 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
IDCNet: Guided Video Diffusion for Metric-Consistent RGBD Scene Generation with Precise Camera Control
Aug 06, 2025We present IDC-Net (Image-Depth Consistency Network), a novel framework designed to generate RGB-D video sequences under explicit camera trajectory control. Unlike approaches that treat RGB and depth generation separately, IDC-Net jointly synthesizes both RGB images and corresponding depth maps within a unified geometry-aware diffusion model. The joint learning framework strengthens spatial and geometric alignment across frames, enabling more precise camera control in the generated sequences. To support the training of this camera-conditioned model and ensure high geometric fidelity, we construct a camera-image-depth consistent dataset with metric-aligned RGB videos, depth maps, and accurate camera poses, which provides precise geometric supervision with notably improved inter-frame geometric consistency. Moreover, we introduce a geometry-aware transformer block that enables fine-grained camera control, enhancing control over the generated sequences. Extensive experiments show that IDC-Net achieves improvements over state-of-the-art approaches in both visual quality and geometric consistency of generated scene sequences. Notably, the generated RGB-D sequences can be directly feed for downstream 3D Scene reconstruction tasks without extra post-processing steps, showcasing the practical benefits of our joint learning framework. See more at https://idcnet-scene.github.io.
High Accuracy, Less Talk (HALT): Reliable LLMs through Capability-Aligned Finetuning
Jun 04, 2025Large Language Models (LLMs) currently respond to every prompt. However, they can produce incorrect answers when they lack knowledge or capability -- a problem known as hallucination. We instead propose post-training an LLM to generate content only when confident in its correctness and to otherwise (partially) abstain. Specifically, our method, HALT, produces capability-aligned post-training data that encodes what the model can and cannot reliably generate. We generate this data by splitting responses of the pretrained LLM into factual fragments (atomic statements or reasoning steps), and use ground truth information to identify incorrect fragments. We achieve capability-aligned finetuning responses by either removing incorrect fragments or replacing them with "Unsure from Here" -- according to a tunable threshold that allows practitioners to trade off response completeness and mean correctness of the response's fragments. We finetune four open-source models for biography writing, mathematics, coding, and medicine with HALT for three different trade-off thresholds. HALT effectively trades off response completeness for correctness, increasing the mean correctness of response fragments by 15% on average, while resulting in a 4% improvement in the F1 score (mean of completeness and correctness of the response) compared to the relevant baselines. By tuning HALT for highest correctness, we train a single reliable Llama3-70B model with correctness increased from 51% to 87% across all four domains while maintaining 53% of the response completeness achieved with standard finetuning.
Diversity-driven Data Selection for Language Model Tuning through Sparse Autoencoder
Feb 19, 2025Current pre-trained large language models typically need instruction tuning to align with human preferences. However, instruction tuning data is often quantity-saturated due to the large volume of data collection and fast model iteration, leaving coreset data selection important but underexplored. On the other hand, existing quality-driven data selection methods such as LIMA (NeurIPS 2023 (Zhou et al., 2024)) and AlpaGasus (ICLR 2024 (Chen et al.)) generally ignore the equal importance of data diversity and complexity. In this work, we aim to design a diversity-aware data selection strategy and creatively propose using sparse autoencoders to tackle the challenge of data diversity measure. In addition, sparse autoencoders can also provide more interpretability of model behavior and explain, e.g., the surprising effectiveness of selecting the longest response (ICML 2024 (Zhao et al.)). Using effective data selection, we experimentally prove that models trained on our selected data can outperform other methods in terms of model capabilities, reduce training cost, and potentially gain more control over model behaviors.
Quality-aware Masked Diffusion Transformer for Enhanced Music Generation
May 24, 2024In recent years, diffusion-based text-to-music (TTM) generation has gained prominence, offering a novel approach to synthesizing musical content from textual descriptions. Achieving high accuracy and diversity in this generation process requires extensive, high-quality data, which often constitutes only a fraction of available datasets. Within open-source datasets, the prevalence of issues like mislabeling, weak labeling, unlabeled data, and low-quality music waveform significantly hampers the development of music generation models. To overcome these challenges, we introduce a novel quality-aware masked diffusion transformer (QA-MDT) approach that enables generative models to discern the quality of input music waveform during training. Building on the unique properties of musical signals, we have adapted and implemented a MDT model for TTM task, while further unveiling its distinct capacity for quality control. Moreover, we address the issue of low-quality captions with a caption refinement data processing approach. Our demo page is shown in https://qa-mdt.github.io/. Code on https://github.com/ivcylc/qa-mdt
SMPLer: Taming Transformers for Monocular 3D Human Shape and Pose Estimation
Apr 23, 2024



Existing Transformers for monocular 3D human shape and pose estimation typically have a quadratic computation and memory complexity with respect to the feature length, which hinders the exploitation of fine-grained information in high-resolution features that is beneficial for accurate reconstruction. In this work, we propose an SMPL-based Transformer framework (SMPLer) to address this issue. SMPLer incorporates two key ingredients: a decoupled attention operation and an SMPL-based target representation, which allow effective utilization of high-resolution features in the Transformer. In addition, based on these two designs, we also introduce several novel modules including a multi-scale attention and a joint-aware attention to further boost the reconstruction performance. Extensive experiments demonstrate the effectiveness of SMPLer against existing 3D human shape and pose estimation methods both quantitatively and qualitatively. Notably, the proposed algorithm achieves an MPJPE of 45.2 mm on the Human3.6M dataset, improving upon Mesh Graphormer by more than 10% with fewer than one-third of the parameters. Code and pretrained models are available at https://github.com/xuxy09/SMPLer.
* Published at TPAMI 2024
Cappy: Outperforming and Boosting Large Multi-Task LMs with a Small Scorer
Nov 12, 2023Large language models (LLMs) such as T0, FLAN, and OPT-IML, excel in multi-tasking under a unified instruction-following paradigm, where they also exhibit remarkable generalization abilities to unseen tasks. Despite their impressive performance, these LLMs, with sizes ranging from several billion to hundreds of billions of parameters, demand substantial computational resources, making their training and inference expensive and inefficient. Furthermore, adapting these models to downstream applications, particularly complex tasks, is often unfeasible due to the extensive hardware requirements for finetuning, even when utilizing parameter-efficient approaches such as prompt tuning. Additionally, the most powerful multi-task LLMs, such as OPT-IML-175B and FLAN-PaLM-540B, are not publicly accessible, severely limiting their customization potential. To address these challenges, we introduce a pretrained small scorer, Cappy, designed to enhance the performance and efficiency of multi-task LLMs. With merely 360 million parameters, Cappy functions either independently on classification tasks or serve as an auxiliary component for LLMs, boosting their performance. Moreover, Cappy enables efficiently integrating downstream supervision without requiring LLM finetuning nor the access to their parameters. Our experiments demonstrate that, when working independently on 11 language understanding tasks from PromptSource, Cappy outperforms LLMs that are several orders of magnitude larger. Besides, on 45 complex tasks from BIG-Bench, Cappy boosts the performance of the advanced multi-task LLM, FLAN-T5, by a large margin. Furthermore, Cappy is flexible to cooperate with other LLM adaptations, including finetuning and in-context learning, offering additional performance enhancement.
Towards Garment Sewing Pattern Reconstruction from a Single Image
Nov 07, 2023Garment sewing pattern represents the intrinsic rest shape of a garment, and is the core for many applications like fashion design, virtual try-on, and digital avatars. In this work, we explore the challenging problem of recovering garment sewing patterns from daily photos for augmenting these applications. To solve the problem, we first synthesize a versatile dataset, named SewFactory, which consists of around 1M images and ground-truth sewing patterns for model training and quantitative evaluation. SewFactory covers a wide range of human poses, body shapes, and sewing patterns, and possesses realistic appearances thanks to the proposed human texture synthesis network. Then, we propose a two-level Transformer network called Sewformer, which significantly improves the sewing pattern prediction performance. Extensive experiments demonstrate that the proposed framework is effective in recovering sewing patterns and well generalizes to casually-taken human photos. Code, dataset, and pre-trained models are available at: https://sewformer.github.io.
Redco: A Lightweight Tool to Automate Distributed Training of LLMs on Any GPU/TPUs
Oct 25, 2023The recent progress of AI can be largely attributed to large language models (LLMs). However, their escalating memory requirements introduce challenges for machine learning (ML) researchers and engineers. Addressing this requires developers to partition a large model to distribute it across multiple GPUs or TPUs. This necessitates considerable coding and intricate configuration efforts with existing model parallel tools, such as Megatron-LM, DeepSpeed, and Alpa. These tools require users' expertise in machine learning systems (MLSys), creating a bottleneck in LLM development, particularly for developers without MLSys background. In this work, we present Redco, a lightweight and user-friendly tool crafted to automate distributed training and inference for LLMs, as well as to simplify ML pipeline development. The design of Redco emphasizes two key aspects. Firstly, to automate model parallism, our study identifies two straightforward rules to generate tensor parallel strategies for any given LLM. Integrating these rules into Redco facilitates effortless distributed LLM training and inference, eliminating the need of additional coding or complex configurations. We demonstrate the effectiveness by applying Redco on a set of LLM architectures, such as GPT-J, LLaMA, T5, and OPT, up to the size of 66B. Secondly, we propose a mechanism that allows for the customization of diverse ML pipelines through the definition of merely three functions, eliminating redundant and formulaic code like multi-host related processing. This mechanism proves adaptable across a spectrum of ML algorithms, from foundational language modeling to complex algorithms like meta-learning and reinforcement learning. Consequently, Redco implementations exhibit much fewer code lines compared to their official counterparts.
Towards Better Semantic Understanding of Mobile Interfaces
Oct 06, 2022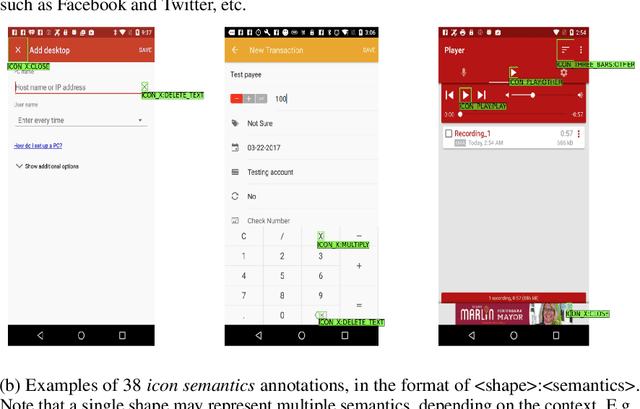

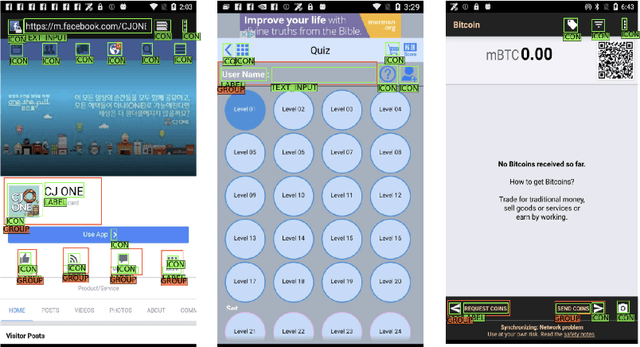

Improving the accessibility and automation capabilities of mobile devices can have a significant positive impact on the daily lives of countless users. To stimulate research in this direction, we release a human-annotated dataset with approximately 500k unique annotations aimed at increasing the understanding of the functionality of UI elements. This dataset augments images and view hierarchies from RICO, a large dataset of mobile UIs, with annotations for icons based on their shapes and semantics, and associations between different elements and their corresponding text labels, resulting in a significant increase in the number of UI elements and the categories assigned to them. We also release models using image-only and multimodal inputs; we experiment with various architectures and study the benefits of using multimodal inputs on the new dataset. Our models demonstrate strong performance on an evaluation set of unseen apps, indicating their generalizability to newer screens. These models, combined with the new dataset, can enable innovative functionalities like referring to UI elements by their labels, improved coverage and better semantics for icons etc., which would go a long way in making UIs more usable for everyone.