 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Token Eviction: Mixed-Dimension Budget Allocation for Efficient KV Cache Compression
Mar 21, 2026Key-value (KV) caching is widely used to accelerate transformer inference, but its memory cost grows linearly with input length, limiting long-context deployment. Existing token eviction methods reduce memory by discarding less important tokens, which can be viewed as a coarse form of dimensionality reduction that assigns each token either zero or full dimension. We propose MixedDimKV, a mixed-dimension KV cache compression method that allocates dimensions to tokens at a more granular level, and MixedDimKV-H, which further integrates head-level importance information. Experiments on long-context benchmarks show that MixedDimKV outperforms prior KV cache compression methods that do not rely on head-level importance profiling. When equipped with the same head-level importance information, MixedDimKV-H consistently outperforms HeadKV. Notably, our approach achieves comparable performance to full attention on LongBench with only 6.25% of the KV cache. Furthermore, in the Needle-in-a-Haystack test, our solution maintains 100% accuracy at a 50K context length while using as little as 0.26% of the cache.
Taming the Chaos: Coordinated Autoscaling for Heterogeneous and Disaggregated LLM Inference
Aug 27, 2025



Serving Large Language Models (LLMs) is a GPU-intensive task where traditional autoscalers fall short, particularly for modern Prefill-Decode (P/D) disaggregated architectures. This architectural shift, while powerful, introduces significant operational challenges, including inefficient use of heterogeneous hardware, network bottlenecks, and critical imbalances between prefill and decode stages. We introduce HeteroScale, a coordinated autoscaling framework that addresses the core challenges of P/D disaggregated serving. HeteroScale combines a topology-aware scheduler that adapts to heterogeneous hardware and network constraints with a novel metric-driven policy derived from the first large-scale empirical study of autoscaling signals in production. By leveraging a single, robust metric to jointly scale prefill and decode pools, HeteroScale maintains architectural balance while ensuring efficient, adaptive resource management. Deployed in a massive production environment on tens of thousands of GPUs, HeteroScale has proven its effectiveness, increasing average GPU utilization by a significant 26.6 percentage points and saving hundreds of thousands of GPU-hours daily, all while upholding stringent service level objectives.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Crowd Counting with Deep Structured Scale Integration Network
Aug 23, 2019


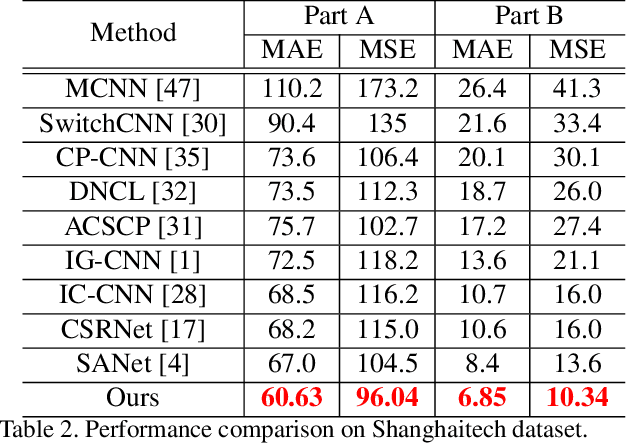
Automatic estimation of the number of people in unconstrained crowded scenes is a challenging task and one major difficulty stems from the huge scale variation of people. In this paper, we propose a novel Deep Structured Scale Integration Network (DSSINet) for crowd counting, which addresses the scale variation of people by using structured feature representation learning and hierarchically structured loss function optimization. Unlike conventional methods which directly fuse multiple features with weighted average or concatenation, we first introduce a Structured Feature Enhancement Module based on conditional random fields (CRFs) to refine multiscale features mutually with a message passing mechanism. In this module, each scale-specific feature is considered as a continuous random variable and passes complementary information to refine the features at other scales. Second, we utilize a Dilated Multiscale Structural Similarity loss to enforce our DSSINet to learn the local correlation of people's scales within regions of various size, thus yielding high-quality density maps. Extensive experiments on four challenging benchmarks well demonstrate the effectiveness of our method. Specifically, our DSSINet achieves improvements of 9.5% error reduction on Shanghaitech dataset and 24.9% on UCF-QNRF dataset against the state-of-the-art methods.