 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards AGI in Computer Vision: Lessons Learned from GPT and Large Language Models
Jun 14, 2023



The AI community has been pursuing algorithms known as artificial general intelligence (AGI) that apply to any kind of real-world problem. Recently, chat systems powered by large language models (LLMs) emerge and rapidly become a promising direction to achieve AGI in natural language processing (NLP), but the path towards AGI in computer vision (CV) remains unclear. One may owe the dilemma to the fact that visual signals are more complex than language signals, yet we are interested in finding concrete reasons, as well as absorbing experiences from GPT and LLMs to solve the problem. In this paper, we start with a conceptual definition of AGI and briefly review how NLP solves a wide range of tasks via a chat system. The analysis inspires us that unification is the next important goal of CV. But, despite various efforts in this direction, CV is still far from a system like GPT that naturally integrates all tasks. We point out that the essential weakness of CV lies in lacking a paradigm to learn from environments, yet NLP has accomplished the task in the text world. We then imagine a pipeline that puts a CV algorithm (i.e., an agent) in world-scale, interactable environments, pre-trains it to predict future frames with respect to its action, and then fine-tunes it with instruction to accomplish various tasks. We expect substantial research and engineering efforts to push the idea forward and scale it up, for which we share our perspectives on future research directions.
Visual Tuning
May 10, 2023Fine-tuning visual models has been widely shown promising performance on many downstream visual tasks. With the surprising development of pre-trained visual foundation models, visual tuning jumped out of the standard modus operandi that fine-tunes the whole pre-trained model or just the fully connected layer. Instead, recent advances can achieve superior performance than full-tuning the whole pre-trained parameters by updating far fewer parameters, enabling edge devices and downstream applications to reuse the increasingly large foundation models deployed on the cloud. With the aim of helping researchers get the full picture and future directions of visual tuning, this survey characterizes a large and thoughtful selection of recent works, providing a systematic and comprehensive overview of existing work and models. Specifically, it provides a detailed background of visual tuning and categorizes recent visual tuning techniques into five groups: prompt tuning, adapter tuning, parameter tuning, and remapping tuning. Meanwhile, it offers some exciting research directions for prospective pre-training and various interactions in visual tuning.
Segment Anything in 3D with NeRFs
Apr 26, 2023The Segment Anything Model (SAM) has demonstrated its effectiveness in segmenting any object/part in various 2D images, yet its ability for 3D has not been fully explored. The real world is composed of numerous 3D scenes and objects. Due to the scarcity of accessible 3D data and high cost of its acquisition and annotation, lifting SAM to 3D is a challenging but valuable research avenue. With this in mind, we propose a novel framework to Segment Anything in 3D, named SA3D. Given a neural radiance field (NeRF) model, SA3D allows users to obtain the 3D segmentation result of any target object via only one-shot manual prompting in a single rendered view. With input prompts, SAM cuts out the target object from the according view. The obtained 2D segmentation mask is projected onto 3D mask grids via density-guided inverse rendering. 2D masks from other views are then rendered, which are mostly uncompleted but used as cross-view self-prompts to be fed into SAM again. Complete masks can be obtained and projected onto mask grids. This procedure is executed via an iterative manner while accurate 3D masks can be finally learned. SA3D can adapt to various radiance fields effectively without any additional redesigning. The entire segmentation process can be completed in approximately two minutes without any engineering optimization. Our experiments demonstrate the effectiveness of SA3D in different scenes, highlighting the potential of SAM in 3D scene perception. The project page is at https://jumpat.github.io/SA3D/.
Pipeline MoE: A Flexible MoE Implementation with Pipeline Parallelism
Apr 22, 2023



The Mixture of Experts (MoE) model becomes an important choice of large language models nowadays because of its scalability with sublinear computational complexity for training and inference. However, existing MoE models suffer from two critical drawbacks, 1) tremendous inner-node and inter-node communication overhead introduced by all-to-all dispatching and gathering, and 2) limited scalability for the backbone because of the bound data parallel and expert parallel to scale in the expert dimension. In this paper, we systematically analyze these drawbacks in terms of training efficiency in the parallel framework view and propose a novel MoE architecture called Pipeline MoE (PPMoE) to tackle them. PPMoE builds expert parallel incorporating with tensor parallel and replaces communication-intensive all-to-all dispatching and gathering with a simple tensor index slicing and inner-node all-reduce. Besides, it is convenient for PPMoE to integrate pipeline parallel to further scale the backbone due to its flexible parallel architecture. Extensive experiments show that PPMoE not only achieves a more than $1.75\times$ speed up compared to existing MoE architectures but also reaches $90\%$ throughput of its corresponding backbone model that is $20\times$ smaller.
Focus on Your Target: A Dual Teacher-Student Framework for Domain-adaptive Semantic Segmentation
Mar 16, 2023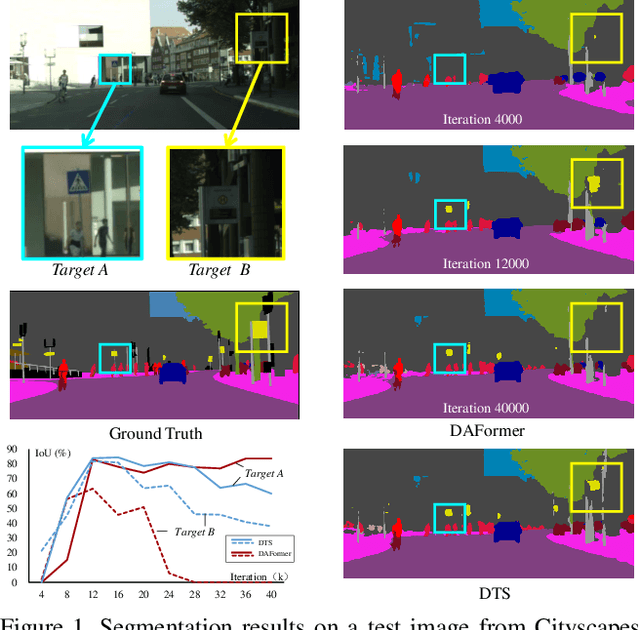
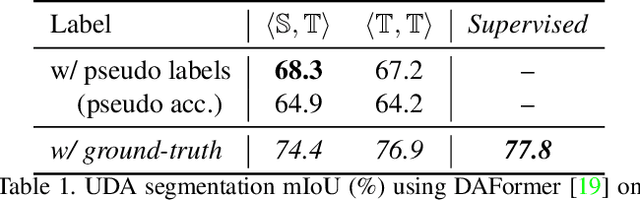
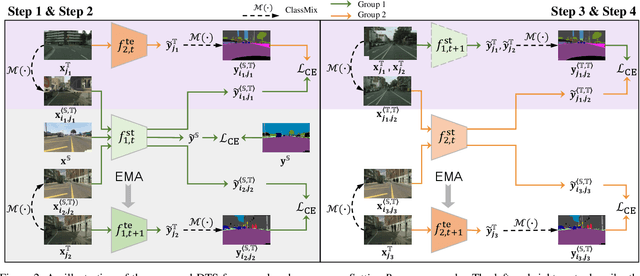
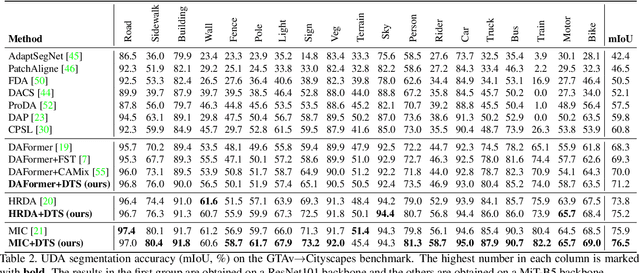
We study unsupervised domain adaptation (UDA) for semantic segmentation. Currently, a popular UDA framework lies in self-training which endows the model with two-fold abilities: (i) learning reliable semantics from the labeled images in the source domain, and (ii) adapting to the target domain via generating pseudo labels on the unlabeled images. We find that, by decreasing/increasing the proportion of training samples from the target domain, the 'learning ability' is strengthened/weakened while the 'adapting ability' goes in the opposite direction, implying a conflict between these two abilities, especially for a single model. To alleviate the issue, we propose a novel dual teacher-student (DTS) framework and equip it with a bidirectional learning strategy. By increasing the proportion of target-domain data, the second teacher-student model learns to 'Focus on Your Target' while the first model is not affected. DTS is easily plugged into existing self-training approaches. In a standard UDA scenario (training on synthetic, labeled data and real, unlabeled data), DTS shows consistent gains over the baselines and sets new state-of-the-art results of 76.5\% and 75.1\% mIoUs on GTAv$\rightarrow$Cityscapes and SYNTHIA$\rightarrow$Cityscapes, respectively.
USAGE: A Unified Seed Area Generation Paradigm for Weakly Supervised Semantic Segmentation
Mar 14, 2023



Seed area generation is usually the starting point of weakly supervised semantic segmentation (WSSS). Computing the Class Activation Map (CAM) from a multi-label classification network is the de facto paradigm for seed area generation, but CAMs generated from Convolutional Neural Networks (CNNs) and Transformers are prone to be under- and over-activated, respectively, which makes the strategies to refine CAMs for CNNs usually inappropriate for Transformers, and vice versa. In this paper, we propose a Unified optimization paradigm for Seed Area GEneration (USAGE) for both types of networks, in which the objective function to be optimized consists of two terms: One is a generation loss, which controls the shape of seed areas by a temperature parameter following a deterministic principle for different types of networks; The other is a regularization loss, which ensures the consistency between the seed areas that are generated by self-adaptive network adjustment from different views, to overturn false activation in seed areas. Experimental results show that USAGE consistently improves seed area generation for both CNNs and Transformers by large margins, e.g., outperforming state-of-the-art methods by a mIoU of 4.1% on PASCAL VOC. Moreover, based on the USAGE-generated seed areas on Transformers, we achieve state-of-the-art WSSS results on both PASCAL VOC and MS COCO.
Integrally Pre-Trained Transformer Pyramid Networks
Nov 23, 2022



In this paper, we present an integral pre-training framework based on masked image modeling (MIM). We advocate for pre-training the backbone and neck jointly so that the transfer gap between MIM and downstream recognition tasks is minimal. We make two technical contributions. First, we unify the reconstruction and recognition necks by inserting a feature pyramid into the pre-training stage. Second, we complement mask image modeling (MIM) with masked feature modeling (MFM) that offers multi-stage supervision to the feature pyramid. The pre-trained models, termed integrally pre-trained transformer pyramid networks (iTPNs), serve as powerful foundation models for visual recognition. In particular, the base/large-level iTPN achieves an 86.2%/87.8% top-1 accuracy on ImageNet-1K, a 53.2%/55.6% box AP on COCO object detection with 1x training schedule using Mask-RCNN, and a 54.7%/57.7% mIoU on ADE20K semantic segmentation using UPerHead -- all these results set new records. Our work inspires the community to work on unifying upstream pre-training and downstream fine-tuning tasks. Code and the pre-trained models will be released at https://github.com/sunsmarterjie/iTPN.
Understanding and Mitigating Overfitting in Prompt Tuning for Vision-Language Models
Nov 14, 2022Pre-trained Vision-Language Models (VLMs) such as CLIP have shown impressive generalization capability in downstream vision tasks with appropriate text prompts. Instead of designing prompts manually, Context Optimization (CoOp) has been recently proposed to learn continuous prompts using task-specific training data. Despite the performance improvements on downstream tasks, several studies have reported that CoOp suffers from the overfitting issue in two aspects: (i) the test accuracy on base classes first gets better and then gets worse during training; (ii) the test accuracy on novel classes keeps decreasing. However, none of the existing studies can understand and mitigate such overfitting problem effectively. In this paper, we first explore the cause of overfitting by analyzing the gradient flow. Comparative experiments reveal that CoOp favors generalizable and spurious features in the early and later training stages respectively, leading to the non-overfitting and overfitting phenomenon. Given those observations, we propose Subspace Prompt Tuning (SubPT) to project the gradients in back-propagation onto the low-rank subspace spanned by the early-stage gradient flow eigenvectors during the entire training process, and successfully eliminate the overfitting problem. Besides, we equip CoOp with Novel Feature Learner (NFL) to enhance the generalization ability of the learned prompts onto novel categories beyond the training set, needless of image training data. Extensive experiments on 11 classification datasets demonstrate that SubPT+NFL consistently boost the performance of CoOp and outperform the state-of-the-art approach CoCoOp. Experiments on more challenging vision downstream tasks including open-vocabulary object detection and zero-shot semantic segmentation also verify the effectiveness of the proposed method. Codes can be found at https://tinyurl.com/mpe64f89.
Pangu-Weather: A 3D High-Resolution Model for Fast and Accurate Global Weather Forecast
Nov 03, 2022



In this paper, we present Pangu-Weather, a deep learning based system for fast and accurate global weather forecast. For this purpose, we establish a data-driven environment by downloading $43$ years of hourly global weather data from the 5th generation of ECMWF reanalysis (ERA5) data and train a few deep neural networks with about $256$ million parameters in total. The spatial resolution of forecast is $0.25^\circ\times0.25^\circ$, comparable to the ECMWF Integrated Forecast Systems (IFS). More importantly, for the first time, an AI-based method outperforms state-of-the-art numerical weather prediction (NWP) methods in terms of accuracy (latitude-weighted RMSE and ACC) of all factors (e.g., geopotential, specific humidity, wind speed, temperature, etc.) and in all time ranges (from one hour to one week). There are two key strategies to improve the prediction accuracy: (i) designing a 3D Earth Specific Transformer (3DEST) architecture that formulates the height (pressure level) information into cubic data, and (ii) applying a hierarchical temporal aggregation algorithm to alleviate cumulative forecast errors. In deterministic forecast, Pangu-Weather shows great advantages for short to medium-range forecast (i.e., forecast time ranges from one hour to one week). Pangu-Weather supports a wide range of downstream forecast scenarios, including extreme weather forecast (e.g., tropical cyclone tracking) and large-member ensemble forecast in real-time. Pangu-Weather not only ends the debate on whether AI-based methods can surpass conventional NWP methods, but also reveals novel directions for improving deep learning weather forecast systems.
Learnable Distribution Calibration for Few-Shot Class-Incremental Learning
Oct 01, 2022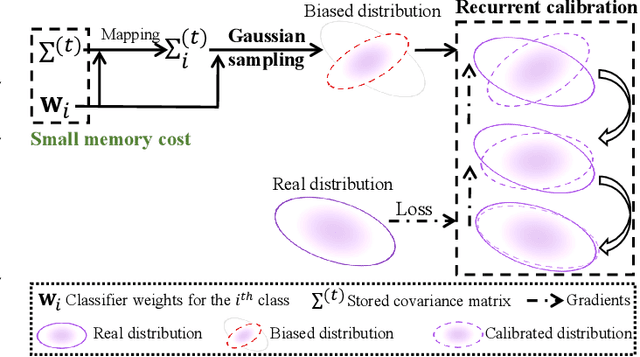



Few-shot class-incremental learning (FSCIL) faces challenges of memorizing old class distributions and estimating new class distributions given few training samples. In this study, we propose a learnable distribution calibration (LDC) approach, with the aim to systematically solve these two challenges using a unified framework. LDC is built upon a parameterized calibration unit (PCU), which initializes biased distributions for all classes based on classifier vectors (memory-free) and a single covariance matrix. The covariance matrix is shared by all classes, so that the memory costs are fixed. During base training, PCU is endowed with the ability to calibrate biased distributions by recurrently updating sampled features under the supervision of real distributions. During incremental learning, PCU recovers distributions for old classes to avoid `forgetting', as well as estimating distributions and augmenting samples for new classes to alleviate `over-fitting' caused by the biased distributions of few-shot samples. LDC is theoretically plausible by formatting a variational inference procedure. It improves FSCIL's flexibility as the training procedure requires no class similarity priori. Experiments on CUB200, CIFAR100, and mini-ImageNet datasets show that LDC outperforms the state-of-the-arts by 4.64%, 1.98%, and 3.97%, respectively. LDC's effectiveness is also validated on few-shot learning scenarios.