 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCCoder: Streamlining Motion Control with LLM-Assisted Code Generation and Rigorous Verification
Oct 19, 2024



Large Language Models (LLMs) have shown considerable promise in code generation. However, the automation sector, especially in motion control, continues to rely heavily on manual programming due to the complexity of tasks and critical safety considerations. In this domain, incorrect code execution can pose risks to both machinery and personnel, necessitating specialized expertise. To address these challenges, we introduce MCCoder, an LLM-powered system designed to generate code that addresses complex motion control tasks, with integrated soft-motion data verification. MCCoder enhances code generation through multitask decomposition, hybrid retrieval-augmented generation (RAG), and self-correction with a private motion library. Moreover, it supports data verification by logging detailed trajectory data and providing simulations and plots, allowing users to assess the accuracy of the generated code and bolstering confidence in LLM-based programming. To ensure robust validation, we propose MCEVAL, an evaluation dataset with metrics tailored to motion control tasks of varying difficulties. Experiments indicate that MCCoder improves performance by 11.61% overall and by 66.12% on complex tasks in MCEVAL dataset compared with base models with naive RAG. This system and dataset aim to facilitate the application of code generation in automation settings with strict safety requirements. MCCoder is publicly available at https://github.com/MCCodeAI/MCCoder.
TypeDance: Creating Semantic Typographic Logos from Image through Personalized Generation
Jan 20, 2024



Semantic typographic logos harmoniously blend typeface and imagery to represent semantic concepts while maintaining legibility. Conventional methods using spatial composition and shape substitution are hindered by the conflicting requirement for achieving seamless spatial fusion between geometrically dissimilar typefaces and semantics. While recent advances made AI generation of semantic typography possible, the end-to-end approaches exclude designer involvement and disregard personalized design. This paper presents TypeDance, an AI-assisted tool incorporating design rationales with the generative model for personalized semantic typographic logo design. It leverages combinable design priors extracted from uploaded image exemplars and supports type-imagery mapping at various structural granularity, achieving diverse aesthetic designs with flexible control. Additionally, we instantiate a comprehensive design workflow in TypeDance, including ideation, selection, generation, evaluation, and iteration. A two-task user evaluation, including imitation and creation, confirmed the usability of TypeDance in design across different usage scenarios
Wukong-Reader: Multi-modal Pre-training for Fine-grained Visual Document Understanding
Dec 19, 2022



Unsupervised pre-training on millions of digital-born or scanned documents has shown promising advances in visual document understanding~(VDU). While various vision-language pre-training objectives are studied in existing solutions, the document textline, as an intrinsic granularity in VDU, has seldom been explored so far. A document textline usually contains words that are spatially and semantically correlated, which can be easily obtained from OCR engines. In this paper, we propose Wukong-Reader, trained with new pre-training objectives to leverage the structural knowledge nested in document textlines. We introduce textline-region contrastive learning to achieve fine-grained alignment between the visual regions and texts of document textlines. Furthermore, masked region modeling and textline-grid matching are also designed to enhance the visual and layout representations of textlines. Experiments show that our Wukong-Reader has superior performance on various VDU tasks such as information extraction. The fine-grained alignment over textlines also empowers Wukong-Reader with promising localization ability.
One-shot Key Information Extraction from Document with Deep Partial Graph Matching
Sep 26, 2021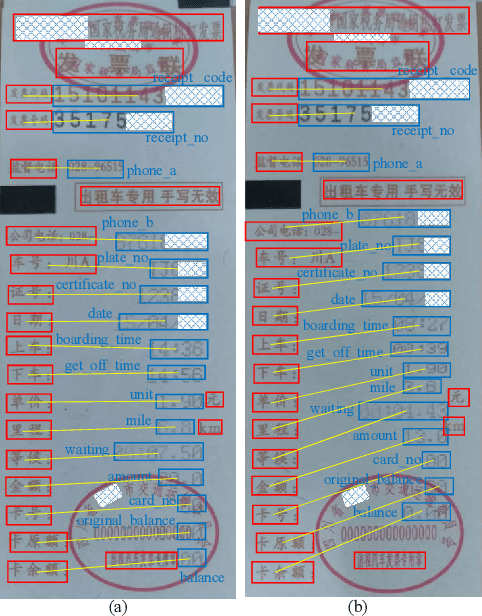
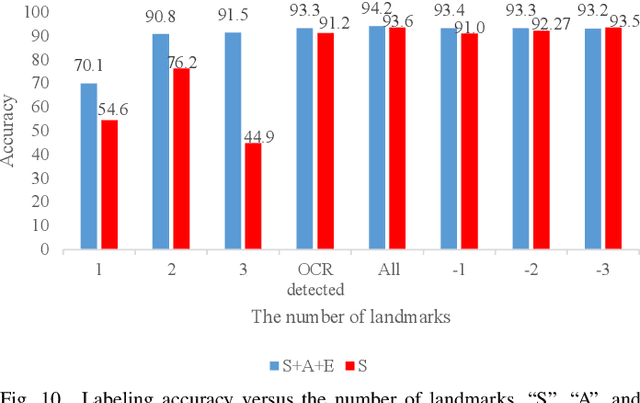
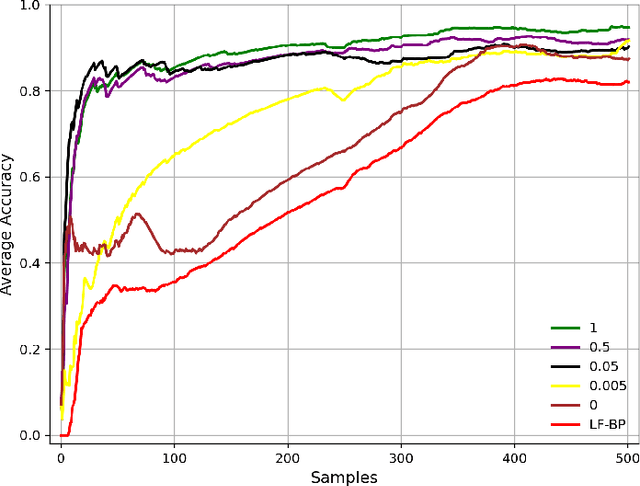
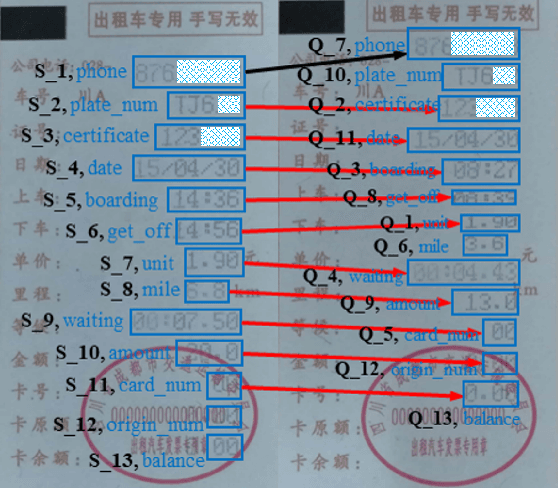
Automating the Key Information Extraction (KIE) from documents improves efficiency, productivity, and security in many industrial scenarios such as rapid indexing and archiving. Many existing supervised learning methods for the KIE task need to feed a large number of labeled samples and learn separate models for different types of documents. However, collecting and labeling a large dataset is time-consuming and is not a user-friendly requirement for many cloud platforms. To overcome these challenges, we propose a deep end-to-end trainable network for one-shot KIE using partial graph matching. Contrary to previous methods that the learning of similarity and solving are optimized separately, our method enables the learning of the two processes in an end-to-end framework. Existing one-shot KIE methods are either template or simple attention-based learning approach that struggle to handle texts that are shifted beyond their desired positions caused by printers, as illustrated in Fig.1. To solve this problem, we add one-to-(at most)-one constraint such that we will find the globally optimized solution even if some texts are drifted. Further, we design a multimodal context ensemble block to boost the performance through fusing features of spatial, textual, and aspect representations. To promote research of KIE, we collected and annotated a one-shot document KIE dataset named DKIE with diverse types of images. The DKIE dataset consists of 2.5K document images captured by mobile phones in natural scenes, and it is the largest available one-shot KIE dataset up to now. The results of experiments on DKIE show that our method achieved state-of-the-art performance compared with recent one-shot and supervised learning approaches. The dataset and proposed one-shot KIE model will be released soo
On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering
Feb 26, 2020
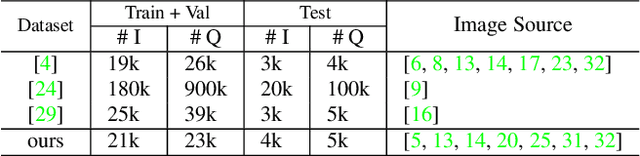

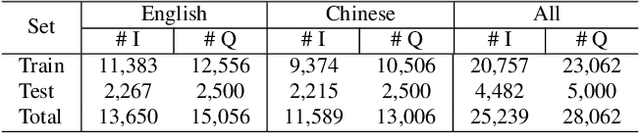
Visual Question Answering (VQA) methods have made incredible progress, but suffer from a failure to generalize. This is visible in the fact that they are vulnerable to learning coincidental correlations in the data rather than deeper relations between image content and ideas expressed in language. We present a dataset that takes a step towards addressing this problem in that it contains questions expressed in two languages, and an evaluation process that co-opts a well understood image-based metric to reflect the method's ability to reason. Measuring reasoning directly encourages generalization by penalizing answers that are coincidentally correct. The dataset reflects the scene-text version of the VQA problem, and the reasoning evaluation can be seen as a text-based version of a referring expression challenge. Experiments and analysis are provided that show the value of the dataset.
ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network
Feb 25, 2020
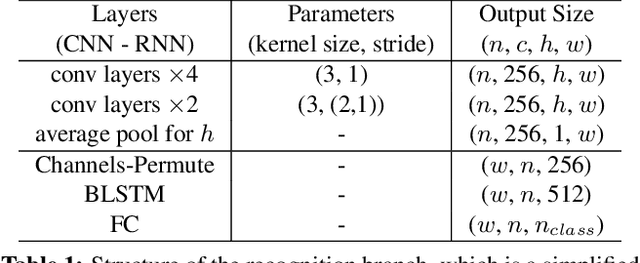
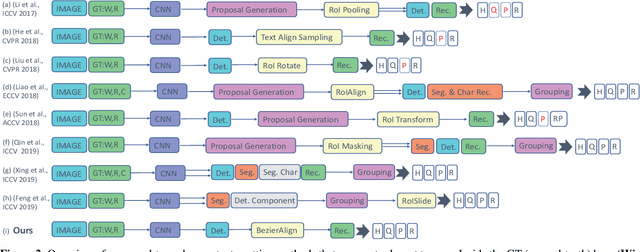
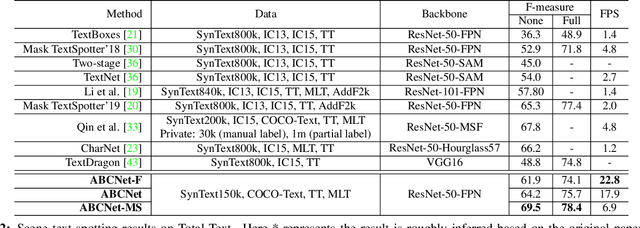
Scene text detection and recognition has received increasing research attention. Existing methods can be roughly categorized into two groups: character-based and segmentation-based. These methods either are costly for character annotation or need to maintain a complex pipeline, which is often not suitable for real-time applications. Here we address the problem by proposing the Adaptive Bezier-Curve Network (ABCNet). Our contributions are three-fold: 1) For the first time, we adaptively fit arbitrarily-shaped text by a parameterized Bezier curve. 2) We design a novel BezierAlign layer for extracting accurate convolution features of a text instance with arbitrary shapes, significantly improving the precision compared with previous methods. 3) Compared with standard bounding box detection, our Bezier curve detection introduces negligible computation overhead, resulting in superiority of our method in both efficiency and accuracy. Experiments on arbitrarily-shaped benchmark datasets, namely Total-Text and CTW1500, demonstrate that ABCNet achieves state-of-the-art accuracy, meanwhile significantly improving the speed. In particular, on Total-Text, our realtime version is over 10 times faster than recent state-of-the-art methods with a competitive recognition accuracy. Code is available at https://tinyurl.com/AdelaiDet