 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Graph Generator for Multi-View Graph Clustering
Oct 13, 2022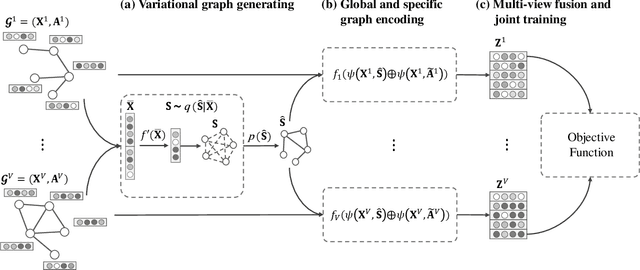
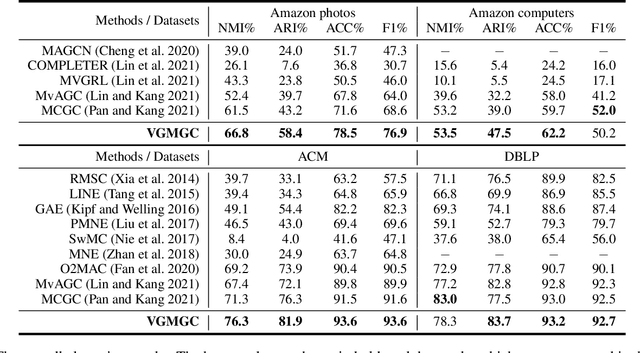
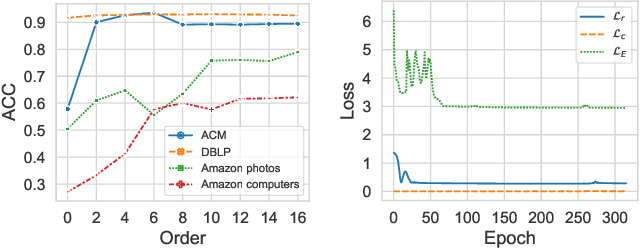
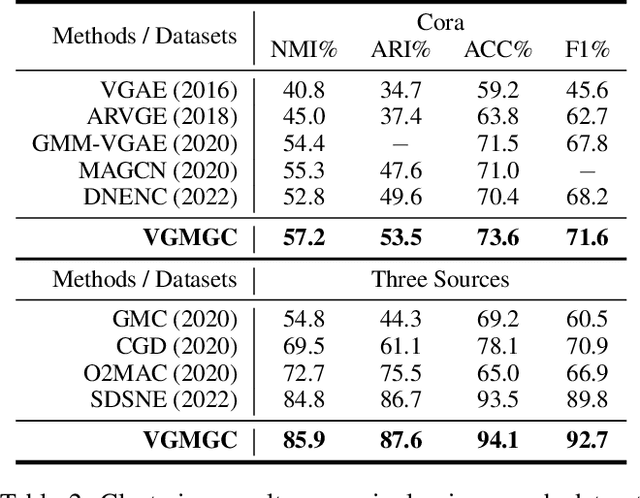
Multi-view graph clustering (MGC) methods are increasingly being studied due to the rising of multi-view data with graph structural information. The critical point of MGC is to better utilize the view-specific and view-common information in features and graphs of multiple views. However, existing works have an inherent limitation that they are unable to concurrently utilize the consensus graph information across multiple graphs and the view-specific feature information. To address this issue, we propose Variational Graph Generator for Multi-View Graph Clustering (VGMGC). Specifically, a novel variational graph generator is proposed to infer a reliable variational consensus graph based on a priori assumption over multiple graphs. Then a simple yet effective graph encoder in conjunction with the multi-view clustering objective is presented to learn the desired graph embeddings for clustering, which embeds the consensus and view-specific graphs together with features. Finally, theoretical results illustrate the rationality of VGMGC by analyzing the uncertainty of the inferred consensus graph with information bottleneck principle. Extensive experiments demonstrate the superior performance of our VGMGC over SOTAs.
Deep Clustering: A Comprehensive Survey
Oct 09, 2022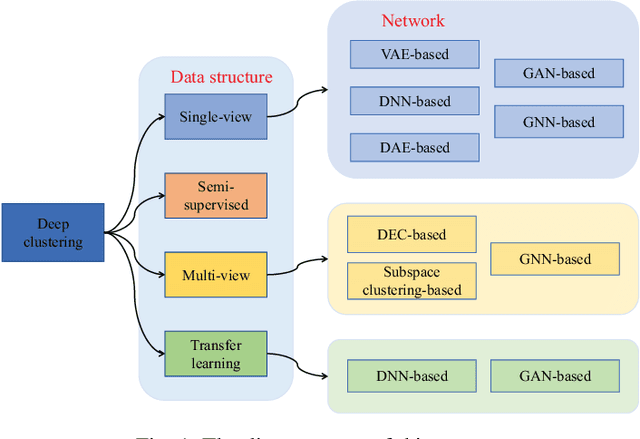
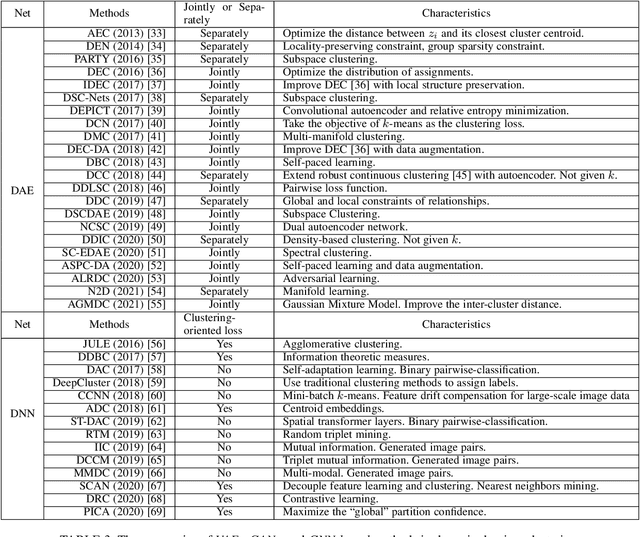
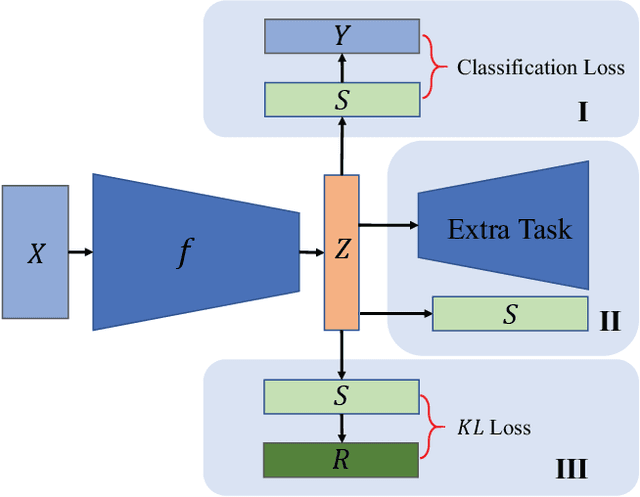
Cluster analysis plays an indispensable role in machine learning and data mining. Learning a good data representation is crucial for clustering algorithms. Recently, deep clustering, which can learn clustering-friendly representations using deep neural networks, has been broadly applied in a wide range of clustering tasks. Existing surveys for deep clustering mainly focus on the single-view fields and the network architectures, ignoring the complex application scenarios of clustering. To address this issue, in this paper we provide a comprehensive survey for deep clustering in views of data sources. With different data sources and initial conditions, we systematically distinguish the clustering methods in terms of methodology, prior knowledge, and architecture. Concretely, deep clustering methods are introduced according to four categories, i.e., traditional single-view deep clustering, semi-supervised deep clustering, deep multi-view clustering, and deep transfer clustering. Finally, we discuss the open challenges and potential future opportunities in different fields of deep clustering.
Tensor-Based Multi-Modality Feature Selection and Regression for Alzheimer's Disease Diagnosis
Sep 23, 2022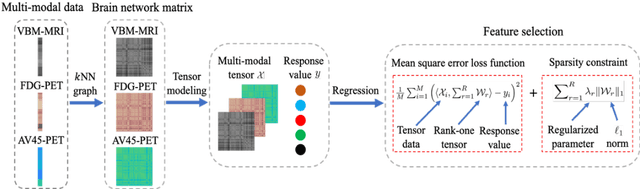
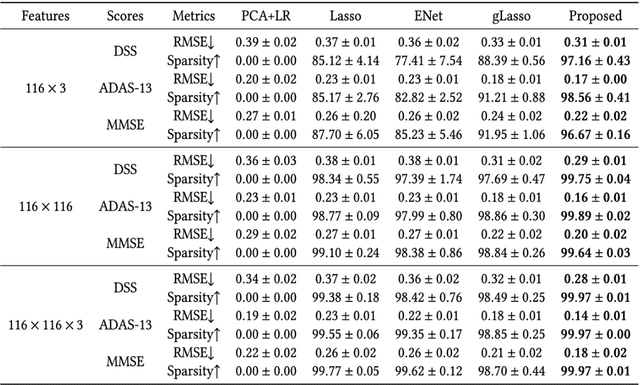
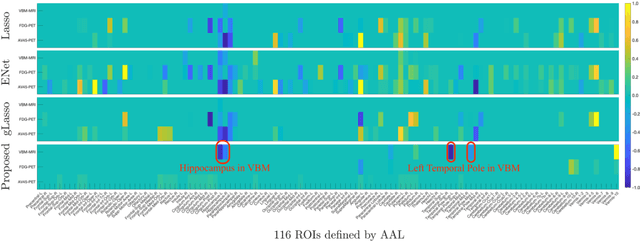
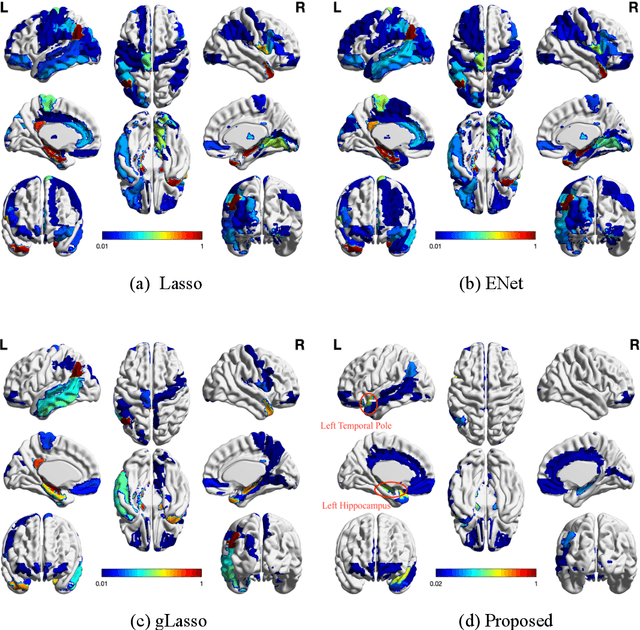
The assessment of Alzheimer's Disease (AD) and Mild Cognitive Impairment (MCI) associated with brain changes remains a challenging task. Recent studies have demonstrated that combination of multi-modality imaging techniques can better reflect pathological characteristics and contribute to more accurate diagnosis of AD and MCI. In this paper, we propose a novel tensor-based multi-modality feature selection and regression method for diagnosis and biomarker identification of AD and MCI from normal controls. Specifically, we leverage the tensor structure to exploit high-level correlation information inherent in the multi-modality data, and investigate tensor-level sparsity in the multilinear regression model. We present the practical advantages of our method for the analysis of ADNI data using three imaging modalities (VBM- MRI, FDG-PET and AV45-PET) with clinical parameters of disease severity and cognitive scores. The experimental results demonstrate the superior performance of our proposed method against the state-of-the-art for the disease diagnosis and the identification of disease-specific regions and modality-related differences. The code for this work is publicly available at https://github.com/junfish/BIOS22.
Interpretable Graph Neural Networks for Connectome-Based Brain Disorder Analysis
Jun 30, 2022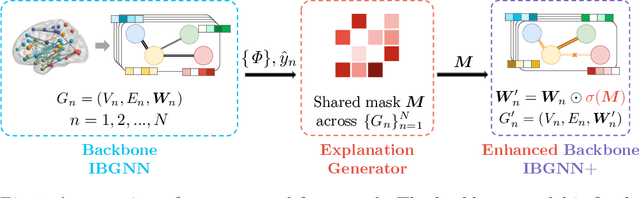
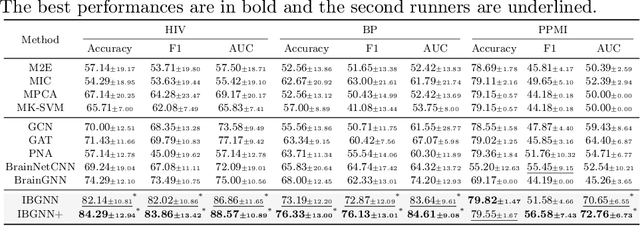
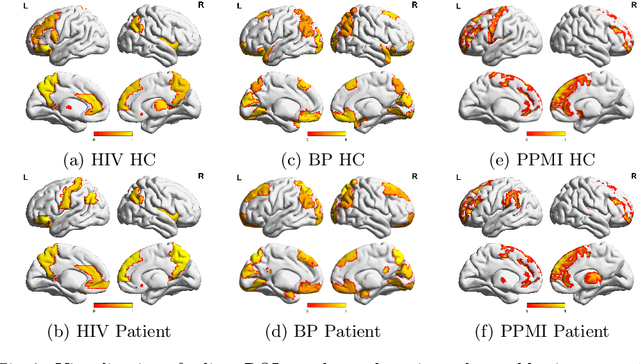
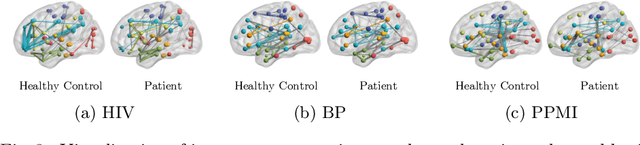
Human brains lie at the core of complex neurobiological systems, where the neurons, circuits, and subsystems interact in enigmatic ways. Understanding the structural and functional mechanisms of the brain has long been an intriguing pursuit for neuroscience research and clinical disorder therapy. Mapping the connections of the human brain as a network is one of the most pervasive paradigms in neuroscience. Graph Neural Networks (GNNs) have recently emerged as a potential method for modeling complex network data. Deep models, on the other hand, have low interpretability, which prevents their usage in decision-critical contexts like healthcare. To bridge this gap, we propose an interpretable framework to analyze disorder-specific Regions of Interest (ROIs) and prominent connections. The proposed framework consists of two modules: a brain-network-oriented backbone model for disease prediction and a globally shared explanation generator that highlights disorder-specific biomarkers including salient ROIs and important connections. We conduct experiments on three real-world datasets of brain disorders. The results verify that our framework can obtain outstanding performance and also identify meaningful biomarkers. All code for this work is available at https://github.com/HennyJie/IBGNN.git.
Data-Efficient Brain Connectome Analysis via Multi-Task Meta-Learning
Jun 09, 2022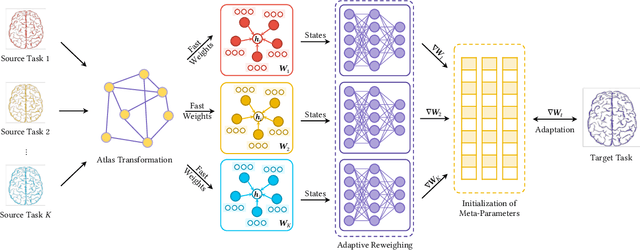
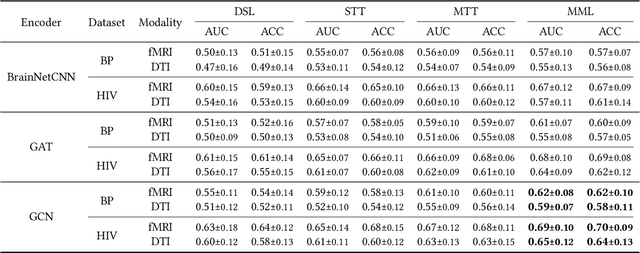
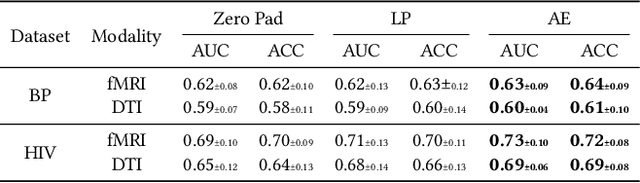
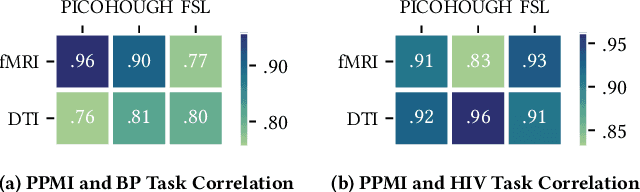
Brain networks characterize complex connectivities among brain regions as graph structures, which provide a powerful means to study brain connectomes. In recent years, graph neural networks have emerged as a prevalent paradigm of learning with structured data. However, most brain network datasets are limited in sample sizes due to the relatively high cost of data acquisition, which hinders the deep learning models from sufficient training. Inspired by meta-learning that learns new concepts fast with limited training examples, this paper studies data-efficient training strategies for analyzing brain connectomes in a cross-dataset setting. Specifically, we propose to meta-train the model on datasets of large sample sizes and transfer the knowledge to small datasets. In addition, we also explore two brain-network-oriented designs, including atlas transformation and adaptive task reweighing. Compared to other pre-training strategies, our meta-learning-based approach achieves higher and stabler performance, which demonstrates the effectiveness of our proposed solutions. The framework is also able to derive new insights regarding the similarities among datasets and diseases in a data-driven fashion.
Deep Embedded Multi-View Clustering via Jointly Learning Latent Representations and Graphs
May 08, 2022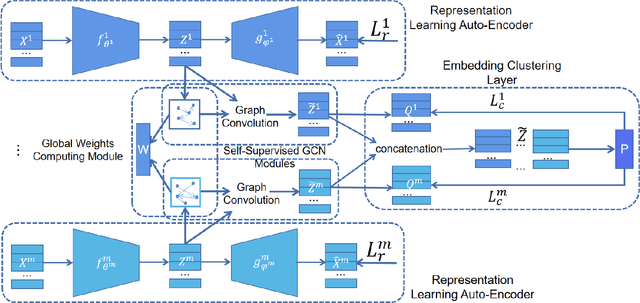
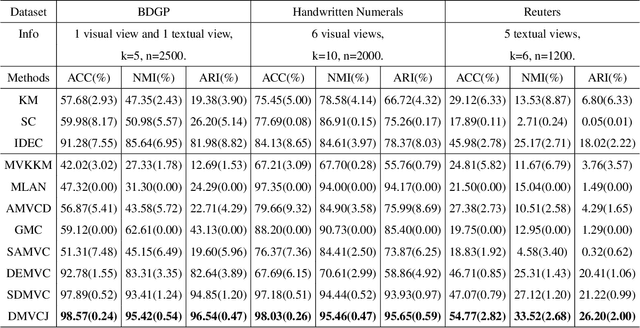
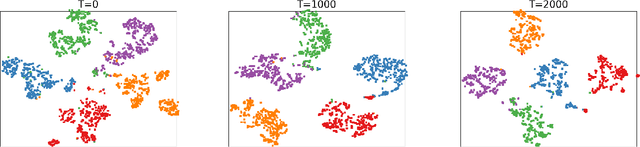

With the representation learning capability of the deep learning models, deep embedded multi-view clustering (MVC) achieves impressive performance in many scenarios and has become increasingly popular in recent years. Although great progress has been made in this field, most existing methods merely focus on learning the latent representations and ignore that learning the latent graph of nodes also provides available information for the clustering task. To address this issue, in this paper we propose Deep Embedded Multi-view Clustering via Jointly Learning Latent Representations and Graphs (DMVCJ), which utilizes the latent graphs to promote the performance of deep embedded MVC models from two aspects. Firstly, by learning the latent graphs and feature representations jointly, the graph convolution network (GCN) technique becomes available for our model. With the capability of GCN in exploiting the information from both graphs and features, the clustering performance of our model is significantly promoted. Secondly, based on the adjacency relations of nodes shown in the latent graphs, we design a sample-weighting strategy to alleviate the noisy issue, and further improve the effectiveness and robustness of the model. Experimental results on different types of real-world multi-view datasets demonstrate the effectiveness of DMVCJ.
Interpretable Graph Convolutional Network of Multi-Modality Brain Imaging for Alzheimer's Disease Diagnosis
Apr 27, 2022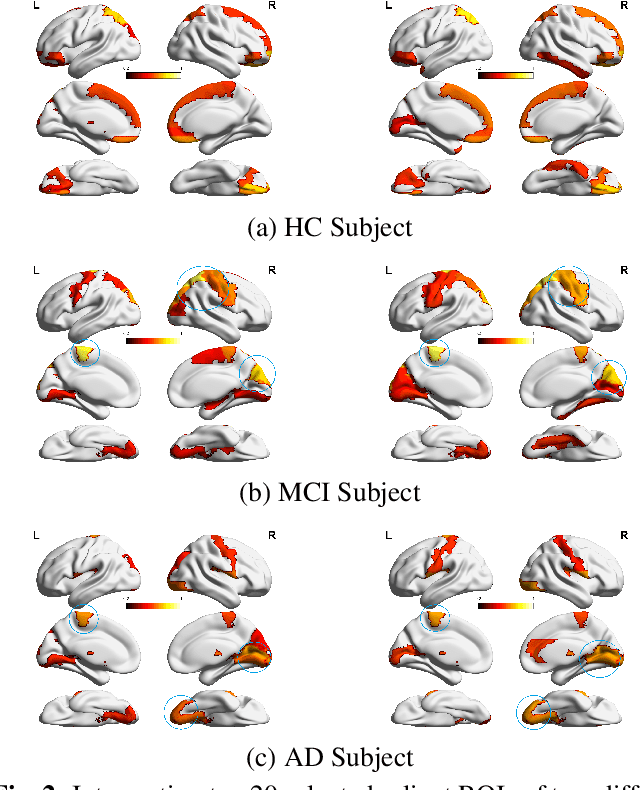
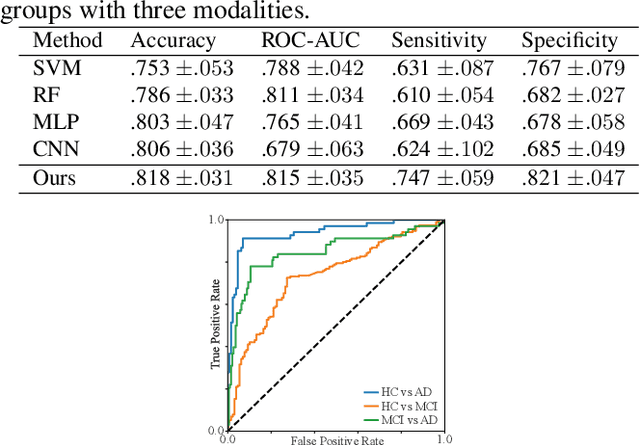
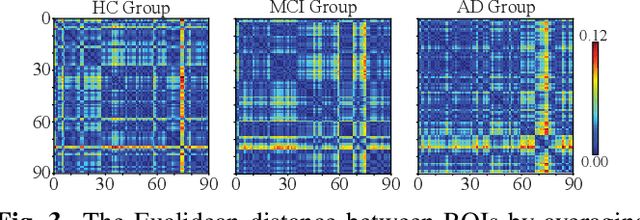
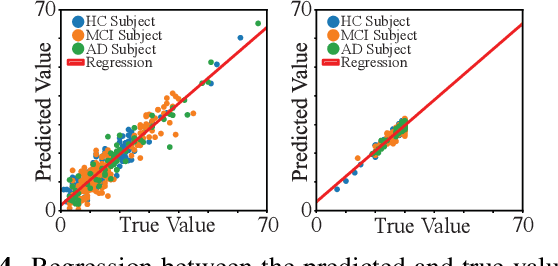
Identification of brain regions related to the specific neurological disorders are of great importance for biomarker and diagnostic studies. In this paper, we propose an interpretable Graph Convolutional Network (GCN) framework for the identification and classification of Alzheimer's disease (AD) using multi-modality brain imaging data. Specifically, we extended the Gradient Class Activation Mapping (Grad-CAM) technique to quantify the most discriminative features identified by GCN from brain connectivity patterns. We then utilized them to find signature regions of interest (ROIs) by detecting the difference of features between regions in healthy control (HC), mild cognitive impairment (MCI), and AD groups. We conducted the experiments on the ADNI database with imaging data from three modalities, including VBM-MRI, FDG-PET, and AV45-PET, and showed that the ROI features learned by our method were effective for enhancing the performances of both clinical score prediction and disease status identification. It also successfully identified biomarkers associated with AD and MCI.
Deep Reinforcement Learning Guided Graph Neural Networks for Brain Network Analysis
Mar 18, 2022
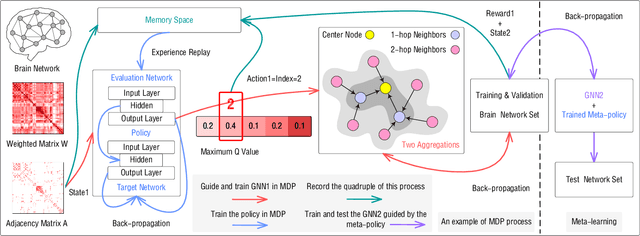

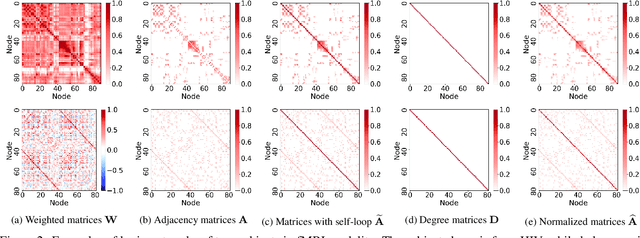
Modern neuroimaging techniques, such as diffusion tensor imaging (DTI) and functional magnetic resonance imaging (fMRI), enable us to model the human brain as a brain network or connectome. Capturing brain networks' structural information and hierarchical patterns is essential for understanding brain functions and disease states. Recently, the promising network representation learning capability of graph neural networks (GNNs) has prompted many GNN-based methods for brain network analysis to be proposed. Specifically, these methods apply feature aggregation and global pooling to convert brain network instances into meaningful low-dimensional representations used for downstream brain network analysis tasks. However, existing GNN-based methods often neglect that brain networks of different subjects may require various aggregation iterations and use GNN with a fixed number of layers to learn all brain networks. Therefore, how to fully release the potential of GNNs to promote brain network analysis is still non-trivial. To solve this problem, we propose a novel brain network representation framework, namely BN-GNN, which searches for the optimal GNN architecture for each brain network. Concretely, BN-GNN employs deep reinforcement learning (DRL) to train a meta-policy to automatically determine the optimal number of feature aggregations (reflected in the number of GNN layers) required for a given brain network. Extensive experiments on eight real-world brain network datasets demonstrate that our proposed BN-GNN improves the performance of traditional GNNs on different brain network analysis tasks.
Task Modifiers for HTN Planning and Acting
Feb 09, 2022
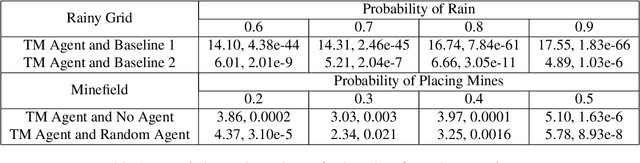
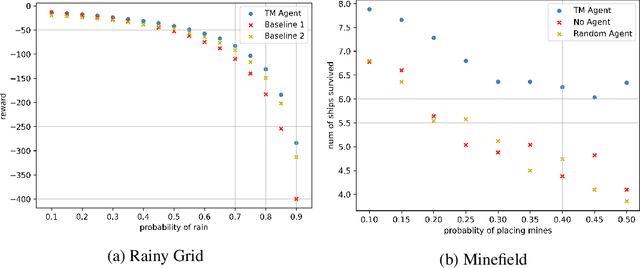
The ability of an agent to change its objectives in response to unexpected events is desirable in dynamic environments. In order to provide this capability to hierarchical task network (HTN) planning, we propose an extension of the paradigm called task modifiers, which are functions that receive a task list and a state and produce a new task list. We focus on a particular type of problems in which planning and execution are interleaved and the ability to handle exogenous events is crucial. To determine the efficacy of this approach, we evaluate the performance of our task modifier implementation in two environments, one of which is a simulation that differs substantially from traditional HTN domains.
Deep learning for drug repurposing: methods, databases, and applications
Feb 08, 2022
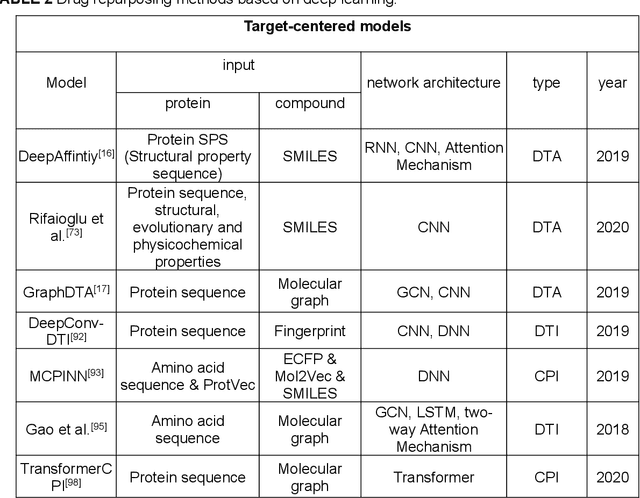
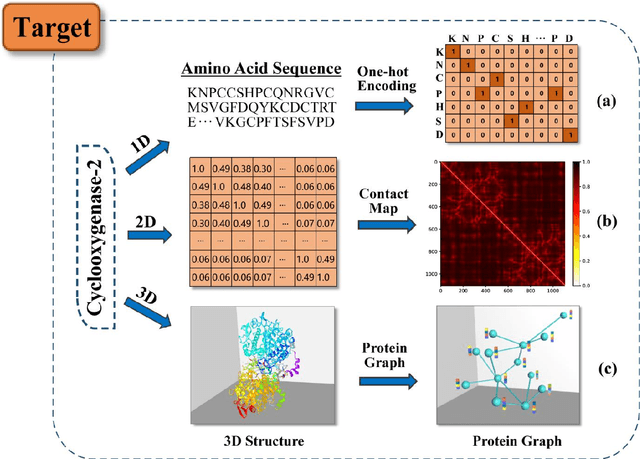
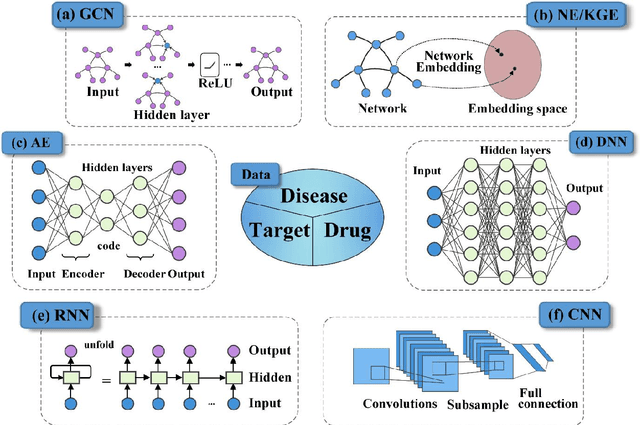
Drug development is time-consuming and expensive. Repurposing existing drugs for new therapies is an attractive solution that accelerates drug development at reduced experimental costs, specifically for Coronavirus Disease 2019 (COVID-19), an infectious disease caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). However, comprehensively obtaining and productively integrating available knowledge and big biomedical data to effectively advance deep learning models is still challenging for drug repurposing in other complex diseases. In this review, we introduce guidelines on how to utilize deep learning methodologies and tools for drug repurposing. We first summarized the commonly used bioinformatics and pharmacogenomics databases for drug repurposing. Next, we discuss recently developed sequence-based and graph-based representation approaches as well as state-of-the-art deep learning-based methods. Finally, we present applications of drug repurposing to fight the COVID-19 pandemic, and outline its future challenges.