 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly supervised cross-domain alignment with optimal transport
Aug 14, 2020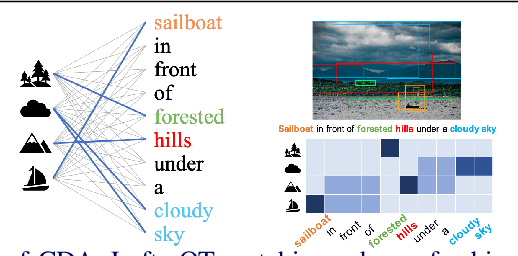
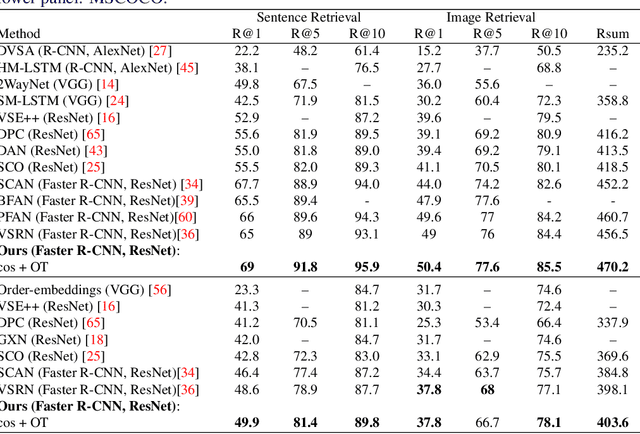
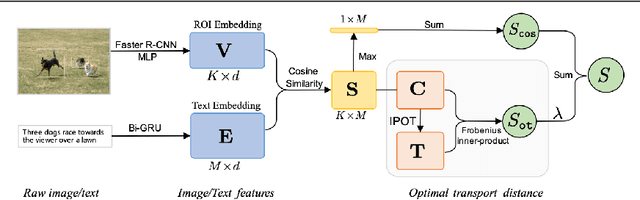
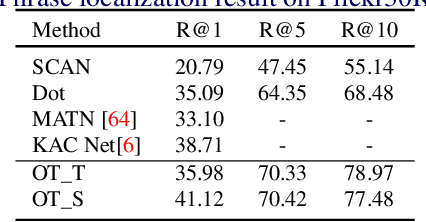
Cross-domain alignment between image objects and text sequences is key to many visual-language tasks, and it poses a fundamental challenge to both computer vision and natural language processing. This paper investigates a novel approach for the identification and optimization of fine-grained semantic similarities between image and text entities, under a weakly-supervised setup, improving performance over state-of-the-art solutions. Our method builds upon recent advances in optimal transport (OT) to resolve the cross-domain matching problem in a principled manner. Formulated as a drop-in regularizer, the proposed OT solution can be efficiently computed and used in combination with other existing approaches. We present empirical evidence to demonstrate the effectiveness of our approach, showing how it enables simpler model architectures to outperform or be comparable with more sophisticated designs on a range of vision-language tasks.
Graph Optimal Transport for Cross-Domain Alignment
Jun 29, 2020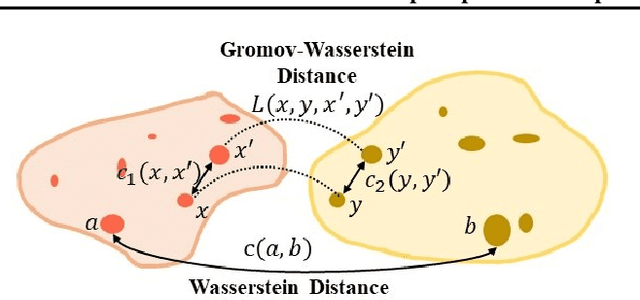
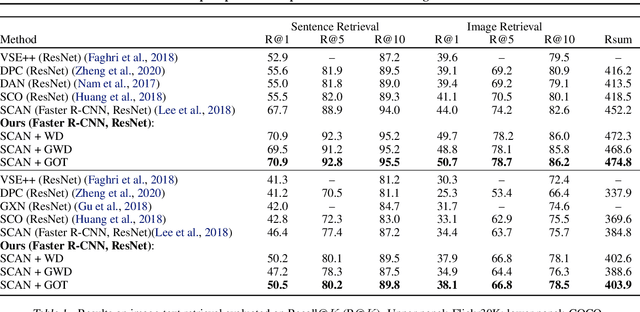
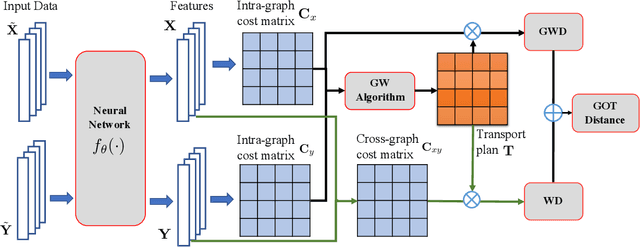
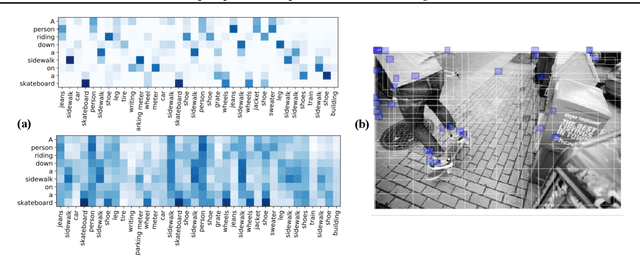
Cross-domain alignment between two sets of entities (e.g., objects in an image, words in a sentence) is fundamental to both computer vision and natural language processing. Existing methods mainly focus on designing advanced attention mechanisms to simulate soft alignment, with no training signals to explicitly encourage alignment. The learned attention matrices are also dense and lacks interpretability. We propose Graph Optimal Transport (GOT), a principled framework that germinates from recent advances in Optimal Transport (OT). In GOT, cross-domain alignment is formulated as a graph matching problem, by representing entities into a dynamically-constructed graph. Two types of OT distances are considered: (i) Wasserstein distance (WD) for node (entity) matching; and (ii) Gromov-Wasserstein distance (GWD) for edge (structure) matching. Both WD and GWD can be incorporated into existing neural network models, effectively acting as a drop-in regularizer. The inferred transport plan also yields sparse and self-normalized alignment, enhancing the interpretability of the learned model. Experiments show consistent outperformance of GOT over baselines across a wide range of tasks, including image-text retrieval, visual question answering, image captioning, machine translation, and text summarization.
Graph-Driven Generative Models for Heterogeneous Multi-Task Learning
Nov 20, 2019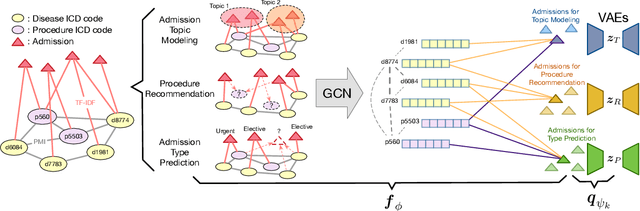


We propose a novel graph-driven generative model, that unifies multiple heterogeneous learning tasks into the same framework. The proposed model is based on the fact that heterogeneous learning tasks, which correspond to different generative processes, often rely on data with a shared graph structure. Accordingly, our model combines a graph convolutional network (GCN) with multiple variational autoencoders, thus embedding the nodes of the graph i.e., samples for the tasks) in a uniform manner while specializing their organization and usage to different tasks. With a focus on healthcare applications (tasks), including clinical topic modeling, procedure recommendation and admission-type prediction, we demonstrate that our method successfully leverages information across different tasks, boosting performance in all tasks and outperforming existing state-of-the-art approaches.
Improving Textual Network Learning with Variational Homophilic Embeddings
Sep 30, 2019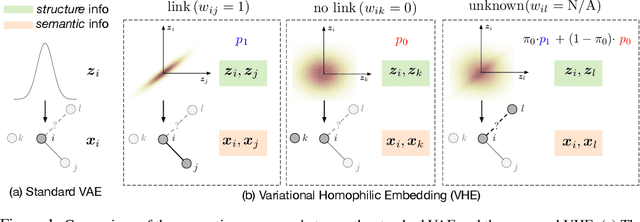
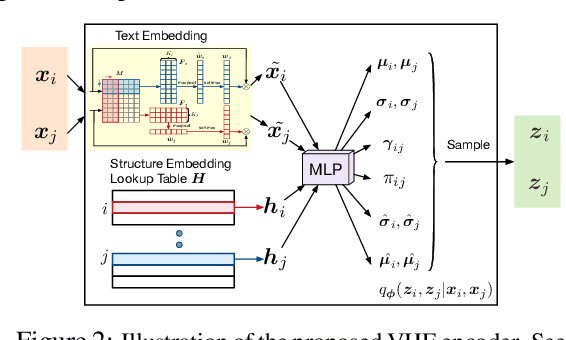
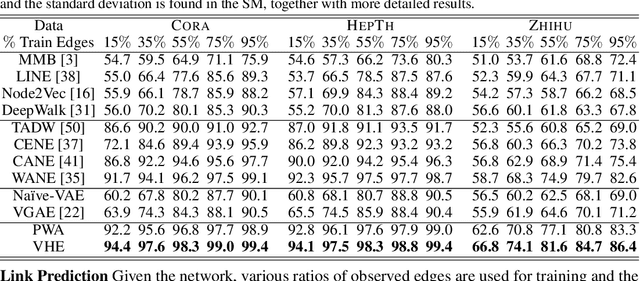
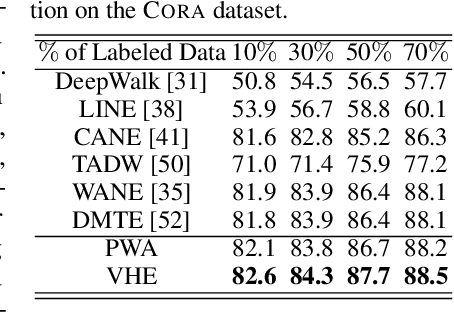
The performance of many network learning applications crucially hinges on the success of network embedding algorithms, which aim to encode rich network information into low-dimensional vertex-based vector representations. This paper considers a novel variational formulation of network embeddings, with special focus on textual networks. Different from most existing methods that optimize a discriminative objective, we introduce Variational Homophilic Embedding (VHE), a fully generative model that learns network embeddings by modeling the semantic (textual) information with a variational autoencoder, while accounting for the structural (topology) information through a novel homophilic prior design. Homophilic vertex embeddings encourage similar embedding vectors for related (connected) vertices. The proposed VHE promises better generalization for downstream tasks, robustness to incomplete observations, and the ability to generalize to unseen vertices. Extensive experiments on real-world networks, for multiple tasks, demonstrate that the proposed method consistently achieves superior performance relative to competing state-of-the-art approaches.
LMVP: Video Predictor with Leaked Motion Information
Jun 24, 2019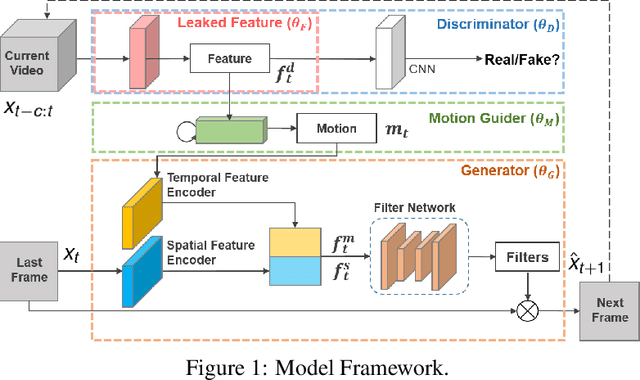
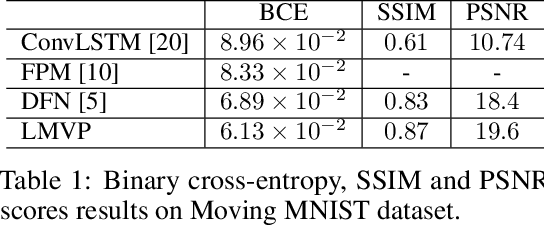


We propose a Leaked Motion Video Predictor (LMVP) to predict future frames by capturing the spatial and temporal dependencies from given inputs. The motion is modeled by a newly proposed component, motion guider, which plays the role of both learner and teacher. Specifically, it {\em learns} the temporal features from real data and {\em guides} the generator to predict future frames. The spatial consistency in video is modeled by an adaptive filtering network. To further ensure the spatio-temporal consistency of the prediction, a discriminator is also adopted to distinguish the real and generated frames. Further, the discriminator leaks information to the motion guider and the generator to help the learning of motion. The proposed LMVP can effectively learn the static and temporal features in videos without the need for human labeling. Experiments on synthetic and real data demonstrate that LMVP can yield state-of-the-art results.
Improving Textual Network Embedding with Global Attention via Optimal Transport
Jun 05, 2019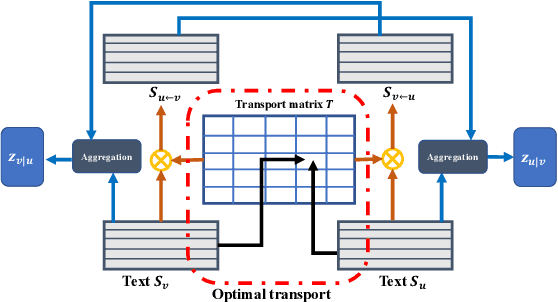
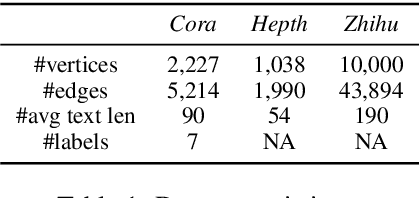
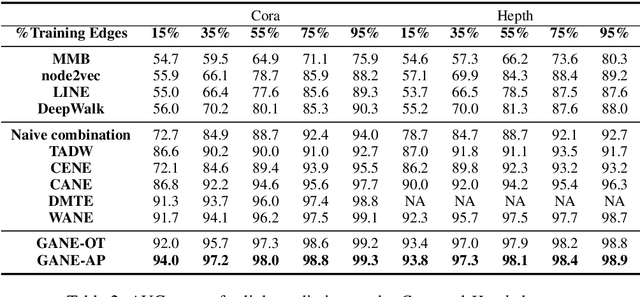
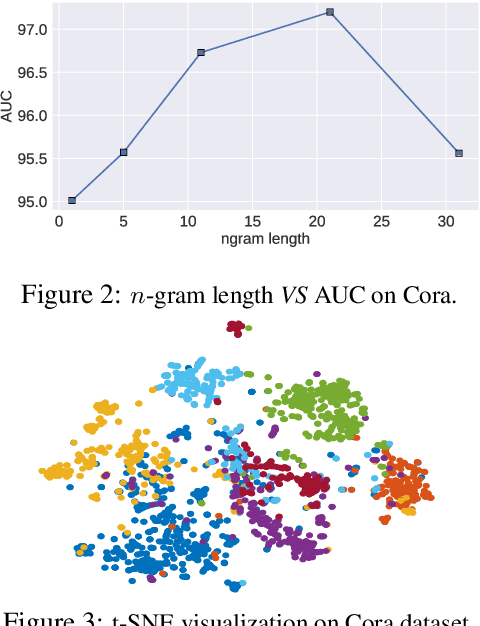
Constituting highly informative network embeddings is an important tool for network analysis. It encodes network topology, along with other useful side information, into low-dimensional node-based feature representations that can be exploited by statistical modeling. This work focuses on learning context-aware network embeddings augmented with text data. We reformulate the network-embedding problem, and present two novel strategies to improve over traditional attention mechanisms: ($i$) a content-aware sparse attention module based on optimal transport, and ($ii$) a high-level attention parsing module. Our approach yields naturally sparse and self-normalized relational inference. It can capture long-term interactions between sequences, thus addressing the challenges faced by existing textual network embedding schemes. Extensive experiments are conducted to demonstrate our model can consistently outperform alternative state-of-the-art methods.
Towards Generating Long and Coherent Text with Multi-Level Latent Variable Models
Feb 01, 2019
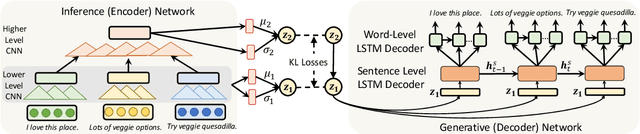
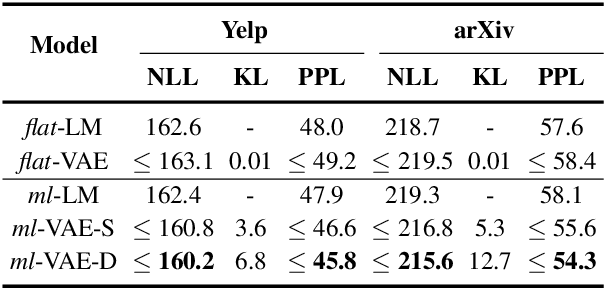
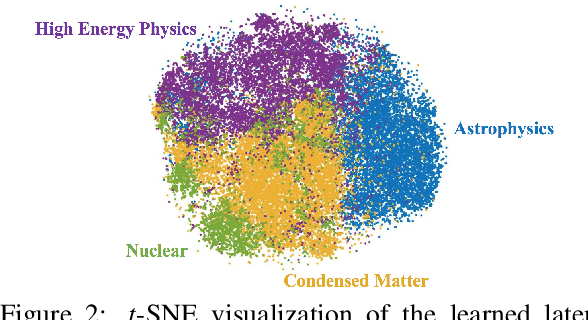
Variational autoencoders (VAEs) have received much attention recently as an end-to-end architecture for text generation with latent variables. In this paper, we investigate several multi-level structures to learn a VAE model to generate long, and coherent text. In particular, we use a hierarchy of stochastic layers between the encoder and decoder networks to generate more informative latent codes. We also investigate a multi-level decoder structure to learn a coherent long-term structure by generating intermediate sentence representations as high-level plan vectors. Empirical results demonstrate that a multi-level VAE model produces more coherent and less repetitive long text compared to the standard VAE models and can further mitigate the posterior-collapse issue.
Improving Sequence-to-Sequence Learning via Optimal Transport
Jan 18, 2019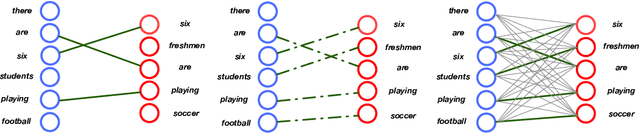
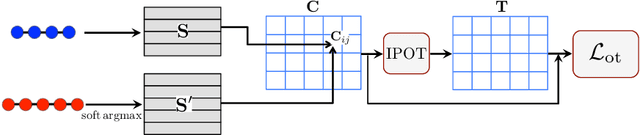
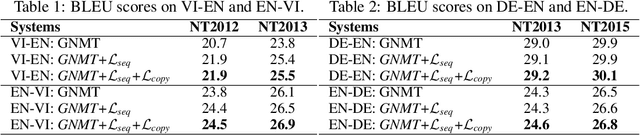
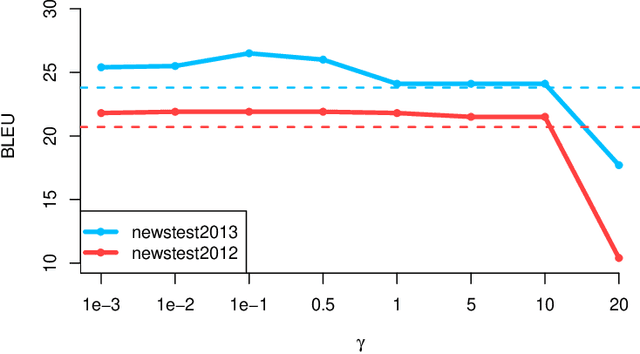
Sequence-to-sequence models are commonly trained via maximum likelihood estimation (MLE). However, standard MLE training considers a word-level objective, predicting the next word given the previous ground-truth partial sentence. This procedure focuses on modeling local syntactic patterns, and may fail to capture long-range semantic structure. We present a novel solution to alleviate these issues. Our approach imposes global sequence-level guidance via new supervision based on optimal transport, enabling the overall characterization and preservation of semantic features. We further show that this method can be understood as a Wasserstein gradient flow trying to match our model to the ground truth sequence distribution. Extensive experiments are conducted to validate the utility of the proposed approach, showing consistent improvements over a wide variety of NLP tasks, including machine translation, abstractive text summarization, and image captioning.
Sequence Generation with Guider Network
Nov 02, 2018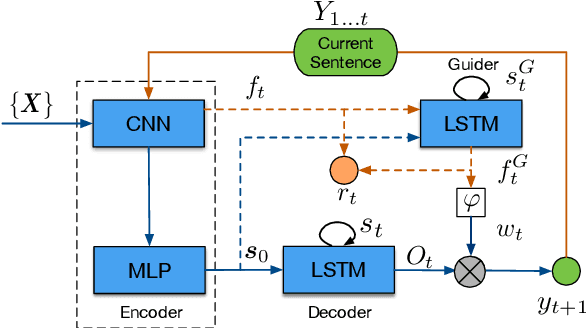
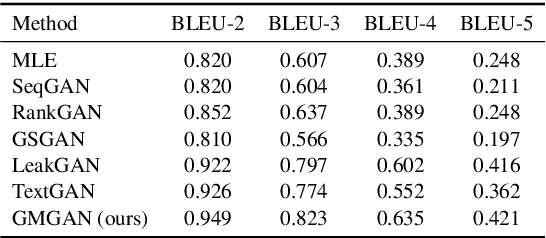
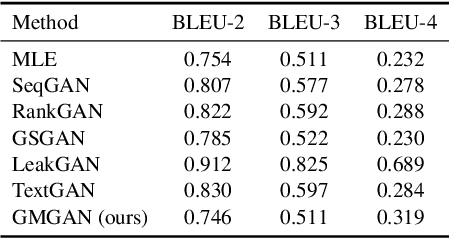
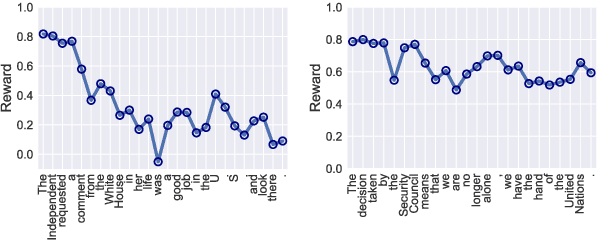
Sequence generation with reinforcement learning (RL) has received significant attention recently. However, a challenge with such methods is the sparse-reward problem in the RL training process, in which a scalar guiding signal is often only available after an entire sequence has been generated. This type of sparse reward tends to ignore the global structural information of a sequence, causing generation of sequences that are semantically inconsistent. In this paper, we present a model-based RL approach to overcome this issue. Specifically, we propose a novel guider network to model the sequence-generation environment, which can assist next-word prediction and provide intermediate rewards for generator optimization. Extensive experiments show that the proposed method leads to improved performance for both unconditional and conditional sequence-generation tasks.
Adversarial Text Generation via Feature-Mover's Distance
Sep 17, 2018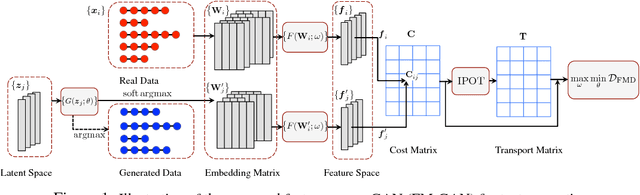

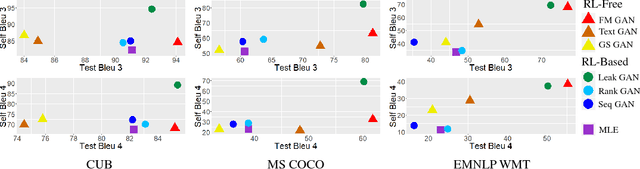

Generative adversarial networks (GANs) have achieved significant success in generating real-valued data. However, the discrete nature of text hinders the application of GAN to text-generation tasks. Instead of using the standard GAN objective, we propose to improve text-generation GAN via a novel approach inspired by optimal transport. Specifically, we consider matching the latent feature distributions of real and synthetic sentences using a novel metric, termed the feature-mover's distance (FMD). This formulation leads to a highly discriminative critic and easy-to-optimize objective, overcoming the mode-collapsing and brittle-training problems in existing methods. Extensive experiments are conducted on a variety of tasks to evaluate the proposed model empirically, including unconditional text generation, style transfer from non-parallel text, and unsupervised cipher cracking. The proposed model yields superior performance, demonstrating wide applicability and effectiveness.