 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayout-Graph Reasoning for Fashion Landmark Detection
Oct 04, 2019
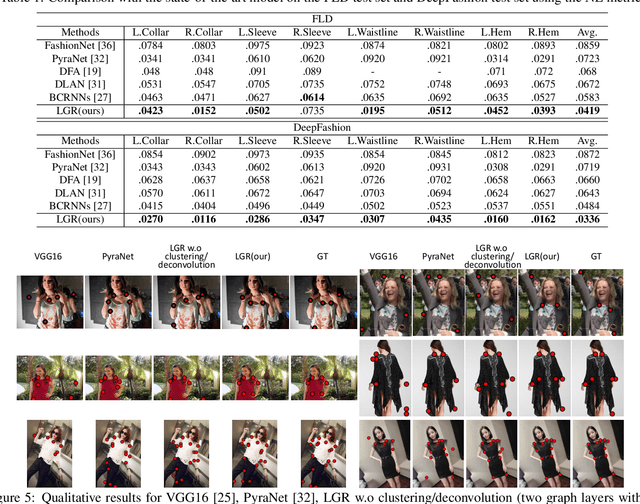

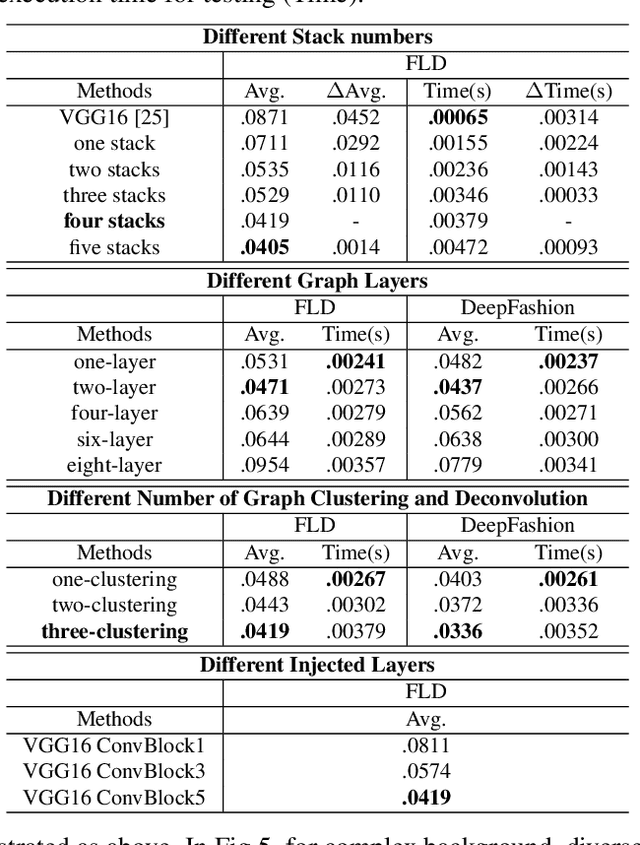
Detecting dense landmarks for diverse clothes, as a fundamental technique for clothes analysis, has attracted increasing research attention due to its huge application potential. However, due to the lack of modeling underlying semantic layout constraints among landmarks, prior works often detect ambiguous and structure-inconsistent landmarks of multiple overlapped clothes in one person. In this paper, we propose to seamlessly enforce structural layout relationships among landmarks on the intermediate representations via multiple stacked layout-graph reasoning layers. We define the layout-graph as a hierarchical structure including a root node, body-part nodes (e.g. upper body, lower body), coarse clothes-part nodes (e.g. collar, sleeve) and leaf landmark nodes (e.g. left-collar, right-collar). Each Layout-Graph Reasoning(LGR) layer aims to map feature representations into structural graph nodes via a Map-to-Node module, performs reasoning over structural graph nodes to achieve global layout coherency via a layout-graph reasoning module, and then maps graph nodes back to enhance feature representations via a Node-to-Map module. The layout-graph reasoning module integrates a graph clustering operation to generate representations of intermediate nodes (bottom-up inference) and then a graph deconvolution operation (top-down inference) over the whole graph. Extensive experiments on two public fashion landmark datasets demonstrate the superiority of our model. Furthermore, to advance the fine-grained fashion landmark research for supporting more comprehensive clothes generation and attribute recognition, we contribute the first Fine-grained Fashion Landmark Dataset (FFLD) containing 200k images annotated with at most 32 key-points for 13 clothes types.
Meta R-CNN : Towards General Solver for Instance-level Low-shot Learning
Sep 28, 2019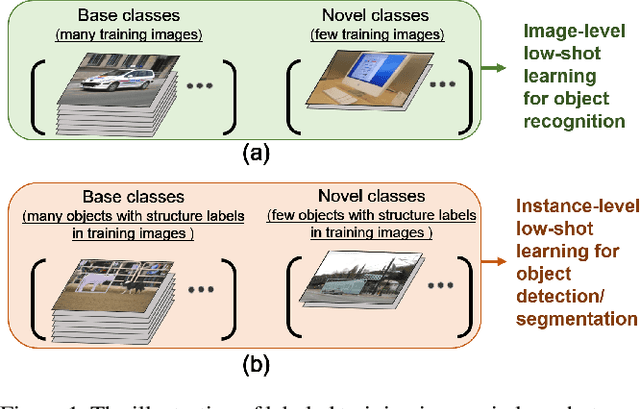
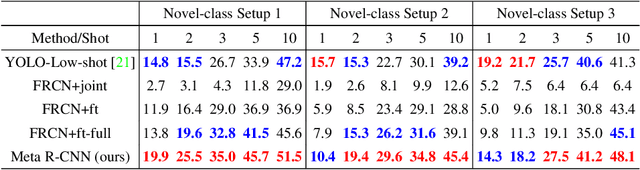
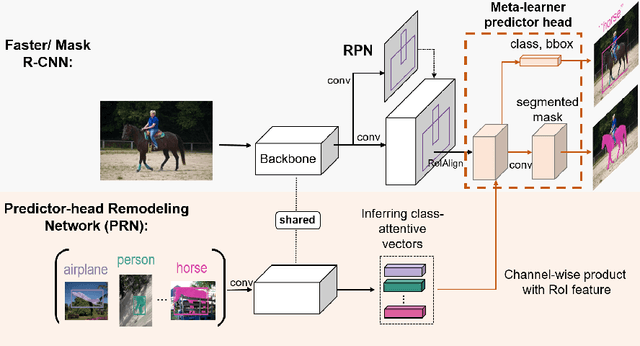
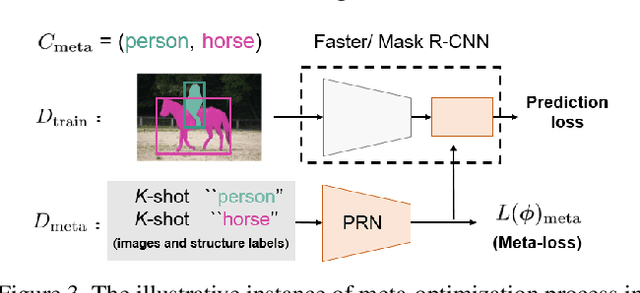
Resembling the rapid learning capability of human, low-shot learning empowers vision systems to understand new concepts by training with few samples. Leading approaches derived from meta-learning on images with a single visual object. Obfuscated by a complex background and multiple objects in one image, they are hard to promote the research of low-shot object detection/segmentation. In this work, we present a flexible and general methodology to achieve these tasks. Our work extends Faster /Mask R-CNN by proposing meta-learning over RoI (Region-of-Interest) features instead of a full image feature. This simple spirit disentangles multi-object information merged with the background, without bells and whistles, enabling Faster /Mask R-CNN turn into a meta-learner to achieve the tasks. Specifically, we introduce a Predictor-head Remodeling Network (PRN) that shares its main backbone with Faster /Mask R-CNN. PRN receives images containing low-shot objects with their bounding boxes or masks to infer their class attentive vectors. The vectors take channel-wise soft-attention on RoI features, remodeling those R-CNN predictor heads to detect or segment the objects that are consistent with the classes these vectors represent. In our experiments, Meta R-CNN yields the state of the art in low-shot object detection and improves low-shot object segmentation by Mask R-CNN.
Explainable High-order Visual Question Reasoning: A New Benchmark and Knowledge-routed Network
Sep 23, 2019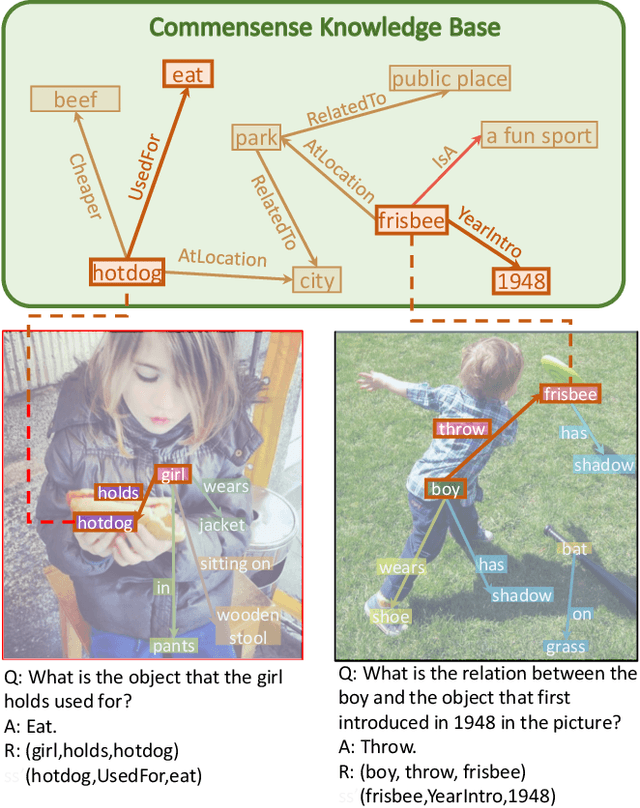
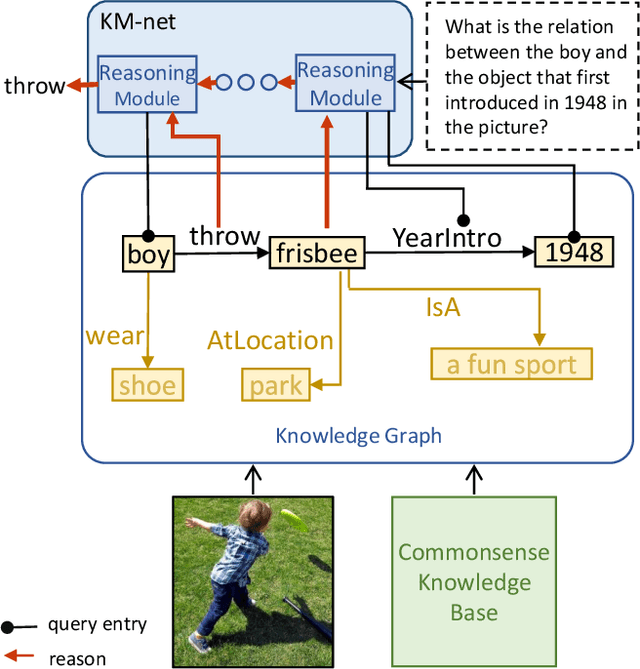
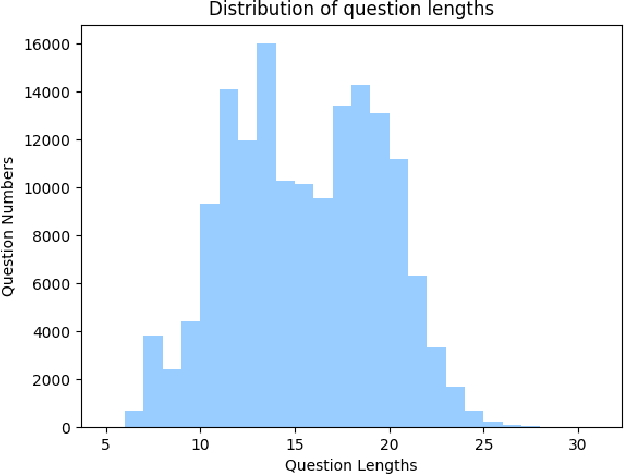
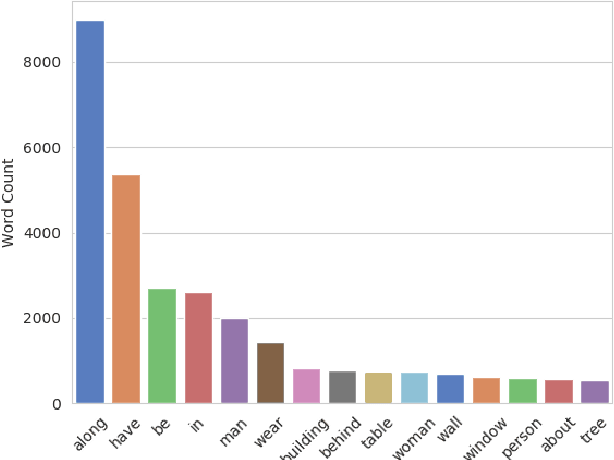
Explanation and high-order reasoning capabilities are crucial for real-world visual question answering with diverse levels of inference complexity (e.g., what is the dog that is near the girl playing with?) and important for users to understand and diagnose the trustworthiness of the system. Current VQA benchmarks on natural images with only an accuracy metric end up pushing the models to exploit the dataset biases and cannot provide any interpretable justification, which severally hinders advances in high-level question answering. In this work, we propose a new HVQR benchmark for evaluating explainable and high-order visual question reasoning ability with three distinguishable merits: 1) the questions often contain one or two relationship triplets, which requires the model to have the ability of multistep reasoning to predict plausible answers; 2) we provide an explicit evaluation on a multistep reasoning process that is constructed with image scene graphs and commonsense knowledge bases; and 3) each relationship triplet in a large-scale knowledge base only appears once among all questions, which poses challenges for existing networks that often attempt to overfit the knowledge base that already appears in the training set and enforces the models to handle unseen questions and knowledge fact usage. We also propose a new knowledge-routed modular network (KM-net) that incorporates the multistep reasoning process over a large knowledge base into visual question reasoning. An extensive dataset analysis and comparisons with existing models on the HVQR benchmark show that our benchmark provides explainable evaluations, comprehensive reasoning requirements and realistic challenges of VQA systems, as well as our KM-net's superiority in terms of accuracy and explanation ability.
ACFM: A Dynamic Spatial-Temporal Network for Traffic Prediction
Sep 02, 2019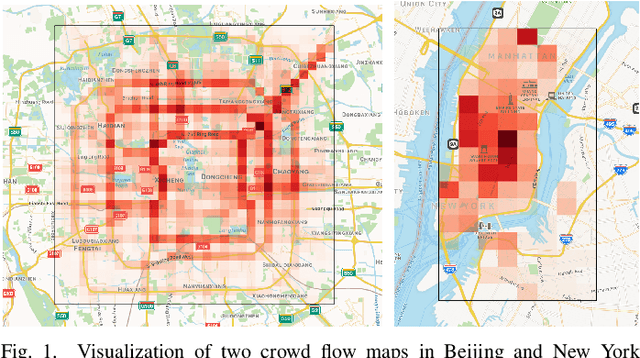
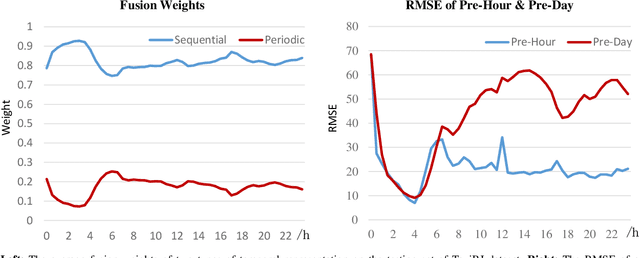
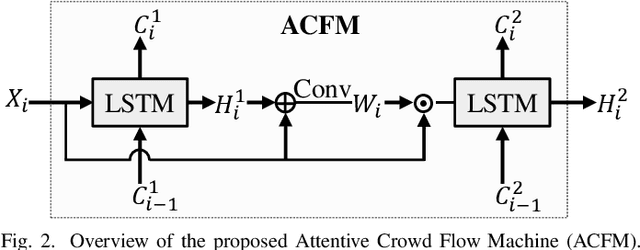
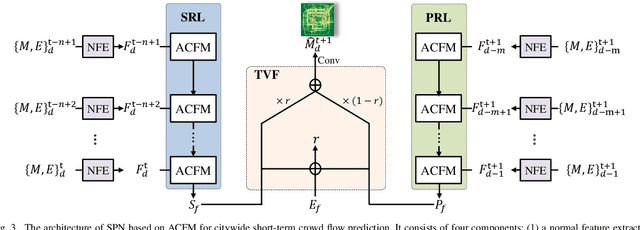
As a crucial component in intelligent transportation systems, crowd flow prediction has recently attracted widespread research interest in the field of artificial intelligence (AI) with the increasing availability of large-scale traffic mobility data. Its key challenge lies in how to integrate diverse factors (such as temporal laws and spatial dependencies) to infer the evolution trend of crowd flow. To address this problem, we propose a unified neural network called Attentive Crowd Flow Machine (ACFM), which can effectively learn the spatial-temporal feature representations of crowd flow with an attention mechanism. In particular, our ACFM is composed of two progressive ConvLSTM units connected with a convolutional layer. Specifically, the first LSTM unit takes normal crowd flow features as input and generates a hidden state at each time-step, which is further fed into the connected convolutional layer for spatial attention map inference. The second LSTM unit aims at learning the dynamic spatial-temporal representations from the attentionally weighted crowd flow features. Further, we develop two deep frameworks based on ACFM to predict citywide short-term/long-term crowd flow by adaptively incorporating the sequential and periodic data as well as other external influences. Extensive experiments on two standard benchmarks well demonstrate the superiority of the proposed method for crowd flow prediction. Moreover, to verify the generalization of our method, we also apply the customized framework to forecast the passenger pickup/dropoff demands and show its superior performance in this traffic prediction task.
Fashion Retrieval via Graph Reasoning Networks on a Similarity Pyramid
Aug 30, 2019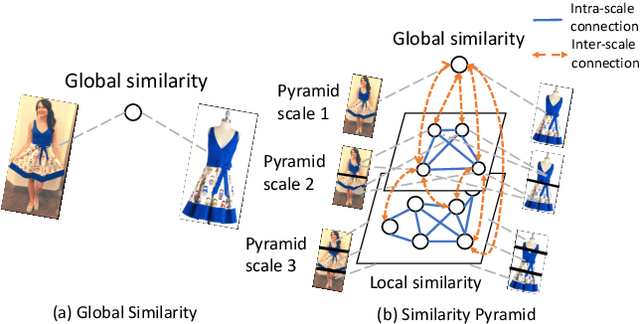
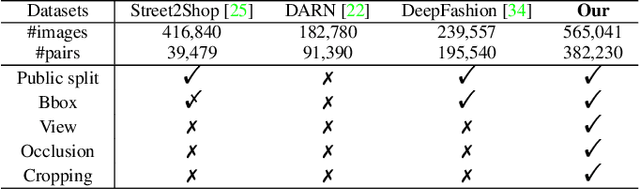
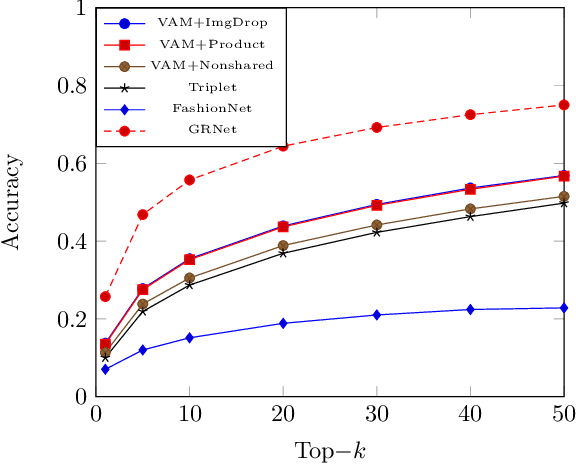
Matching clothing images from customers and online shopping stores has rich applications in E-commerce. Existing algorithms encoded an image as a global feature vector and performed retrieval with the global representation. However, discriminative local information on clothes are submerged in this global representation, resulting in sub-optimal performance. To address this issue, we propose a novel Graph Reasoning Network (GRNet) on a Similarity Pyramid, which learns similarities between a query and a gallery cloth by using both global and local representations in multiple scales. The similarity pyramid is represented by a Graph of similarity, where nodes represent similarities between clothing components at different scales, and the final matching score is obtained by message passing along edges. In GRNet, graph reasoning is solved by training a graph convolutional network, enabling to align salient clothing components to improve clothing retrieval. To facilitate future researches, we introduce a new benchmark FindFashion, containing rich annotations of bounding boxes, views, occlusions, and cropping. Extensive experiments show that GRNet obtains new state-of-the-art results on two challenging benchmarks, e.g., pushing the top-1, top-20, and top-50 accuracies on DeepFashion to 26%, 64%, and 75% (i.e., 4%, 10%, and 10% absolute improvements), outperforming competitors with large margins. On FindFashion, GRNet achieves considerable improvements on all empirical settings.
Crowd Counting with Deep Structured Scale Integration Network
Aug 23, 2019


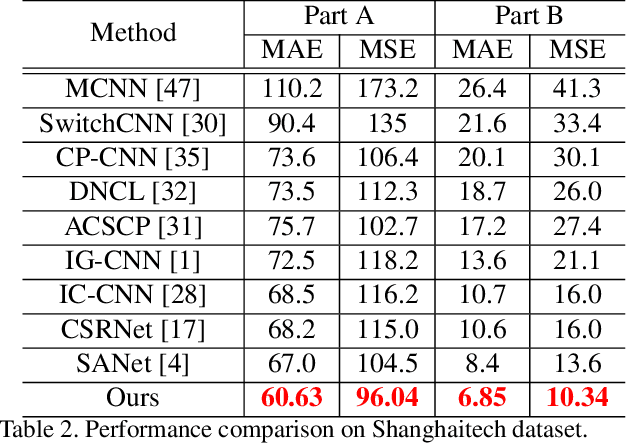
Automatic estimation of the number of people in unconstrained crowded scenes is a challenging task and one major difficulty stems from the huge scale variation of people. In this paper, we propose a novel Deep Structured Scale Integration Network (DSSINet) for crowd counting, which addresses the scale variation of people by using structured feature representation learning and hierarchically structured loss function optimization. Unlike conventional methods which directly fuse multiple features with weighted average or concatenation, we first introduce a Structured Feature Enhancement Module based on conditional random fields (CRFs) to refine multiscale features mutually with a message passing mechanism. In this module, each scale-specific feature is considered as a continuous random variable and passes complementary information to refine the features at other scales. Second, we utilize a Dilated Multiscale Structural Similarity loss to enforce our DSSINet to learn the local correlation of people's scales within regions of various size, thus yielding high-quality density maps. Extensive experiments on four challenging benchmarks well demonstrate the effectiveness of our method. Specifically, our DSSINet achieves improvements of 9.5% error reduction on Shanghaitech dataset and 24.9% on UCF-QNRF dataset against the state-of-the-art methods.
Learning Semantic-Specific Graph Representation for Multi-Label Image Recognition
Aug 20, 2019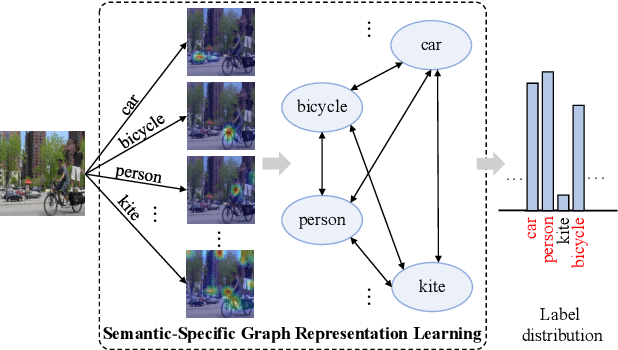
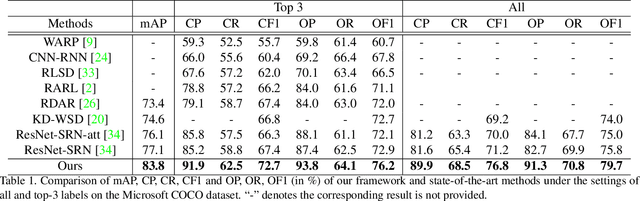
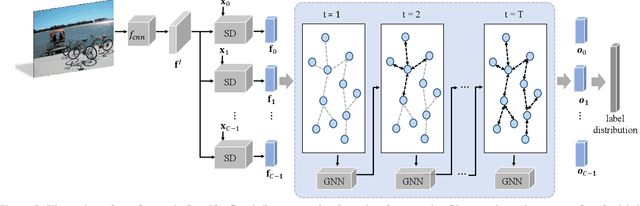
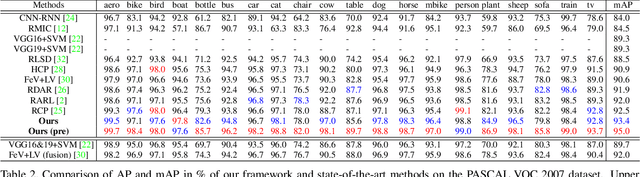
Recognizing multiple labels of images is a practical and challenging task, and significant progress has been made by searching semantic-aware regions and modeling label dependency. However, current methods cannot locate the semantic regions accurately due to the lack of part-level supervision or semantic guidance. Moreover, they cannot fully explore the mutual interactions among the semantic regions and do not explicitly model the label co-occurrence. To address these issues, we propose a Semantic-Specific Graph Representation Learning (SSGRL) framework that consists of two crucial modules: 1) a semantic decoupling module that incorporates category semantics to guide learning semantic-specific representations and 2) a semantic interaction module that correlates these representations with a graph built on the statistical label co-occurrence and explores their interactions via a graph propagation mechanism. Extensive experiments on public benchmarks show that our SSGRL framework outperforms current state-of-the-art methods by a sizable margin, e.g. with an mAP improvement of 2.5%, 2.6%, 6.7%, and 3.1% on the PASCAL VOC 2007 & 2012, Microsoft-COCO and Visual Genome benchmarks, respectively. Our codes and models are available at https://github.com/HCPLab-SYSU/SSGRL.
Semi-Supervised Video Salient Object Detection Using Pseudo-Labels
Aug 12, 2019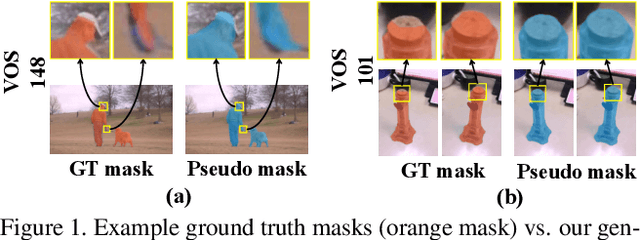

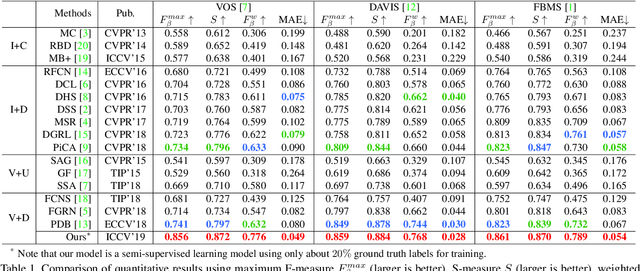
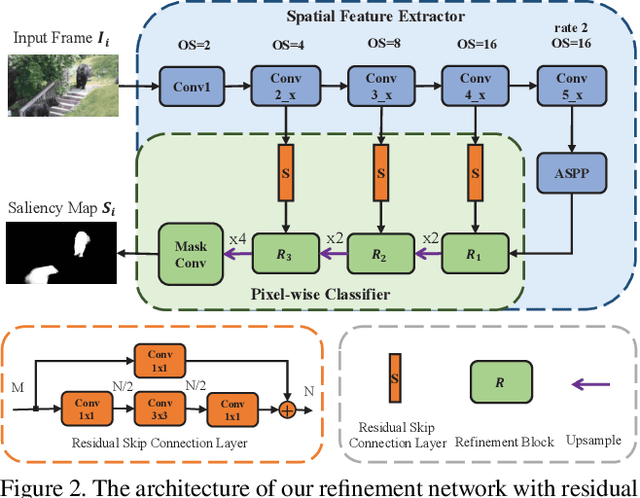
Deep learning-based video salient object detection has recently achieved great success with its performance significantly outperforming any other unsupervised methods. However, existing data-driven approaches heavily rely on a large quantity of pixel-wise annotated video frames to deliver such promising results. In this paper, we address the semi-supervised video salient object detection task using pseudo-labels. Specifically, we present an effective video saliency detector that consists of a spatial refinement network and a spatiotemporal module. Based on the same refinement network and motion information in terms of optical flow, we further propose a novel method for generating pixel-level pseudo-labels from sparsely annotated frames. By utilizing the generated pseudo-labels together with a part of manual annotations, our video saliency detector learns spatial and temporal cues for both contrast inference and coherence enhancement, thus producing accurate saliency maps. Experimental results demonstrate that our proposed semi-supervised method even greatly outperforms all the state-of-the-art fully supervised methods across three public benchmarks of VOS, DAVIS, and FBMS.
Learning Compact Target-Oriented Feature Representations for Visual Tracking
Aug 05, 2019

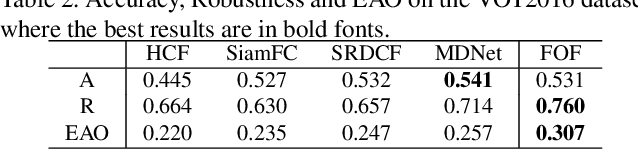
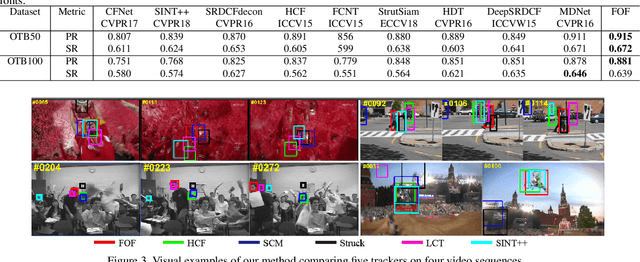
Many state-of-the-art trackers usually resort to the pretrained convolutional neural network (CNN) model for correlation filtering, in which deep features could usually be redundant, noisy and less discriminative for some certain instances, and the tracking performance might thus be affected. To handle this problem, we propose a novel approach, which takes both advantages of good generalization of generative models and excellent discrimination of discriminative models, for visual tracking. In particular, we learn compact, discriminative and target-oriented feature representations using the Laplacian coding algorithm that exploits the dependence among the input local features in a discriminative correlation filter framework. The feature representations and the correlation filter are jointly learnt to enhance to each other via a fast solver which only has very slight computational burden on the tracking speed. Extensive experiments on three benchmark datasets demonstrate that this proposed framework clearly outperforms baseline trackers with a modest impact on the frame rate, and performs comparably against the state-of-the-art methods.
Multivariate-Information Adversarial Ensemble for Scalable Joint Distribution Matching
Jul 08, 2019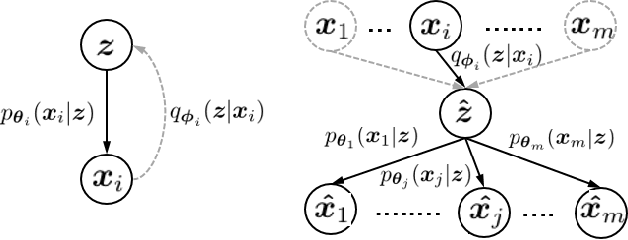


A broad range of cross-$m$-domain generation researches boil down to matching a joint distribution by deep generative models (DGMs). Hitherto algorithms excel in pairwise domains while as $m$ increases, remain struggling to scale themselves to fit a joint distribution. In this paper, we propose a domain-scalable DGM, i.e., MMI-ALI for $m$-domain joint distribution matching. As an $m$-domain ensemble model of ALIs \cite{dumoulin2016adversarially}, MMI-ALI is adversarially trained with maximizing Multivariate Mutual Information (MMI) w.r.t. joint variables of each pair of domains and their shared feature. The negative MMIs are upper bounded by a series of feasible losses that provably lead to matching $m$-domain joint distributions. MMI-ALI linearly scales as $m$ increases and thus, strikes a right balance between efficacy and scalability. We evaluate MMI-ALI in diverse challenging $m$-domain scenarios and verify its superiority.