 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-model fusion for Aerial Vision and Dialog Navigation based on human attention aids
Aug 27, 2023



Drones have been widely used in many areas of our daily lives. It relieves people of the burden of holding a controller all the time and makes drone control easier to use for people with disabilities or occupied hands. However, the control of aerial robots is more complicated compared to normal robots due to factors such as uncontrollable height. Therefore, it is crucial to develop an intelligent UAV that has the ability to talk to humans and follow natural language commands. In this report, we present an aerial navigation task for the 2023 ICCV Conversation History. Based on the AVDN dataset containing more than 3k recorded navigation trajectories and asynchronous human-robot conversations, we propose an effective method of fusion training of Human Attention Aided Transformer model (HAA-Transformer) and Human Attention Aided LSTM (HAA-LSTM) model, which achieves the prediction of the navigation routing points and human attention. The method not only achieves high SR and SPL metrics, but also shows a 7% improvement in GP metrics compared to the baseline model.
DiffUCD:Unsupervised Hyperspectral Image Change Detection with Semantic Correlation Diffusion Model
May 21, 2023



Hyperspectral image change detection (HSI-CD) has emerged as a crucial research area in remote sensing due to its ability to detect subtle changes on the earth's surface. Recently, diffusional denoising probabilistic models (DDPM) have demonstrated remarkable performance in the generative domain. Apart from their image generation capability, the denoising process in diffusion models can comprehensively account for the semantic correlation of spectral-spatial features in HSI, resulting in the retrieval of semantically relevant features in the original image. In this work, we extend the diffusion model's application to the HSI-CD field and propose a novel unsupervised HSI-CD with semantic correlation diffusion model (DiffUCD). Specifically, the semantic correlation diffusion model (SCDM) leverages abundant unlabeled samples and fully accounts for the semantic correlation of spectral-spatial features, which mitigates pseudo change between multi-temporal images arising from inconsistent imaging conditions. Besides, objects with the same semantic concept at the same spatial location may exhibit inconsistent spectral signatures at different times, resulting in pseudo change. To address this problem, we propose a cross-temporal contrastive learning (CTCL) mechanism that aligns the spectral feature representations of unchanged samples. By doing so, the spectral difference invariant features caused by environmental changes can be obtained. Experiments conducted on three publicly available datasets demonstrate that the proposed method outperforms the other state-of-the-art unsupervised methods in terms of Overall Accuracy (OA), Kappa Coefficient (KC), and F1 scores, achieving improvements of approximately 3.95%, 8.13%, and 4.45%, respectively. Notably, our method can achieve comparable results to those fully supervised methods requiring numerous annotated samples.
DynamicKD: An Effective Knowledge Distillation via Dynamic Entropy Correction-Based Distillation for Gap Optimizing
May 09, 2023The knowledge distillation uses a high-performance teacher network to guide the student network. However, the performance gap between the teacher and student networks can affect the student's training. This paper proposes a novel knowledge distillation algorithm based on dynamic entropy correction to reduce the gap by adjusting the student instead of the teacher. Firstly, the effect of changing the output entropy (short for output information entropy) in the student on the distillation loss is analyzed in theory. This paper shows that correcting the output entropy can reduce the gap. Then, a knowledge distillation algorithm based on dynamic entropy correction is created, which can correct the output entropy in real-time with an entropy controller updated dynamically by the distillation loss. The proposed algorithm is validated on the CIFAR100 and ImageNet. The comparison with various state-of-the-art distillation algorithms shows impressive results, especially in the experiment on the CIFAR100 regarding teacher-student pair resnet32x4-resnet8x4. The proposed algorithm raises 2.64 points over the traditional distillation algorithm and 0.87 points over the state-of-the-art algorithm CRD in classification accuracy, demonstrating its effectiveness and efficiency.
An EMO Joint Pruning with Multiple Sub-networks: Fast and Effect
Mar 28, 2023The network pruning algorithm based on evolutionary multi-objective (EMO) can balance the pruning rate and performance of the network. However, its population-based nature often suffers from the complex pruning optimization space and the highly resource-consuming pruning structure verification process, which limits its application. To this end, this paper proposes an EMO joint pruning with multiple sub-networks (EMO-PMS) to reduce space complexity and resource consumption. First, a divide-and-conquer EMO network pruning framework is proposed, which decomposes the complex EMO pruning task on the whole network into easier sub-tasks on multiple sub-networks. On the one hand, this decomposition reduces the pruning optimization space and decreases the optimization difficulty; on the other hand, the smaller network structure converges faster, so the computational resource consumption of the proposed algorithm is lower. Secondly, a sub-network training method based on cross-network constraints is designed so that the sub-network can process the features generated by the previous one through feature constraints. This method allows sub-networks optimized independently to collaborate better and improves the overall performance of the pruned network. Finally, a multiple sub-networks joint pruning method based on EMO is proposed. For one thing, it can accurately measure the feature processing capability of the sub-networks with the pre-trained feature selector. For another, it can combine multi-objective pruning results on multiple sub-networks through global performance impairment ranking to design a joint pruning scheme. The proposed algorithm is validated on three datasets with different challenging. Compared with fifteen advanced pruning algorithms, the experiment results exhibit the effectiveness and efficiency of the proposed algorithm.
Curvature-Balanced Feature Manifold Learning for Long-Tailed Classification
Mar 22, 2023To address the challenges of long-tailed classification, researchers have proposed several approaches to reduce model bias, most of which assume that classes with few samples are weak classes. However, recent studies have shown that tail classes are not always hard to learn, and model bias has been observed on sample-balanced datasets, suggesting the existence of other factors that affect model bias. In this work, we systematically propose a series of geometric measurements for perceptual manifolds in deep neural networks, and then explore the effect of the geometric characteristics of perceptual manifolds on classification difficulty and how learning shapes the geometric characteristics of perceptual manifolds. An unanticipated finding is that the correlation between the class accuracy and the separation degree of perceptual manifolds gradually decreases during training, while the negative correlation with the curvature gradually increases, implying that curvature imbalance leads to model bias. Therefore, we propose curvature regularization to facilitate the model to learn curvature-balanced and flatter perceptual manifolds. Evaluations on multiple long-tailed and non-long-tailed datasets show the excellent performance and exciting generality of our approach, especially in achieving significant performance improvements based on current state-of-the-art techniques. Our work opens up a geometric analysis perspective on model bias and reminds researchers to pay attention to model bias on non-long-tailed and even sample-balanced datasets. The code and model will be made public.
SoftMatch Distance: A Novel Distance for Weakly-Supervised Trend Change Detection in Bi-Temporal Images
Mar 08, 2023



General change detection (GCD) and semantic change detection (SCD) are common methods for identifying changes and distinguishing object categories involved in those changes, respectively. However, the binary changes provided by GCD is often not practical enough, while annotating semantic labels for training SCD models is very expensive. Therefore, there is a novel solution that intuitively dividing changes into three trends (``appear'', ``disappear'' and ``transform'') instead of semantic categories, named it trend change detection (TCD) in this paper. It offers more detailed change information than GCD, while requiring less manual annotation cost than SCD. However, there are limited public data sets with specific trend labels to support TCD application. To address this issue, we propose a softmatch distance which is used to construct a weakly-supervised TCD branch in a simple GCD model, using GCD labels instead of TCD label for training. Furthermore, a strategic approach is presented to successfully explore and extract background information, which is crucial for the weakly-supervised TCD task. The experiment results on four public data sets are highly encouraging, which demonstrates the effectiveness of our proposed model.
Bi-level Multi-objective Evolutionary Learning: A Case Study on Multi-task Graph Neural Topology Search
Feb 06, 2023The construction of machine learning models involves many bi-level multi-objective optimization problems (BL-MOPs), where upper level (UL) candidate solutions must be evaluated via training weights of a model in the lower level (LL). Due to the Pareto optimality of sub-problems and the complex dependency across UL solutions and LL weights, an UL solution is feasible if and only if the LL weight is Pareto optimal. It is computationally expensive to determine which LL Pareto weight in the LL Pareto weight set is the most appropriate for each UL solution. This paper proposes a bi-level multi-objective learning framework (BLMOL), coupling the above decision-making process with the optimization process of the UL-MOP by introducing LL preference $r$. Specifically, the UL variable and $r$ are simultaneously searched to minimize multiple UL objectives by evolutionary multi-objective algorithms. The LL weight with respect to $r$ is trained to minimize multiple LL objectives via gradient-based preference multi-objective algorithms. In addition, the preference surrogate model is constructed to replace the expensive evaluation process of the UL-MOP. We consider a novel case study on multi-task graph neural topology search. It aims to find a set of Pareto topologies and their Pareto weights, representing different trade-offs across tasks at UL and LL, respectively. The found graph neural network is employed to solve multiple tasks simultaneously, including graph classification, node classification, and link prediction. Experimental results demonstrate that BLMOL can outperform some state-of-the-art algorithms and generate well-representative UL solutions and LL weights.
Delving into Semantic Scale Imbalance
Jan 10, 2023Model bias triggered by long-tailed data has been widely studied. However, measure based on the number of samples cannot explicate three phenomena simultaneously: (1) Given enough data, the classification performance gain is marginal with additional samples. (2) Classification performance decays precipitously as the number of training samples decreases when there is insufficient data. (3) Model trained on sample-balanced datasets still has different biases for different classes. In this work, we define and quantify the semantic scale of classes, which is used to measure the feature diversity of classes. It is exciting to find experimentally that there is a marginal effect of semantic scale, which perfectly describes the first two phenomena. Further, the quantitative measurement of semantic scale imbalance is proposed, which can accurately reflect model bias on multiple datasets, even on sample-balanced data, revealing a novel perspective for the study of class imbalance. Due to the prevalence of semantic scale imbalance, we propose semantic-scale-balanced learning, including a general loss improvement scheme and a dynamic re-weighting training framework that overcomes the challenge of calculating semantic scales in real-time during iterations. Comprehensive experiments show that dynamic semantic-scale-balanced learning consistently enables the model to perform superiorly on large-scale long-tailed and non-long-tailed natural and medical datasets, which is a good starting point for mitigating the prevalent but unnoticed model bias.
Absolute Wrong Makes Better: Boosting Weakly Supervised Object Detection via Negative Deterministic Information
Apr 21, 2022
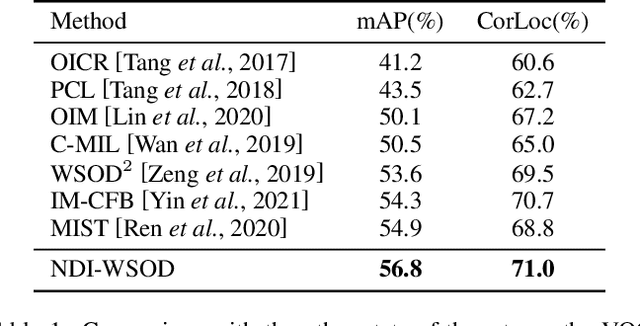
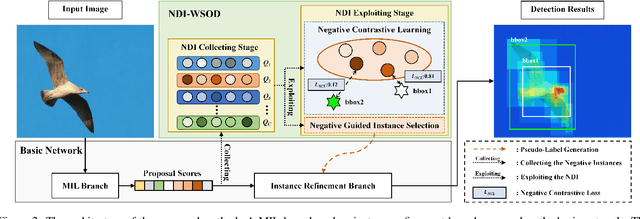
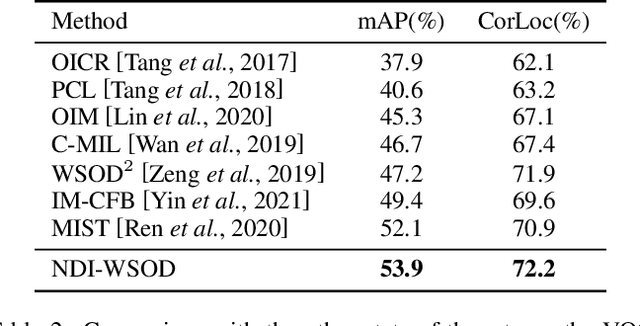
Weakly supervised object detection (WSOD) is a challenging task, in which image-level labels (e.g., categories of the instances in the whole image) are used to train an object detector. Many existing methods follow the standard multiple instance learning (MIL) paradigm and have achieved promising performance. However, the lack of deterministic information leads to part domination and missing instances. To address these issues, this paper focuses on identifying and fully exploiting the deterministic information in WSOD. We discover that negative instances (i.e. absolutely wrong instances), ignored in most of the previous studies, normally contain valuable deterministic information. Based on this observation, we here propose a negative deterministic information (NDI) based method for improving WSOD, namely NDI-WSOD. Specifically, our method consists of two stages: NDI collecting and exploiting. In the collecting stage, we design several processes to identify and distill the NDI from negative instances online. In the exploiting stage, we utilize the extracted NDI to construct a novel negative contrastive learning mechanism and a negative guided instance selection strategy for dealing with the issues of part domination and missing instances, respectively. Experimental results on several public benchmarks including VOC 2007, VOC 2012 and MS COCO show that our method achieves satisfactory performance.
A Multi-Transformation Evolutionary Framework for Influence Maximization in Social Networks
Apr 07, 2022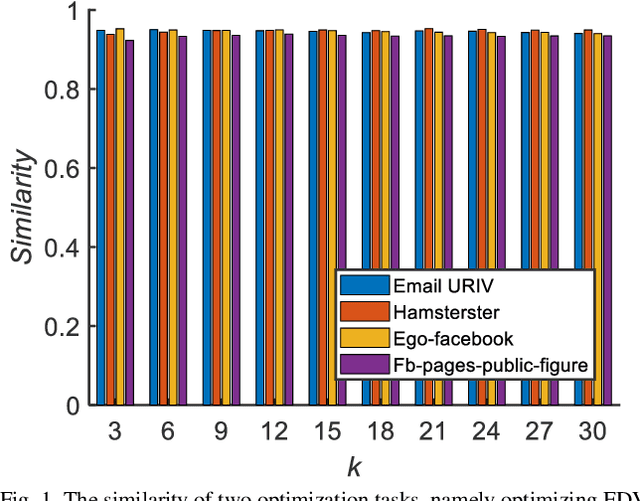
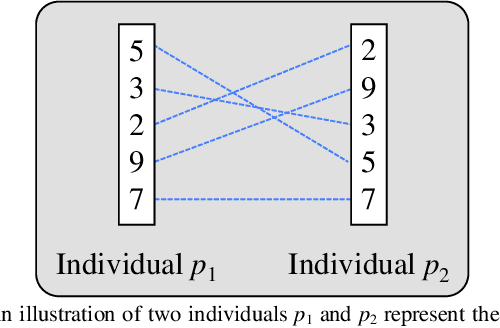
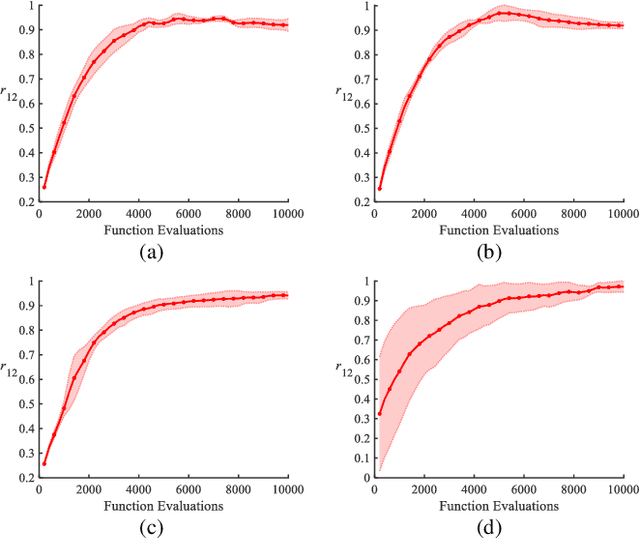
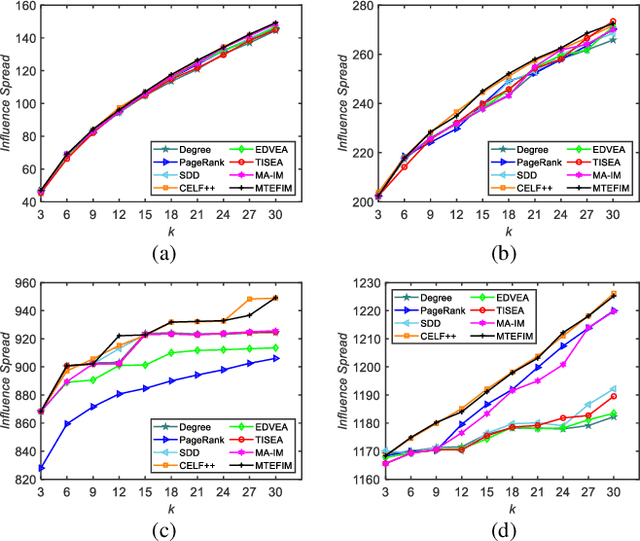
Influence maximization is a key issue for mining the deep information of social networks, which aims to select a seed set from the network to maximize the number of influenced nodes. To evaluate the influence spread of a seed set efficiently, existing works have proposed some proxy models (transformations) with lower computational costs to replace the expensive Monte Carlo simulation process. These alternate transformations based on network prior knowledge induce different search behaviors with similar characteristics from various perspectives. For a specific case, it is difficult for users to determine a suitable transformation a priori. Keeping those in mind, we propose a multi-transformation evolutionary framework for influence maximization (MTEFIM) to exploit the potential similarities and unique advantages of alternate transformations and avoid users to determine the most suitable one manually. In MTEFIM, multiple transformations are optimized simultaneously as multiple tasks. Each transformation is assigned an evolutionary solver. Three major components of MTEFIM are conducted: 1) estimating the potential relationship across transformations based on the degree of overlap across individuals (seed sets) of different populations, 2) transferring individuals across populations adaptively according to the inter-transformation relationship, 3) selecting the final output seed set containing all the proxy model knowledge. The effectiveness of MTEFIM is validated on four real-world social networks. Experimental results show that MTEFIM can efficiently utilize the potentially transferable knowledge across multiple transformations to achieve highly competitive performance compared to several popular IM-specific methods. The implementation of MTEFIM can be accessed at https://github.com/xiaofangxd/MTEFIM.