 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-optimal Representation Learning for Linear Bandits and Linear RL
Feb 08, 2021This paper studies representation learning for multi-task linear bandits and multi-task episodic RL with linear value function approximation. We first consider the setting where we play $M$ linear bandits with dimension $d$ concurrently, and these bandits share a common $k$-dimensional linear representation so that $k\ll d$ and $k \ll M$. We propose a sample-efficient algorithm, MTLR-OFUL, which leverages the shared representation to achieve $\tilde{O}(M\sqrt{dkT} + d\sqrt{kMT} )$ regret, with $T$ being the number of total steps. Our regret significantly improves upon the baseline $\tilde{O}(Md\sqrt{T})$ achieved by solving each task independently. We further develop a lower bound that shows our regret is near-optimal when $d > M$. Furthermore, we extend the algorithm and analysis to multi-task episodic RL with linear value function approximation under low inherent Bellman error \citep{zanette2020learning}. To the best of our knowledge, this is the first theoretical result that characterizes the benefits of multi-task representation learning for exploration in RL with function approximation.
CoinDICE: Off-Policy Confidence Interval Estimation
Oct 22, 2020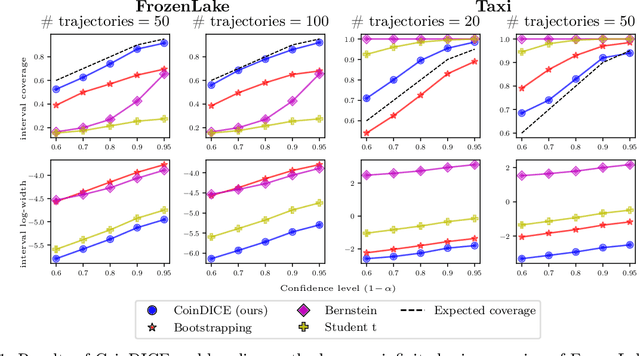
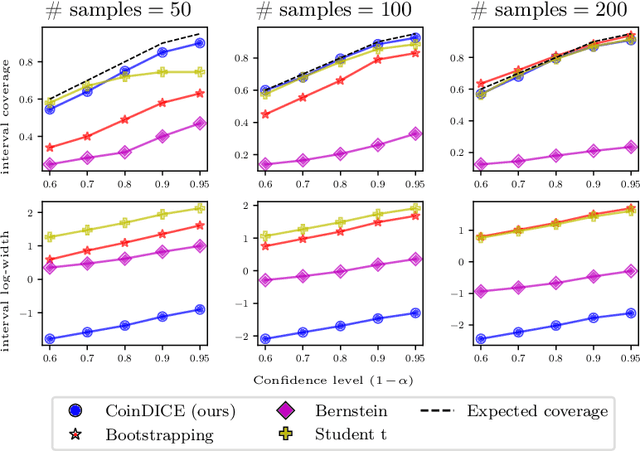
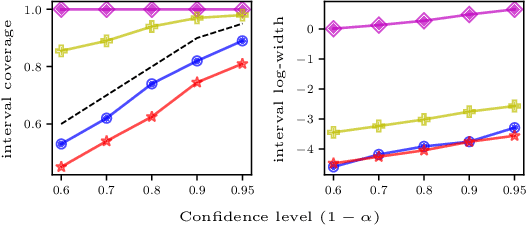
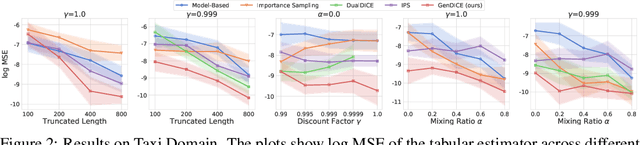
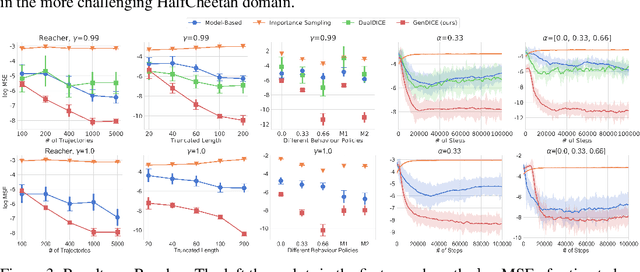
We study high-confidence behavior-agnostic off-policy evaluation in reinforcement learning, where the goal is to estimate a confidence interval on a target policy's value, given only access to a static experience dataset collected by unknown behavior policies. Starting from a function space embedding of the linear program formulation of the $Q$-function, we obtain an optimization problem with generalized estimating equation constraints. By applying the generalized empirical likelihood method to the resulting Lagrangian, we propose CoinDICE, a novel and efficient algorithm for computing confidence intervals. Theoretically, we prove the obtained confidence intervals are valid, in both asymptotic and finite-sample regimes. Empirically, we show in a variety of benchmarks that the confidence interval estimates are tighter and more accurate than existing methods.
Neural Thompson Sampling
Oct 02, 2020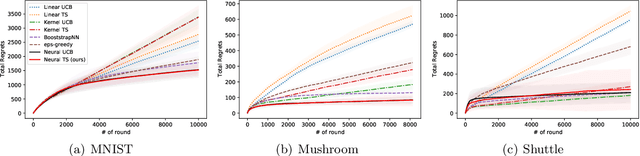
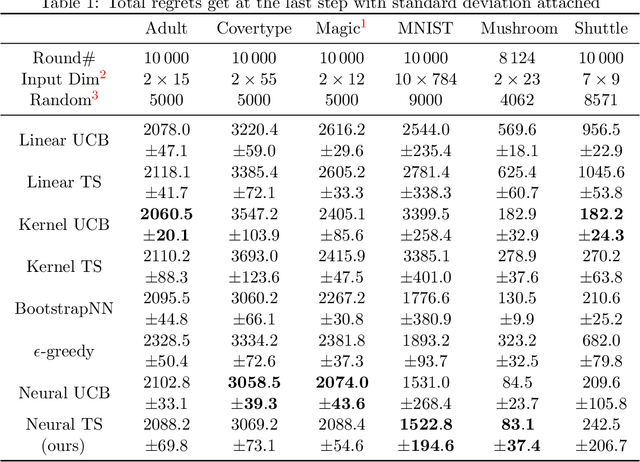
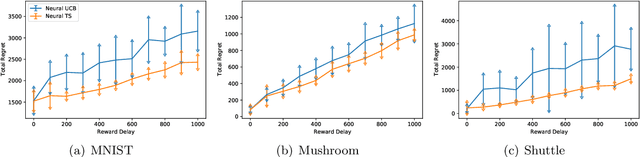
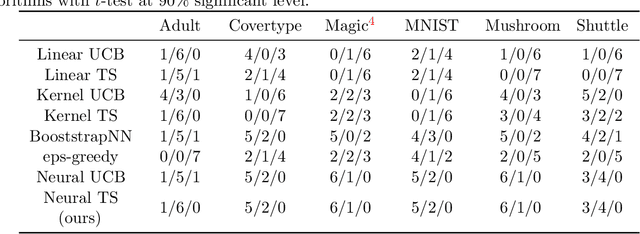
Thompson Sampling (TS) is one of the most effective algorithms for solving contextual multi-armed bandit problems. In this paper, we propose a new algorithm, called Neural Thompson Sampling, which adapts deep neural networks for both exploration and exploitation. At the core of our algorithm is a novel posterior distribution of the reward, where its mean is the neural network approximator, and its variance is built upon the neural tangent features of the corresponding neural network. We prove that, provided the underlying reward function is bounded, the proposed algorithm is guaranteed to achieve a cumulative regret of $\mathcal{O}(T^{1/2})$, which matches the regret of other contextual bandit algorithms in terms of total round number $T$. Experimental comparisons with other benchmark bandit algorithms on various data sets corroborate our theory.
Efficient Reinforcement Learning in Factored MDPs with Application to Constrained RL
Sep 15, 2020Reinforcement learning (RL) in episodic, factored Markov decision processes (FMDPs) is studied. We propose an algorithm called FMDP-BF, which leverages the factorization structure of FMDP. The regret of FMDP-BF is shown to be exponentially smaller than that of optimal algorithms designed for non-factored MDPs, and improves on the best previous result for FMDPs~\citep{osband2014near} by a factored of $\sqrt{H|\mathcal{S}_i|}$, where $|\mathcal{S}_i|$ is the cardinality of the factored state subspace and $H$ is the planning horizon. To show the optimality of our bounds, we also provide a lower bound for FMDP, which indicates that our algorithm is near-optimal w.r.t. timestep $T$, horizon $H$ and factored state-action subspace cardinality. Finally, as an application, we study a new formulation of constrained RL, known as RL with knapsack constraints (RLwK), and provides the first sample-efficient algorithm based on FMDP-BF.
Off-policy Evaluation in Infinite-Horizon Reinforcement Learning with Latent Confounders
Jul 27, 2020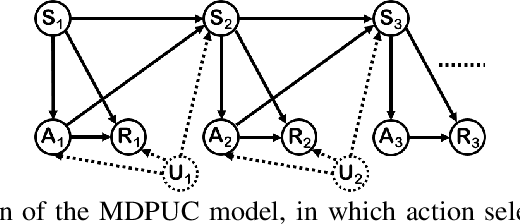
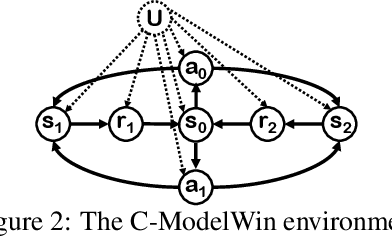

Off-policy evaluation (OPE) in reinforcement learning is an important problem in settings where experimentation is limited, such as education and healthcare. But, in these very same settings, observed actions are often confounded by unobserved variables making OPE even more difficult. We study an OPE problem in an infinite-horizon, ergodic Markov decision process with unobserved confounders, where states and actions can act as proxies for the unobserved confounders. We show how, given only a latent variable model for states and actions, policy value can be identified from off-policy data. Our method involves two stages. In the first, we show how to use proxies to estimate stationary distribution ratios, extending recent work on breaking the curse of horizon to the confounded setting. In the second, we show optimal balancing can be combined with such learned ratios to obtain policy value while avoiding direct modeling of reward functions. We establish theoretical guarantees of consistency, and benchmark our method empirically.
Off-Policy Evaluation via the Regularized Lagrangian
Jul 07, 2020

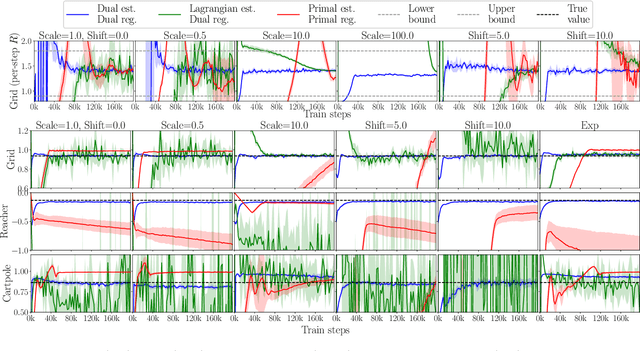
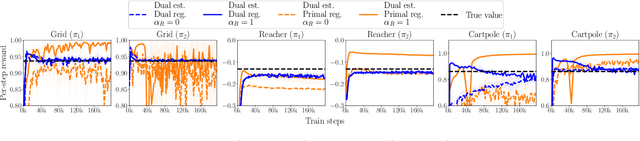
The recently proposed distribution correction estimation (DICE) family of estimators has advanced the state of the art in off-policy evaluation from behavior-agnostic data. While these estimators all perform some form of stationary distribution correction, they arise from different derivations and objective functions. In this paper, we unify these estimators as regularized Lagrangians of the same linear program. The unification allows us to expand the space of DICE estimators to new alternatives that demonstrate improved performance. More importantly, by analyzing the expanded space of estimators both mathematically and empirically we find that dual solutions offer greater flexibility in navigating the tradeoff between optimization stability and estimation bias, and generally provide superior estimates in practice.
Black-box Off-policy Estimation for Infinite-Horizon Reinforcement Learning
Mar 24, 2020



Off-policy estimation for long-horizon problems is important in many real-life applications such as healthcare and robotics, where high-fidelity simulators may not be available and on-policy evaluation is expensive or impossible. Recently, \cite{liu18breaking} proposed an approach that avoids the \emph{curse of horizon} suffered by typical importance-sampling-based methods. While showing promising results, this approach is limited in practice as it requires data be drawn from the \emph{stationary distribution} of a \emph{known} behavior policy. In this work, we propose a novel approach that eliminates such limitations. In particular, we formulate the problem as solving for the fixed point of a certain operator. Using tools from Reproducing Kernel Hilbert Spaces (RKHSs), we develop a new estimator that computes importance ratios of stationary distributions, without knowledge of how the off-policy data are collected. We analyze its asymptotic consistency and finite-sample generalization. Experiments on benchmarks verify the effectiveness of our approach.
Batch Stationary Distribution Estimation
Mar 02, 2020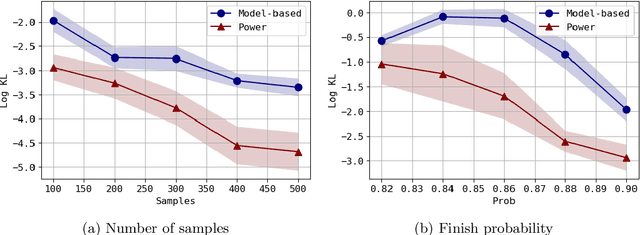
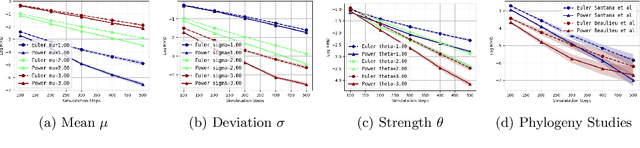
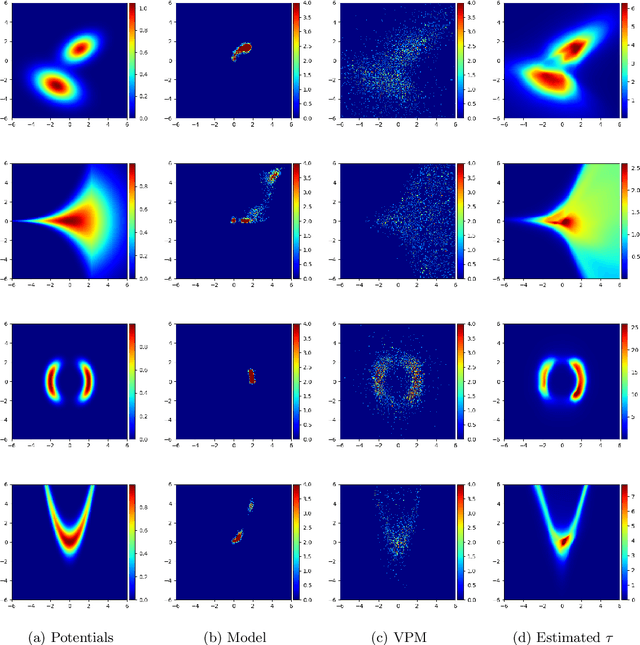
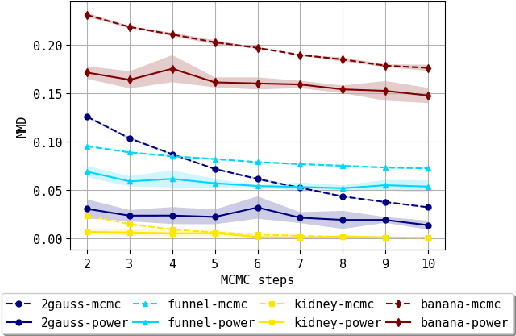
We consider the problem of approximating the stationary distribution of an ergodic Markov chain given a set of sampled transitions. Classical simulation-based approaches assume access to the underlying process so that trajectories of sufficient length can be gathered to approximate stationary sampling. Instead, we consider an alternative setting where a fixed set of transitions has been collected beforehand, by a separate, possibly unknown procedure. The goal is still to estimate properties of the stationary distribution, but without additional access to the underlying system. We propose a consistent estimator that is based on recovering a correction ratio function over the given data. In particular, we develop a variational power method (VPM) that provides provably consistent estimates under general conditions. In addition to unifying a number of existing approaches from different subfields, we also find that VPM yields significantly better estimates across a range of problems, including queueing, stochastic differential equations, post-processing MCMC, and off-policy evaluation.
GenDICE: Generalized Offline Estimation of Stationary Values
Feb 21, 2020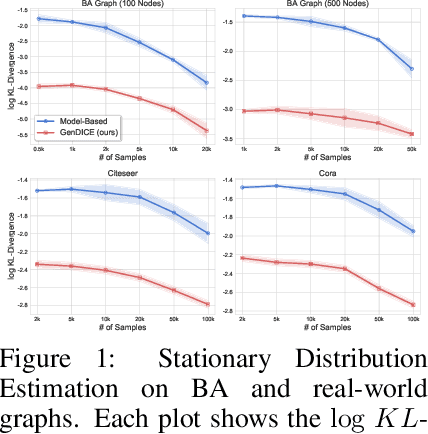
An important problem that arises in reinforcement learning and Monte Carlo methods is estimating quantities defined by the stationary distribution of a Markov chain. In many real-world applications, access to the underlying transition operator is limited to a fixed set of data that has already been collected, without additional interaction with the environment being available. We show that consistent estimation remains possible in this challenging scenario, and that effective estimation can still be achieved in important applications. Our approach is based on estimating a ratio that corrects for the discrepancy between the stationary and empirical distributions, derived from fundamental properties of the stationary distribution, and exploiting constraint reformulations based on variational divergence minimization. The resulting algorithm, GenDICE, is straightforward and effective. We prove its consistency under general conditions, provide an error analysis, and demonstrate strong empirical performance on benchmark problems, including off-line PageRank and off-policy policy evaluation.
Data Efficient Training for Reinforcement Learning with Adaptive Behavior Policy Sharing
Feb 12, 2020
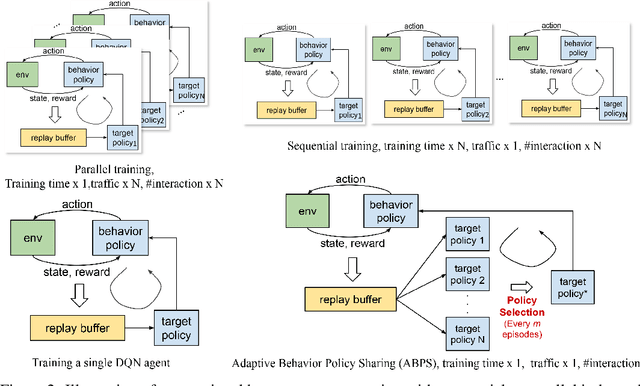
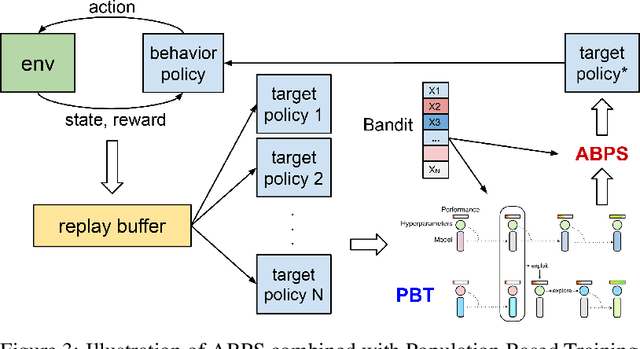
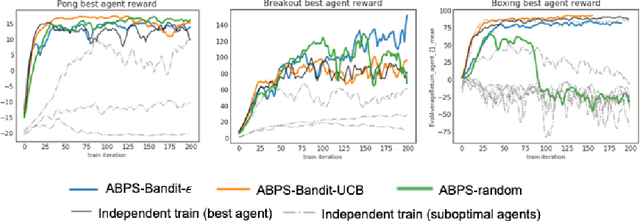
Deep Reinforcement Learning (RL) is proven powerful for decision making in simulated environments. However, training deep RL model is challenging in real world applications such as production-scale health-care or recommender systems because of the expensiveness of interaction and limitation of budget at deployment. One aspect of the data inefficiency comes from the expensive hyper-parameter tuning when optimizing deep neural networks. We propose Adaptive Behavior Policy Sharing (ABPS), a data-efficient training algorithm that allows sharing of experience collected by behavior policy that is adaptively selected from a pool of agents trained with an ensemble of hyper-parameters. We further extend ABPS to evolve hyper-parameters during training by hybridizing ABPS with an adapted version of Population Based Training (ABPS-PBT). We conduct experiments with multiple Atari games with up to 16 hyper-parameter/architecture setups. ABPS achieves superior overall performance, reduced variance on top 25% agents, and equivalent performance on the best agent compared to conventional hyper-parameter tuning with independent training, even though ABPS only requires the same number of environmental interactions as training a single agent. We also show that ABPS-PBT further improves the convergence speed and reduces the variance.