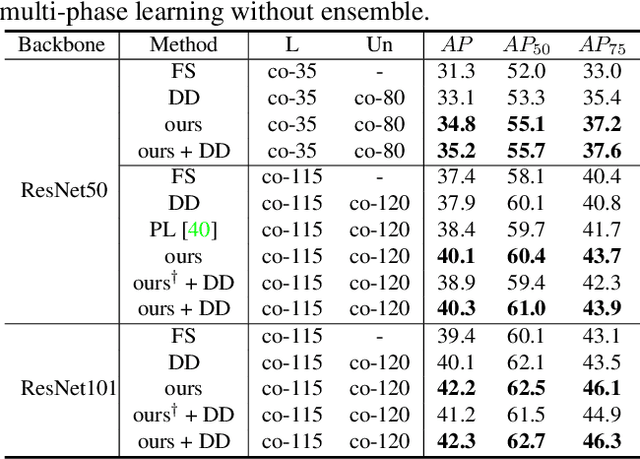
In this paper, we delve into semi-supervised object detection where unlabeled images are leveraged to break through the upper bound of fully-supervised object detection models. Previous semi-supervised methods based on pseudo labels are severely degenerated by noise and prone to overfit to noisy labels, thus are deficient in learning different unlabeled knowledge well. To address this issue, we propose a data-uncertainty guided multi-phase learning method for semi-supervised object detection. We comprehensively consider divergent types of unlabeled images according to their difficulty levels, utilize them in different phases and ensemble models from different phases together to generate ultimate results. Image uncertainty guided easy data selection and region uncertainty guided RoI Re-weighting are involved in multi-phase learning and enable the detector to concentrate on more certain knowledge. Through extensive experiments on PASCAL VOC and MS COCO, we demonstrate that our method behaves extraordinarily compared to baseline approaches and outperforms them by a large margin, more than 3% on VOC and 2% on COCO.
Light Field Reconstruction Using Convolutional Network on EPI and Extended Applications
Mar 24, 2021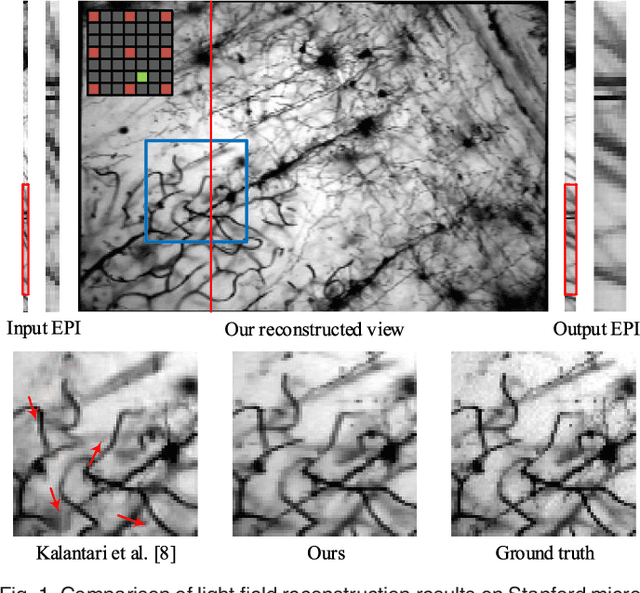
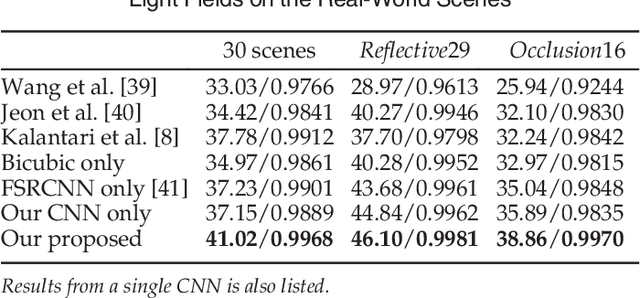


In this paper, a novel convolutional neural network (CNN)-based framework is developed for light field reconstruction from a sparse set of views. We indicate that the reconstruction can be efficiently modeled as angular restoration on an epipolar plane image (EPI). The main problem in direct reconstruction on the EPI involves an information asymmetry between the spatial and angular dimensions, where the detailed portion in the angular dimensions is damaged by undersampling. Directly upsampling or super-resolving the light field in the angular dimensions causes ghosting effects. To suppress these ghosting effects, we contribute a novel "blur-restoration-deblur" framework. First, the "blur" step is applied to extract the low-frequency components of the light field in the spatial dimensions by convolving each EPI slice with a selected blur kernel. Then, the "restoration" step is implemented by a CNN, which is trained to restore the angular details of the EPI. Finally, we use a non-blind "deblur" operation to recover the spatial high frequencies suppressed by the EPI blur. We evaluate our approach on several datasets, including synthetic scenes, real-world scenes and challenging microscope light field data. We demonstrate the high performance and robustness of the proposed framework compared with state-of-the-art algorithms. We further show extended applications, including depth enhancement and interpolation for unstructured input. More importantly, a novel rendering approach is presented by combining the proposed framework and depth information to handle large disparities.
* Published in IEEE TPAMI, 2019