 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossing Variational Autoencoders for Answer Retrieval
May 06, 2020
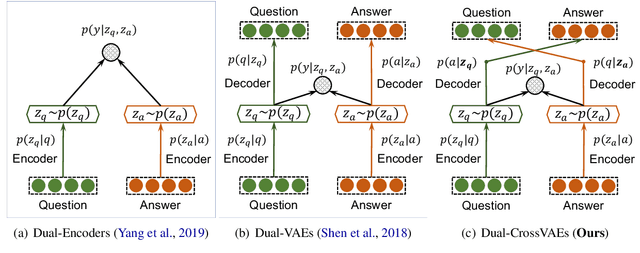
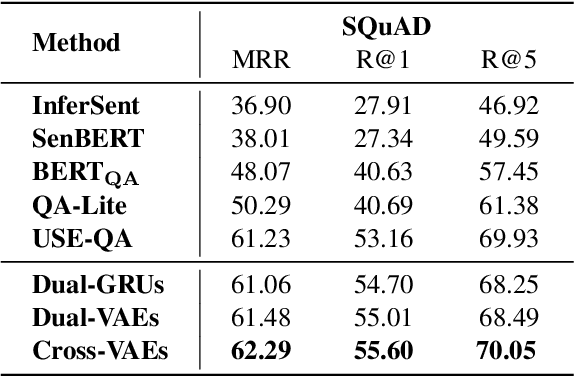
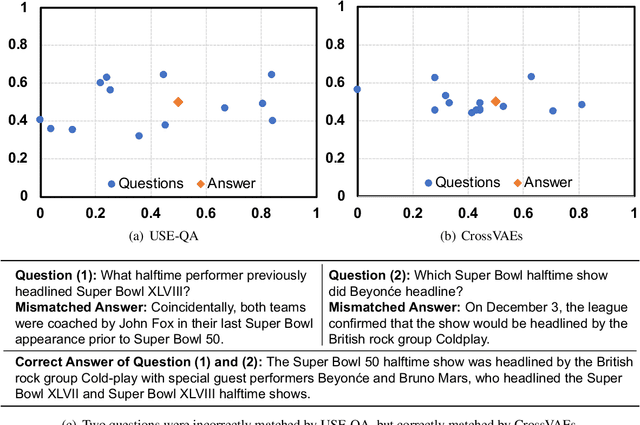
Answer retrieval is to find the most aligned answer from a large set of candidates given a question. Learning vector representations of questions/answers is the key factor. Question-answer alignment and question/answer semantics are two important signals for learning the representations. Existing methods learned semantic representations with dual encoders or dual variational auto-encoders. The semantic information was learned from language models or question-to-question (answer-to-answer) generative processes. However, the alignment and semantics were too separate to capture the aligned semantics between question and answer. In this work, we propose to cross variational auto-encoders by generating questions with aligned answers and generating answers with aligned questions. Experiments show that our method outperforms the state-of-the-art answer retrieval method on SQuAD.
Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward
May 03, 2020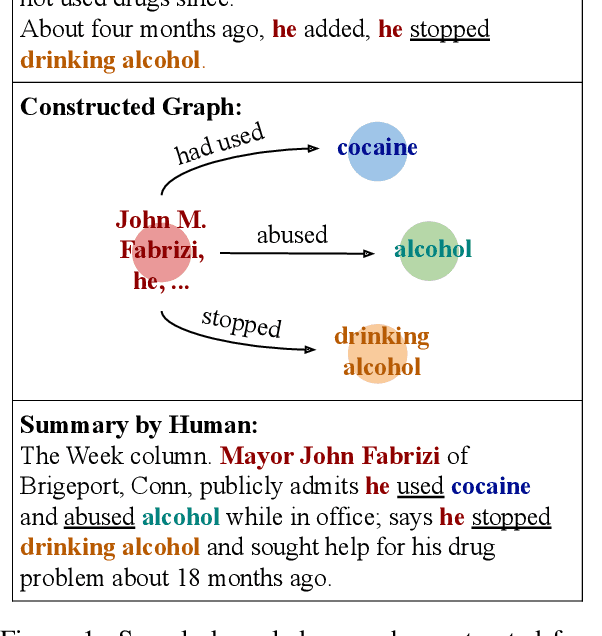
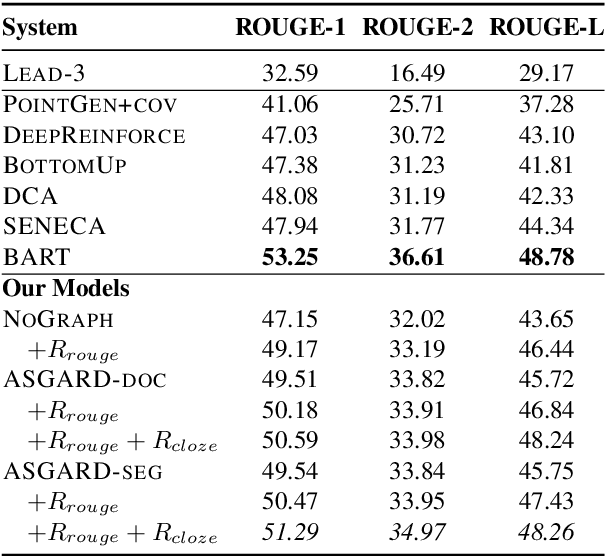
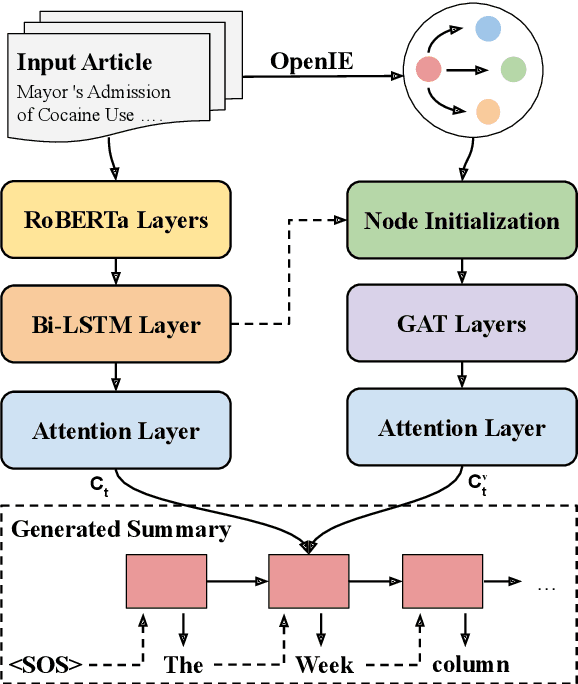
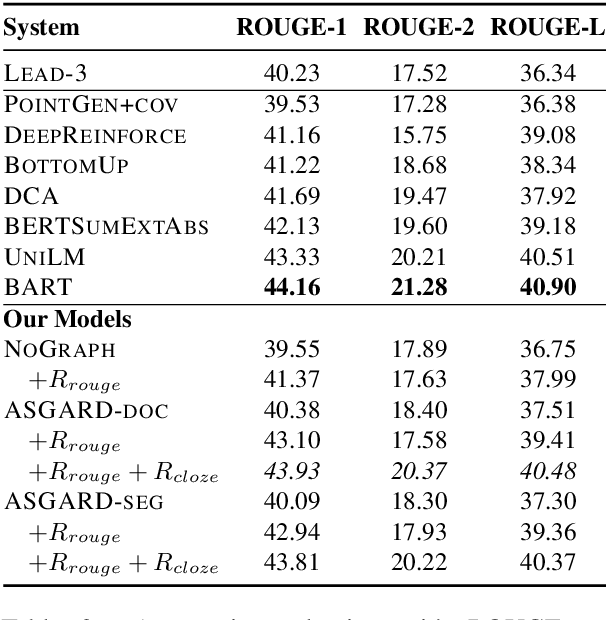
Sequence-to-sequence models for abstractive summarization have been studied extensively, yet the generated summaries commonly suffer from fabricated content, and are often found to be near-extractive. We argue that, to address these issues, the summarizer should acquire semantic interpretation over input, e.g., via structured representation, to allow the generation of more informative summaries. In this paper, we present ASGARD, a novel framework for Abstractive Summarization with Graph-Augmentation and semantic-driven RewarD. We propose the use of dual encoders---a sequential document encoder and a graph-structured encoder---to maintain the global context and local characteristics of entities, complementing each other. We further design a reward based on a multiple choice cloze test to drive the model to better capture entity interactions. Results show that our models produce significantly higher ROUGE scores than a variant without knowledge graph as input on both New York Times and CNN/Daily Mail datasets. We also obtain better or comparable performance compared to systems that are fine-tuned from large pretrained language models. Human judges further rate our model outputs as more informative and containing fewer unfaithful errors.
Toward Subgraph Guided Knowledge Graph Question Generation with Graph Neural Networks
Apr 13, 2020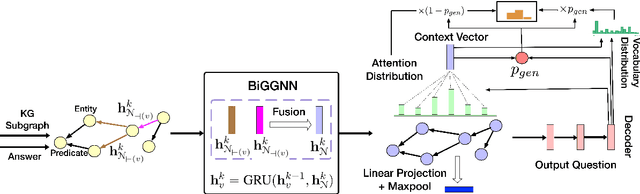

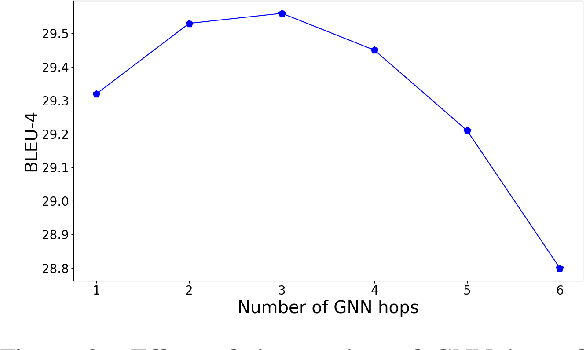
Knowledge graph question generation (QG) aims to generate natural language questions from KG and target answers. Most previous works mainly focusing on the simple setting are to generate questions from a single KG triple. In this work, we focus on a more realistic setting, where we aim to generate questions from a KG subgraph and target answers. In addition, most of previous works built on either RNN-based or Transformer-based models to encode a KG sugraph, which totally discard the explicit structure information contained in a KG subgraph. To address this issue, we propose to apply a bidirectional Graph2Seq model to encode the KG subgraph. In addition, we enhance our RNN decoder with node-level copying mechanism to allow directly copying node attributes from the input graph to the output question. We also explore different ways of initializing node/edge embeddings and handling multi-relational graphs. Our model is end-to-end trainable and achieves new state-of-the-art scores, outperforming existing methods by a significant margin on the two benchmarks.
Graph-to-Tree Neural Networks for Learning Structured Input-Output Translation with Applications to Semantic Parsing and Math Word Problem
Apr 07, 2020
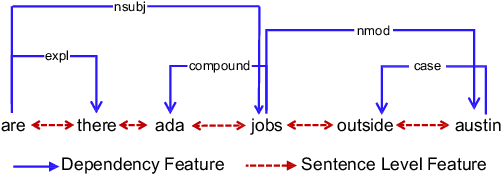
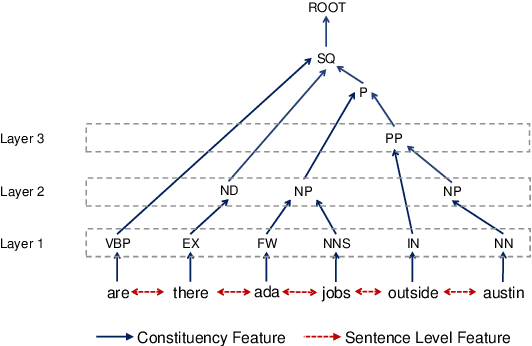
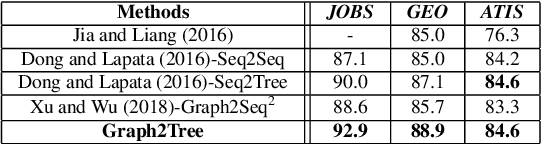
The celebrated Seq2Seq technique and its numerous variants achieve excellent performance on many tasks such as neural machine translation, semantic parsing, and math word problem solving. However, these models either only consider input objects as sequences while ignoring the important structural information for encoding, or they simply treat output objects as sequence outputs instead of structural objects for decoding. In this paper, we present a novel Graph-to-Tree Neural Networks, namely Graph2Tree consisting of a graph encoder and a hierarchical tree decoder, that encodes an augmented graph-structured input and decodes a tree-structured output. In particular, we investigated our model for solving two problems, neural semantic parsing and math word problem. Our extensive experiments demonstrate that our Graph2Tree model outperforms or matches the performance of other state-of-the-art models on these tasks.
Improved Code Summarization via a Graph Neural Network
Apr 07, 2020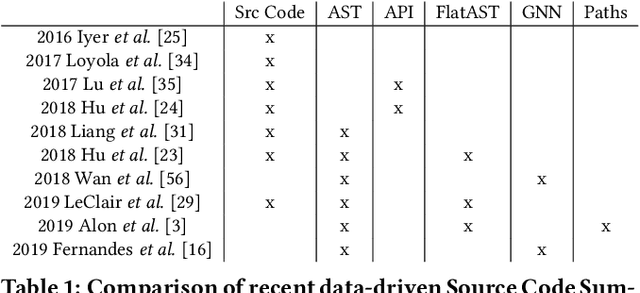
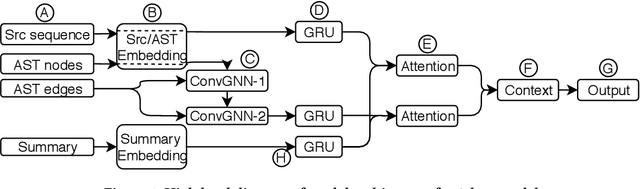
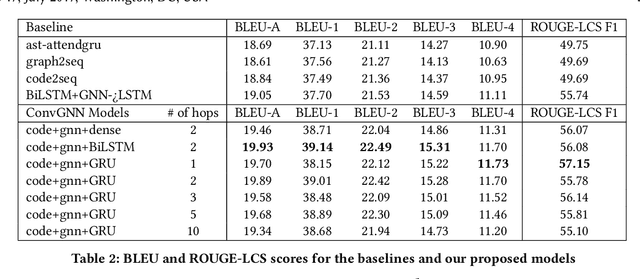
Automatic source code summarization is the task of generating natural language descriptions for source code. Automatic code summarization is a rapidly expanding research area, especially as the community has taken greater advantage of advances in neural network and AI technologies. In general, source code summarization techniques use the source code as input and outputs a natural language description. Yet a strong consensus is developing that using structural information as input leads to improved performance. The first approaches to use structural information flattened the AST into a sequence. Recently, more complex approaches based on random AST paths or graph neural networks have improved on the models using flattened ASTs. However, the literature still does not describe the using a graph neural network together with source code sequence as separate inputs to a model. Therefore, in this paper, we present an approach that uses a graph-based neural architecture that better matches the default structure of the AST to generate these summaries. We evaluate our technique using a data set of 2.1 million Java method-comment pairs and show improvement over four baseline techniques, two from the software engineering literature, and two from machine learning literature.
Deep Iterative and Adaptive Learning for Graph Neural Networks
Dec 17, 2019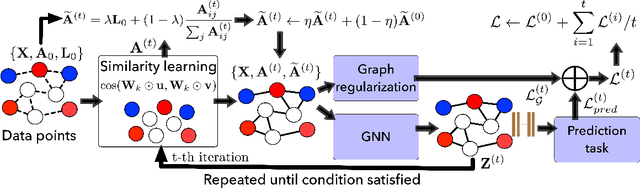
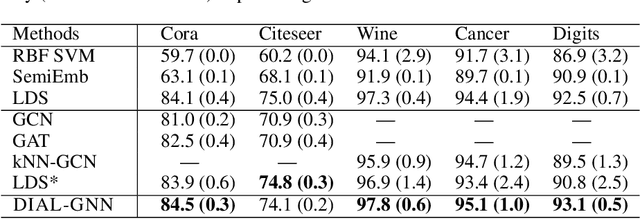
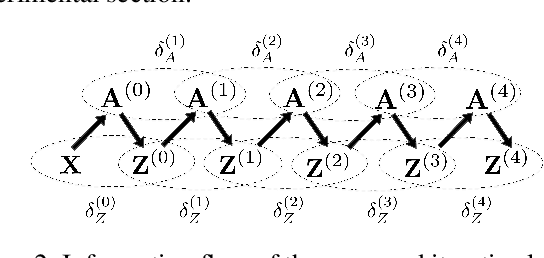
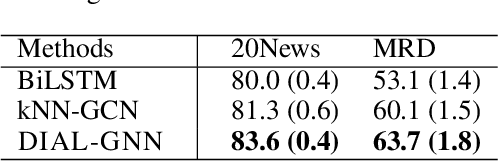
In this paper, we propose an end-to-end graph learning framework, namely Deep Iterative and Adaptive Learning for Graph Neural Networks (DIAL-GNN), for jointly learning the graph structure and graph embeddings simultaneously. We first cast the graph structure learning problem as a similarity metric learning problem and leverage an adapted graph regularization for controlling smoothness, connectivity and sparsity of the generated graph. We further propose a novel iterative method for searching for a hidden graph structure that augments the initial graph structure. Our iterative method dynamically stops when the learned graph structure approaches close enough to the optimal graph. Our extensive experiments demonstrate that the proposed DIAL-GNN model can consistently outperform or match state-of-the-art baselines in terms of both downstream task performance and computational time. The proposed approach can cope with both transductive learning and inductive learning.
Efficient Global String Kernel with Random Features: Beyond Counting Substructures
Nov 25, 2019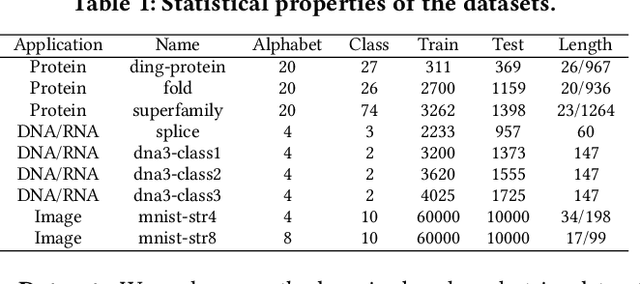
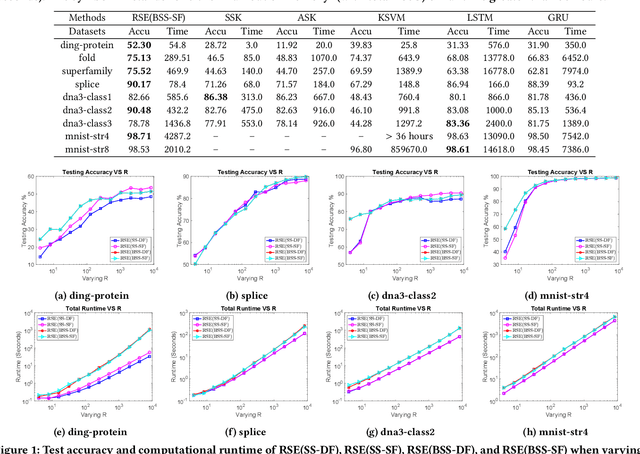
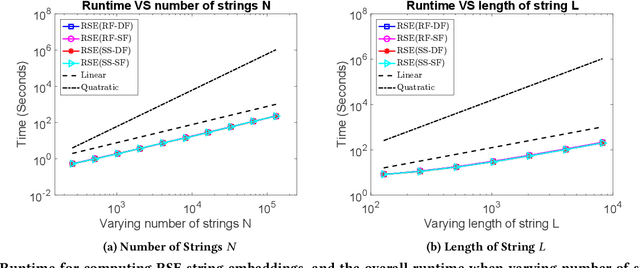
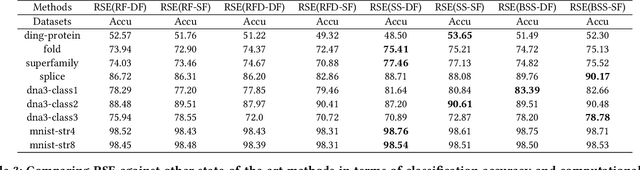
Analysis of large-scale sequential data has been one of the most crucial tasks in areas such as bioinformatics, text, and audio mining. Existing string kernels, however, either (i) rely on local features of short substructures in the string, which hardly capture long discriminative patterns, (ii) sum over too many substructures, such as all possible subsequences, which leads to diagonal dominance of the kernel matrix, or (iii) rely on non-positive-definite similarity measures derived from the edit distance. Furthermore, while there have been works addressing the computational challenge with respect to the length of string, most of them still experience quadratic complexity in terms of the number of training samples when used in a kernel-based classifier. In this paper, we present a new class of global string kernels that aims to (i) discover global properties hidden in the strings through global alignments, (ii) maintain positive-definiteness of the kernel, without introducing a diagonal dominant kernel matrix, and (iii) have a training cost linear with respect to not only the length of the string but also the number of training string samples. To this end, the proposed kernels are explicitly defined through a series of different random feature maps, each corresponding to a distribution of random strings. We show that kernels defined this way are always positive-definite, and exhibit computational benefits as they always produce \emph{Random String Embeddings (RSE)} that can be directly used in any linear classification models. Our extensive experiments on nine benchmark datasets corroborate that RSE achieves better or comparable accuracy in comparison to state-of-the-art baselines, especially with the strings of longer lengths. In addition, we empirically show that RSE scales linearly with the increase of the number and the length of string.
KerGM: Kernelized Graph Matching
Nov 25, 2019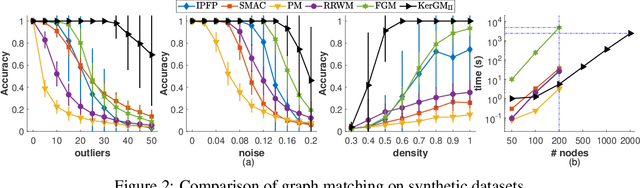
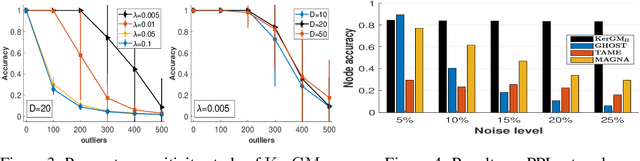
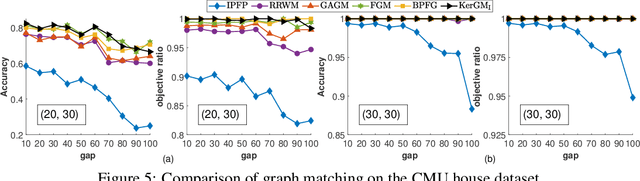
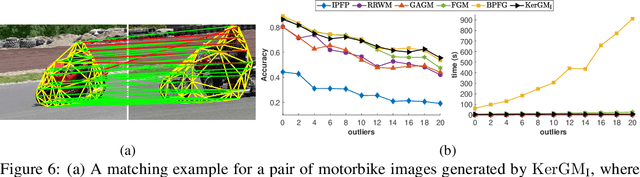
Graph matching plays a central role in such fields as computer vision, pattern recognition, and bioinformatics. Graph matching problems can be cast as two types of quadratic assignment problems (QAPs): Koopmans-Beckmann's QAP or Lawler's QAP. In our paper, we provide a unifying view for these two problems by introducing new rules for array operations in Hilbert spaces. Consequently, Lawler's QAP can be considered as the Koopmans-Beckmann's alignment between two arrays in reproducing kernel Hilbert spaces (RKHS), making it possible to efficiently solve the problem without computing a huge affinity matrix. Furthermore, we develop the entropy-regularized Frank-Wolfe (EnFW) algorithm for optimizing QAPs, which has the same convergence rate as the original FW algorithm while dramatically reducing the computational burden for each outer iteration. We conduct extensive experiments to evaluate our approach, and show that our algorithm significantly outperforms the state-of-the-art in both matching accuracy and scalability.
Scalable Global Alignment Graph Kernel Using Random Features: From Node Embedding to Graph Embedding
Nov 25, 2019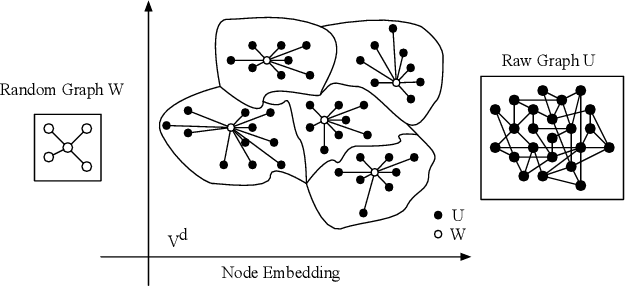
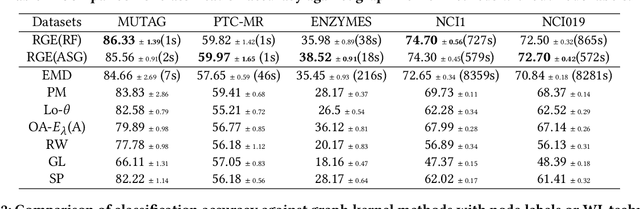
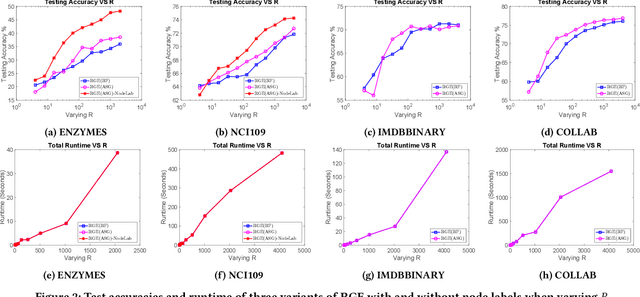
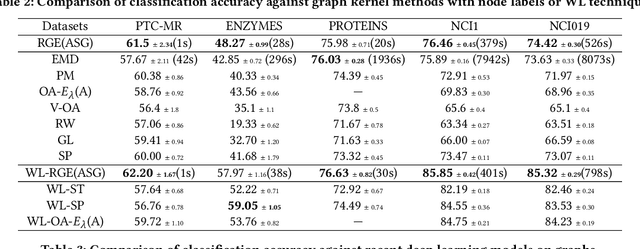
Graph kernels are widely used for measuring the similarity between graphs. Many existing graph kernels, which focus on local patterns within graphs rather than their global properties, suffer from significant structure information loss when representing graphs. Some recent global graph kernels, which utilizes the alignment of geometric node embeddings of graphs, yield state-of-the-art performance. However, these graph kernels are not necessarily positive-definite. More importantly, computing the graph kernel matrix will have at least quadratic {time} complexity in terms of the number and the size of the graphs. In this paper, we propose a new family of global alignment graph kernels, which take into account the global properties of graphs by using geometric node embeddings and an associated node transportation based on earth mover's distance. Compared to existing global kernels, the proposed kernel is positive-definite. Our graph kernel is obtained by defining a distribution over \emph{random graphs}, which can naturally yield random feature approximations. The random feature approximations lead to our graph embeddings, which is named as "random graph embeddings" (RGE). In particular, RGE is shown to achieve \emph{(quasi-)linear scalability} with respect to the number and the size of the graphs. The experimental results on nine benchmark datasets demonstrate that RGE outperforms or matches twelve state-of-the-art graph classification algorithms.
Improving Graph Neural Network Representations of Logical Formulae with Subgraph Pooling
Nov 15, 2019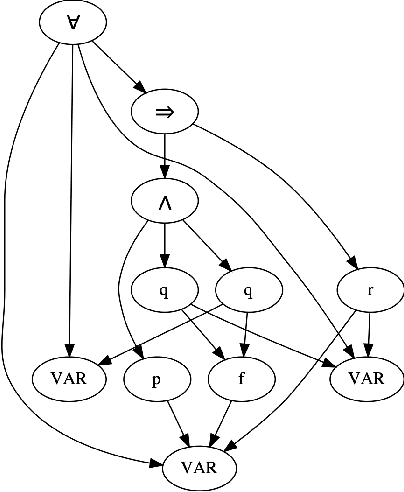
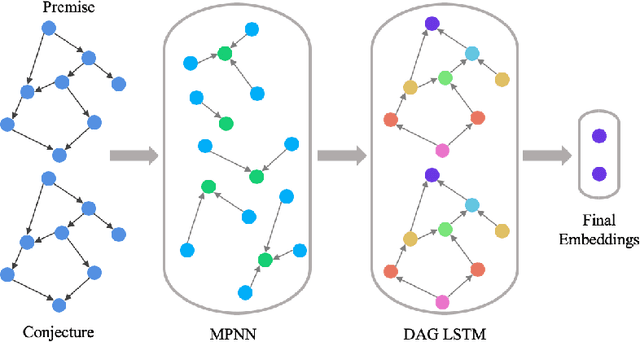
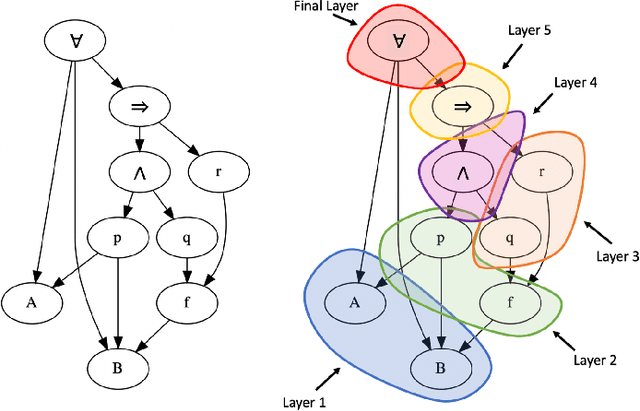
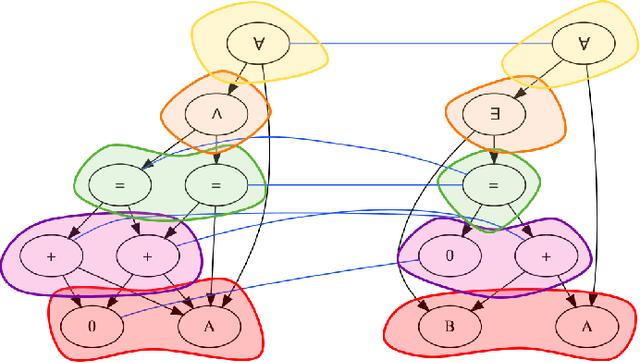
Recent advances in the integration of deep learning with automated theorem proving have centered around the representation of logical formulae as inputs to deep learning systems. In particular, there has been a shift from character and token-level representations to graph-structured representations, in large part driven by the rapidly emerging body of research on geometric deep learning. Typically, structure-aware neural methods for embedding logical formulae have been variants of either Tree LSTMs or GNNs. While more effective than character and token-level approaches, such methods have often made representational trade-offs that limited their ability to effectively represent the global structure of their inputs. In this work, we introduce a novel approach for embedding logical formulae using DAG LSTMs that is designed to overcome the limitations of both Tree LSTMs and GNNs. The effectiveness of the proposed framework is demonstrated on the tasks of premise selection and proof step classification where it achieves the state-of-the-art performance on two standard datasets.