 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Response Function Guided Deep Optimization-driven Network for Spectral Super-resolution
Dec 08, 2020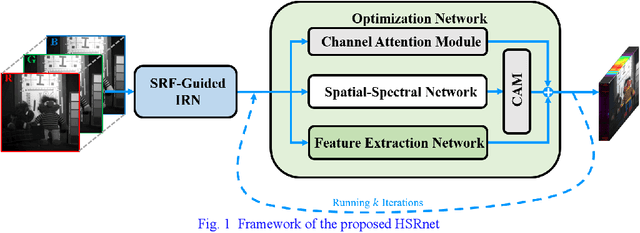

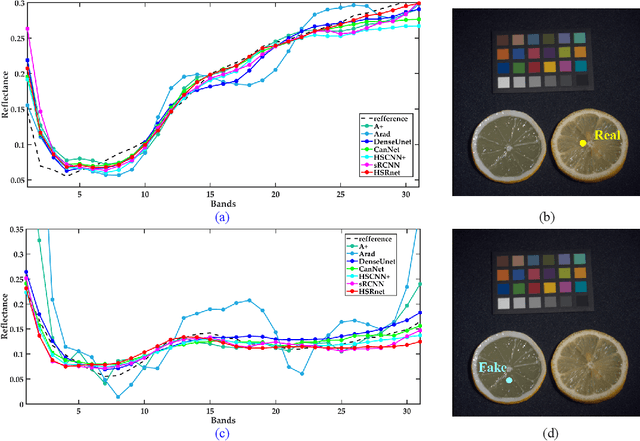
Hyperspectral images are crucial for many research works. Spectral super-resolution (SSR) is a method used to obtain high spatial resolution (HR) hyperspectral images from HR multispectral images. Traditional SSR methods include model-driven algorithms and deep learning. By unfolding a variational method, this paper proposes an optimization-driven convolutional neural network (CNN) with a deep spatial-spectral prior, resulting in physically interpretable networks. Unlike the fully data-driven CNN, auxiliary spectral response function (SRF) is utilized to guide CNNs to group the bands with spectral relevance. In addition, the channel attention module (CAM) and reformulated spectral angle mapper loss function are applied to achieve an effective reconstruction model. Finally, experiments on two types of datasets, including natural and remote sensing images, demonstrate the spectral enhancement effect of the proposed method. And the classification results on the remote sensing dataset also verified the validity of the information enhanced by the proposed method.
FPGA: Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification
Nov 11, 2020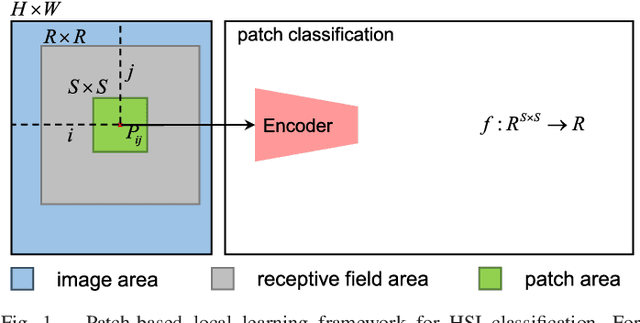

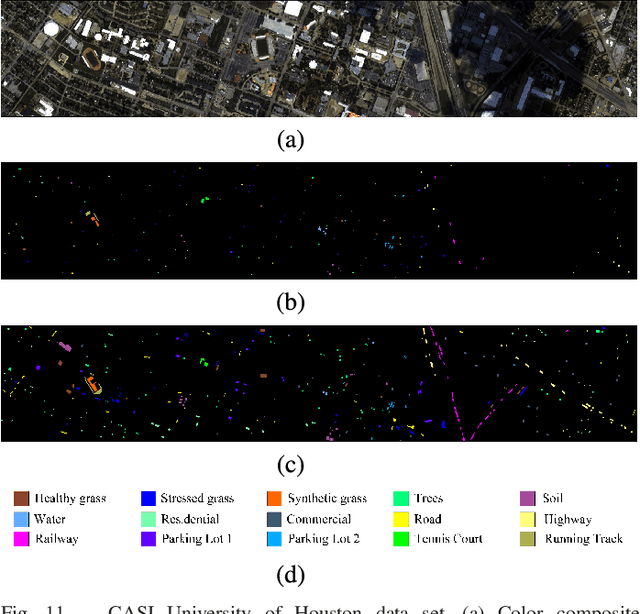
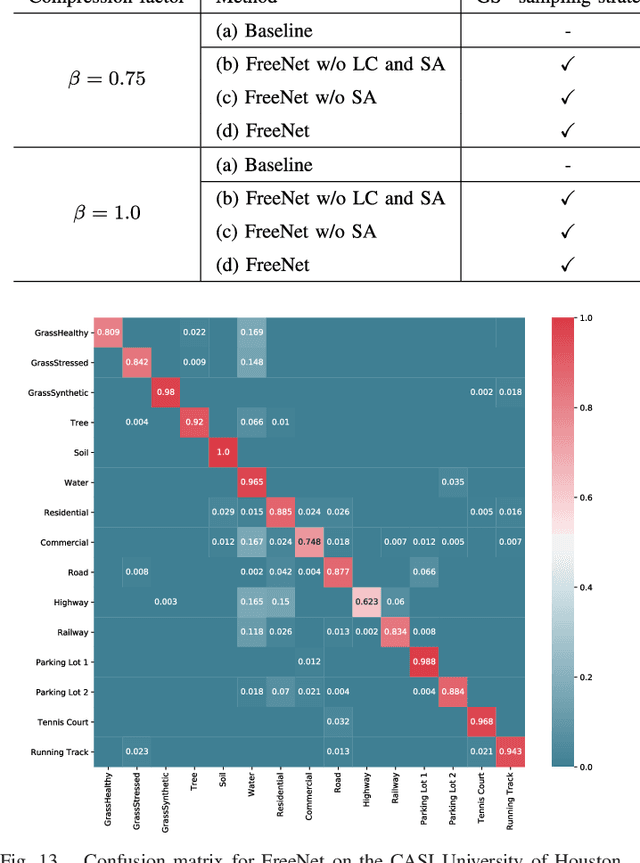
Deep learning techniques have provided significant improvements in hyperspectral image (HSI) classification. The current deep learning based HSI classifiers follow a patch-based learning framework by dividing the image into overlapping patches. As such, these methods are local learning methods, which have a high computational cost. In this paper, a fast patch-free global learning (FPGA) framework is proposed for HSI classification. In FPGA, an encoder-decoder based FCN is utilized to consider the global spatial information by processing the whole image, which results in fast inference. However, it is difficult to directly utilize the encoder-decoder based FCN for HSI classification as it always fails to converge due to the insufficiently diverse gradients caused by the limited training samples. To solve the divergence problem and maintain the abilities of FCN of fast inference and global spatial information mining, a global stochastic stratified sampling strategy is first proposed by transforming all the training samples into a stochastic sequence of stratified samples. This strategy can obtain diverse gradients to guarantee the convergence of the FCN in the FPGA framework. For a better design of FCN architecture, FreeNet, which is a fully end-to-end network for HSI classification, is proposed to maximize the exploitation of the global spatial information and boost the performance via a spectral attention based encoder and a lightweight decoder. A lateral connection module is also designed to connect the encoder and decoder, fusing the spatial details in the encoder and the semantic features in the decoder. The experimental results obtained using three public benchmark datasets suggest that the FPGA framework is superior to the patch-based framework in both speed and accuracy for HSI classification. Code has been made available at: https://github.com/Z-Zheng/FreeNet.
Hyperspectral Anomaly Change Detection Based on Auto-encoder
Oct 27, 2020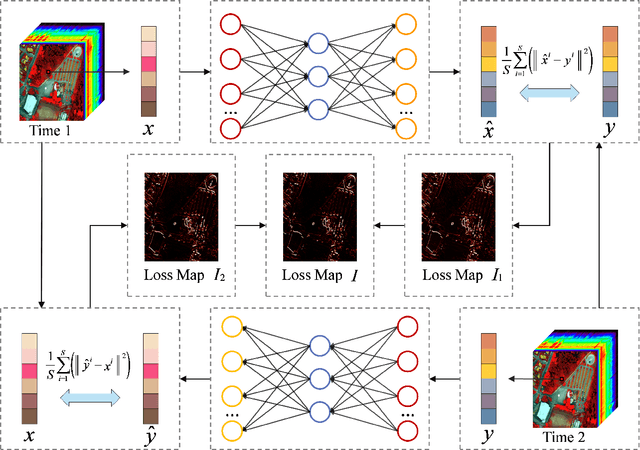



With the hyperspectral imaging technology, hyperspectral data provides abundant spectral information and plays a more important role in geological survey, vegetation analysis and military reconnaissance. Different from normal change detection, hyperspectral anomaly change detection (HACD) helps to find those small but important anomaly changes between multi-temporal hyperspectral images (HSI). In previous works, most classical methods use linear regression to establish the mapping relationship between two HSIs and then detect the anomalies from the residual image. However, the real spectral differences between multi-temporal HSIs are likely to be quite complex and of nonlinearity, leading to the limited performance of these linear predictors. In this paper, we propose an original HACD algorithm based on auto-encoder (ACDA) to give a nonlinear solution. The proposed ACDA can construct an effective predictor model when facing complex imaging conditions. In the ACDA model, two systematic auto-encoder (AE) networks are deployed to construct two predictors from two directions. The predictor is used to model the spectral variation of the background to obtain the predicted image under another imaging condition. Then mean square error (MSE) between the predictive image and corresponding expected image is computed to obtain the loss map, where the spectral differences of the unchanged pixels are highly suppressed and anomaly changes are highlighted. Ultimately, we take the minimum of the two loss maps of two directions as the final anomaly change intensity map. The experiments results on public "Viareggio 2013" datasets demonstrate the efficiency and superiority over traditional methods.
Non-local Meets Global: An Iterative Paradigm for Hyperspectral Image Restoration
Oct 24, 2020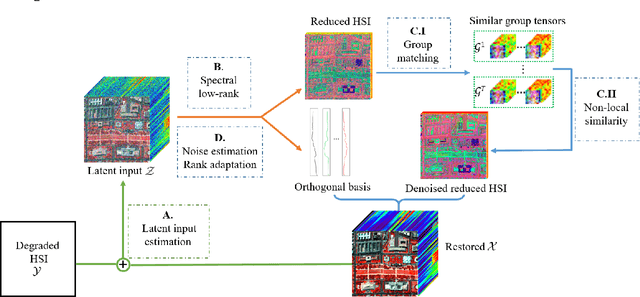
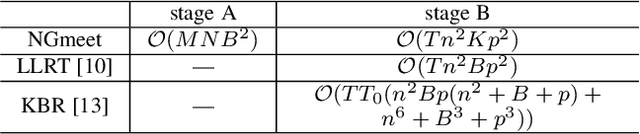
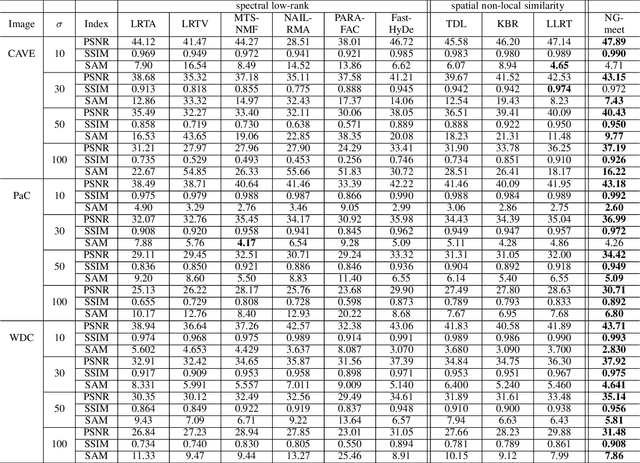
Non-local low-rank tensor approximation has been developed as a state-of-the-art method for hyperspectral image (HSI) restoration, which includes the tasks of denoising, compressed HSI reconstruction and inpainting. Unfortunately, while its restoration performance benefits from more spectral bands, its runtime also substantially increases. In this paper, we claim that the HSI lies in a global spectral low-rank subspace, and the spectral subspaces of each full band patch group should lie in this global low-rank subspace. This motivates us to propose a unified paradigm combining the spatial and spectral properties for HSI restoration. The proposed paradigm enjoys performance superiority from the non-local spatial denoising and light computation complexity from the low-rank orthogonal basis exploration. An efficient alternating minimization algorithm with rank adaptation is developed. It is done by first solving a fidelity term-related problem for the update of a latent input image, and then learning a low-dimensional orthogonal basis and the related reduced image from the latent input image. Subsequently, non-local low-rank denoising is developed to refine the reduced image and orthogonal basis iteratively. Finally, the experiments on HSI denoising, compressed reconstruction, and inpainting tasks, with both simulated and real datasets, demonstrate its superiority with respect to state-of-the-art HSI restoration methods.
Few-Shot Hyperspectral Image Classification With Unknown Classes Using Multitask Deep Learning
Sep 08, 2020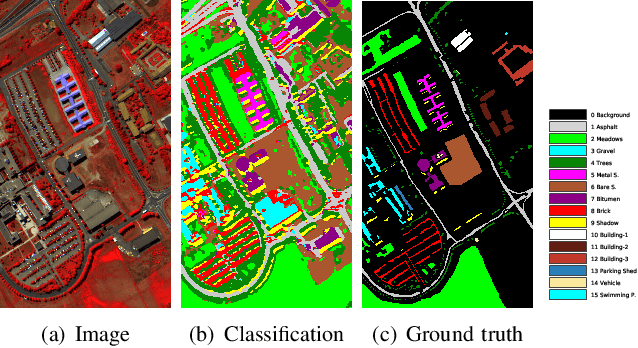
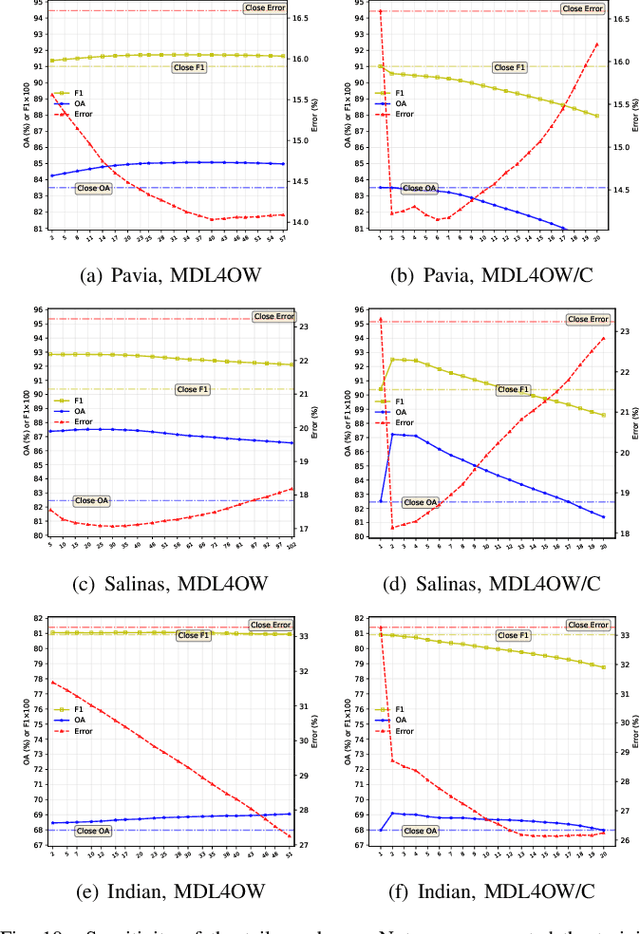
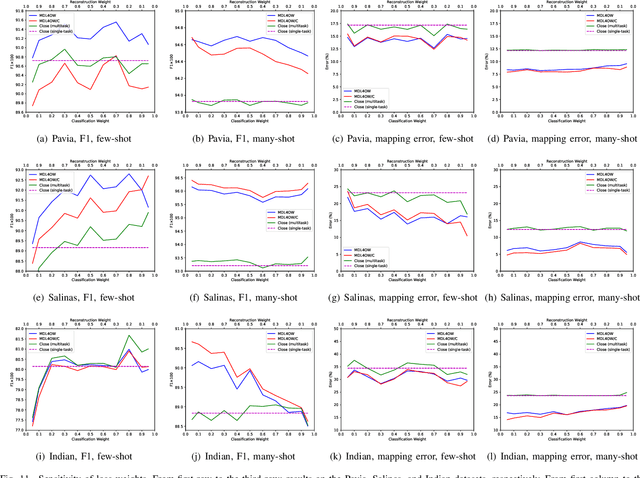
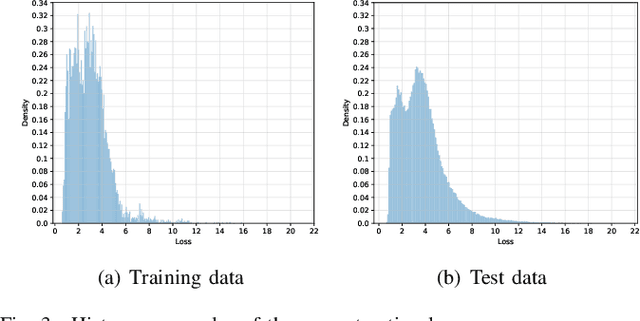
Current hyperspectral image classification assumes that a predefined classification system is closed and complete, and there are no unknown or novel classes in the unseen data. However, this assumption may be too strict for the real world. Often, novel classes are overlooked when the classification system is constructed. The closed nature forces a model to assign a label given a new sample and may lead to overestimation of known land covers (e.g., crop area). To tackle this issue, we propose a multitask deep learning method that simultaneously conducts classification and reconstruction in the open world (named MDL4OW) where unknown classes may exist. The reconstructed data are compared with the original data; those failing to be reconstructed are considered unknown, based on the assumption that they are not well represented in the latent features due to the lack of labels. A threshold needs to be defined to separate the unknown and known classes; we propose two strategies based on the extreme value theory for few-shot and many-shot scenarios. The proposed method was tested on real-world hyperspectral images; state-of-the-art results were achieved, e.g., improving the overall accuracy by 4.94% for the Salinas data. By considering the existence of unknown classes in the open world, our method achieved more accurate hyperspectral image classification, especially under the few-shot context.
A Measurement of Transportation Ban inside Wuhan on the COVID-19 Epidemic by Vehicle Detection in Remote Sensing Imagery
Jun 26, 2020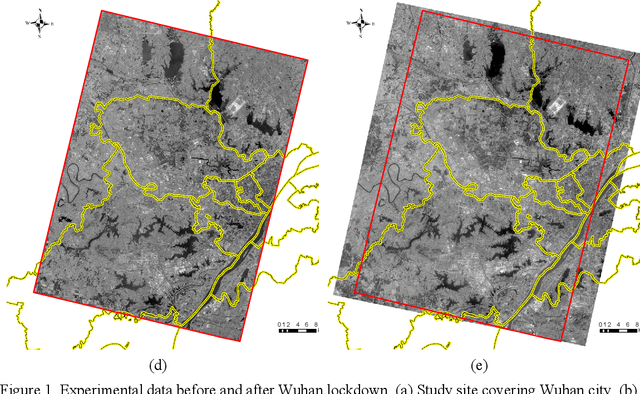
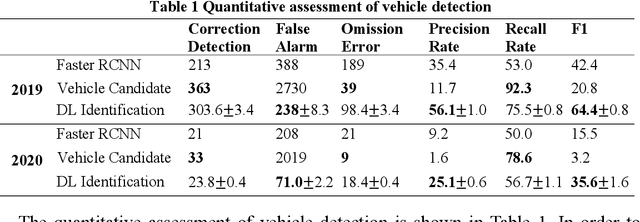
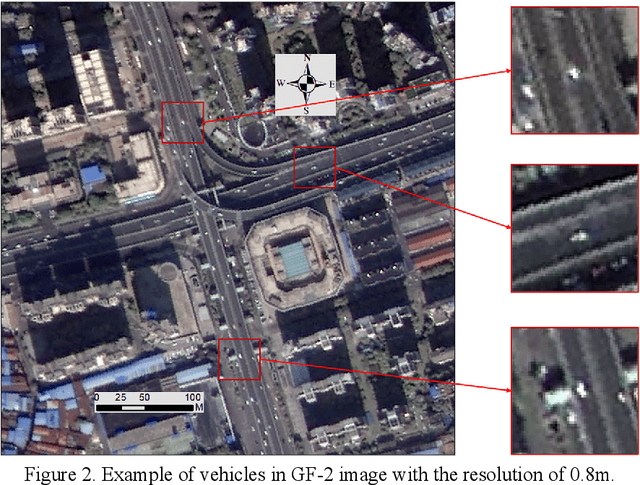
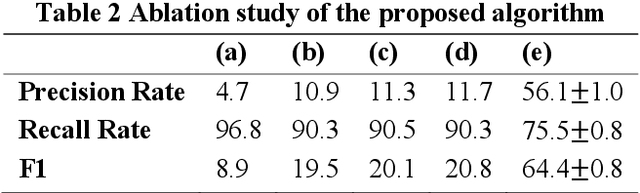
Wuhan, the biggest city in China's central region with a population of more than 11 million, was shut down to control the COVID-19 epidemic on 23 January, 2020. Even though many researches have studied the travel restriction between cities and provinces, few studies focus on the transportation control inside the city, which may be due to the lack of the measurement of the transportation ban. Therefore, we evaluate the implementation of transportation ban policy inside the city by extracting motor vehicles on the road from two high-resolution remote sensing image sets before and after Wuhan lockdown. In order to detect vehicles from the remote sensing image datasets with the resolution of 0.8m accurately, we proposed a novel method combining anomaly detection, region grow and deep learning. The vehicle numbers in Wuhan dropped with a percentage of at least 63.31% caused by COVID-19. Considering fewer interferences, the dropping percentages of ring road and high-level road should be more representative with the value of 84.81% and 80.22%. The districts located in city center were more intensively affected by the transportation ban. Since the public transportations have been shut down, the significant reduction of motor vehicles indicates that the lockdown policy in Wuhan show effectiveness in controlling human transmission inside the city.
DiRS: On Creating Benchmark Datasets for Remote Sensing Image Interpretation
Jun 22, 2020



The past decade has witnessed great progress on remote sensing (RS) image interpretation and its wide applications. With RS images becoming more accessible than ever before, there is an increasing demand for the automatic interpretation of these images, where benchmark datasets are essential prerequisites for developing and testing intelligent interpretation algorithms. After reviewing existing benchmark datasets in the research community of RS image interpretation, this article discusses the problem of how to efficiently prepare a suitable benchmark dataset for RS image analysis. Specifically, we first analyze the current challenges of developing intelligent algorithms for RS image interpretation with bibliometric investigations. We then present some principles, i.e., diversity, richness, and scalability (called DiRS), on constructing benchmark datasets in efficient manners. Following the DiRS principles, we also provide an example on building datasets for RS image classification, i.e., Million-AID, a new large-scale benchmark dataset containing million instances for RS scene classification. Several challenges and perspectives in RS image annotation are finally discussed to facilitate the research in benchmark dataset construction. We do hope this paper will provide RS community an overall perspective on constructing large-scale and practical image datasets for further research, especially data-driven ones.
DSDANet: Deep Siamese Domain Adaptation Convolutional Neural Network for Cross-domain Change Detection
Jun 16, 2020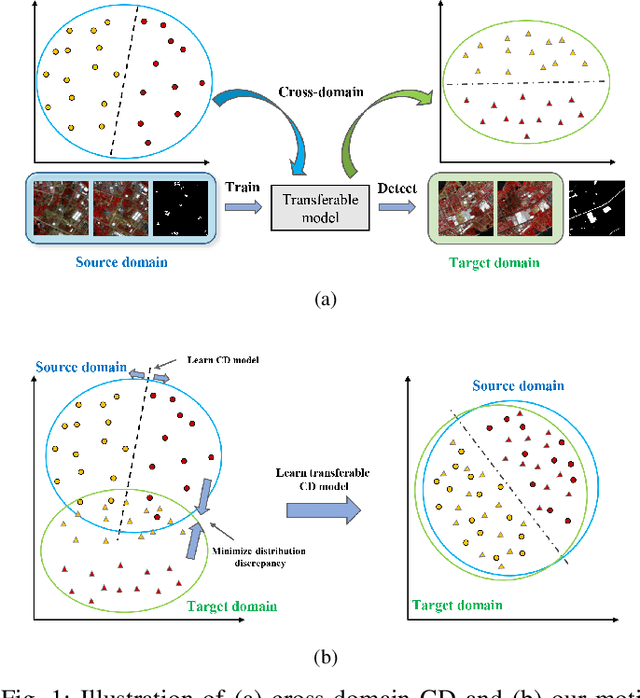
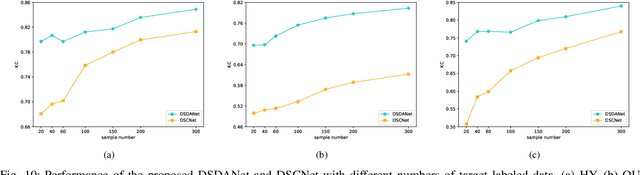
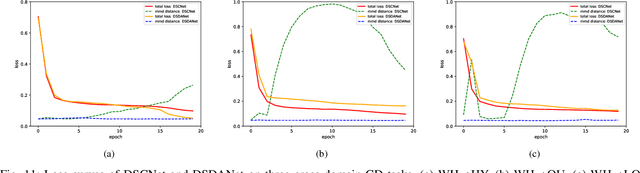
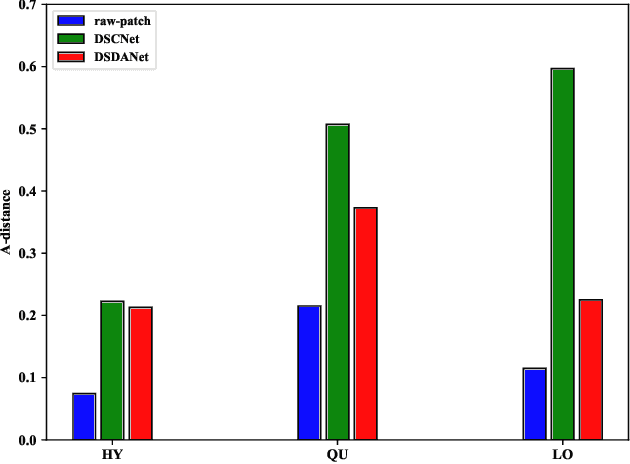
Change detection (CD) is one of the most vital applications in remote sensing. Recently, deep learning has achieved promising performance in the CD task. However, the deep models are task-specific and CD data set bias often exists, hence it is inevitable that deep CD models would suffer degraded performance after transferring it from original CD data set to new ones, making manually label numerous samples in the new data set unavoidable, which costs a large amount of time and human labor. How to learn a transferable CD model in the data set with enough labeled data (original domain) but can well detect changes in another data set without labeled data (target domain)? This is defined as the cross-domain change detection problem. In this paper, we propose a novel deep siamese domain adaptation convolutional neural network (DSDANet) architecture for cross-domain CD. In DSDANet, a siamese convolutional neural network first extracts spatial-spectral features from multi-temporal images. Then, through multi-kernel maximum mean discrepancy (MK-MMD), the learned feature representation is embedded into a reproducing kernel Hilbert space (RKHS), in which the distribution of two domains can be explicitly matched. By optimizing the network parameters and kernel coefficients with the source labeled data and target unlabeled data, DSDANet can learn transferrable feature representation that can bridge the discrepancy between two domains. To the best of our knowledge, it is the first time that such a domain adaptation-based deep network is proposed for CD. The theoretical analysis and experimental results demonstrate the effectiveness and potential of the proposed method.
Holistically-Attracted Wireframe Parsing
Mar 03, 2020
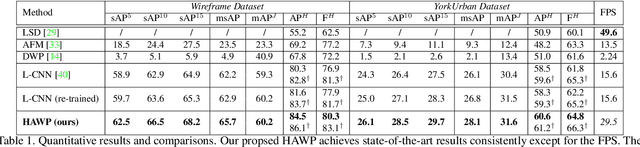
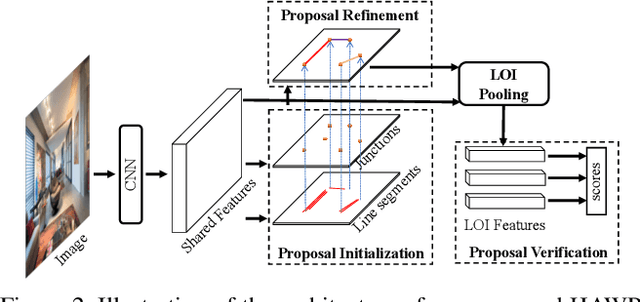
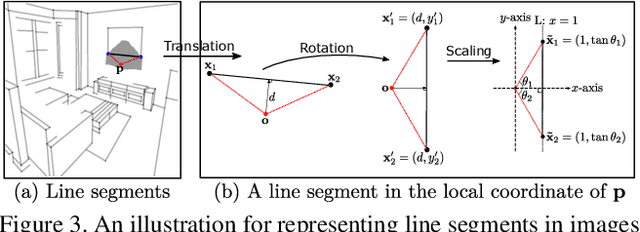
This paper presents a fast and parsimonious parsing method to accurately and robustly detect a vectorized wireframe in an input image with a single forward pass. The proposed method is end-to-end trainable, consisting of three components: (i) line segment and junction proposal generation, (ii) line segment and junction matching, and (iii) line segment and junction verification. For computing line segment proposals, a novel exact dual representation is proposed which exploits a parsimonious geometric reparameterization for line segments and forms a holistic 4-dimensional attraction field map for an input image. Junctions can be treated as the "basins" in the attraction field. The proposed method is thus called Holistically-Attracted Wireframe Parser (HAWP). In experiments, the proposed method is tested on two benchmarks, the Wireframe dataset, and the YorkUrban dataset. On both benchmarks, it obtains state-of-the-art performance in terms of accuracy and efficiency. For example, on the Wireframe dataset, compared to the previous state-of-the-art method L-CNN, it improves the challenging mean structural average precision (msAP) by a large margin ($2.8\%$ absolute improvements) and achieves 29.5 FPS on single GPU ($89\%$ relative improvement). A systematic ablation study is performed to further justify the proposed method.
Unsupervised Change Detection in Multi-temporal VHR Images Based on Deep Kernel PCA Convolutional Mapping Network
Dec 18, 2019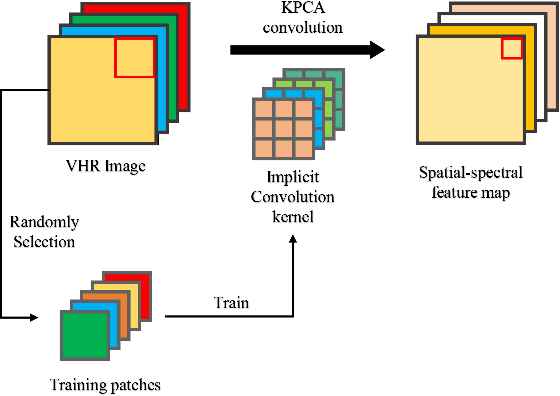
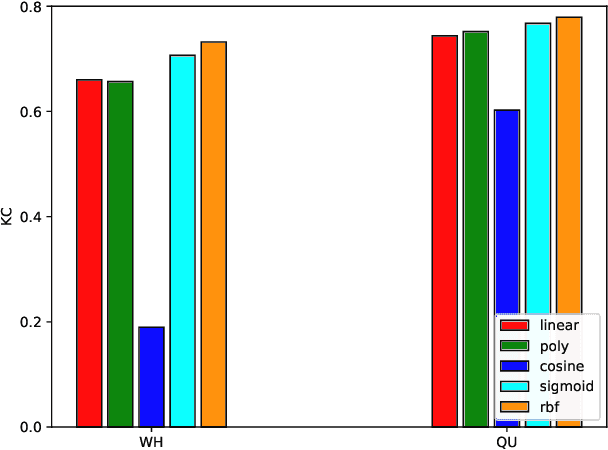


With the development of Earth observation technology, very-high-resolution (VHR) image has become an important data source of change detection. Nowadays, deep learning methods have achieved conspicuous performance in the change detection of VHR images. Nonetheless, most of the existing change detection models based on deep learning require annotated training samples. In this paper, a novel unsupervised model called kernel principal component analysis (KPCA) convolution is proposed for extracting representative features from multi-temporal VHR images. Based on the KPCA convolution, an unsupervised deep siamese KPCA convolutional mapping network (KPCA-MNet) is designed for binary and multi-class change detection. In the KPCA-MNet, the high-level spatial-spectral feature maps are extracted by a deep siamese network consisting of weight-shared PCA convolution layers. Then, the change information in the feature difference map is mapped into a 2-D polar domain. Finally, the change detection results are generated by threshold segmentation and clustering algorithms. All procedures of KPCA-MNet does not require labeled data. The theoretical analysis and experimental results demonstrate the validity, robustness, and potential of the proposed method in two binary change detection data sets and one multi-class change detection data set.