 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore before Moving: A Feasible Path Estimation and Memory Recalling Framework for Embodied Navigation
Oct 16, 2021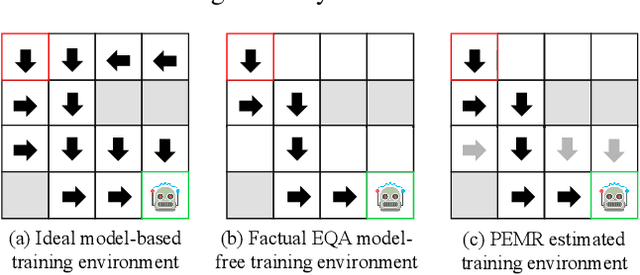
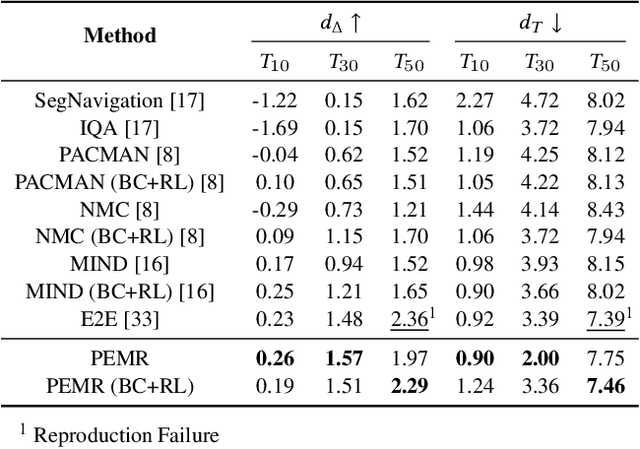
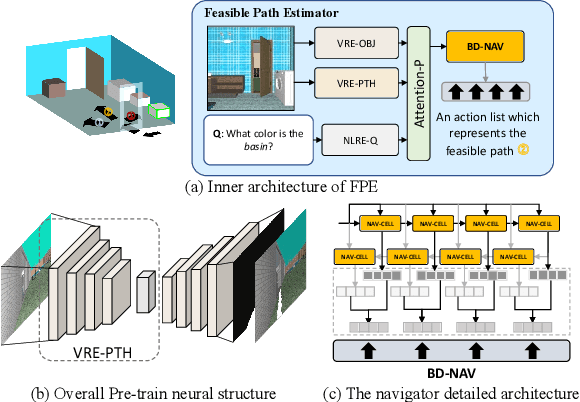
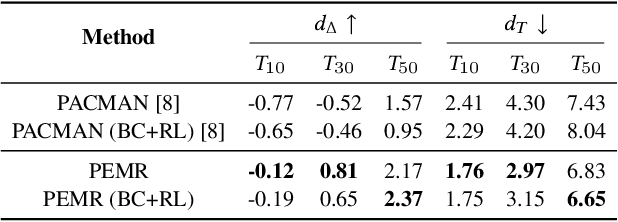
An embodied task such as embodied question answering (EmbodiedQA), requires an agent to explore the environment and collect clues to answer a given question that related with specific objects in the scene. The solution of such task usually includes two stages, a navigator and a visual Q&A module. In this paper, we focus on the navigation and solve the problem of existing navigation algorithms lacking experience and common sense, which essentially results in a failure finding target when robot is spawn in unknown environments. Inspired by the human ability to think twice before moving and conceive several feasible paths to seek a goal in unfamiliar scenes, we present a route planning method named Path Estimation and Memory Recalling (PEMR) framework. PEMR includes a "looking ahead" process, \textit{i.e.} a visual feature extractor module that estimates feasible paths for gathering 3D navigational information, which is mimicking the human sense of direction. PEMR contains another process ``looking behind'' process that is a memory recall mechanism aims at fully leveraging past experience collected by the feature extractor. Last but not the least, to encourage the navigator to learn more accurate prior expert experience, we improve the original benchmark dataset and provide a family of evaluation metrics for diagnosing both navigation and question answering modules. We show strong experimental results of PEMR on the EmbodiedQA navigation task.
Wav-BERT: Cooperative Acoustic and Linguistic Representation Learning for Low-Resource Speech Recognition
Oct 09, 2021
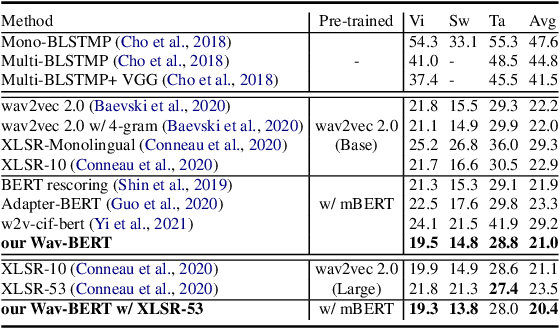
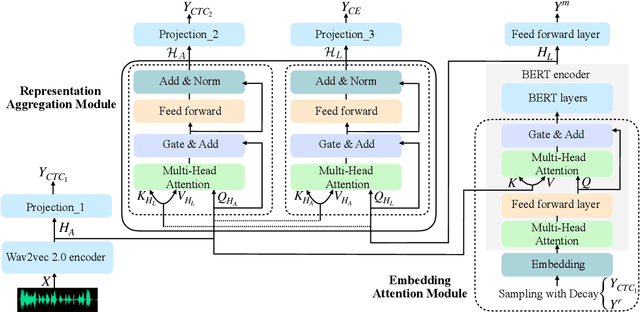
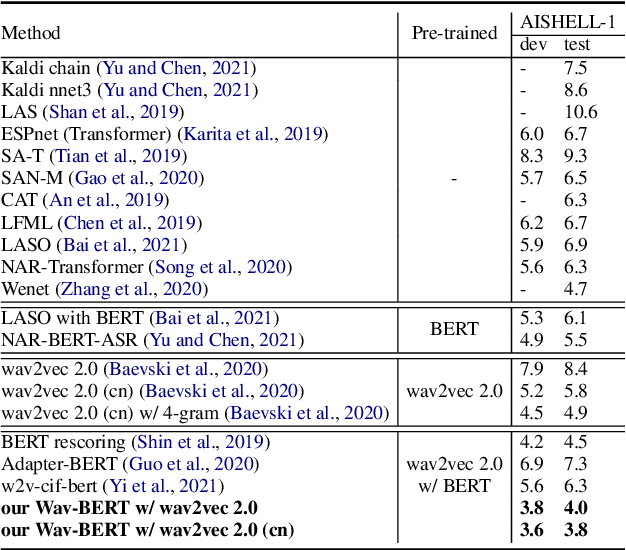
Unifying acoustic and linguistic representation learning has become increasingly crucial to transfer the knowledge learned on the abundance of high-resource language data for low-resource speech recognition. Existing approaches simply cascade pre-trained acoustic and language models to learn the transfer from speech to text. However, how to solve the representation discrepancy of speech and text is unexplored, which hinders the utilization of acoustic and linguistic information. Moreover, previous works simply replace the embedding layer of the pre-trained language model with the acoustic features, which may cause the catastrophic forgetting problem. In this work, we introduce Wav-BERT, a cooperative acoustic and linguistic representation learning method to fuse and utilize the contextual information of speech and text. Specifically, we unify a pre-trained acoustic model (wav2vec 2.0) and a language model (BERT) into an end-to-end trainable framework. A Representation Aggregation Module is designed to aggregate acoustic and linguistic representation, and an Embedding Attention Module is introduced to incorporate acoustic information into BERT, which can effectively facilitate the cooperation of two pre-trained models and thus boost the representation learning. Extensive experiments show that our Wav-BERT significantly outperforms the existing approaches and achieves state-of-the-art performance on low-resource speech recognition.
Road Network Guided Fine-Grained Urban Traffic Flow Inference
Sep 29, 2021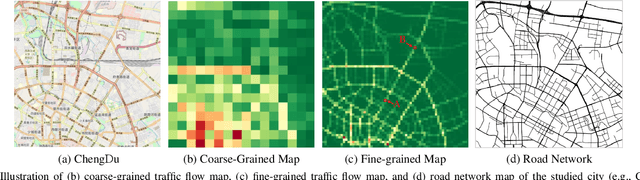
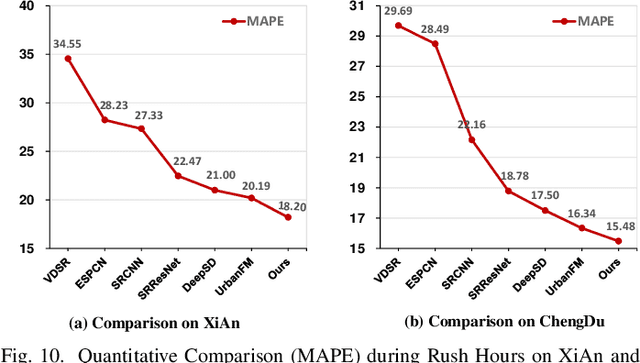
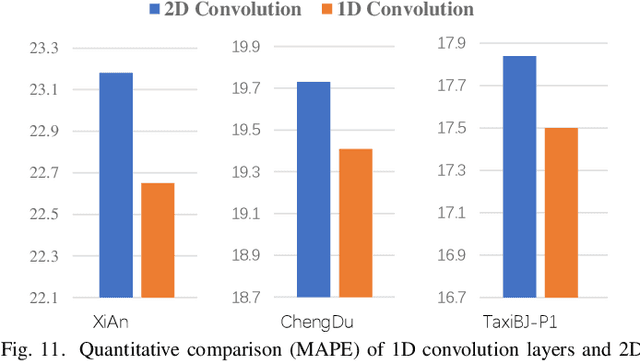
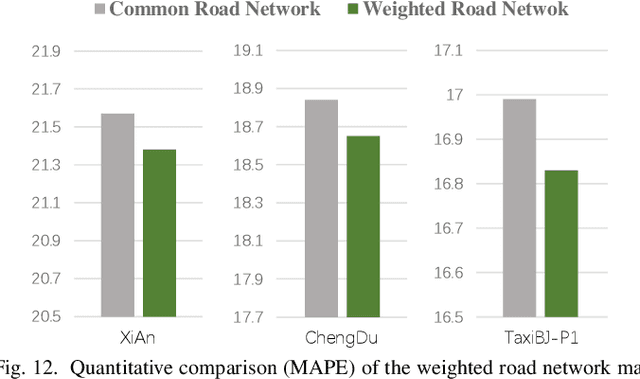
Accurate inference of fine-grained traffic flow from coarse-grained one is an emerging yet crucial problem, which can help greatly reduce the number of traffic monitoring sensors for cost savings. In this work, we notice that traffic flow has a high correlation with road network, which was either completely ignored or simply treated as an external factor in previous works. To facilitate this problem, we propose a novel Road-Aware Traffic Flow Magnifier (RATFM) that explicitly exploits the prior knowledge of road networks to fully learn the road-aware spatial distribution of fine-grained traffic flow. Specifically, a multi-directional 1D convolutional layer is first introduced to extract the semantic feature of the road network. Subsequently, we incorporate the road network feature and coarse-grained flow feature to regularize the short-range spatial distribution modeling of road-relative traffic flow. Furthermore, we take the road network feature as a query to capture the long-range spatial distribution of traffic flow with a transformer architecture. Benefiting from the road-aware inference mechanism, our method can generate high-quality fine-grained traffic flow maps. Extensive experiments on three real-world datasets show that the proposed RATFM outperforms state-of-the-art models under various scenarios.
Pi-NAS: Improving Neural Architecture Search by Reducing Supernet Training Consistency Shift
Aug 22, 2021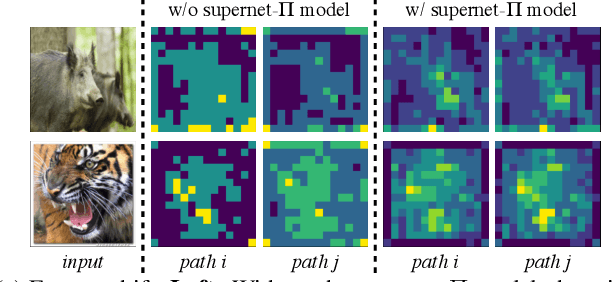
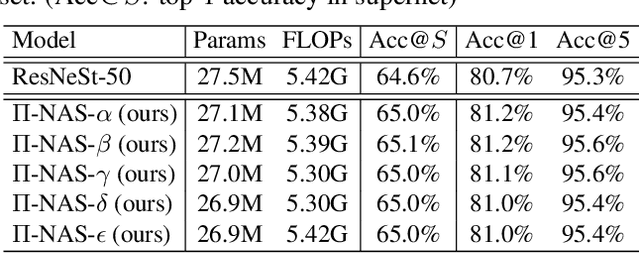
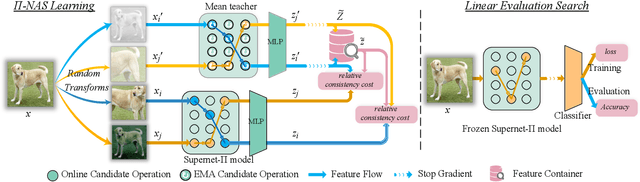
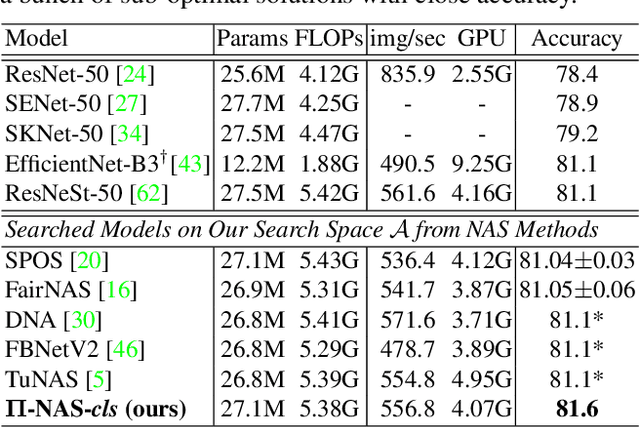
Recently proposed neural architecture search (NAS) methods co-train billions of architectures in a supernet and estimate their potential accuracy using the network weights detached from the supernet. However, the ranking correlation between the architectures' predicted accuracy and their actual capability is incorrect, which causes the existing NAS methods' dilemma. We attribute this ranking correlation problem to the supernet training consistency shift, including feature shift and parameter shift. Feature shift is identified as dynamic input distributions of a hidden layer due to random path sampling. The input distribution dynamic affects the loss descent and finally affects architecture ranking. Parameter shift is identified as contradictory parameter updates for a shared layer lay in different paths in different training steps. The rapidly-changing parameter could not preserve architecture ranking. We address these two shifts simultaneously using a nontrivial supernet-Pi model, called Pi-NAS. Specifically, we employ a supernet-Pi model that contains cross-path learning to reduce the feature consistency shift between different paths. Meanwhile, we adopt a novel nontrivial mean teacher containing negative samples to overcome parameter shift and model collision. Furthermore, our Pi-NAS runs in an unsupervised manner, which can search for more transferable architectures. Extensive experiments on ImageNet and a wide range of downstream tasks (e.g., COCO 2017, ADE20K, and Cityscapes) demonstrate the effectiveness and universality of our Pi-NAS compared to supervised NAS. See Codes: https://github.com/Ernie1/Pi-NAS.
Trash to Treasure: Harvesting OOD Data with Cross-Modal Matching for Open-Set Semi-Supervised Learning
Aug 12, 2021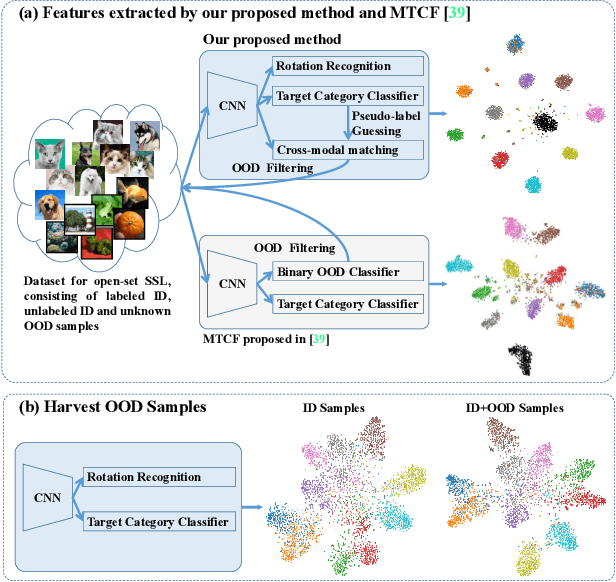
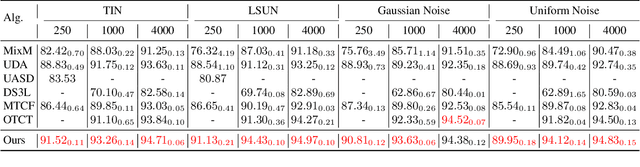
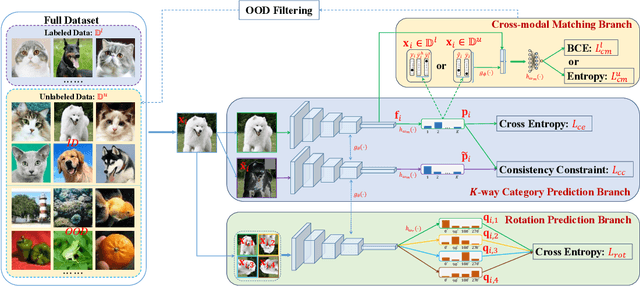
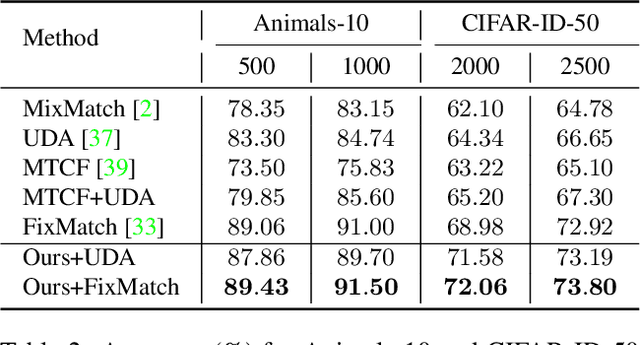
Open-set semi-supervised learning (open-set SSL) investigates a challenging but practical scenario where out-of-distribution (OOD) samples are contained in the unlabeled data. While the mainstream technique seeks to completely filter out the OOD samples for semi-supervised learning (SSL), we propose a novel training mechanism that could effectively exploit the presence of OOD data for enhanced feature learning while avoiding its adverse impact on the SSL. We achieve this goal by first introducing a warm-up training that leverages all the unlabeled data, including both the in-distribution (ID) and OOD samples. Specifically, we perform a pretext task that enforces our feature extractor to obtain a high-level semantic understanding of the training images, leading to more discriminative features that can benefit the downstream tasks. Since the OOD samples are inevitably detrimental to SSL, we propose a novel cross-modal matching strategy to detect OOD samples. Instead of directly applying binary classification, we train the network to predict whether the data sample is matched to an assigned one-hot class label. The appeal of the proposed cross-modal matching over binary classification is the ability to generate a compatible feature space that aligns with the core classification task. Extensive experiments show that our approach substantially lifts the performance on open-set SSL and outperforms the state-of-the-art by a large margin.
Weakly-Supervised Spatio-Temporal Anomaly Detection in Surveillance Video
Aug 09, 2021
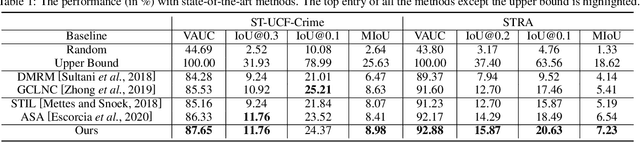
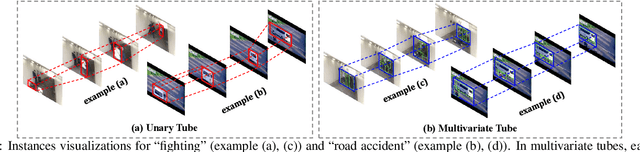
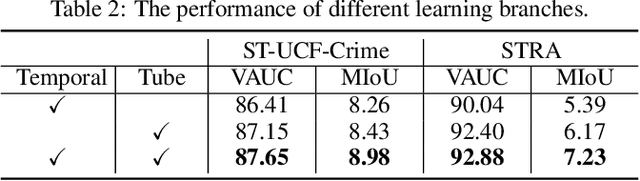
In this paper, we introduce a novel task, referred to as Weakly-Supervised Spatio-Temporal Anomaly Detection (WSSTAD) in surveillance video. Specifically, given an untrimmed video, WSSTAD aims to localize a spatio-temporal tube (i.e., a sequence of bounding boxes at consecutive times) that encloses the abnormal event, with only coarse video-level annotations as supervision during training. To address this challenging task, we propose a dual-branch network which takes as input the proposals with multi-granularities in both spatial-temporal domains. Each branch employs a relationship reasoning module to capture the correlation between tubes/videolets, which can provide rich contextual information and complex entity relationships for the concept learning of abnormal behaviors. Mutually-guided Progressive Refinement framework is set up to employ dual-path mutual guidance in a recurrent manner, iteratively sharing auxiliary supervision information across branches. It impels the learned concepts of each branch to serve as a guide for its counterpart, which progressively refines the corresponding branch and the whole framework. Furthermore, we contribute two datasets, i.e., ST-UCF-Crime and STRA, consisting of videos containing spatio-temporal abnormal annotations to serve as the benchmarks for WSSTAD. We conduct extensive qualitative and quantitative evaluations to demonstrate the effectiveness of the proposed approach and analyze the key factors that contribute more to handle this task.
Adversarial Reinforced Instruction Attacker for Robust Vision-Language Navigation
Jul 23, 2021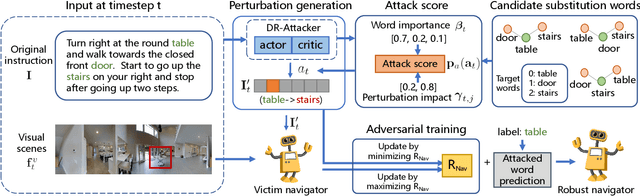
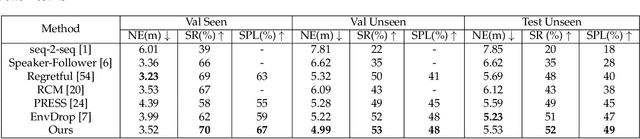
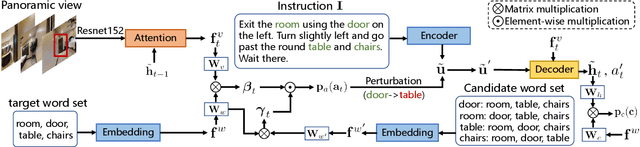

Language instruction plays an essential role in the natural language grounded navigation tasks. However, navigators trained with limited human-annotated instructions may have difficulties in accurately capturing key information from the complicated instruction at different timesteps, leading to poor navigation performance. In this paper, we exploit to train a more robust navigator which is capable of dynamically extracting crucial factors from the long instruction, by using an adversarial attacking paradigm. Specifically, we propose a Dynamic Reinforced Instruction Attacker (DR-Attacker), which learns to mislead the navigator to move to the wrong target by destroying the most instructive information in instructions at different timesteps. By formulating the perturbation generation as a Markov Decision Process, DR-Attacker is optimized by the reinforcement learning algorithm to generate perturbed instructions sequentially during the navigation, according to a learnable attack score. Then, the perturbed instructions, which serve as hard samples, are used for improving the robustness of the navigator with an effective adversarial training strategy and an auxiliary self-supervised reasoning task. Experimental results on both Vision-and-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks show the superiority of our proposed method over state-of-the-art methods. Moreover, the visualization analysis shows the effectiveness of the proposed DR-Attacker, which can successfully attack crucial information in the instructions at different timesteps. Code is available at https://github.com/expectorlin/DR-Attacker.
* Accepted by TPAMI 2021
Hybrid and dynamic policy gradient optimization for bipedal robot locomotion
Jul 05, 2021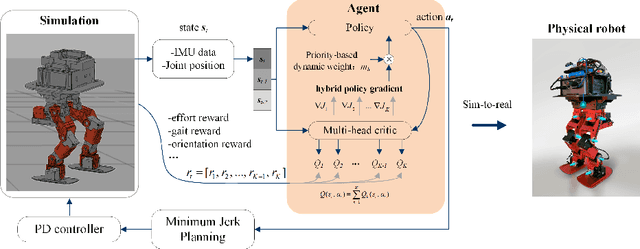
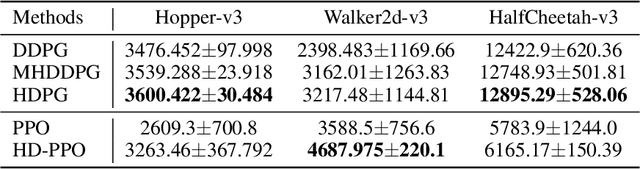
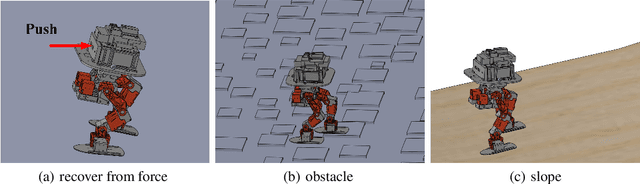
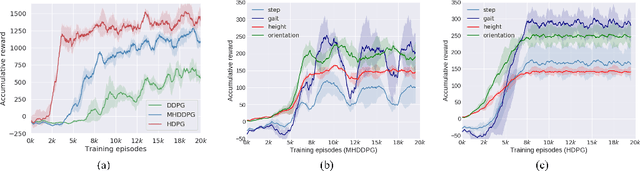
Controlling a non-statically bipedal robot is challenging due to the complex dynamics and multi-criterion optimization involved. Recent works have demonstrated the effectiveness of deep reinforcement learning (DRL) for simulation and physically implemented bipeds. In these methods, the rewards from different criteria are normally summed to learn a single value function. However, this may cause the loss of dependency information between hybrid rewards and lead to a sub-optimal policy. In this work, we propose a novel policy gradient reinforcement learning for biped locomotion, allowing the control policy to be simultaneously optimized by multiple criteria using a dynamic mechanism. Our proposed method applies a multi-head critic to learn a separate value function for each component reward function. This also leads to hybrid policy gradients. We further propose dynamic weight for hybrid policy gradients to optimize the policy with different priorities. This hybrid and dynamic policy gradient (HDPG) design makes the agent learn more efficiently. We showed that the proposed method outperforms summed-up-reward approaches and is able to transfer to physical robots. The MuJoCo results further demonstrate the effectiveness and generalization of our HDPG.
Neural-Symbolic Solver for Math Word Problems with Auxiliary Tasks
Jul 03, 2021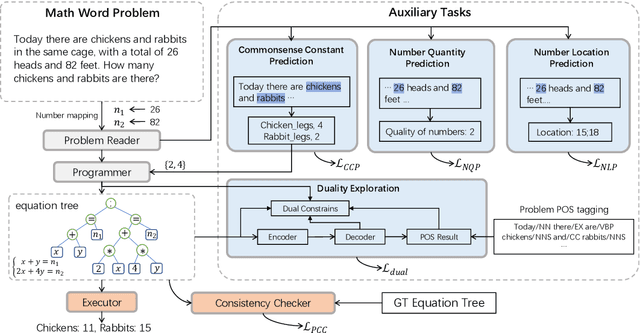
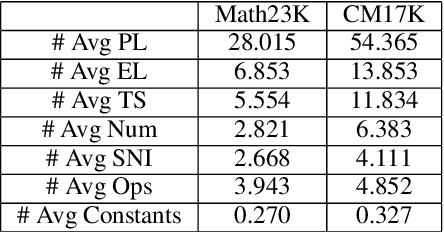
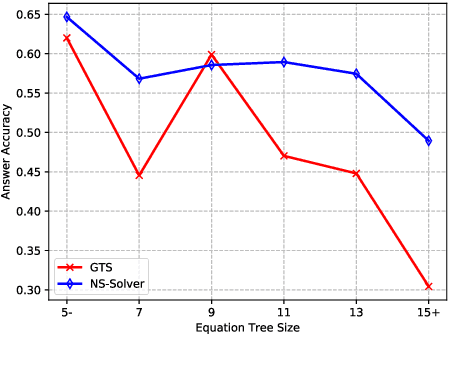
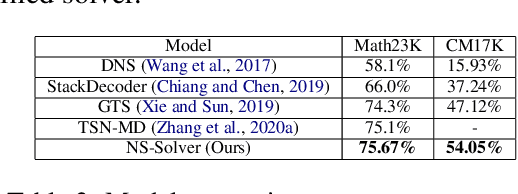
Previous math word problem solvers following the encoder-decoder paradigm fail to explicitly incorporate essential math symbolic constraints, leading to unexplainable and unreasonable predictions. Herein, we propose Neural-Symbolic Solver (NS-Solver) to explicitly and seamlessly incorporate different levels of symbolic constraints by auxiliary tasks. Our NS-Solver consists of a problem reader to encode problems, a programmer to generate symbolic equations, and a symbolic executor to obtain answers. Along with target expression supervision, our solver is also optimized via 4 new auxiliary objectives to enforce different symbolic reasoning: a) self-supervised number prediction task predicting both number quantity and number locations; b) commonsense constant prediction task predicting what prior knowledge (e.g. how many legs a chicken has) is required; c) program consistency checker computing the semantic loss between predicted equation and target equation to ensure reasonable equation mapping; d) duality exploiting task exploiting the quasi duality between symbolic equation generation and problem's part-of-speech generation to enhance the understanding ability of a solver. Besides, to provide a more realistic and challenging benchmark for developing a universal and scalable solver, we also construct a new large-scale MWP benchmark CM17K consisting of 4 kinds of MWPs (arithmetic, one-unknown linear, one-unknown non-linear, equation set) with more than 17K samples. Extensive experiments on Math23K and our CM17k demonstrate the superiority of our NS-Solver compared to state-of-the-art methods.
Prototypical Graph Contrastive Learning
Jun 17, 2021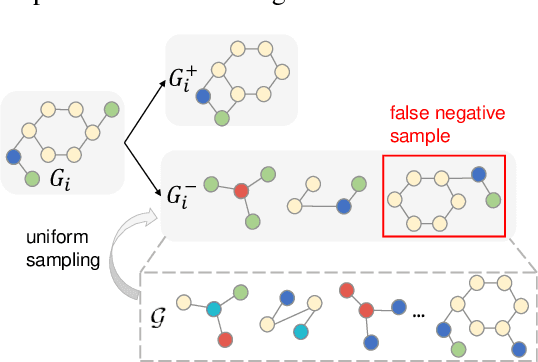
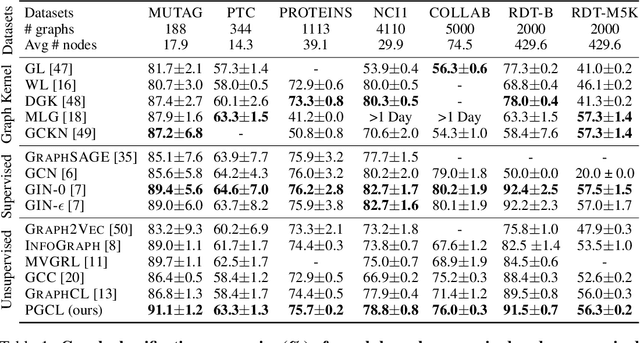
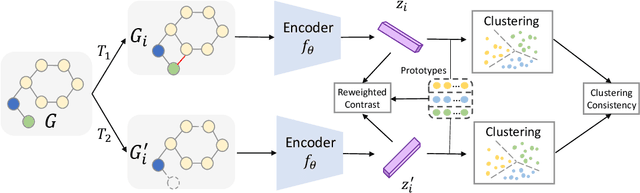
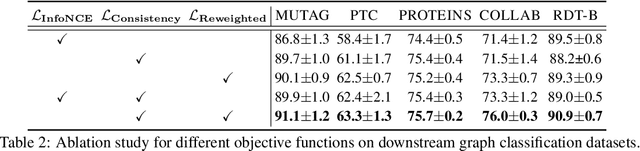
Graph-level representations are critical in various real-world applications, such as predicting the properties of molecules. But in practice, precise graph annotations are generally very expensive and time-consuming. To address this issue, graph contrastive learning constructs instance discrimination task which pulls together positive pairs (augmentation pairs of the same graph) and pushes away negative pairs (augmentation pairs of different graphs) for unsupervised representation learning. However, since for a query, its negatives are uniformly sampled from all graphs, existing methods suffer from the critical sampling bias issue, i.e., the negatives likely having the same semantic structure with the query, leading to performance degradation. To mitigate this sampling bias issue, in this paper, we propose a Prototypical Graph Contrastive Learning (PGCL) approach. Specifically, PGCL models the underlying semantic structure of the graph data via clustering semantically similar graphs into the same group, and simultaneously encourages the clustering consistency for different augmentations of the same graph. Then given a query, it performs negative sampling via drawing the graphs from those clusters that differ from the cluster of query, which ensures the semantic difference between query and its negative samples. Moreover, for a query, PGCL further reweights its negative samples based on the distance between their prototypes (cluster centroids) and the query prototype such that those negatives having moderate prototype distance enjoy relatively large weights. This reweighting strategy is proved to be more effective than uniform sampling. Experimental results on various graph benchmarks testify the advantages of our PGCL over state-of-the-art methods.